はじめに
Apache Saprkのお勉強を始めるにあたってPC上に環境を作ってみようと思ったのですが、IBM Bluemix上でSparkのサービスが提供されているようなので使ってみました。
基本的なコマンドを実行してみる所までのメモです。
※Bluemixは30日間無償のフリートライアルというのが提供されています。
※Bluemixのユーザーインターフェースは結構コロコロと変わるイメージがあります。細かい所はすぐ変わってしまうかもしれませんがあしからず。
手順例
Sparkインスタンス作成
BluemixにログインしてカタログからSparkを検索します。
データ&分析のカテゴリに 「Apache Spark」というサービスが表示されるので、ポチっとクリックします。
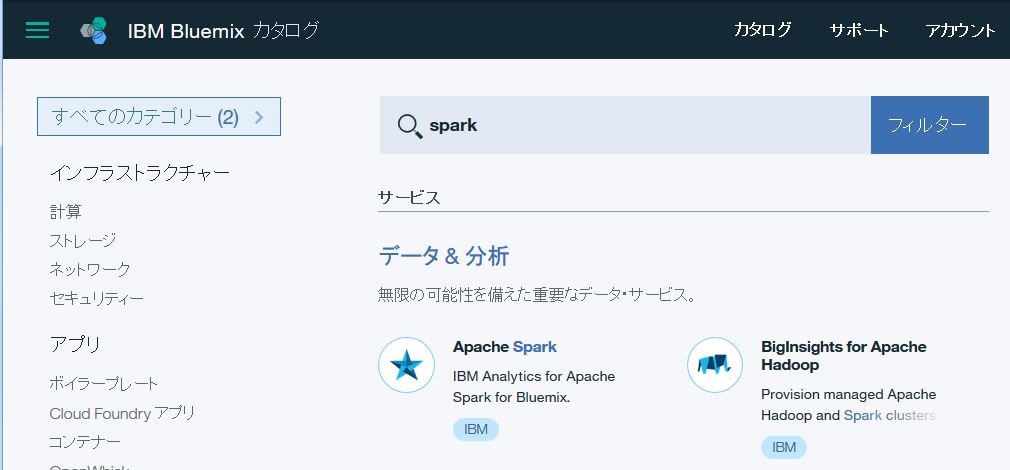
サービス名とか変更できるようですが、そのまま。
価格プランは2 Spark Execution(無料)を選択して、作成!
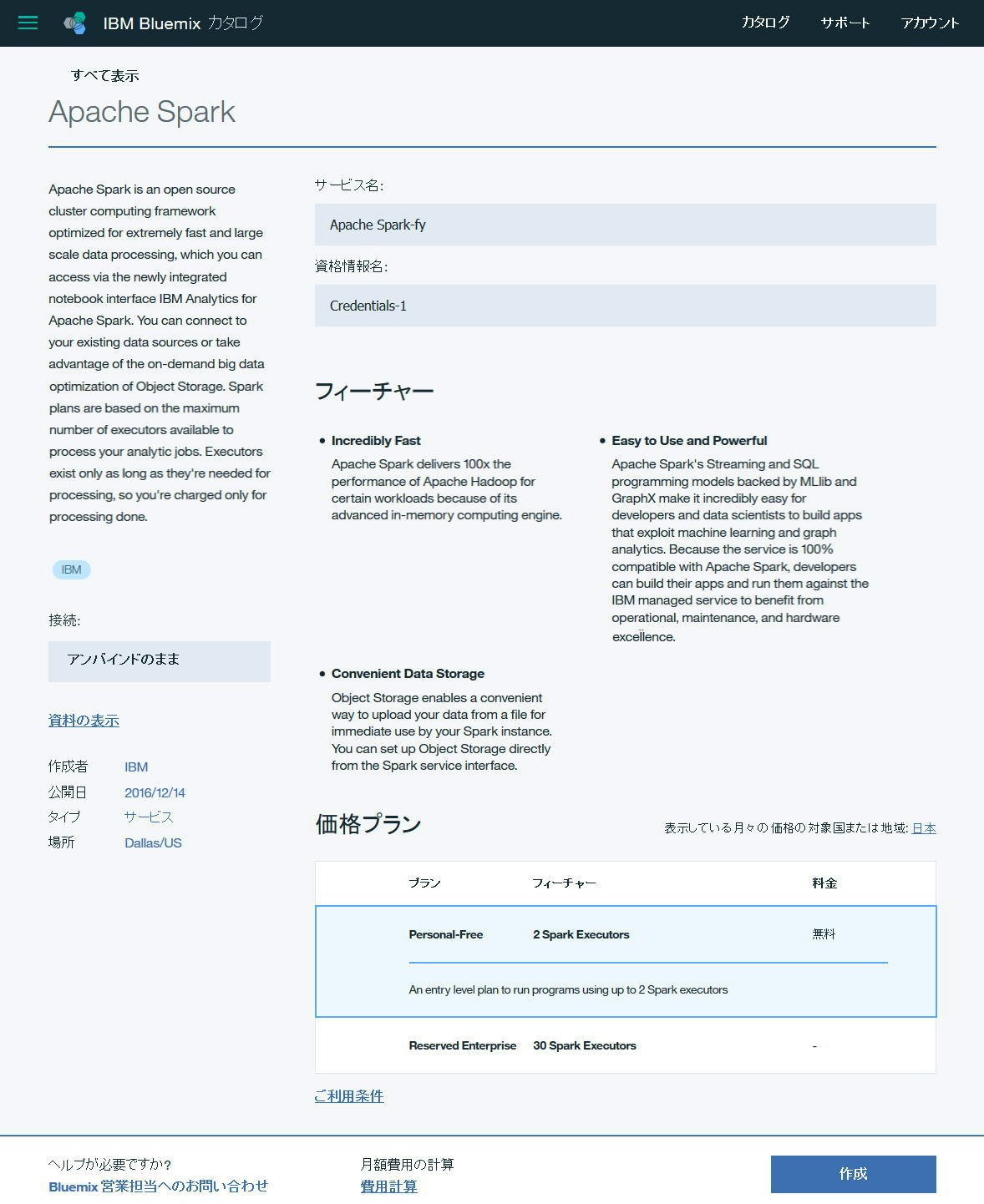
インスタンスが作成されて、以下のような画面が表示されました。
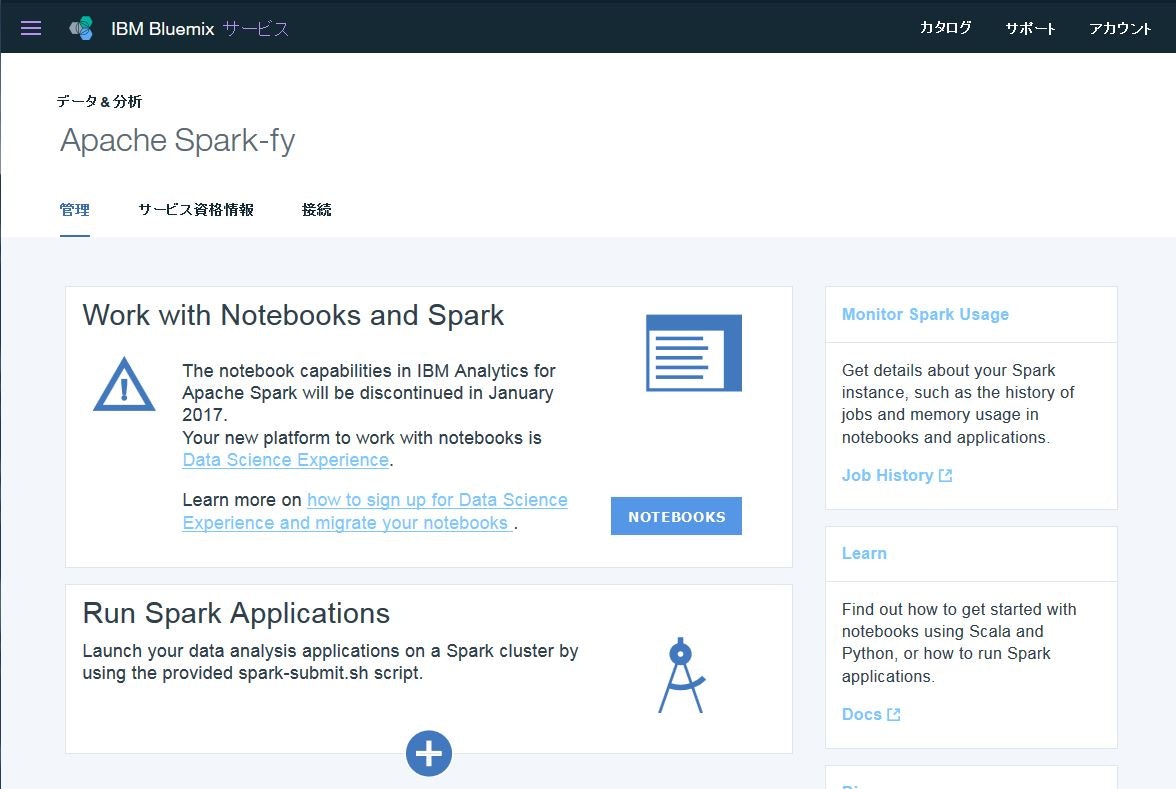
さて、この辺↓の記事をみてると、
Apache Spark for Bluemixで天気情報を高速分析
Sparkを手っ取り早く使ってみるツールとして、Jupyter Notebookというツールが使えそうだったのでそれを想定していたら、上の画面に、Notebookは2017年1月で使えなくなるようなことが書いてありました。Data Science Experience なるものに置き換わるようですね。
The notebook capabilities in IBM Analytics for Apache Spark will be discontinued in January 2017.
Your new platform to work with notebooks is Data Science Experience.
DSX(Data Science Experience)の設定
DSXのサービス?を利用してNotebook(これはJupyter Notebookと同じモノなのか?)を使うための設定をします。
Data Science Experienceのリンクを辿ると以下のページに飛ばされます。
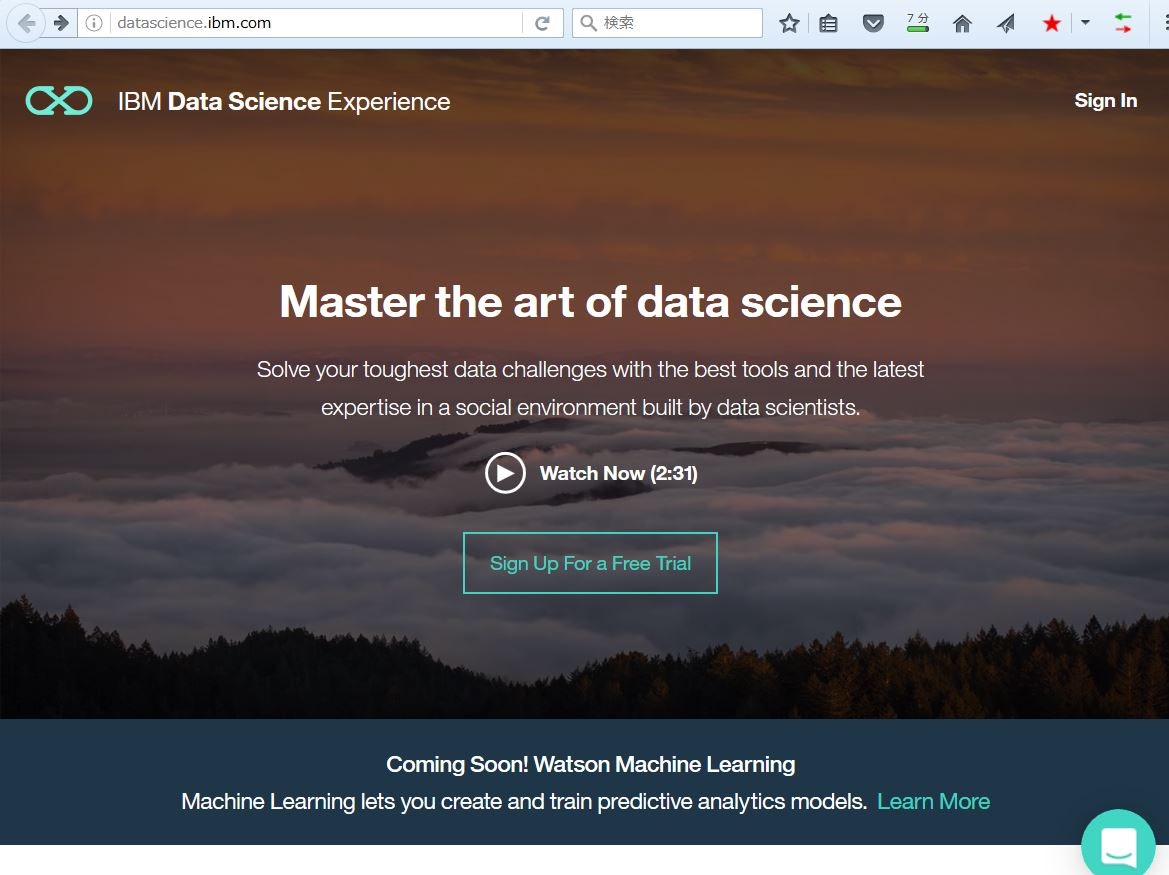
SignInのリンクから指示に従ってBluemixのアカウントを元に、DSX(Data Science Experience)のアカウントを設定します。
DSXにログイン?した状態になるようです。
左上のメニューから「My Projects」を選択します。
My Projectsの右上の「create project」を選択します。
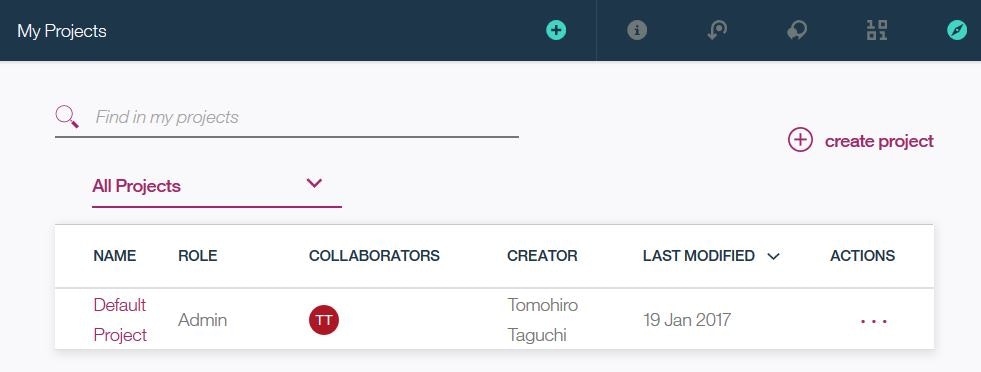
プロジェクトの名前などを設定します。
ここで、Spark Serviceとして先ほど作成したインスタンスが表示されるので、それを選択します。
で、「Create」
プロジェクトが作成されて、以下のようなメニューが出てきます。
Notebooks という項目の右側の「add notebooks」をクリックします。
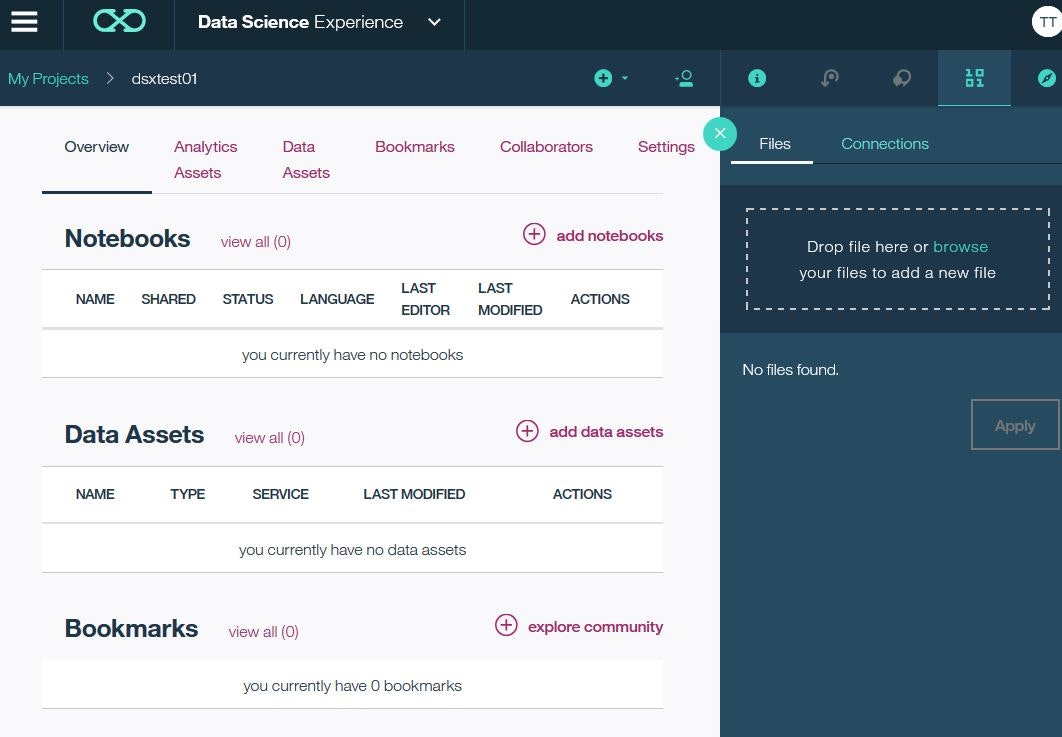
Notebookの設定を行います。ここでは、言語としてScala、Spark Versionとして2.0を選択し、Spark Serviceは先に作成したインスタンスを指定します。
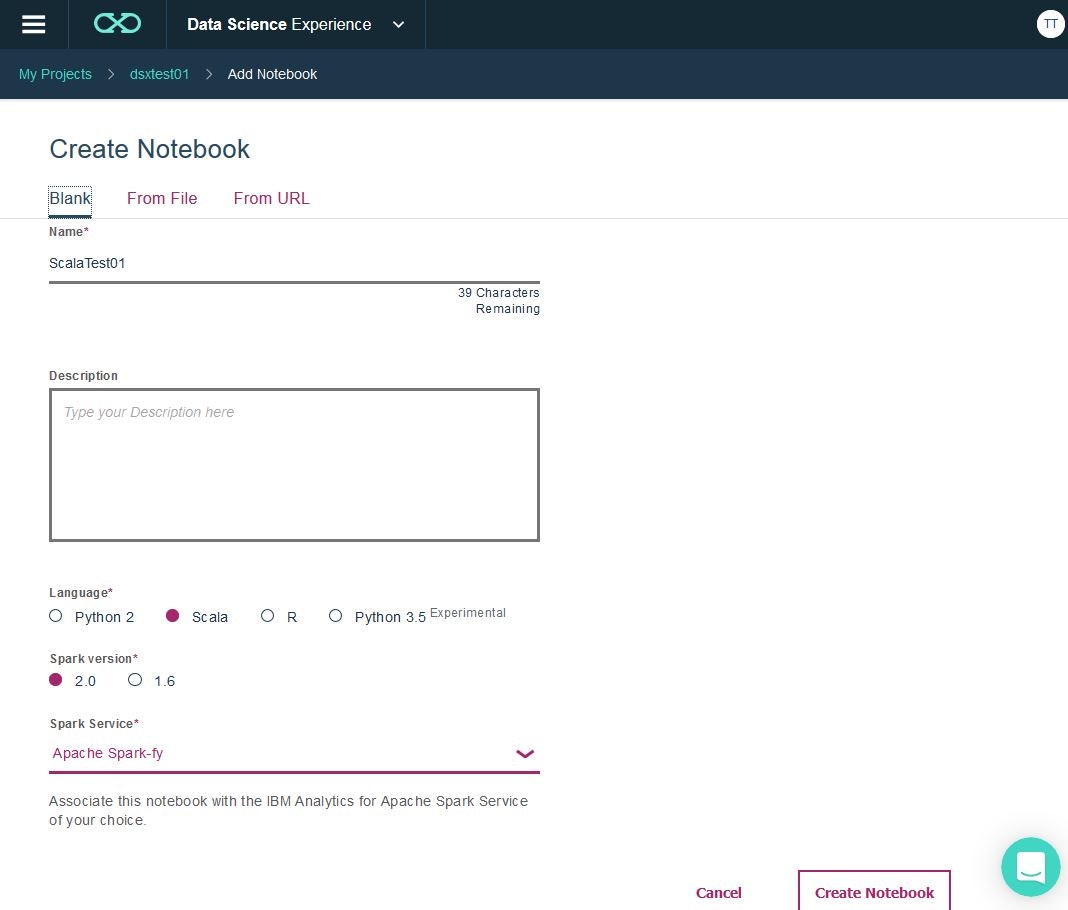
「Create Notebook」をすると、以下のようにNotebookが起動し、Scalaのコードが投入できる状態になりました。
Scalaコードの実行1
簡単なコードを試してみます。
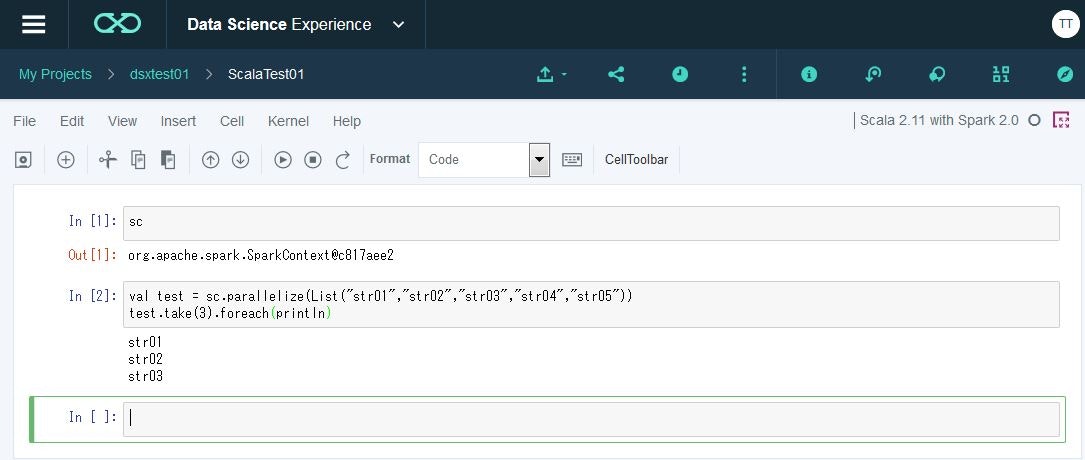
ふむ、一応動いているっぽい。
Scalaコードの実行2
次にcsvファイルを読んでRDDで扱ってみたいと思います。
テスト用のcsvを用意します。
test01,10
test02,20
test03,30
test04,40
test05,50
データは、Object Storage(My Projectの画面のData Assetという項目で管理される)に登録しておく必要があるっぽい。
My Projectの画面で、右上の「Find and add data」のアイコン(10 01っぽいやつ)をクリックして、扱いたいファイル(ここではtest.csv)をここにドラッグ&ドロップするか、browseのリンクからファイルを選択し、Applyを押します。
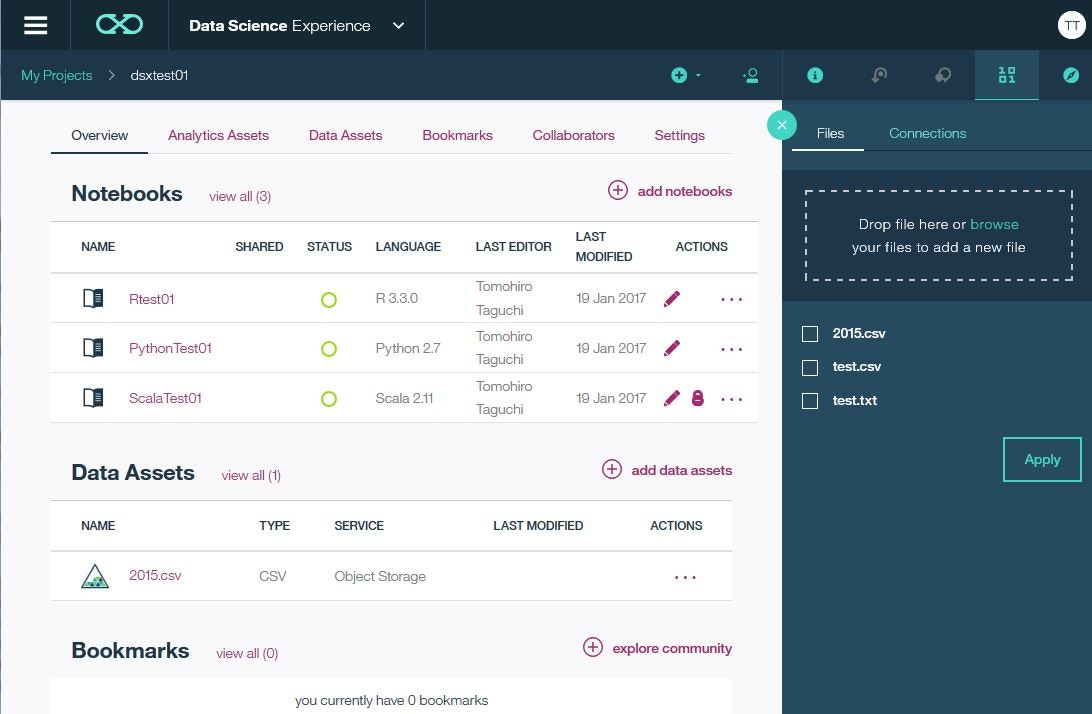
test.csvがData Assetsに追加されました。
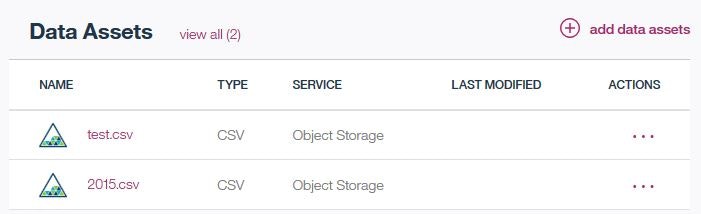
Notebook開いて、同じく「Find and Add data」のアイコンをクリックすると、Data Assetsに登録されているファイルがリストされます(この画面からもファイルのアップロードは可能)。扱いたいファイルの「Insert to code」のプルダウンメニューから、Insert Spark RDDを選択します。
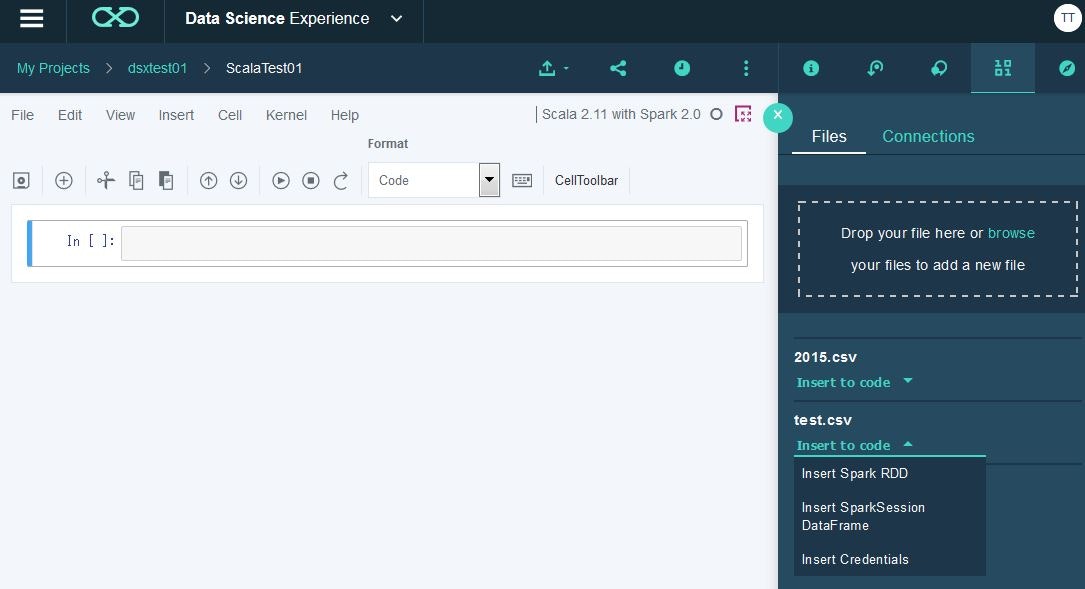
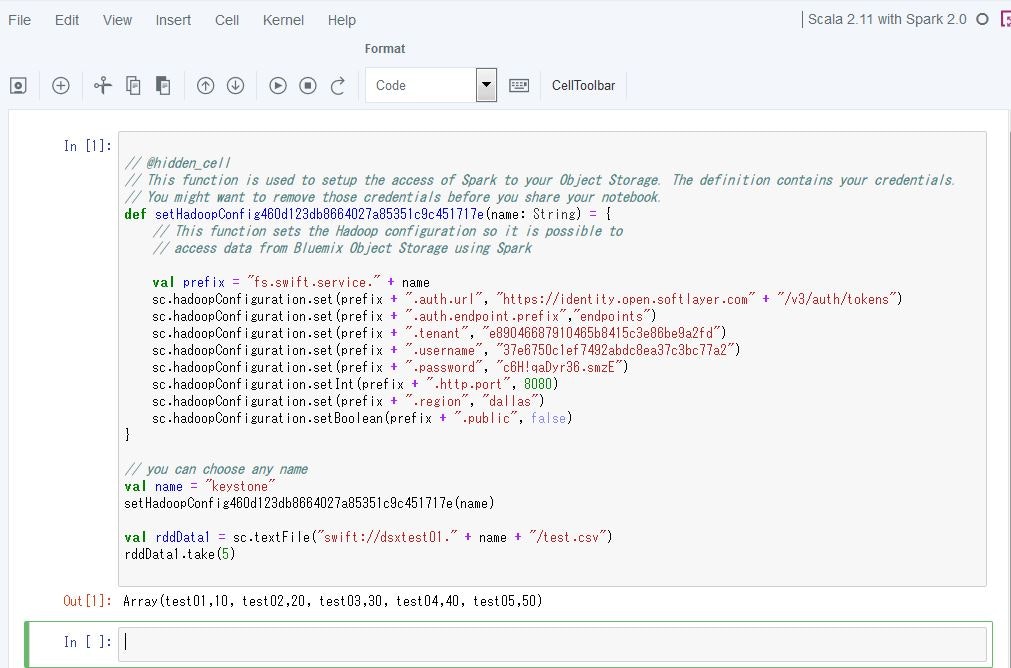
そうすると、左側の入力欄に、ペロッとそのデータをアクセスするためのコードが自動生成されます。実行すると、RDDとしてCSVのデータがハンドリングできていることが分かります。
Rコードの実行
同じようにRの実行を試してみます。
R用のNotebookを作成して起動します。
test.csvの「Insert to code」プルダウンメニューから、「Insert SparkSession DataFrame」を選択し、生成されたコードを実行します。
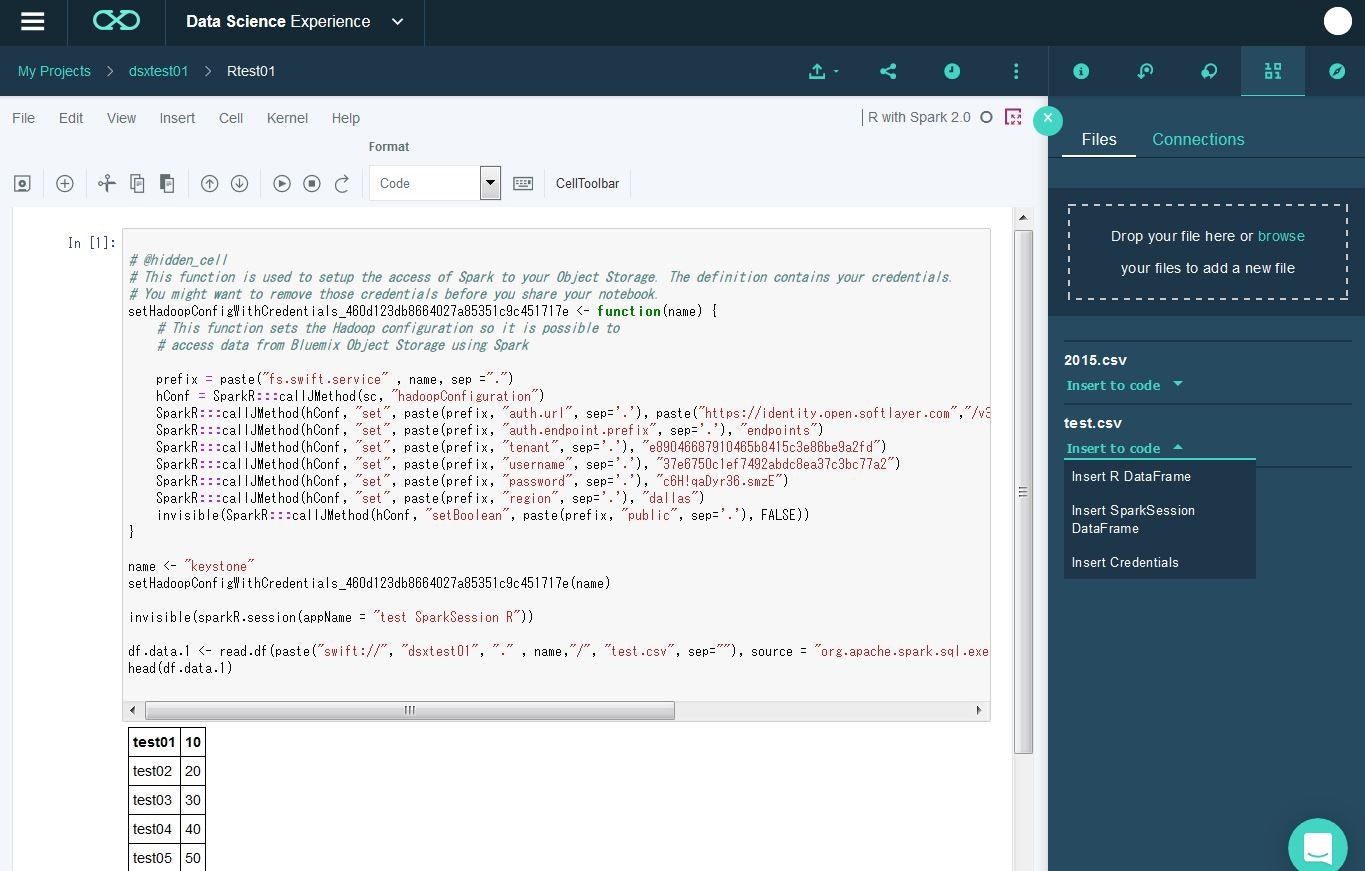
こんな感じに実行されました。