Does Apache Kafka® really preserve message ordering?の翻訳です。
2023年3月21日
Apache Kafka® は本当にメッセージの順序を保持するのか?
Apache Kafka®はトピック/パーティションごとにメッセージの順序を保持すると言われているが、それは本当なのだろうか?
Apache Kafka®の最も有名なマントラの1つは「トピック・パーティションごとのメッセージ順序を保持する」ですが、それは常に正しいのでしょうか?このブログポストでは、そのマントラを疑うことなく受け入れると、予期せぬ、誤ったメッセージの順序になる可能性がある、いくつかの実際のシナリオを分析します。
基本シナリオ:単一のプロデューサー
基本的なシナリオから始めましょう。単一のプロデューサーが、単一のパーティションを持つApache Kafkaトピックに、順番にメッセージを送信します。
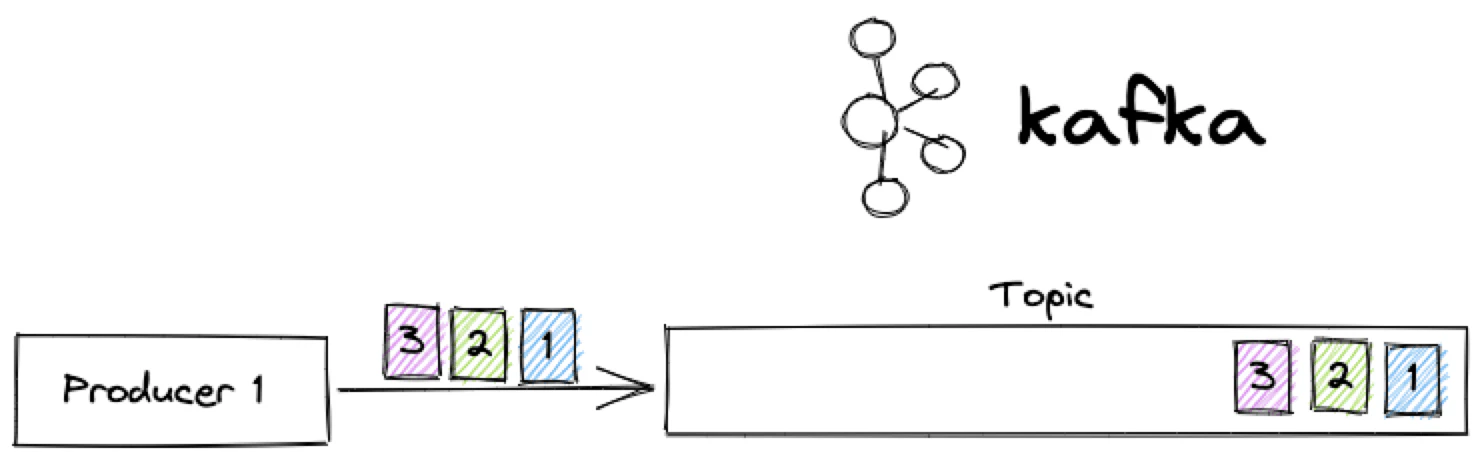
この基本的な状況では、よく知られているマントラの通り、常に正しい順序が期待できるはずだ。しかし、それは本当だろうか?まあ...場合によるね!
ネットワークは平等ではない
理想的な世界では、単一生産者のシナリオは常に正しい順序になるはずである。しかし、我々の世界は完璧ではない!異なるネットワーク経路、エラーや遅延は、メッセージが遅れたり失われたりすることを意味します。
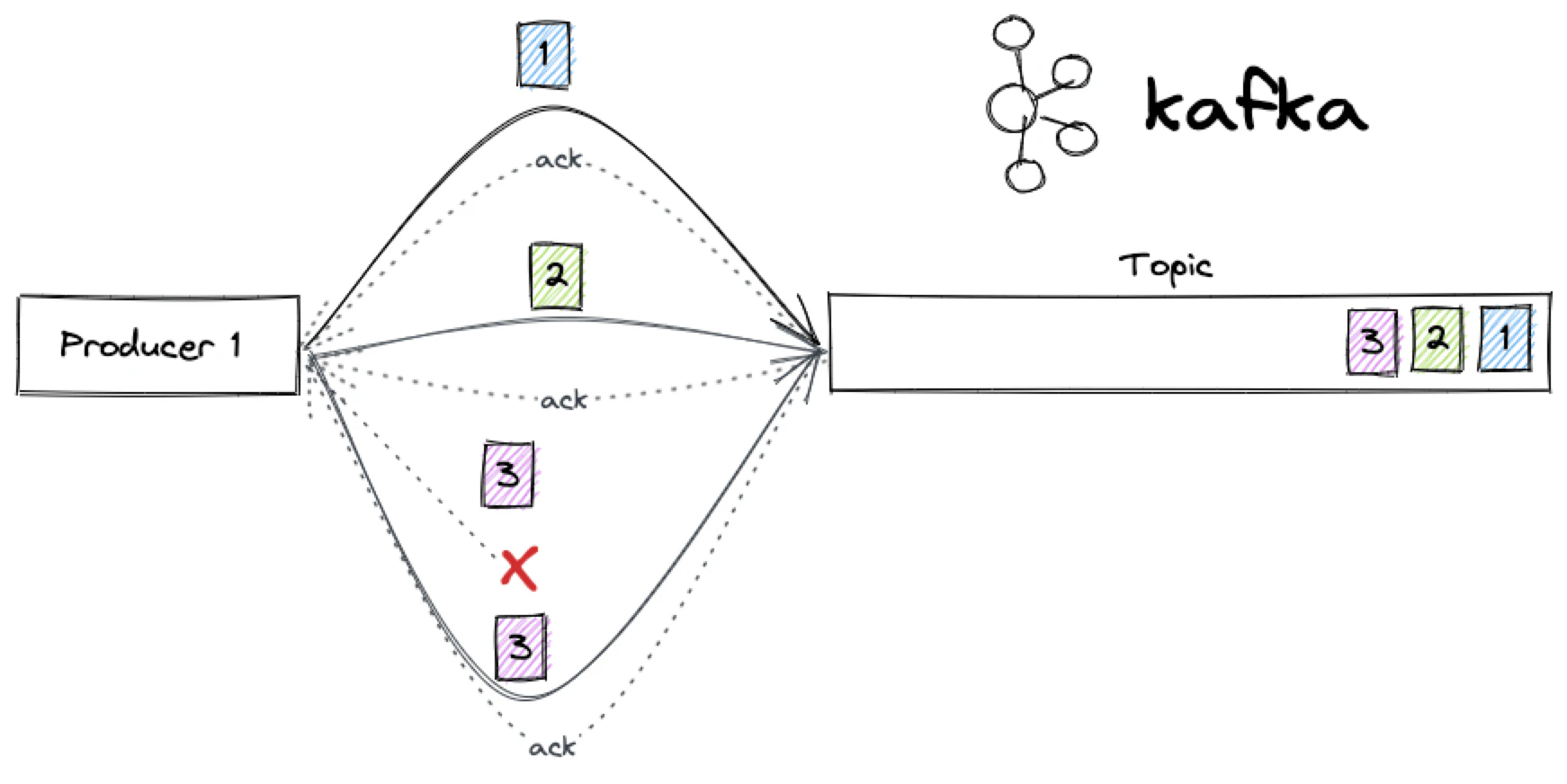
以下のような状況を想像してみよう。単一のプロデューサーが、トピックに3つのメッセージを送信する:
- メッセージ
1は、何らかの理由で Apache Kafka への長いネットワークルートを見つける。 - メッセージ
2は Apache Kafka への最短のネットワークルートを見つける。 - メッセージ
3はネットワークで迷子になる。

この基本的なシナリオでさえ、たった一人のプロデューサがいれば、トピックに予期せぬメッセージの連続を得ることができる。
Kafkaトピックの最終結果は、2つのイベントだけが保存され、予期しない順序 2, 1 で表示されます。
考えてみれば、これは Apache Kafka の観点 から見れば正しい順序だ。トピックは情報のログに過ぎず、Apache Kafka は新しいイベントの到着を「感知」したタイミングに応じてメッセージをログに書き込む。これはKafkaのインジェスト時間に基づいており、メッセージが作成された時間(イベント時間)には基づいていません。
アックとリトライ
しかし、すべてが失われたわけではない!プロデュース・ライブラリ(aiokafkaがその一例)を調べれば、メッセージが適切に配信されるようにする方法がある。
まず、上のシナリオのメッセージ 3 の問題を回避するために、適切な 承認 メカニズムを定義することができる。acks` プロデューサ・パラメータを使うと、Apache Kafka からどのようなメッセージ受信の確認が欲しいかを定義できる。
このパラメータを 1 に設定すると、トピック(とパーティション)を担当するプライマリ・ブローカーからの確認応答を確実に受け取ることができる。all` に設定すると、プライマリとレプリカの両方がメッセージを正しく保存している場合にのみ確認応答を受け取れるようになり、プライマリのみがメッセージを受信してレプリカに伝搬する前に失敗する問題を回避できる。
適切なackを設定したら、適切な確認応答を受け取らなかった場合にメッセージの送信をリトライするように設定する。他のライブラリ(kafka-pythonもその一つ)とは異なり、aiokafkaはタイムアウト(request_timeout_msパラメータで設定)を超えるまで自動的にメッセージの送信を再試行する。
acknowledgmentと自動再試行を使えば、メッセージ 3 の問題は解決するはずだ。そのため、retry_backoff_msの間隔の後、プロデューサは再び 3 というメッセージを送信します。
そのため、retry_backoff_ms 間隔の後、メッセージ 3 を再度送信することになる。
フライト中の最大リクエスト数
しかし、Apache Kafkaトピックの最終結果をよく見ると、結果の順序は正しくない。
古い方法(kafka-pythonで利用可能)は、接続ごとの最大飛行中リクエスト数を設定することだった。同時に送信できるメッセージの数が多ければ多いほど、順番が狂ってしまうリスクが高くなる。
kafka-pythonを使用しているとき、トピック内で特定の順序が絶対に必要な場合は、max_in_flight_requests_per_connectionを1に制限せざるを得なかった。基本的に、仮に ack パラメータを最低でも 1 に設定したとすると、次のメッセージを送信する前に、すべてのメッセージ(メッセージのサイズがバッチサイズより小さい場合はメッセージのバッチ)の肯定応答を待つことになる。
順序付け、確認、再試行の絶対的な正しさは、スループットを犠牲にする。同時に "空中に "存在できるメッセージの量が少なければ少ないほど、より多くのacksを受信する必要があり、定義された時間枠内でKafkaに配信できるメッセージ全体の量は少なくなります。
べきプロデューサー
一度に1つのメッセージを送信し、確認応答を待つという厳密なシリアライゼーションを克服するために、idempotent producersを定義することができます。idempotentプロデューサーでは、各メッセージはプロデューサーIDとシリアル番号(パーティションごとに保持されるシーケンス)の両方でラベル付けされます。この構成されたIDは、メッセージと一緒にブローカーに送られます。
ブローカーは、プロデューサーとトピック/パーティションごとに通し番号を管理する。新しいメッセージが到着するたびに、ブローカーは構成されたIDをチェックし、同じプロデューサー内でその値が前の番号+1に等しければ、新しいメッセージは承認され、そうでなければ拒否される。これにより、メッセージのグローバルな順序が保証され、1接続あたりのインフライトリクエストの数を増やすことができます(Javaクライアントでは最大5)。
複数のプロデューサによる複雑性の増大
ここまでは、プロデューサーが1人だけの基本的なシナリオを想像してきたが、Apache Kafkaの現実は、プロデューサーが複数になることが多い。最終的な注文結果を確実にしたいのであれば、どのような細かい点に気をつければいいのだろうか?
異なるロケーション、異なるレイテンシー
繰り返しますが、ネットワークは平等ではありません。そして、複数のプロデューサーがおそらく非常に離れた場所に位置しているため、異なるレイテンシは、Kafkaの順序付けがイベント時間に基づくものと異なる可能性があることを意味します。

残念ながら、地球上の異なる場所間で異なるレイテンシを修正することはできないので、このシナリオを受け入れる必要がある。
バッチング、追加の変数
より高いスループットを達成するために、メッセージをバッチ化 したい場合がある。バッチ処理では、メッセージを "グループ "に分けて送信し、全体的な呼び出し回数を最小化し、全体のメッセージサイズに対するペイロードの比率を高める。しかし、そうすることで、イベントの順序を再び変えることができる。Apache Kafkaのメッセージは、バッチの取り込み時間に応じて、バッチごとに保存される。そのため、メッセージの順序はバッチごとに正しくなるが、異なるバッチではその中で順序が異なるメッセージが存在する可能性がある。

さて、異なるレイテンシーとバッチ処理の両方が存在する場合、グローバルな順序付けの前提は完全に失われてしまうようだ...。では、なぜ私たちはイベントを順番に管理できると主張しているのでしょうか?
救世主:イベント時間
Kafkaがメッセージの順序を保持するという当初の前提が100%正しいわけではないことは理解した。メッセージの順序はKafkaの取り込み時間に依存し、イベントの発生時間に依存しない。しかし、イベント時間に基づく順序付けが重要な場合はどうでしょうか?
プロダクション側でこの問題を解決することはできませんが、コンシューマー側で解決することはできます。Kafka Streams、専用のTimestamp extractorシングルメッセージ変換(SMT)を備えたKafka Connect、Apache Flink®など、Apache Kafkaで動作する最も一般的なツールはすべて、イベント時間として使用するフィールドを定義する機能を持っています。
コンシューマーが適切に定義されていれば、特定のApache Kafkaトピックから送られてくるメッセージの順序を入れ替えることができる。以下、Apache Flinkの例を分析してみよう:
CREATE TABLE CPU_IN (
hostname STRING,
cpu STRING,
usage DOUBLE,
occurred_at BIGINT,
time_ltz AS TO_TIMESTAMP_LTZ(occurred_at, 3),
WATERMARK FOR time_ltz AS time_ltz - INTERVAL '10' SECOND
)
WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = '',
'topic' = 'cpu_load_stats_real',
'value.format' = 'json',
'scan.startup.mode' = 'earliest-offset'
)
上記のApache Flinkのテーブル定義で、次のことに気づく:
- フィールドは Apache Kafka のソーストピックに unix 時間で定義されている(データ型は
BIGINT)。 - time_ltz AS TO_TIMESTAMP_LTZ(occurred_at, 3)`: unix time を Flink のタイムスタンプに変換する。
- WATERMARK FOR time_ltz AS time_ltz - INTERVAL '10' SECOND
: (occurred_atから計算された) 新しいフィールドtime_ltz` をイベント時刻として定義し、イベントの到着が最大 10 秒遅れる閾値を定義する。
上記のテーブルが定義されると、time_ltz フィールドを使用して、イベントを正しく順番に並べ、許容される遅延時間内のすべてのイベントが計算に含まれるようにして、集計ウィンドウを定義することができる。
INTERVAL '10' SECOND` はデータパイプラインのレイテンシを定義するものであり、遅れて到着したイベ ントを正しく取り込むために必要なものである。しかし、スループットには影響がないことに注意してください。パイプラインには望むだけ多くのメッセージを流すことができますが、特定の時間枠内のすべてのイベントを画像に含めることを確認するために、最終的なKPIを計算する前に「10秒待機」しています。
別のアプローチとして、イベントに完全な状態が含まれている場合にのみ機能する、特定のキー(上記の例では、hostnameとcpu)に対して、これまでに到達したイベント時間の最大値を保持し、新しいイベント時間が最大値よりも大きい場合にのみ変更を受け付けるという方法がある。
まとめ
Kafkaにおける順序付けの概念は、1つのパーティションを持つ1つのトピックを含むだけでも厄介なことがある。この投稿では、予期しない一連のイベントを引き起こす可能性のある、いくつかの一般的な状況を共有しました。幸運なことに、飛行中のメッセージ数を制限したり、idempotent producerを使用したりすることで、期待通りの順序付けを実現することができます。
複数のプロデューサーの場合、そしてネットワーク遅延の予測不可能性の場合、利用可能なオプションは、ペイロードで指定される必要があるイベント時間を適切に処理することによって、コンシューマ側で全体的な順序を修正することである。
参考文献