はじめに
Logstashの設定ファイル関連で調査したことのメモ書きです。
<環境>
RHEL V7.5
Logstash V7.5.2
参考: Logstashの実践的な説明
関連記事
Logstashメモ - (1)インストール/簡易操作
Logstashメモ - (2) 設定ファイル関連
Logstash起動時の指定
参考: Running Logstash from the Command Line
デフォルトだとlogstashコマンドは/usr/share/logstash/bin/logstashに展開されている。
Single Pipeline
-fオプションで、設定ファイルもしくは、設定ファイルを配置しているディレクトリを指定
/usr/share/logstash/bin/logstash -f test01.conf
-f, --path.config CONFIG_PATH
Load the Logstash config from a specific file or directory. If a directory is given, all files in that directory will be concatenated in lexicographical order and then parsed as a single config file.
ディレクトリを指定した場合、配下の全ファイルを辞書順にマージして読み込まれます。
Multiple Pipelines
特定のディレクトリ下(ここでは/etc/logstash/test01/)に、pipelines.ymlというファイルを用意します(ファイル名は固定)。
- pipeline.id: my-pipeline_1
path.config: "/etc/logstash/test01/conf01.d"
pipeline.workers: 3
- pipeline.id: my-pipeline_2
path.config: "/etc/logstash/test01/conf02.d"
pipelines.ymlファイルでは、上の例のように、複数の設定ファイル(もしくは設定ファイル配置ディレクトリ)をpath.configで指定できます。それぞれが別のパイプラインとして動作します。
(各path.configの指定はSingle Pipelineと同様)
このpipelines.ymlを読み込ませて実行させる場合は、--path.settingオプションでpipelines.ymlファイルが配置されているディレクトリを指定します。
/usr/share/logstash/bin/logstash --path.settings /etc/logstash/test01
設定ファイル
input plugin
stdin
logstash起動シェルの標準入力からデータを受け取ります。主にテスト用として利用します。
input {
stdin { }
}
file
ファイルに書かれたデータを入力とします。
input{
file{
path => ["/root/logstash/data/test02*.csv"]
start_position => "beginning"
sincedb_path => "/root/logstash/data/test02.sincedb"
}
}
デフォルトでは、"Tail mode"と呼ばれるモードでファイルの読み取りを行います。これは、指定されたpath(ファイル/ディレクトリの指定が可)に合致するファイルにデータがAppendされることを想定したモードです。
各ファイルについて、Logstashがどこまでデータを読んだかの情報をトラッキングしておき、追記された部分のみを読みとるようになっています。
"Read mode"と呼ばれるモードを使用することもでき、その場合ターゲットとなるファイルは追記されるものではなく完結している想定となります。modeオプションで切り替えることができます。
tcp
参考: Tcp input plugin
TCPでリクエストを受け付けます。Logstashが特定のポートをListenしてコネクションを受け付けます。
input{
tcp{
port => 8081
}
}
filter plugin
csv
CSVのデータを解釈してくれます。(カンマ以外のセパレーターも指定可能)
以下の設定ファイルで試してみます。
シンプルケース
input {
stdin { }
}
filter {
csv{
columns => ["field01","field02","field03"]
}
}
output {
stdout{ }
}
aaa,bbb,ccc
{
"host" => "test08",
"@version" => "1",
"field02" => "bbb",
"message" => "aaa,bbb,ccc",
"@timestamp" => 2020-02-04T08:38:22.522Z,
"field01" => "aaa",
"field03" => "ccc"
}
1行目が標準入力から投入したCSVのデータで、2行目移行が、csv filterで解釈された結果です。
111,222,333
{
"host" => "test08",
"@version" => "1",
"field02" => "222",
"message" => "111,222,333",
"@timestamp" => 2020-02-04T08:42:30.950Z,
"field01" => "111",
"field03" => "333"
}
数値を入れてもダブルクォーテーションで括られる、すなわち、文字列として判断されます。
aaa,bbb
{
"host" => "test08",
"@version" => "1",
"field02" => "bbb",
"message" => "aaa,bbb",
"@timestamp" => 2020-02-04T08:53:20.286Z,
"field01" => "aaa"
}
aaa,bbb,ccc,ddd
{
"host" => "test08",
"@version" => "1",
"field02" => "bbb",
"column4" => "ddd",
"message" => "aaa,bbb,ccc,ddd",
"@timestamp" => 2020-02-04T08:53:33.203Z,
"field01" => "aaa",
"field03" => "ccc"
}
フィールド数が少ない場合、field03は無しとなります。数が多い場合は、"column4"というように名前が動的に付けられます。
型指定
参考: convert
デフォルトでは分割されたフィールドはダブルクォーテーションで括られます。すなわち文字列として判断されますが、フィールド単位に型を指定することもできます。
input{
stdin { }
}
filter {
csv{
columns => ["field01","field02","field03"]
convert => { "field02" => "integer"
"field03" => "float"
}
}
}
output {
stdout{ }
}
field02は整数、field03は浮動小数点として変換するよう定義しています。
aaa,111,23.4
{
"@version" => "1",
"@timestamp" => 2020-02-04T09:11:21.221Z,
"field01" => "aaa",
"host" => "test08",
"field02" => 111,
"field03" => 23.4,
"message" => "aaa,111,23.4"
}
field02, field03の値はダブルクォーテーションでくくられていないので、数値としてハンドリングされていることが分かります。
aaa,-111,-23.4
{
"@version" => "1",
"@timestamp" => 2020-02-04T09:11:50.488Z,
"field01" => "aaa",
"host" => "test08",
"field02" => -111,
"field03" => -23.4,
"message" => "aaa,-111,-23.4"
}
負の数もOK
aaa,111,-234E-05
{
"@version" => "1",
"@timestamp" => 2020-02-04T09:12:41.171Z,
"field01" => "aaa",
"host" => "test08",
"field02" => 111,
"field03" => -0.00234,
"message" => "aaa,111,-234E-05"
}
指数表記もOK
aaa,bbb,ccc
{
"@version" => "1",
"@timestamp" => 2020-02-04T09:17:22.312Z,
"field01" => "aaa",
"host" => "test08",
"field02" => "bbb",
"field03" => "ccc",
"message" => "aaa,bbb,ccc"
}
field02, field03に数値以外の文字列指定したら、文字列のままとなりました。
aaa,23.4,555
{
"@version" => "1",
"@timestamp" => 2020-02-04T09:29:49.781Z,
"field01" => "aaa",
"host" => "test08",
"field02" => "23.4",
"field03" => 555.0,
"message" => "aaa,23.4,555"
}
field02に少数の値を設定すると文字列のままとなりました。
aaa,111,999E999
{
"@version" => "1",
"@timestamp" => 2020-02-04T09:27:38.266Z,
"field01" => "aaa",
"host" => "test08",
"field02" => 111,
"field03" => Infinity,
"message" => "aaa,111,999E999"
}
field03に大きい値を入れるとInfinityとなりました。(floatで扱える範囲についての記述が見つけられなかった...)
ruby
参考:
Ruby filter plugin
Event API
Moving Custom Ruby Code out of the Logstash Pipeline
Ruby入門
rubyのコードを埋め込んで、ロジックを組み込むことが可能です。そのコードの中ではEvent APIを使うことでLogstash上を流れるフィールド情報をハンドリングすることができます。
ここでは、既存のフィールドを加工して新たなフィールドを作成する、という辺りを中心にやってみます。
フィールドコピー
※単純なフィールドコピーは後述のmutateというフィルターでも実現できますが、ここではrubyの使い方の理解のために作っています。
input {
stdin { }
}
filter {
csv{
columns => ["field01","field02","field03"]
}
ruby {
code => "event.set('[field04]', event.get('[field03]'))"
}
}
output {
stdout{ }
}
単純に、field03と同じ内容でfield04というのを新たに作成します。
event.set / event.get というメソッドで、各フィールドの値を扱えます。フィールドの参照は、'[<fieldname>]'という形式で行えます。
aaa,bbb,ccc
{
"@version" => "1",
"field02" => "bbb",
"field04" => "ccc",
"field03" => "ccc",
"host" => "test08",
"field01" => "aaa",
"message" => "aaa,bbb,ccc",
"@timestamp" => 2020-02-04T09:38:31.230Z
}
field03と同じ値のfield04が作成されています。
aaa,bbb
{
"@version" => "1",
"field02" => "bbb",
"field04" => nil,
"host" => "test08",
"field01" => "aaa",
"message" => "aaa,bbb",
"@timestamp" => 2020-02-04T09:38:50.565Z
}
field03が無いので、field04はnilとなっています。event.getの結果がnilになるので。
フィールドコピー2(nil判定あり)
コピー元のフィールドが存在する場合のみ、そのフィールドをコピーして新たなフィールドを追加する、というロジックを追加してみます。
input {
stdin { }
}
filter {
csv{
columns => ["field01","field02","field03"]
}
ruby {
code => "
if !event.get('[field03]').nil? then
event.set('[field04]', event.get('[field03]'))
end
"
}
}
output {
stdout{ }
}
aaa,bbb,ccc
{
"message" => "aaa,bbb,ccc",
"@timestamp" => 2020-02-04T10:47:51.417Z,
"field04" => "ccc",
"field01" => "aaa",
"field03" => "ccc",
"host" => "test08",
"field02" => "bbb",
"@version" => "1"
}
こちらは先の例と同じく、field03と同じ内容のfield04が追加されます。
aaa,bbb
{
"message" => "aaa,bbb",
"@timestamp" => 2020-02-04T10:47:55.649Z,
"field01" => "aaa",
"host" => "test08",
"field02" => "bbb",
"@version" => "1"
}
こちらはfield03が存在しないケース。この場合、field04も作成されません。
Rubyコードの汎用化/外出し
参考: Moving Custom Ruby Code out of the Logstash Pipeline
特定のフィールドをコピーして別の名前のフィールドとして作成する、というコードを別のファイルとして作成し、対象のフィールド名を変数にして汎用化してみます。
汎用化したRubyコードを別ファイルとして作成します。コピー元のフィールド名と、コピー先のフィールド名を引数で受け取るようにしています。
def register(params)
@source_field = params["source_field"]
@target_field = params["target_field"]
end
def filter(event)
if !event.get("[#{@source_field}]").nil? then
event.set("[#{@target_field}]", event.get("[#{@source_field}]"))
end
return [event]
end
上のRubyコードを呼び出すように、Logstashの設定ファイルを記述します。この時、引数でコピー元/先のフィールド名を指定します。
input {
stdin { }
}
filter {
csv{
columns => ["field01","field02","field03"]
}
ruby {
path => "/root/logstash/field_copy.rb"
script_params => {
"source_field" => "field03"
"target_field" => "field04"
}
}
}
output {
stdout{ }
}
aaa,bbb,ccc
{
"field03" => "ccc",
"@timestamp" => 2020-02-04T11:22:26.120Z,
"field02" => "bbb",
"@version" => "1",
"field01" => "aaa",
"field04" => "ccc",
"message" => "aaa,bbb,ccc",
"host" => "test08"
}
aaa,bbb
{
"@timestamp" => 2020-02-04T11:19:15.167Z,
"field02" => "bbb",
"@version" => "1",
"field01" => "aaa",
"message" => "aaa,bbb",
"host" => "test08"
}
やっている内容は先の例と同じなので、結果は同様。
2つのフィールドを足し算して新たなフィールドを作成
参考: instance method String#to_f
数値フィールド前提の2つの値を足し算して、結果を新たなフィールドとして追加します。
Rubyコードを作成します。
def register(params)
@source_field1 = params["source_field1"]
@source_field2 = params["source_field2"]
@target_field = params["target_field"]
end
def filter(event)
if !event.get("[#{@source_field1}]").nil? && !event.get("[#{@source_field2}]").nil? then
source_value1 = event.get("[#{@source_field1}]").to_f
source_value2 = event.get("[#{@source_field2}]").to_f
target_value = source_value1 + source_value2
event.set("[#{@target_field}]", target_value)
end
return [event]
end
source_field1, source_field2を引数で受け取って、それらの値をfloat型に変換し、足し算します。結果はtarget_fieldで受け取った名前のフィールドにセットします。
これを呼び出すLogstash設定ファイルを作成します。
input {
stdin { }
}
filter {
csv{
columns => ["field01","field02","field03"]
}
ruby {
path => "/root/logstash/field_add.rb"
script_params => {
"source_field1" => "field02"
"source_field2" => "field03"
"target_field" => "field04"
}
}
}
output {
stdout{ }
}
field02 + field03の結果を、新しくfield04という名前のフィールドにセットするようにしています。
aaa,123,456
{
"@version" => "1",
"field01" => "aaa",
"field03" => "456",
"message" => "aaa,123,456",
"field02" => "123",
"@timestamp" => 2020-02-04T11:41:07.299Z,
"field04" => 579.0,
"host" => "test08"
}
123 + 456 の結果 579がfield04にセットされました。
aaa,55.5,-11.1
{
"@version" => "1",
"field01" => "aaa",
"field03" => "-11.1",
"message" => "aaa,55.5,-11.1",
"field02" => "55.5",
"@timestamp" => 2020-02-04T11:42:02.522Z,
"field04" => 44.4,
"host" => "test08"
}
マイナスもOK
aaa,555E-01,-111E-01
{
"@version" => "1",
"field01" => "aaa",
"field03" => "-111E-01",
"message" => "aaa,555E-01,-111E-01",
"field02" => "555E-01",
"@timestamp" => 2020-02-04T11:42:51.915Z,
"field04" => 44.4,
"host" => "test08"
}
指数表記もOK
aaa,bbb,111
{
"@version" => "1",
"field01" => "aaa",
"field03" => "111",
"message" => "aaa,bbb,111",
"field02" => "bbb",
"@timestamp" => 2020-02-04T11:43:36.473Z,
"field04" => 111.0,
"host" => "test08"
}
数値以外を指定した場合はto_f関数では0と判断されるらしい。
設定ファイルを以下のように書き換えて、field02 + field03 の結果を、field02に上書きしてみます。
input {
stdin { }
}
filter {
csv{
columns => ["field01","field02","field03"]
}
ruby {
path => "/root/logstash/field_add.rb"
script_params => {
"source_field1" => "field02"
"source_field2" => "field03"
"target_field" => "field02"
}
}
}
output {
stdout{ }
}
aaa,111,222
{
"@version" => "1",
"message" => "aaa,111,222",
"field02" => 333.0,
"@timestamp" => 2020-02-05T05:57:23.579Z,
"field01" => "aaa",
"field03" => "222",
"host" => "test08"
}
field02の値が上書きされました。
2つのフィールドに対して四則演算を行う
上の例をさらに汎用化して、2つのフィールドと演算子を与えることで、指定した計算を行わせるようにしてみます。
四則演算用のRubyコードを用意します(足算、引算、掛算、割算、パーセンテージの5つの演算を含む)。
def register(params)
@source_field1 = params["source_field1"]
@source_field2 = params["source_field2"]
@target_field = params["target_field"]
@operator = params["operator"]
end
def filter(event)
if !event.get("[#{@source_field1}]").nil? && !event.get("[#{@source_field2}]").nil? then
source_value1 = event.get("[#{@source_field1}]").to_f
source_value2 = event.get("[#{@source_field2}]").to_f
case @operator
when "add" then
target_value = source_value1 + source_value2
event.set("[#{@target_field}]", target_value)
when "sub" then
target_value = source_value1 - source_value2
event.set("[#{@target_field}]", target_value)
when "mul" then
target_value = source_value1 * source_value2
event.set("[#{@target_field}]", target_value)
when "div" then
target_value = source_value1 / source_value2
event.set("[#{@target_field}]", target_value)
when "per" then
target_value = (source_value1 / source_value2) * 100
event.set("[#{@target_field}]", target_value)
else
# do nothing
end
end
return [event]
end
これを呼び出すLogstash設定ファイルを作成します。
input {
stdin { }
}
filter {
csv{
columns => ["field01","field02","field03"]
}
ruby {
path => "/root/logstash/field_calculation.rb"
script_params => {
"source_field1" => "field02"
"source_field2" => "field03"
"target_field" => "field_add"
"operator" => "add"
}
}
ruby {
path => "/root/logstash/field_calculation.rb"
script_params => {
"source_field1" => "field02"
"source_field2" => "field03"
"target_field" => "field_sub"
"operator" => "sub"
}
}
ruby {
path => "/root/logstash/field_calculation.rb"
script_params => {
"source_field1" => "field02"
"source_field2" => "field03"
"target_field" => "field_mul"
"operator" => "mul"
}
}
ruby {
path => "/root/logstash/field_calculation.rb"
script_params => {
"source_field1" => "field02"
"source_field2" => "field03"
"target_field" => "field_div"
"operator" => "div"
}
}
ruby {
path => "/root/logstash/field_calculation.rb"
script_params => {
"source_field1" => "field02"
"source_field2" => "field03"
"target_field" => "field_per"
"operator" => "per"
}
}
}
output {
stdout{ }
}
field02,field03の足算、引算、掛算、割算の結果をそれぞれfield_add, field_sub, field_mul, field_divというフィールドに追加します。
aaa,111,222
{
"field_mul" => 24642.0,
"@version" => "1",
"field_sub" => -111.0,
"field02" => "111",
"message" => "aaa,111,222",
"host" => "test08",
"field01" => "aaa",
"field_div" => 0.5,
"@timestamp" => 2020-02-10T06:22:37.380Z,
"field_add" => 333.0,
"field_per" => 50.0,
"field03" => "222"
}
意図した通りにフィールドが追加されました。
aaa,111
{
"@version" => "1",
"host" => "test08",
"@timestamp" => 2020-02-05T06:12:49.750Z,
"field02" => "111",
"field01" => "aaa",
"message" => "aaa,111"
}
元になるフィールドが無い場合は処理されません。
aaa,111,0
{
"field_mul" => 0.0,
"@version" => "1",
"field_sub" => 111.0,
"field02" => "111",
"message" => "aaa,111,0",
"host" => "test08",
"field01" => "aaa",
"field_div" => Infinity,
"@timestamp" => 2020-02-10T06:26:21.538Z,
"field_add" => 111.0,
"field_per" => Infinity,
"field03" => "0"
}
0割すると"inifinity"となりました(エラーにはならないようです)。
mutate
参考: Mutate filter plugin
フィールドの加工が行えます。フィールドをコピーしたり分割したりマージしたり...
add_field
ここでは、日付と時刻が別フィールドに分かれて保持されているという想定で、それを1つのフィールドにまとめてみます。
field01に日付、field02に時刻が保持される想定で、それらをブランク区切りでつなげて、my_timestamp_strというフィールドに格納します。
input {
stdin { }
}
filter {
csv{
columns => ["field01","field02","field03"]
}
mutate{ add_field => {
"[my_timestamp_str]" => "%{field01} %{field02}"
}
}
}
output {
stdout{ }
}
2020-01-02,08:00:00:00,aaa
{
"field01" => "2020-01-02",
"field03" => "aaa",
"field02" => "08:00:00:00",
"host" => "test08",
"message" => "2020-01-02,08:00:00:00,aaa",
"@version" => "1",
"my_timestamp_str" => "2020-01-02 08:00:00:00",
"@timestamp" => 2020-02-05T23:42:51.626Z
my_timestamp_strに、"2020-01-02 08:00:00:00"という文字列が格納されました。
date
各レコードにはタイムスタンプ情報が付きますが、デフォルトではそのレコードがLogstash上に取り込まれた時刻がそのレコードのタイムスタンプとなります(Logstash上@timestampというフィールドに保持)。
取り込まれたタイミングとそのレコードが発生したタイミングが異なるケースもあり、レコード上に保持されている日時情報をそのレコードのタイムスタンプとして認識させたい場合は多々あります。
date filter pluginを使うことで、各レコードのフィールドのデータをタイムスタンプとして認識させることができます。
シンプルケース
上のmutateのシナリオに続けて、日付+時刻をマージしたmy_timestamp_strフィールドをタイムスタンプとして認識させてみます。
input {
stdin { }
}
filter {
csv{
columns => ["field01","field02","field03"]
}
mutate{ add_field => {
"[my_timestamp_str]" => "%{field01} %{field02}"
}
}
date{ match => [
"[my_timestamp_str]", "yyyy-MM-dd HH:mm:ss:SS"
]
}
}
output {
stdout{ }
}
2020-01-02,08:00:00:00,aaa
{
"@version" => "1",
"message" => "2020-01-02,08:00:00:00,aaa",
"field03" => "aaa",
"field01" => "2020-01-02",
"@timestamp" => 2020-01-01T23:00:00.000Z,
"field02" => "08:00:00:00",
"host" => "test08",
"my_timestamp_str" => "2020-01-02 08:00:00:00"
1カラム目(field01)と2カラム目(field02)の情報を元に、@timestamp情報が置き換わりました。ここで注意が必要なのは、@timestampは内部的にはUTCで情報が保持されるということです。今回、Logstashが稼働しているLinuxのタイムゾーンはJSTになっているので、与えられた日時の文字列"2020-01-02 08:00:00:00"を日本時間の1月2日8:00として認識し、それをUTCに置き換えたため、@timestampには9時間ずれた 1月1日23:00が設定されています。
timezone指定
上のように、デフォルトだとLogstashの稼働環境に依存して時刻情報の判断が行われるようです。
参考: date - timezone
Specify a time zone canonical ID to be used for date parsing. The valid IDs are listed on the Joda.org available time zones page. This is useful in case the time zone cannot be extracted from the value, and is not the platform default. If this is not specified the platform default will be used.
例えば、以下のように敢えて日本ではなく"Americ/Los_Angeles"のタイムゾーンを指定してみます。
input {
stdin { }
}
filter {
csv{
columns => ["field01","field02","field03"]
}
mutate{ add_field => {
"[my_timestamp_str]" => "%{field01} %{field02}"
}
}
date{ match => [
"[my_timestamp_str]", "yyyy-MM-dd HH:mm:ss:SS"
]
timezone => "America/Los_Angeles"
}
}
output {
stdout{ }
}
この設定で上と同じシナリオを試すと...
2020-01-02,08:00:00:00,aaa
{
"@timestamp" => 2020-01-02T16:00:00.000Z,
"field01" => "2020-01-02",
"field02" => "08:00:00:00",
"my_timestamp_str" => "2020-01-02 08:00:00:00",
"host" => "test08",
"@version" => "1",
"field03" => "aaa",
"message" => "2020-01-02,08:00:00:00,aaa"
}
1月2日8:00の情報がUS時間として認識され、@timestamp上は1月2日16:00(UTC)で保持されました。
日本のタイムゾーンを明示的に指定したい場合は、timezone => "Asia/Tokeyo"を指定すればOKです。
output plugin
stdout
データ送信先をLogstash起動シェルの標準出力にします。主にテスト用で使われます。
codecで出力形式を設定できますが、デフォルトだとrubydebugという形式になります。
output {
stdout{ }
}
json形式での出力の場合以下のように指定します。
output {
stdout { codec => json }
}
elasticsearch
参考: Elasticsearch output plugin
Indexのタイムゾーン
Elasticsearchにデータを送信します。インデックス名の加工(日付情報を付与したり)がよく行われます。
output {
elasticsearch {
hosts => ["http://localhost:9200"]
action => "index"
index => "test-%{+yyyyMMdd}"
}
}
ここで参照されるyyyyMMddは、UTCベースとなっているので、日本時間だと9時間ずれます。従って、以下の記事にある対応をするのが望ましいです。
参考: Elasticsearchのタイムゾーン問題
ただし、このリンク先の対応では、localtimeというメソッドでローカルのタイムスタンプに変換していいます。これはすなわちLogstash稼働環境のタイムゾーンに依存します。稼働環境とは異なるタイムゾーンを明示的に指定するには、動的に環境変数を上書きするコード(ENV['TZ'] = 'Asia/Tokyo')を追加すればよさそうです。
参考: 任意のタイムゾーンで出力する方法
...
filter {
ruby {
code => "ENV['TZ'] = 'Asia/Tokyo'
event.set('[@metadata][local_time]',event.get('[@timestamp]').time.localtime.strftime('%Y%m%d'))"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
action => "index"
index => "test-%{[@metadata][local_time]}"
}
}
同一キーでのデータの結合/更新
デフォルトでは、LogstashからElasticsearchに投入されるeventはそれぞれ別のレコードとして保持されることになりますが、特定のフィールドをキーとして同一キーのものを更新したりフィールド追加するというようなことができます。
例えばelasticsearchプラグインのパラメータで以下のような指定をすると、field01の値に同一のものが無ければ新規にレコードが追加されますが、無ければ既存のレコードが更新されます。
action => "update"
doc_as_upsert => true
document_id => "%{field01}"
input{
stdin {}
}
filter {
json { source => "message" }
}
output {
elasticsearch {
hosts => [ "localhost" ]
action => "update"
index => "test12-01-%{+yyyyMMdd}"
doc_as_upsert => true
document_id => "%{field01}"
}
}
この設定で起動したLogstashに、標準入力から以下のJSONを投入してみます。
{"field01":"aaa","field02":"bbb","field03":"ccc"}
最初のレコードなので普通に追加されます。投入された結果はこうなります(Kibana-Discoverで確認)。

次に、同じfield01の値を含む以下のJSONを投入してみます。(field03の値を変更)
{"field01":"aaa","field02":"bbb","field03":"ddd"}

レコードは追加されず、field03の値が変更されました(タイムスタンプも更新されてます)
以下のJSONを投入してみます。(filed02に異なる値を指定、field03無し、新たにfield04追加)
{"field01":"aaa","field02":"bbb222","field04":111}

field02は更新され、field03は前の値がそのまま残り、field04が新たに追加されました。
さらに、以下のJSONを投入してみます。(filed04に異なる型のデータを投入)
{"field01":"aaa","field04":"xxx"}
これは以下のようなエラーで失敗しました。
[WARN ] 2020-04-28 09:14:00.640 [[main]>worker1] elasticsearch - Could not index event to Elasticsearch. {:status=>400, :action=>["update", {:_id=>"aaa", :_index=>"test12-01-20200428", :routing=>nil, :_type=>"_doc", :retry_on_conflict=>1}, #<LogStash::Event:0x477f4ef2>], :response=>{"update"=>{"_index"=>"test12-01-20200428", "_type"=>"_doc", "_id"=>"aaa", "status"=>400, "error"=>{"type"=>"mapper_parsing_exception", "reason"=>"failed to parse field [field04] of type [long] in document with id 'aaa'. Preview of field's value: 'xxx'", "caused_by"=>{"type"=>"illegal_argument_exception", "reason"=>"For input string: \"xxx\""}}}}}
document_id 指定、action=>"update"、doc_as_upsert => true 指定によって、特定キーで複数レコードのjoinのような操作が行えることが確認できました。ただ、Elasticsearchの場合、通常日次等でIndexを分けて管理することになりますが、Indexをまたぐ複数レコードの場合この方法は使えないので注意が必要です。
おまけ
ちょっと気になったので、既に複数の同一キーが存在するIndexに対して上の設定のLogstashからデータを投入したらどうなるかやってみました。
別経路で以下のようにfield01に同一の値を含むレコードを用意しておきます(doc_as_upsertの指定無しで)。

このIndexに対して、上のLogstashから以下のデータを投入してみます。
{"field01":"aaa","field02":"bbb9","field04":"AAA"}

結果は、別のレコードとして新規に追加されました。
なぜだろう???
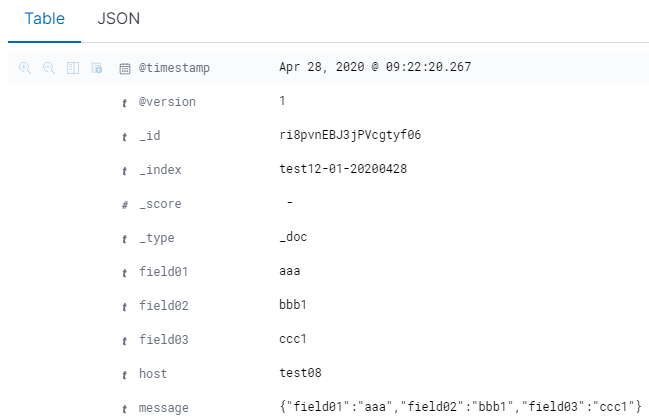
先に投入されていたレコード(document_id指定なし)
後から投入されたレコード(document_id指定あり)
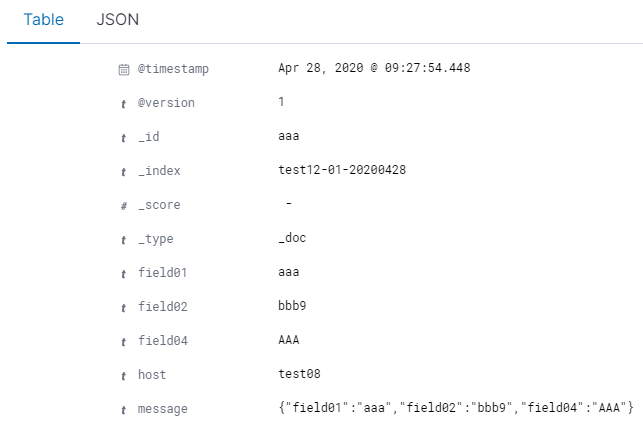
なーるほど、上の2つを見比べると、_id(各レコードのID)の値が違っています。デフォルト(1つめ)だと_idはユニークに割り振られますが、Logstashでdocument_idを明示的に指定した場合は(2つめ)は_idがfiled01の値になるということのようです。"field01"の値がキー値として認識されている訳では無く、field01の値をレコード固有のIDとして使用してそれをどういう風に扱うか(上書きなのか更新なのか)を制御している、という感じですね。
ちなみに、document_id指定し、action=>"index"のまま、doc_as_upsert指定無し(false)だと、後から追加したレコードで完全に置き換えられることになります。