はじめに
みなさんAV観てますか?
今回は、こんな人に向けて記事を作成しました。
「自分のスマホ持ってない。実家に一台のPCしかないから、AV履歴削除めんどくさいなぁ」
「スクレイピング覚えたいけど、やる気がでないんだよなぁ」
そんな悩みを解決します。
では、夢の世界へどうぞ
HTMLの取得
# ライブラリ一覧
import requests #webページを取得するライブラリ
import pandas as pd
from bs4 import BeautifulSoup #取得したHTMLのデータの中から、タグを読み取り、操作できるライブラリ
from IPython.display import HTML
from IPython.display import Image
url = "https://www.dmm.co.jp/digital/videoa/-/ranking/=/term=realtime/" #売れ筋作品ランキング(10分ごとに更新されます)
response = requests.get(url)
response.encoding = response.apparent_encoding #response.apparent_encoding に、正しい文字コードである SHIFT_JISが格納されている(文字化けを防げます)
soup = BeautifulSoup(response.text, "html.parser") #BeautifulSoup(解析対象のHTML/XML, 利用するパーサー(解析器))
# HTMLをインデントできる
print(soup.prettify())

上記の様にHTMLが取得できていることが分かります。
ここから、どのタグ・どの属性を取得するかの方針を立てます。
一筋縄ではいかない部分が多々あるのが、スクレイピングですので、試行錯誤を繰り返していきましょう。
画像を取得(images)
images=[]
for link in soup.find_all("img"): # imgタグを取得しlinkに格納
if link.get("src").endswith(".jpg"): # imgタグ内の.jpgであるsrcタグを取得
images.append(link.get("src")) # imagesリストに格納
以下のような形になります。

リンクを取得(AV_links)
AV_links=[]
tags1=soup.find_all("td", attrs={"class": "bd-b"})
for j,i in enumerate(tags1):
a=i.find("a")
print(a.get('href'))
AV_links.append("https://www.dmm.co.jp"+a.get('href'))
 **https://www.dmm.co.jp**が抜けているので先頭に追加してあげます。
**https://www.dmm.co.jp**が抜けているので先頭に追加してあげます。

動画url(movie_links)
movie_links=[]
for i in AV_links:
a=i.split("/=/")
b=a[0]+'/ajax-movie/=/'+a[1]
movie_links.append(b)
**"/ajax-movie/=/"**を間に追加します。

作品名,順位を取得(titles,ranks)
import re
titles=[]
ranks=[]
tags2=soup.find_all("td", attrs={"class": "bd-b"})
for j,i in enumerate(tags2):
ranks.append(j)
tmp=i.find("p")
tmp1=tmp.text
a=re.sub("【[^】]+】","",tmp1)
titles.append(a)

女優名を取得(names)
names_contents=[]
tags1=soup.find_all("div",class_="data")
for i in tags1:
a=i.text
names_contents.append(a)

**----**と表示されているところは女優名が書いておらず、複数人で出演していました。
names=[]
for i in names_contents:
q=i.split("出演者:")
if q[-1]=="----":
names.append("複数人")
else:
names.append(q[-1])

パケ写(real_images)
real_images=[]
for j,i in enumerate(images):
real_images.append(Image(images[j]))

データフレーム作成
columns={"順位":ranks,"女優名":names,"タイトル名":titles,"画像url":images,"AVurl":AV_links,"動画":movie_links,"パケ写":real_images}
df=pd.DataFrame(columns)

結果は!?
HTML(df["AVurl"][0])
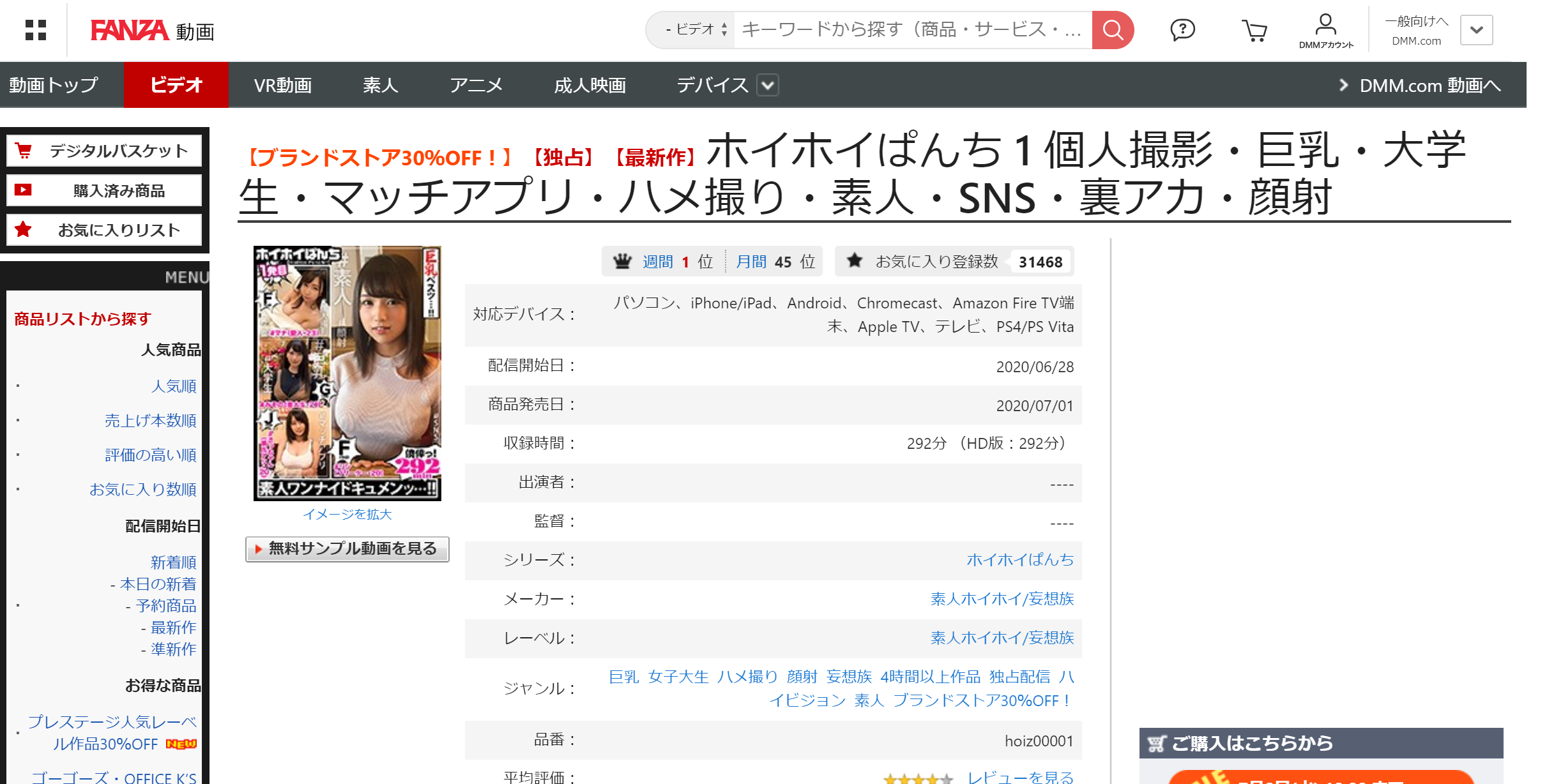
HTML(df["動画"][0])

上記の様に履歴を残さず、データフレームから値を取得するだけでAV鑑賞が出来ますね!
実家にPCが1台しかない人は、
①jupyterの環境を整える
②python覚える
この2点を学習すれば、履歴の消し忘れもないので安心して見れますね。