はじめに
メインフレーム開発環境をできるだけ標準的な技術を使ってモダナイズしていく際に直面するであろう課題の具体例を取り上げていきます。
まずは「オープン系とメインフレームの差異」に関連する課題を見ていきます。
関連記事
メインフレーム開発環境モダナイゼーションにおける課題 - 前置き
メインフレーム開発環境モダナイゼーションにおける課題 - 1. オープン系とメインフレームの差異に関する課題
メインフレーム開発環境モダナイゼーションにおける課題 - 2. プロジェクト固有の利用方法に関する課題
メインフレーム開発環境モダナイゼーションにおける課題 - 3. 組織/人材に関する課題
オープン系とメインフレームの差異に関する課題
背景
オープン系プラットフォームとメインフレームでは歴史的経緯やコンセプトなどの違いから管理方法や考え方に大きな違いがあります。両者の世界は"文化が異なる"と言っても過言ではないかもしれません。

先の記事で示したGitを中心とした開発プロセス改善イメージを色分けしてみると、水色部分のオープン系の世界とグレー部分のメインフレームの世界が一体となって開発環境を構成していることが分かります。
このように新しい開発環境としてはオープン系とメインフレームの間で頻繁かつ密な連携が必要となります。これまでメインフレームの中だけで考慮されていた開発プロセスをオープン系の世界にも広げることになるので、この両者の文化感のギャップの部分で課題や考慮点が発生することになります。
ソースの管理に関してプラットフォーム間の主な差異を以下にまとめます。
| オープン系 | メインフレーム (既存アプリケーション) |
|
|---|---|---|
| ソースの実体 | ファイル | PDSメンバー |
| ソース管理場所 | Git Server | PDS (or 管理ツール) |
| 変更管理方法 | ツールによる差分管理 | ソース中のコメントによる管理 |
| ソース名の制約 (文字数、使用できる文字等) |
開発に使用するOS (Windows/Linux)依存 「\」(U+005C)は使用不可 |
z/OS(MVS)依存 8文字以内 記号: @ (x'7C'), # (x'7B'), $ (x'5B') |
| ソース内容の識別 | 拡張子 | 配置するデータセット メンバー名のネーミングルール など |
| 文字コード | UTF-8 | EBCDIC 英小文字系/カタカナ系 DBCS区切り文字 |
| バイナリ情報 | 基本的に含まれない | 含まれる可能性あり |
| 開発言語特性 | 基本的には桁位置に制約なし | 桁位置の制約あり |
このような違いにより具体的にどのような課題/考慮点が生じるかを見ていきます。
(1) 日本語(DBCS)を含むソース
メインフレームの世界では文字コードは基本的にEBCDICと呼ばれる文字コード体系が用いられます。EBCDIC文字コード体系では英数字や記号は1バイト(Single Byte)で表現され、平仮名や漢字などの日本語文字列は2バイト(Double Byte)で表されます。前者はSBCS(Single Byte Character Set)、後者はDBCS(Double Byte Character Set)と呼ばれ、SBCSとDBCSの間にはShift-Out(SO)、Shift-In(SI)と呼ばれる制御コードを挿入する必要があります。
バイナリの情報を文字として解釈する際に、通常はSBCS文字として解釈し、SOからSIまでの間のコードはDBCSとして解釈することになります。ISPFのエディターで日本語文字列を挿入すると内部的には自動的にSO/SIの制御コードがDBCSの前後に挿入されます。このSO/SIの制御コードはそれぞれx'0E'、x'0F' という1バイトのコードで表され、エディター上はブランクのように表示されます。
以下はPCOM(3270端末エミュレーター)のエディターで日本語文字列(DBCS)を含むソースを表示している例です。

「あいうえお」というDBCS文字の前後(赤枠部分)が1バイト分ブランクになっています。
HEX ON のモードでこの部分を見ると、x'0E'、x'0F'のコードがDBCSの前後に挿入されていることが分かります。

PCOMの表示の設定でSO/SIをそれぞれ→/←の矢印で表示させるオプションもあります(Ctrl+F1で表示切替)。

このようにDBCSを含む場合は前後にSO/SIという余分な制御コードが入ることを意識して編集を行う必要があります。というのは、COBOLやPL/Iという言語はコーディングする際にコードを記述する位置(桁の位置)を意識する必要があるからです。例えば、73桁以降はシーケンス番号と呼ばれるエリアなので73桁目以降にコードは書けません。
EBCDICの世界で完結してる場合はエディター上での表示と、コンパイルに通すソースのイメージが合致しているのでよいですが、Gitによるソース管理やVS Codeエディターを使用してソース編集を行う場合、ソースは基本的にUTF-8などのEBCDIC以外の文字コードで扱われることになります。UTF-8やSJISなどの文字コード体系では、SBCSとDBCSの考え方もそのそも違いますし、区切り文字という概念もありません。従って、英数字と日本語文字の間に余分なブランクが入るということもありません。
つまり、EBCDICで作られていた日本語を含むソースをオープン系の環境に持ってきてUTF-8に文字コード変換をしてVS Codeエディターで開くと、以下のような桁ずれが生じることになります。
上と同じソースをVS Codeのエディターで表示したイメージです。

「あいうえお」の前後の制御コード分が無くなるので、本来73桁目以降に記載されていたシーケンス番号部分がコード本文のエリアにずれてきてしまっています。エディター上Syntax Errorのように見えてしまいますが、これをそのままz/OS上に転送してEBCDICに変換するとSO/SIが挿入されるのでうまくコンパイラは解釈できるということになります。
しかし、これをVS Code上で編集して桁合わせをしてしまうと、z/OSに持って行ってEBCDICに変換した時にシーケンス番号部分が意図しないものになってしまいます。
あるいは日本語文字を含む行のコード本文を72桁目までフルに書いてしまうと、EBCDICに変換した時にはコード本文が73桁目以降にはみ出てしまうことになり、コード本体のSyntaxが正しくない状態になってしまいます。
EclipseベースのIDz(IBM Developer for z)という有償製品に含まれるエディターであれば、DBCS前後のSO/SI分を解釈して桁合わせをしてくれる機能が提供されています。

しかし、VS CodeのIBM Z Open Editorでは現時点では残念ながらこのような機能は提供されていません(改善要望中)。
エディター上での見た目の差異以外にも問題になるケースがあります。
EBCDIC ⇔ UTF-8 間で文字コード変換が入ることで桁ずれが生じるわけですが、基本的にはソースをEBCDIC → UTF-8 → EBCDICと変換しても何も編集していない状態であれば中身が変わる訳では無く元に戻ります。

しかし、例外的に以下のような場合は編集作業を行わなくても文字コード変換するだけで桁ずれが発生します。

これは、SO/SIの制御コードのみが残っていて中身のDBCSが存在しない、いわゆる意味のないゴミのデータが残ってしまっているケースです。UTF-8に変換した時点で制御コードのみの部分(テキスト情報としては無意味な情報)は欠落することになりますので、再度EBCDICに変換すると制御コードのみの部分は欠落した状態になります。これによって桁ずれが生じることになります。
対応案検討
まず桁ずれで一番影響が出やすいのは73桁目以降のシーケンス番号の部分ですので、基本的には73桁目以降のシーケンス番号部分は削除して利用しないようにする、というのが王道の対応と思われます。
やり方としては、シーケンス番号部分を削除するツール(スクリプトなど)を作って一括で変換するか、もしくは新しいスタイルで編集が入るコードからその都度削除する、というような運用も考えられます。(例えばISPFエディターではUNNUMBERコマンドで一括で消せますし、VS Codeでも矩形選択して削除するといったこともできます。)
シーケンス番号部分を特にソース管理に使用していない場合は上の対応が望ましいですが、変更管理等で使用しているケースもあるかと思います。その場合は変更管理のやり方そのものをGit機能を利用する方法に変更する、あるいは、変えられないソースのみ分割しその部分だけは別途既存の仕組みを残すなど検討が必要と考えます。
中身のないSO/SIが含まれている場合の問題については、対応としてはこのようなゴミの情報は排除するという一択しかないと思います。
桁ずれの問題はシーケンス番号削除、中身無しのSO/SIの削除であらかた回避できる可能性がありますが、それだけでは完全ではありません。根本的にはエディターでSO/SI部分を疑似的に再現する機能が必要になります。IDz提供のエディターでは実現できていますが、無償のツールとして提供されているVS CodeのIBM Z Open Editorでは現時点では対応していません。製品改善要望など行っている状況ですが、日本語(DBCS圏)固有の問題のため対応が後手に回っていると思われます。利用者が増えて声が大きくなれば対応も進みやすいと期待しています。
(2) ファイル管理体系
冒頭にも表で示したように、オープン系とメインフレームではファイルシステムの考え方からして大きく異なります。例えばメインフレーム上ではソースはPDSのメンバーとして保持されますが、オープン系ではディレクトリ下のファイルとして保持されます。
オープン系ではアプリケーションはGit Server上のリポジトリと呼ばれる単位で管理され、編集を行う場合にはリポジトリ単位でローカルにクローン/ブランチを作成して管理することになります。各種操作を行う際にファイル種別を判断するのに拡張子が用いられます。このような概念はメインフレームにはないのですが、最終的にはソースはMVS上のデータセットとして転送しコンパイル/リンクを行う必要があるため、両者の間でのマッピングが必要になります。
Gitでソース管理を行って、DBB, zAppBuildの仕組みでビルドを行う場合のファイル管理に関連する部分に着目すると、例えば以下の図で示すような観点があります。

対応案検討
まず、DBB, zAppBuildをベースにビルド処理を行うことを考えると、zAppBuildのフレームワークでデフォルトで想定されているファイルのネーミングをしておくのが望ましいです。
基本的にはオープン系の世界で管理されるファイル名としては、<PDSメンバー名>.<拡張子>ということになります。<PDSメンバー名>部分は8文字以内の大文字の文字列で、PDSメンバーとして使用できる文字限定とします(記号については後続の考慮点も関係します)。拡張子はそのファイルの種類によって付与します。例えば以下のようなイメージです。
- COBOLソース: .cbl
- COBOL COPYBOOK: .cpy
- PL/Iソース: .pli
- PL/I INCLUDE: .inc
- アセンブラソース: .asm
- REXXソース: .rex
- ...
PDSメンバーに拡張子をつけるだけなのでこの辺りは比較的機械的に変換はできると思います。DBBが提供するユーティリティーを利用することも可能です。
参考: DBB - Migrating source files from z/OS to Git
ファイル個別のマッピングについては比較的機械的にできると思いますが、それをどのような単位のGitリポジトリに管理してディレクトリ構造をどうするかというのは一意に決まるものでは無いので、アプリケーションの特性や管理方法等をふまえて個別に検討をする必要があると考えます。
メインフレームのアプリケーションだと規模が大きくソースの数も多くなりリポジトリも巨大になる可能性があるというのは1つ懸念されるところかもしれません。これについては以下のような記事が出されています。
Worried about cloning your large Z code Git repo?
その他大規模なリポジトリについて参考になりそうな記事も挙げておきます。
GitHub における大規模なモノリポのパフォーマンスの向上
パーシャルクローンとシャロークローンを活用しよう
大きなGitリポジトリをクローンするときの工夫を図解します
(3) カタカナ系文字コード
メインフレームの世界での日本語の文字コードとしては英小文字系と呼ばれるもの(CCSID:939/5035/1399)と、カタカナ系と呼ばれるもの(CCSID:930/5026/1390)の2種類に大別されます。
これは大昔に半角カタカナを使いたい人が、英小文字部分のコードを犠牲にしてそこに半角カタカナを割り当てたという背景があるようです。日本のシステムではそれが脈々と受け継がれていまだにこのカタカナ系の文字コードが使用されているケースは多いようです。
半角カタカナと英小文字のコードが入れ替わっているという点だけならまだよいのですが、やっかいなのは一部の記号についても入れ替わっている点です。
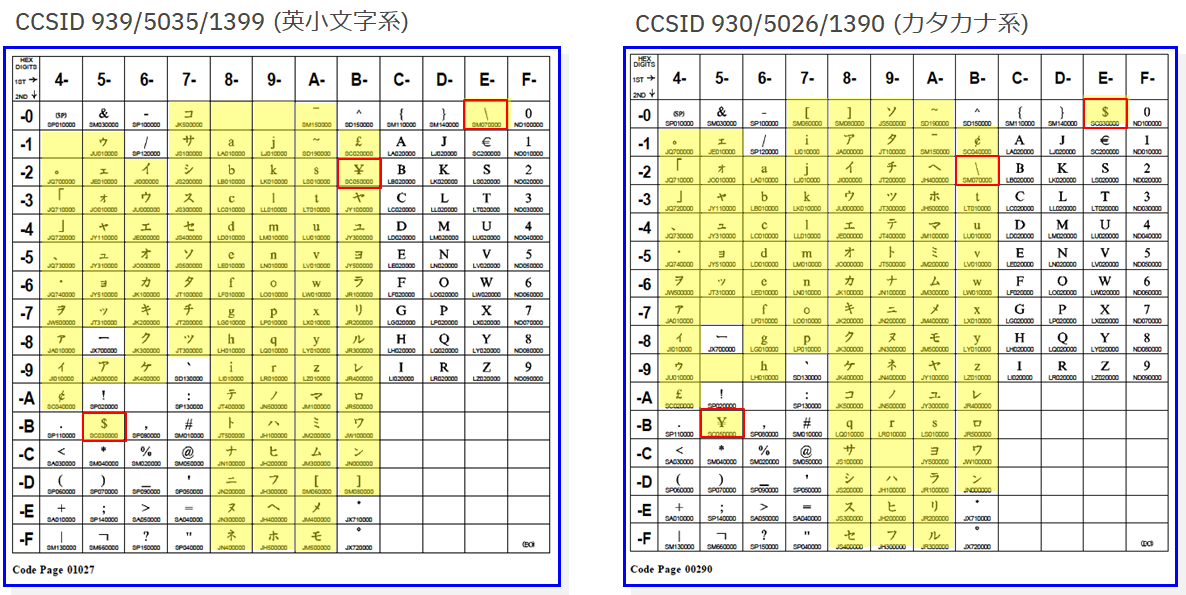
上の表は英小文字系文字コードとカタカナ系文字コードのSBCS部分の比較です。黄色部分がコードが入れ替わっている部分ですが、とりわけ赤枠部分の差異がやっかいな部分です。
コードが変わっているものについて一部抜粋して整理するとこんな感じになります。

ここでPDSメンバー名として使用できる文字に着目してみます。
上のマニュアルの記述にある通り、メンバー名として使用できる英数字以外の記号は以下の3つです。
@ (x'7C'), # (x'7B'), $ (x'5B')
このうち、$(x'5B')については、英小文字系の文字コードとカタカナ系の文字コードで文字とコードポイントのマッピングが異なります。
つまり、z/OSとしてはHexで言うとx'5B'という記号は使えますが、英小文字系だとそれは$として扱われますし、カタカナ系だと¥として扱われることになります。
※英語圏だと基本的には英小文字系のコードページと同じマッピングなので、マニュアル上などは通常は$として表記されています。
一方で、Windowsでも日本語環境固有のややこしい事情があります。Windows上で使用する機能や入力/表示の方法によって、Unicodeで言うところのバックスラッシュ「\」(U+005C)は「¥」として扱われます。このバックスラッシュはディレクトリの区切り文字として使用されるのでファイル名には使用できません。Unicodeでいう所の円マーク「¥」(U+00A5)であればファイル名として利用はできますが、Windows上ではバックスラッシュ(U+005C)も円マーク(U+00A5)はどちらも「¥」と表示されてしまうので非常にややこしいです。しかも日本語キーボードで右上端の「¥」が書かれたキーを押すとそれはバックスラッシュ(U+005C)の方(ファイル名としては使えない方)が入力されることになります。
このように日本語環境のWindows上では「¥」と「\」はかなり慎重に扱わなければなりません。
このような背景から、EBCDICのカタカナ系文字コードを使用していて、メンバー名に「¥」(x'5B')を使用している場合は、Windowsファイル名との変換で不具合が生じることが多々あります。ファイルの中身に関してはほぼ文字コード変換を行うコードページの指定で制御できるのですが、残念ながらファイル名に関しては文字コードが指定できずに英小文字系の文字コードとして一律変換されてしまう部分が出てきてしまいます。
具体的な不具合の一例をあげると、例えばDBB, zAppBuildによるユーザービルドを行う際の問題があります。ソースから別ファイルを参照しているケース、すなわちCOBOL COPYBOOKやPL/IのINCLUDEファイルを参照するようなケースで、参照先のファイル名に「¥」が含まれていると、z/OSへ転送した時にファイルの中身とファイル名の変換が違ってしまうためにビルド(コンパイル)がうまく機能しないということになります。

※このあたりの詳細は以下の記事にも記載していますのでそちらもご参照ください。
参考: z/OS利用時の文字コード変換 - 動作検証(4) カタカナ系文字コードにおけるPDSメンバー名
対応案検討
z/OS上でカタカナ系文字コードを使用している場合は、メンバー名に「¥」(x'5B')を使用しないようにネーミングの体系を検討しなおすのが王道の対応と考えられます。
ただ、例えば上のCOPYBOOK, INCLUDEの参照問題については、COPYBOOK, INCLUDE側の変更は基本的には無いと想定すると、ローカル(Windows)からの参照用にCOPYBOOK/INCLUDEのライブラリを用意し、開発環境のz/OS上にはコンパイル用のライブラリを別途用意しておいてそれぞれ意図したネーミングで管理しておく、というような逃げ道も考えられるかもしれません。このようにコード変換が入る箇所それぞれで、運用によって回避策は考えられるかもしれませんが、しかしこのような対処療法は後々禍根を残すことになると思われます。将来的に何か新しい仕組みを導入しようとした時にこの回避策が足かせとなって対応に苦慮することになるのは想像に難くありません。できる限り「¥」(x'5B')を使用しない対応を模索するのが望ましいと考えます。
(4) バイナリー・データ
メインフレームに閉じた環境で情報を扱う場合、人間が解釈できるいわゆる「文字列」ではなくバイナリー・データを直接扱うということができていました。
例えば、PCOM上でのISPFのエディターの機能で「HEX ON」とすると、各行が3行表示になって、1行目が通常表示上の文字列、2,3行目が1行目に対応するHEXのコード(縦2文字で1バイトのコードを示す)を表示してくれます。

エディター上ではHEX部分も編集することができますので、「文字列」として扱えないものでも直接HEXでの編集ができてしまいます。
既存の仕組みの中でバイナリー・データを直接扱っているケースとしては例えば以下のような例があると思います。
【ソース中に制御コードを直接埋め込んでいるケース】
例えばCOBOLでPIC G(n) DISPLAY-1というようなGraphic型(SO/SI無し)のフィールドに対して、前後にSO/SIを付与して無理やりMixedフィールドとして扱うために、SO(x'0E')、SI(x'0F')を保持する1バイトのフィールドを定義したい場合があります。この時VALUE部分にHEXモードで値を直接を埋め込んでいるというようなことがあります。
【テスト用データを作成するケース】
これは直接ソースということではないですが、単体テスト等を行う際に使用するテストデータとしてバイナリの情報を編集したいということがあります。
新しい仕組みに置き換わった場合にはEBCDICとUTF-8など他の文字コードの間で文字コード変換が発生することになります。"文字コード変換"という言い方をしている通り当然のことながら「文字」として扱えないものは正しく変換できません。
対応案検討
ソース中のバイナリー・データについては排除するしか対応の余地はありません。どうしても排除できないものは既存の仕組みを残すなど例外として対処することを考える必要があります。
ソース中のバイナリー・データの排除としては、例えばCOBOLのVALUE句での指定であれば、HEXコードをテキスト情報として指定することができますので、そのような置き換えをすることを検討します。
例えば、以下のようにHEX ONモードで直接HEXで制御コードを埋め込んでいるフィールドがあった場合は...

以下のようにテキストベースでのHEXコード指定方法に置き換え可能です。
(ただし古いコンパイラではこのような16進数表記はサポートされないものもあるので注意)

テスト用のデータについては、こちらはソース管理とは別の話になってくるのでテストのやり方に応じて検討する必要があります。既存のツールを利用するなり、単純なものでよければテキストベースでHEXコードを編集できる自作ツールで対応する、といったことも検討の余地があると思います。