こんばんは。
今回は(何番煎じかはわかりませんが)高精細出力すぎるで有名なStyleGAN2を使ってアニメ(風)キャラの生成を試してみました。
画像生成を簡単に試せる**Make AnimeFace**を公開しました。ぜひお試しください。
追記(6/23):システム改組のため一時停止しています。AniAutoとして再公開予定。
追記(8/1):Pixivにサンプル公開しました。
※この記事では「試す」事が趣旨のため、実際にPythonでコードを書いたりといった本格的な実装は行いません。その辺のご理解をよろしくおねがいします。
StyleGANの凄さやディープラーニングではこんなことができるよっていうGANに関する簡単な概念及び全体像を把握していただければ幸いです。
はじめにGANとStyleGANの概念的なものを(この記事で書くかは迷いましたが)ざっとご紹介します。とりあえず結果を見せろって方はWhat's~をスキップしてください。
わかりやすいように数式や専門用語等を極力控えて説明しているため本質的な理解にはならないかもしれませんがご了承ください。
What's GAN?
GANとは敵対的生成ネットワークの略称でいわゆる人工知能のアルゴリズムの一つです。
互いに競合し合う2つのニューラルネットワークにより実装されており、画像生成を例とするとニセ画像を生成するGenerator(生成器)とそれがニセモノかどうか判断するDiscriminator(識別器)の2種類が互いに勝負することで生成の精度を高くしていくっていう認識を持っていただければ大丈夫です。
よくGANにおけるGeneratorとDiscriminatorは「本当っぽい嘘をつく不審者」と「その嘘を見破ろうとする警察官」の関係にあると例えられますよね。(個人的には被疑者と検察の取り調べで例えてました)
それからGANについての研究が進められDCGAN,GCGAN,W-GANといったより精度の高い派生が多く生まれてきました。
特にDCGANは学習をCNN(畳み込みニューラルネットワーク)を使うことで有名だと思います。私も以前DCGANを使って実装してみたことがあります。(隙きあらば自分語り)
What's StyleGAN2?
StyleGAN2を一言で説明すると「超高画質なGANの一種であるStyleGANの改良版だよ」です。
↓がStyleGAN2で生成した画像です。

当たり前ですが誰が撮ったものでもないし画像の中の人は実在しません。
StyleGANの長所はなんと言っても超高画質ってことです。上記画像は1024ピクセルです。すごい…!
私もPytorchを使ってDCGANで画像生成をやってみたことがあるのですが個人のパソコンで学習させるのはせいぜい縦横128ピクセルでの生成が限界でした。(もっとがんばれたかもしれませんが如何せんGPUの性能もあるしデータセットの準備もあるしできつかった記憶があります。)
StyleGANはNVIDIAが開発したものです。GeForceやQuadroを長年手がけてるいわばGPUの超プロフェッショナルであるNVIDIAなら納得できます。
**PGGAN(Progressive Growing of GANs)**からインスピレーションを受けており、一気に高画質画像を生成するのではなく、低画質からだんだんと(漸近的に)高画質に成長させていくという特徴があります。
つまり一旦初期の低解像度生成のときに輪郭と言った大まかな特徴を再現し、後の高解像度生成のときに目や口と言った細かな特徴を再現することで非常に質の高い生成ができます。
AdaINが~とか、もっと細かくStyleGANについてかければいいんですけどこれを言い出したらきりがないのであとはリポジトリや論文を見てください(放棄)それかググれ。
GANは本当にいろんな派生がありますので、それぞれのアーキテクチャを見てみると結構面白いですよ!
【GitHub】https://github.com/NVlabs/stylegan2
【論文】https://arxiv.org/abs/1912.04958
実際に試す。
話は長くなりましたが本題です。実際にやってみましょう。
環境構築
動作環境
StyleGAN2は一応去年に流行ったやつなんで環境も去年と同じにしないといけません(´・ω・`)
以下がソフトウェアの動作要件です。
- Python 3.7
- CUDA ToolKit 10.0
- cuDNN 7.4
- Tensorflow 1.14
はい。確かに一年前ですね。Tensorflow1.14以上(2.x系)が使えないため、pipでのインストール等々の関係のせいでPython3.7以降も使えません。めんどくさいなぁ…
Tensorflowインストール
Tensorflow1.14をインストールする詳しいやり方は以下の私の記事を参考にしてください。
https://0115765.com/archives/1064
ここでは大まかに書きます。
※Linux+Dockerのほうがいいらしいですが今回は都合上Windowsでやってみます。
Python 3.7.9をダウンロード(直リン)してインストールしてください。
次にCUDAを10.0をダウンロードしてインストールしてください。
cuDNN7.4は公式サイトからダウンロードできますがNVIDIA Developerアカウントが要ります。適宜取ってください。
DLしたらフォルダ内部すべてをC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0へ移動&以下のように環境変数を追加してください。
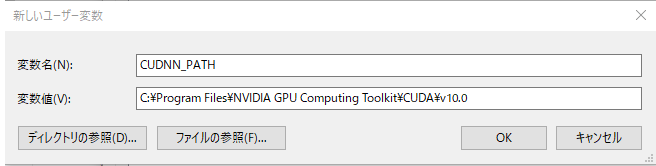
最後にpipでTensorflowインストールしましょう。
pip install -U pip setuptools
pip install -U tensorflow-gpu==1.14 tensorflow_datasets
これでおkです。
動作確認
Pythonのインタラクティブシェルで以下を入力。
import tensorflow as tf; print( tf.__version__ )でバージョン確認。
from tensorflow.python.client import device_lib; print(device_lib.list_local_devices())でCUDAをが動くか確認。
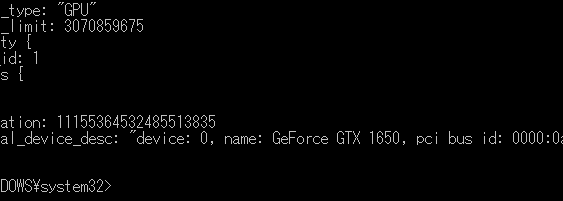
問題なければおkです。
いろいろDL
さっきも書いたんですけど高画質で出力可能が故に学習の際にとんでもない時間とリソースがかかります。なので今回は予め大量のアニメ画像で学習したトレーニング済みのファイルを公開している聖人がいるのでそこからダウンロードしまて使用します。
紹介ページ | ダウンロードリンク(mega.nz)
あといちばん大事なStyleGANをクローンしてください。(あと、さっきDLしたpklファイルも入れてください)
git clone https://github.com/NVlabs/stylegan2
cl.exeのやつ。
StyleGAN2を動かすにはVisual C++のコンパイラが必要です
なのでVisual Studio 2017でC++をの開発環境をインストールしてください。2019じゃないです2017です!(怒)
2019だと以下のエラーが出ます。めんどくせぇ…
host_config.h(143): fatal error C1189: #error: -- unsupported Microsoft Visual Studio version! Only the versions between 2013 and 2017 (inclusive) are supported!
インストールが終わったらあとはパスを通すだけ。
人により違うと思うんですけど私はC:/Program Files (x86)/Microsoft Visual Studio/2019/Community/VC/Tools/MSVC/14.23.28105/bin/Hostx64/x64にcl.exeにありました。
これでコンパイラが使えたのでclを入力してチェック。
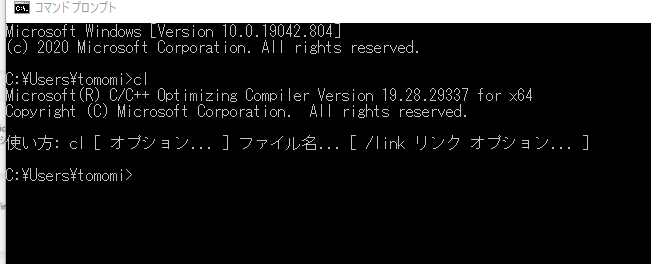
おkならstylegan2/dnnlib/tflib/custom_ops.py内のsompiler_bindir_search_pathにさっきのcl.exeのあるディレクトリのフルパスをコピー。

これで完了です。
実践
いざやってみます。
さっきクローンしたフォルダ内にあるrun_generator.pyがpkl形式の学習済みモデルをもとに画像を生成するためのPythonファイルです。
StyleGANのディレクトリでコマンドプロンプトを起動し、以下を入力。
python run_generator.py generate-images --network=<pklファイル> --seeds=6600-6625
重要なパラメータは以下の通り。
-
--seeds→生成するシード値的なやつ。(ex.6000-6025にしたら26件生成されます。135,541,654にしたら該当シード値の画像3枚分が生成されます。) -
--network→学習済みモデルの参照。
結果
今回はシード値4000~4200の201件ほど生成してみました。
結果は以下のGitのrepoに上げてます。
https://github.com/tomomi0115/stylegan2-generated-image
その中からできが良いやつをご紹介します。
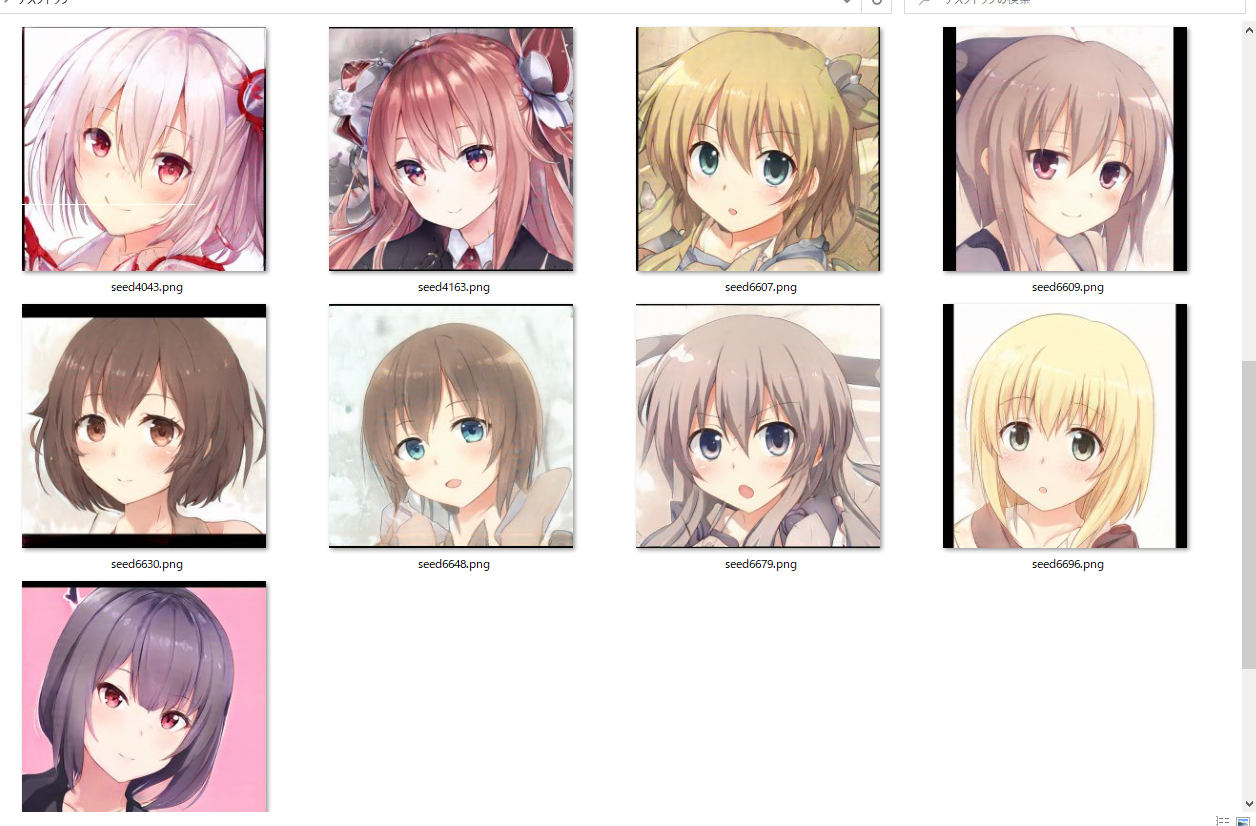
画像サイズは512ピクセルです。因みに左上のやつはTwitter@ichii731のアイコンでした。
おわりに
今回は一応コードを書いてるわけじゃないんですけど画像を生成してみました。
なんか今更気づいたんですけどPytorch版もあるらしいので私はそれで実装してみたいと思います。
参考になれば幸いです。。。