*この記事は2021年9月24日(金)に社内で行ったAnother works LT会のスライドを元に作成しています。

弊社サービス複業クラウドでは全文検索エンジンとして、ElastciSearchを導入しています。
自分はこの知見が乏しかったので今回記事に纏めました!
ElasticSearchとは?

複数のデータベースを横断して検索、なおかつ柔軟な検索をすることが可能になる。
RDBとの比較
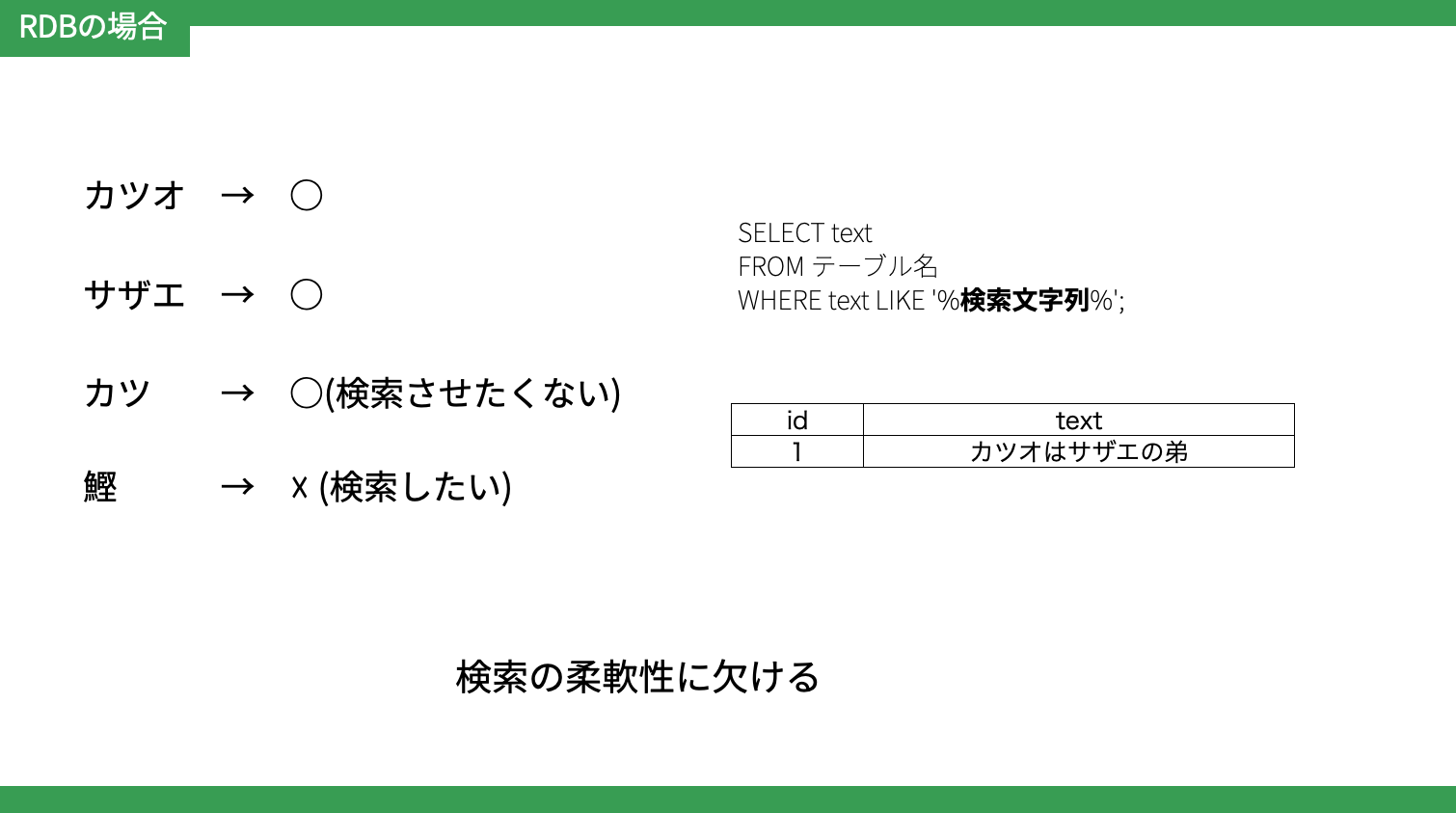
例えば、文章の中でカツオはサザエの弟といった文があったときにRDBで検索することを考えてみます。
検索は以下のSQLで前方一致、後方一致で行います。
SELECT text FROM テーブル名 WHERE text LIKE '%検索文字列%'
すると以下のように本来ヒットさせたくない'カツ'はヒットする。
ヒットさせたい'鰹'はヒットされないといった事案が発生して、検索柔軟性に欠けてしまいます。
■検索文字列
かつお → ヒットする
サザエ → ヒットする
カツ → ヒットする(ヒットさせたくない
鰹 → ヒットしない(ヒットさせたい)
そのためElasticSearchでは柔軟な検索を可能にするために文章を意味のある単語に分割してドキュメント(RDBでいうレコード)に保存させます。
ただ、意味のある単語に分割することは日本語の場合難しいです。
英語の場合は半角スペースなどである程度区切られていますが。
そこで出てくるのが形態素解析やN-gramです。
形態素解析
自然言語で書かれた単語を予め登録された辞書で分割して、品詞などを割り出す方法。
ex)kuromoji、sudachi

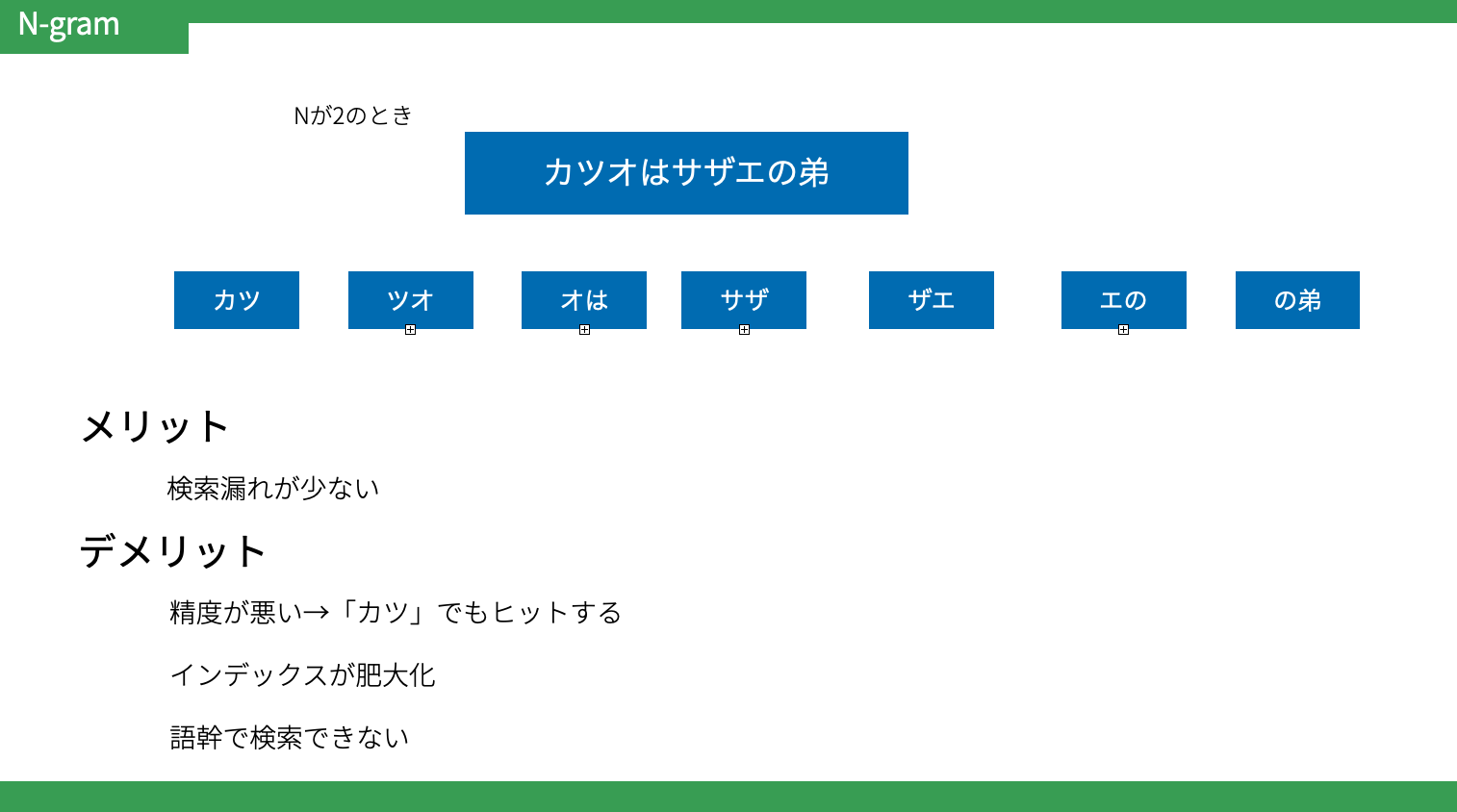
Ngram
N(1以上の数字)文字ずつ文章で区切る方法
検索精度を上げていくには
検索ノイズが少なく、検索漏れが多い形態素解析と検索ノイズが少なく検索漏れが少ないNgramを組み合わせてドキュメントに登録する。
又は単純に形態素解析の辞書の精度を高める方法が考えられるかなと思います。
弊社では後者の方法でで検索精度を高めて行きたいと考えています!

Another worksでは一緒に働ける仲間を探しています