はじめに
KibanaではElasticsearchに格納されているデータを容易にグラフ化するための機能が提供されています。ただ、この機能はElasticsearch上のIndex Patternの単位で操作するのが基本なので、構造の異なる複数のIndexの情報をまとめて扱おうとするとグラフを作るのが結構難しかったり、複雑な計算処理を含めるとグラフ化する際に処理が重くなったりしてしまいます。そのため、事前にデータを加工してVisualizeしやすいようなIndexにあらかじめ加工しておく方がやりやすい場合があります。
そこで、ここではElasticsearchの情報を加工する方法として、Apache Sparkを利用してみます。
Elasticsearchの複数indexを読み取り、簡単な加工をして、新たなindexを作成する、ということをやってみます。
参考情報
Elasticsearch for Apache Hadoop - Apache Spark support
Maven Repository - Elasticsearch Spark (for Spark 2.X)
GitHub - elastic/elasticsearch-hadoop
Elasticsearchのクラスタを構築してSparkでIndexを作るまでの簡易手順
Adding a column of rowsums across a list of columns in Spark Dataframe
事前準備
利用環境
RHEL V7.5
Elasticsearch V7.6.2
Apache Spark V2.4.5 (scala V2.11.12), sbt V1.3.10
ElasticsearchとSparkはセットアップ済の想定です(1ノード上に簡易的に構成)。
参考:
fluentd/Elasticsearch/kibanaを試す
Linux(RHEL)上でのApache Spark環境構築メモ
elasticsearch-sparkコネクタ
Elasticsearch - Apach Spark Support -Spark SQL Support
Supported Spark SQL versions
...
elasticsearch-hadoop supports both version Spark SQL 1.3-1.6 and Spark SQL 2.0 through two different jars: elasticsearch-spark-1.x-.jar and elasticsearch-hadoop-<version>.jar support Spark SQL 1.3-1.6 (or higher) while elasticsearch-spark-2.0-<version>.jar supports Spark SQL 2.0. In other words, unless you are using Spark 2.0, use elasticsearch-spark-1.x-<version>.jar
elasticsearchのSpark用のコネクタはelasticsearch-spark-2.0xxx.jarで提供されているものを使えばよさそうです。jarはMaven Repositoryで提供されていたので、そこからダウンロードしておきます。今回利用する環境のElasticsearch,Scalaのバージョンに合わせたjarを使用します。
https://mvnrepository.com/artifact/org.elasticsearch/elasticsearch-spark-20_2.11/7.6.2
[root@test08 /Inst_Image/elastic]# wget https://repo1.maven.org/maven2/org/elasticsearch/elasticsearch-spark-20_2.11/7.6.2/elasticsearch-spark-20_2.11-7.6.2.jar
--2020-04-22 09:21:05-- https://repo1.maven.org/maven2/org/elasticsearch/elasticsearch-spark-20_2.11/7.6.2/elasticsearch-spark-20_2.11-7.6.2.jar
repo1.maven.org (repo1.maven.org) をDNSに問いあわせています... 151.101.52.209
repo1.maven.org (repo1.maven.org)|151.101.52.209|:443 に接続しています... 接続しました。
HTTP による接続要求を送信しました、応答を待っています... 200 OK
長さ: 929583 (908K) [application/java-archive]
`elasticsearch-spark-20_2.11-7.6.2.jar' に保存中
100%[================================================================================>] 929,583 348KB/s 時間 2.6s
2020-04-22 09:21:08 (348 KB/s) - `elasticsearch-spark-20_2.11-7.6.2.jar' へ保存完了 [929583/929583]
ElasticsearchにIndex Template作成
今回動作確認で作成するIndexはsample-*という名前で作成する想定です。また、@timestamp列に時刻情報を設定する想定なので、date型の指定をindex templateに指定しておきます。
PUT _template/sample
{
"index_patterns": ["sample-*"],
"order" : 0,
"settings": {
"number_of_shards": 1,
"number_of_replicas" : 0
},
"mappings": {
"numeric_detection": true,
"properties": {
"@timestamp": {
"type": "date"
}
}
}
}
spark-shellでの確認
spark-shellは対話型のインターフェースが提供されているので、sparkの命令を1つずつ実行することができます。
逐一内容を確認しながら操作できますので、一旦ここでいくつかのバリエーションの動作を確認し、後続のスタンドアローンのアプリに落とし込む、という流れでやっていきます。
サンプルデータ準備
まず、CSVでテスト用のデータを用意しておきます。
@timestamp,key01,key02,field01,field02
2020-04-01 11:22:01,AAA,COR01,11,22.22
2020-04-01 11:22:01,AAA,COR02,22,33.33
2020-04-01 11:22:01,BBB,COR01,33,44.44
2020-04-01 11:22:01,BBB,COR02,44,55.55
2020-04-01 11:23:02,AAA,COR01,55,66.66
2020-04-01 11:23:02,AAA,COR02,66,77.77
2020-04-01 11:23:02,BBB,COR01,77,88.88
2020-04-01 11:23:02,BBB,COR02,88,99.99
2020-04-01 11:24:03,CCC,COR01,11,11.11
2020-04-01 11:25:04,DDD,COR01,11,11.11
2020-04-01 11:25:04,DDD,COR01,22,22.22
2020-04-01 11:25:04,DDD,COR01,33,33.33
2020-04-01 11:26:05,EEE,COR01,12,34.56
2020-04-01 11:26:05,EEE,COR02,23,45.67
2020-05-02 11:22:01,AAA,COR01,11,22.22
2020-05-02 11:22:01,AAA,COR02,22,33.33
2020-05-02 11:22:01,BBB,COR01,33,44.44
2020-05-02 11:22:01,BBB,COR02,44,55.55
2020-05-02 11:23:02,AAA,COR01,55,66.66
2020-05-02 11:23:02,AAA,COR02,66,77.77
2020-05-02 11:23:02,BBB,COR01,77,88.88
2020-05-02 11:23:02,BBB,COR02,88,99.99
2020-05-02 11:24:03,CCC,COR01,11,11.11
2020-05-02 11:25:04,DDD,COR01,11,11.11
2020-05-02 11:25:04,DDD,COR01,22,22.22
2020-05-02 11:25:04,DDD,COR01,33,33.33
2020-05-02 11:26:05,EEE,COR01,12,34.56
2020-05-02 11:26:05,EEE,COR02,23,45.67
@timestamp,key01,key02,field03,field04
2020-04-01 11:22:01,AAA,COR01,99,88.88
2020-04-01 11:22:01,AAA,COR02,88,77.77
2020-04-01 11:22:01,BBB,COR01,77,66.66
2020-04-01 11:22:01,BBB,COR02,66,55.55
2020-04-01 11:22:02,AAA,COR01,55,44.44
2020-04-01 11:22:02,AAA,COR02,44,33.33
2020-04-01 11:22:02,BBB,COR01,33,22.22
2020-04-01 11:22:02,BBB,COR02,22,11.11
2020-04-01 11:22:03,CCC,COR01,11,11.11
2020-04-01 11:22:03,CCC,COR01,22,22.22
2020-04-01 11:22:03,CCC,COR01,33,33.33
2020-04-01 11:22:04,DDD,COR01,11,11.11
2020-04-01 11:26:05,FFF,COR01,12,34.56
2020-04-01 11:26:05,FFF,COR02,23,45.67
2020-05-02 11:22:01,AAA,COR01,99,88.88
2020-05-02 11:22:01,AAA,COR02,88,77.77
2020-05-02 11:22:01,BBB,COR01,77,66.66
2020-05-02 11:22:01,BBB,COR02,66,55.55
2020-05-02 11:22:02,AAA,COR01,55,44.44
2020-05-02 11:22:02,AAA,COR02,44,33.33
2020-05-02 11:22:02,BBB,COR01,33,22.22
2020-05-02 11:22:02,BBB,COR02,22,11.11
2020-05-02 11:22:03,CCC,COR01,11,11.11
2020-05-02 11:22:03,CCC,COR01,22,22.22
2020-05-02 11:22:03,CCC,COR01,33,33.33
2020-05-02 11:22:04,DDD,COR01,11,11.11
2020-05-02 11:26:05,FFF,COR01,12,34.56
2020-05-02 11:26:05,FFF,COR02,23,45.67
spark-shell操作
spark-shell起動
elaticsearch-sparkコネクターのjarを指定してspark-shell実行
[root@test08 ~/Spark]# spark-shell
20/04/25 10:15:18 WARN Utils: Your hostname, test08 resolves to a loopback address: 127.0.0.1; using 10.0.2.15 instead (on interface enp0s3)
20/04/25 10:15:18 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/04/25 10:15:19 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://10.0.2.15:4040
Spark context available as 'sc' (master = local[*], app id = local-1587777325949).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.5
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_161)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
事前準備:Sampleデータの取り込み
事前準備として、csvファイルを読み取り、Elasticsearch上にサンプルのIndexを2つ(sample-data01, sample-data02)作成します。
scala> val sample01 = spark.read.option("header","true").option("inferSchema", "true").csv("file:///root/Spark/sample-data01.csv")
sample01: org.apache.spark.sql.DataFrame = [@timestamp: timestamp, key01: string ... 3 more fields]
scala> sample01.show
+-------------------+-----+-----+-------+-------+
| @timestamp|key01|key02|field01|field02|
+-------------------+-----+-----+-------+-------+
|2020-04-01 11:22:01| AAA|COR01| 11| 22.22|
|2020-04-01 11:22:01| AAA|COR02| 22| 33.33|
|2020-04-01 11:22:01| BBB|COR01| 33| 44.44|
|2020-04-01 11:22:01| BBB|COR02| 44| 55.55|
|2020-04-01 11:23:02| AAA|COR01| 55| 66.66|
|2020-04-01 11:23:02| AAA|COR02| 66| 77.77|
|2020-04-01 11:23:02| BBB|COR01| 77| 88.88|
|2020-04-01 11:23:02| BBB|COR02| 88| 99.99|
|2020-04-01 11:24:03| CCC|COR01| 11| 11.11|
|2020-04-01 11:25:04| DDD|COR01| 11| 11.11|
|2020-04-01 11:25:04| DDD|COR01| 22| 22.22|
|2020-04-01 11:25:04| DDD|COR01| 33| 33.33|
|2020-04-01 11:26:05| EEE|COR01| 12| 34.56|
|2020-04-01 11:26:05| EEE|COR02| 23| 45.67|
|2020-05-02 11:22:01| AAA|COR01| 11| 22.22|
|2020-05-02 11:22:01| AAA|COR02| 22| 33.33|
|2020-05-02 11:22:01| BBB|COR01| 33| 44.44|
|2020-05-02 11:22:01| BBB|COR02| 44| 55.55|
|2020-05-02 11:23:02| AAA|COR01| 55| 66.66|
|2020-05-02 11:23:02| AAA|COR02| 66| 77.77|
+-------------------+-----+-----+-------+-------+
only showing top 20 rows
scala> sample01.printSchema
root
|-- @timestamp: timestamp (nullable = true)
|-- key01: string (nullable = true)
|-- key02: string (nullable = true)
|-- field01: integer (nullable = true)
|-- field02: double (nullable = true)
scala> :paste
// Entering paste mode (ctrl-D to finish)
sample01.write
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port","9200")
.option("es_resource", "sample-data01")
.save()
// Exiting paste mode, now interpreting.
scala> val sample02 = spark.read.option("header","true").option("inferSchema", "true").csv("file:///root/Spark/sample-data02.csv")
sample02: org.apache.spark.sql.DataFrame = [@timestamp: timestamp, key01: string ... 3 more fields]
scala> sample02.show
+-------------------+-----+-----+-------+-------+
| @timestamp|key01|key02|field03|field04|
+-------------------+-----+-----+-------+-------+
|2020-04-01 11:22:01| AAA|COR01| 99| 88.88|
|2020-04-01 11:22:01| AAA|COR02| 88| 77.77|
|2020-04-01 11:22:01| BBB|COR01| 77| 66.66|
|2020-04-01 11:22:01| BBB|COR02| 66| 55.55|
|2020-04-01 11:23:02| AAA|COR01| 55| 44.44|
|2020-04-01 11:23:02| AAA|COR02| 44| 33.33|
|2020-04-01 11:23:02| BBB|COR01| 33| 22.22|
|2020-04-01 11:23:02| BBB|COR02| 22| 11.11|
|2020-04-01 11:24:03| CCC|COR01| 11| 11.11|
|2020-04-01 11:24:03| CCC|COR01| 22| 22.22|
|2020-04-01 11:24:03| CCC|COR01| 33| 33.33|
|2020-04-01 11:25:04| DDD|COR01| 11| 11.11|
|2020-04-01 11:26:05| FFF|COR01| 12| 34.56|
|2020-04-01 11:26:05| FFF|COR02| 23| 45.67|
|2020-05-02 11:22:01| AAA|COR01| 99| 88.88|
|2020-05-02 11:22:01| AAA|COR02| 88| 77.77|
|2020-05-02 11:22:01| BBB|COR01| 77| 66.66|
|2020-05-02 11:22:01| BBB|COR02| 66| 55.55|
|2020-05-02 11:23:02| AAA|COR01| 55| 44.44|
|2020-05-02 11:23:02| AAA|COR02| 44| 33.33|
+-------------------+-----+-----+-------+-------+
only showing top 20 rows
scala> sample02.printSchema
root
|-- @timestamp: timestamp (nullable = true)
|-- key01: string (nullable = true)
|-- key02: string (nullable = true)
|-- field03: integer (nullable = true)
|-- field04: double (nullable = true)
scala> :paste
// Entering paste mode (ctrl-D to finish)
sample02.write
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port","9200")
.option("es_resource", "sample-data02")
.save()
// Exiting paste mode, now interpreting.
これで、Elasticsearch上にsample-data01, sample-data02というIndexが作成されました。以降の操作では、これらのIndexをApache Sparkで加工してみます。
※CSVのサンプルデータをElasticseachに投入する所も上の通りSpark使ってやっちゃいましたが、ここはあくまで事前準備としての操作なので、本題はここからです。
2つのIndexをJoin
Elasticsearchからデータの読み込み
まず、Elasticsearchからindex "sample-data01"を読み込んでDataFrame "df01"を作成します。
scala> :paste
// Entering paste mode (ctrl-D to finish)
val df01 = {
spark.read
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port", "9200")
.option("es.resource", "sample-data01")
.load()
}
// Exiting paste mode, now interpreting.
df01: org.apache.spark.sql.DataFrame = [@timestamp: timestamp, field01: bigint ... 3 more fields]
scala> df01.show
+-------------------+-------+-------+-----+-----+
| @timestamp|field01|field02|key01|key02|
+-------------------+-------+-------+-----+-----+
|2020-04-01 11:22:01| 11| 22.22| AAA|COR01|
|2020-04-01 11:22:01| 22| 33.33| AAA|COR02|
|2020-04-01 11:22:01| 33| 44.44| BBB|COR01|
|2020-04-01 11:22:01| 44| 55.55| BBB|COR02|
|2020-04-01 11:23:02| 55| 66.66| AAA|COR01|
|2020-04-01 11:23:02| 66| 77.77| AAA|COR02|
|2020-04-01 11:23:02| 77| 88.88| BBB|COR01|
|2020-04-01 11:23:02| 88| 99.99| BBB|COR02|
|2020-04-01 11:24:03| 11| 11.11| CCC|COR01|
|2020-04-01 11:25:04| 11| 11.11| DDD|COR01|
|2020-04-01 11:25:04| 22| 22.22| DDD|COR01|
|2020-04-01 11:25:04| 33| 33.33| DDD|COR01|
|2020-04-01 11:26:05| 12| 34.56| EEE|COR01|
|2020-04-01 11:26:05| 23| 45.67| EEE|COR02|
|2020-05-02 11:22:01| 11| 22.22| AAA|COR01|
|2020-05-02 11:22:01| 22| 33.33| AAA|COR02|
|2020-05-02 11:22:01| 33| 44.44| BBB|COR01|
|2020-05-02 11:22:01| 44| 55.55| BBB|COR02|
|2020-05-02 11:23:02| 55| 66.66| AAA|COR01|
|2020-05-02 11:23:02| 66| 77.77| AAA|COR02|
+-------------------+-------+-------+-----+-----+
only showing top 20 rows
scala> df01.printSchema
root
|-- @timestamp: timestamp (nullable = true)
|-- field01: long (nullable = true)
|-- field02: float (nullable = true)
|-- key01: string (nullable = true)
|-- key02: string (nullable = true)
次に、index "sample-data02"を読み込んでDataFrame "df02"を作成します。
scala> :paste
// Entering paste mode (ctrl-D to finish)
val df02 = {
spark.read
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port", "9200")
.option("es.resource", "sample-data02")
.load()
}
// Exiting paste mode, now interpreting.
df02: org.apache.spark.sql.DataFrame = [@timestamp: timestamp, field03: bigint ... 3 more fields]
scala> df02.show
+-------------------+-------+-------+-----+-----+
| @timestamp|field03|field04|key01|key02|
+-------------------+-------+-------+-----+-----+
|2020-04-01 11:22:01| 99| 88.88| AAA|COR01|
|2020-04-01 11:22:01| 88| 77.77| AAA|COR02|
|2020-04-01 11:22:01| 77| 66.66| BBB|COR01|
|2020-04-01 11:22:01| 66| 55.55| BBB|COR02|
|2020-04-01 11:23:02| 55| 44.44| AAA|COR01|
|2020-04-01 11:23:02| 44| 33.33| AAA|COR02|
|2020-04-01 11:23:02| 33| 22.22| BBB|COR01|
|2020-04-01 11:23:02| 22| 11.11| BBB|COR02|
|2020-04-01 11:24:03| 11| 11.11| CCC|COR01|
|2020-04-01 11:24:03| 22| 22.22| CCC|COR01|
|2020-04-01 11:24:03| 33| 33.33| CCC|COR01|
|2020-04-01 11:25:04| 11| 11.11| DDD|COR01|
|2020-04-01 11:26:05| 12| 34.56| FFF|COR01|
|2020-04-01 11:26:05| 23| 45.67| FFF|COR02|
|2020-05-02 11:22:01| 99| 88.88| AAA|COR01|
|2020-05-02 11:22:01| 88| 77.77| AAA|COR02|
|2020-05-02 11:22:01| 77| 66.66| BBB|COR01|
|2020-05-02 11:22:01| 66| 55.55| BBB|COR02|
|2020-05-02 11:23:02| 55| 44.44| AAA|COR01|
|2020-05-02 11:23:02| 44| 33.33| AAA|COR02|
+-------------------+-------+-------+-----+-----+
only showing top 20 rows
scala> df02.printSchema
root
|-- @timestamp: timestamp (nullable = true)
|-- field03: long (nullable = true)
|-- field04: float (nullable = true)
|-- key01: string (nullable = true)
|-- key02: string (nullable = true)
読み込んだ2つのデータをJoin
@timestamp, key01, key02をキーとしてdf01とdf02をleft joinし、結果をdf03として作成します。
scala> :paste
// Entering paste mode (ctrl-D to finish)
val df03 = {
df01
.join(df02, Seq("@timestamp","key01","key02"), "left")
}
// Exiting paste mode, now interpreting.
df03: org.apache.spark.sql.DataFrame = [@timestamp: timestamp, key01: string ... 5 more fields]
scala> df03.show
+-------------------+-----+-----+-------+-------+-------+-------+
| @timestamp|key01|key02|field01|field02|field03|field04|
+-------------------+-----+-----+-------+-------+-------+-------+
|2020-04-01 11:25:04| DDD|COR01| 11| 11.11| 11| 11.11|
|2020-04-01 11:25:04| DDD|COR01| 22| 22.22| 11| 11.11|
|2020-04-01 11:25:04| DDD|COR01| 33| 33.33| 11| 11.11|
|2020-05-02 11:26:05| EEE|COR01| 12| 34.56| null| null|
|2020-05-02 11:23:02| AAA|COR01| 55| 66.66| 55| 44.44|
|2020-04-01 11:26:05| EEE|COR02| 23| 45.67| null| null|
|2020-05-02 11:22:01| BBB|COR02| 44| 55.55| 66| 55.55|
|2020-05-02 11:23:02| AAA|COR02| 66| 77.77| 44| 33.33|
|2020-04-01 11:24:03| CCC|COR01| 11| 11.11| 11| 11.11|
|2020-04-01 11:24:03| CCC|COR01| 11| 11.11| 22| 22.22|
|2020-04-01 11:24:03| CCC|COR01| 11| 11.11| 33| 33.33|
|2020-04-01 11:22:01| AAA|COR01| 11| 22.22| 99| 88.88|
|2020-04-01 11:23:02| BBB|COR01| 77| 88.88| 33| 22.22|
|2020-05-02 11:26:05| EEE|COR02| 23| 45.67| null| null|
|2020-04-01 11:23:02| BBB|COR02| 88| 99.99| 22| 11.11|
|2020-04-01 11:23:02| AAA|COR01| 55| 66.66| 55| 44.44|
|2020-05-02 11:22:01| BBB|COR01| 33| 44.44| 77| 66.66|
|2020-04-01 11:22:01| BBB|COR01| 33| 44.44| 77| 66.66|
|2020-04-01 11:26:05| EEE|COR01| 12| 34.56| null| null|
|2020-05-02 11:22:01| AAA|COR02| 22| 33.33| 88| 77.77|
+-------------------+-----+-----+-------+-------+-------+-------+
only showing top 20 rows
scala> df03.printSchema
root
|-- @timestamp: timestamp (nullable = true)
|-- key01: string (nullable = true)
|-- key02: string (nullable = true)
|-- field01: long (nullable = true)
|-- field02: float (nullable = true)
|-- field03: long (nullable = true)
|-- field04: float (nullable = true)
Elasticsearchに結果を書き込み
joinした結果をsample-data03というindex名でElasticsearchに投入します。
scala> :paste
// Entering paste mode (ctrl-D to finish)
df03.write
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port","9200")
.option("es_resource", "sample-data03")
.save()
// Exiting paste mode, now interpreting.
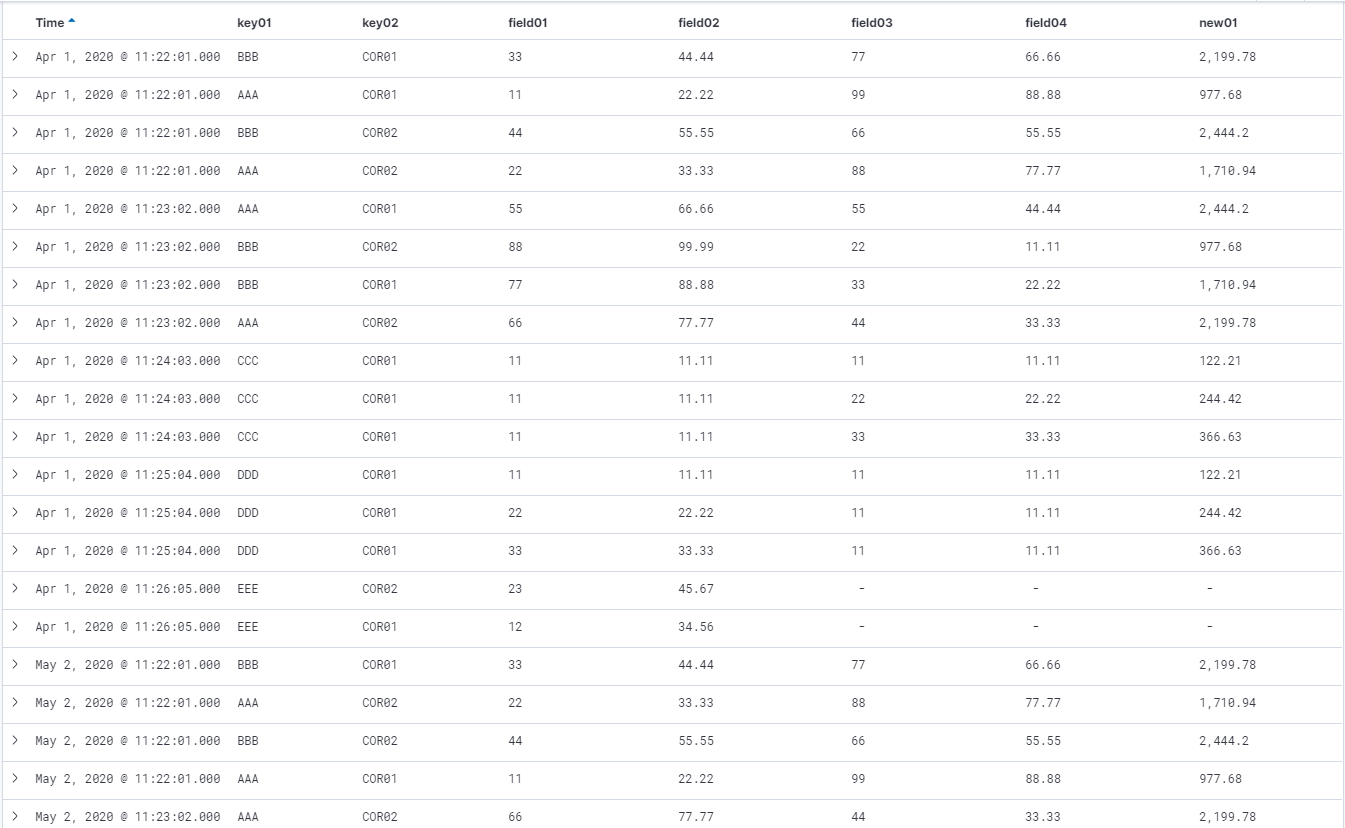
Kibana上でもこんな感じにsample-data03のデータが確認できるようになりました。
これで、2つのindexをjoinする単純ケースが確認できました。
データの加工
上の例は、単純に2つのindexをjoinしただけですが、もう少し手を加える場合を考えてみます。
大量データがあった場合、全カラムを扱うと処理が重くなるので、必要なカラムだけ抽出して操作したい(列の絞り込み)、あるいは、時系列データなどの場合は、ある範囲の時間帯のみのデータに絞りたい(行の絞り込み)、ということがあると思います。
また、複数の列の内容を計算させて新しい列を作るとか、そういう列単位の加工もしたいケースがあると思います。
その辺りやってみます。
※これ以降は、Elasticsearchとは直接的には関係なく、Spark上でのデータフレームの操作が中心です。
列の絞り込み(select)
selectで必要なカラムのみ選択できます。
scala> :paste
// Entering paste mode (ctrl-D to finish)
val df01 = {
spark.read
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port", "9200")
.option("es.resource", "sample-data01")
.load()
.select($"@timestamp",$"key01",$"key02",$"field01")
}
// Exiting paste mode, now interpreting.
df01: org.apache.spark.sql.DataFrame = [@timestamp: timestamp, key01: string ... 2 more fields]
scala> df01.show
+-------------------+-----+-----+-------+
| @timestamp|key01|key02|field01|
+-------------------+-----+-----+-------+
|2020-04-01 11:22:01| AAA|COR01| 11|
|2020-04-01 11:22:01| AAA|COR02| 22|
|2020-04-01 11:22:01| BBB|COR01| 33|
|2020-04-01 11:22:01| BBB|COR02| 44|
|2020-04-01 11:23:02| AAA|COR01| 55|
|2020-04-01 11:23:02| AAA|COR02| 66|
|2020-04-01 11:23:02| BBB|COR01| 77|
|2020-04-01 11:23:02| BBB|COR02| 88|
|2020-04-01 11:24:03| CCC|COR01| 11|
|2020-04-01 11:25:04| DDD|COR01| 11|
|2020-04-01 11:25:04| DDD|COR01| 22|
|2020-04-01 11:25:04| DDD|COR01| 33|
|2020-04-01 11:26:05| EEE|COR01| 12|
|2020-04-01 11:26:05| EEE|COR02| 23|
|2020-05-02 11:22:01| AAA|COR01| 11|
|2020-05-02 11:22:01| AAA|COR02| 22|
|2020-05-02 11:22:01| BBB|COR01| 33|
|2020-05-02 11:22:01| BBB|COR02| 44|
|2020-05-02 11:23:02| AAA|COR01| 55|
|2020-05-02 11:23:02| AAA|COR02| 66|
+-------------------+-----+-----+-------+
only showing top 20 rows
行の絞り込み(filter)
条件に合致した列のみ抽出するにはfilterが使えます。色々とバリエーションはあると思いますが、いくつかのケースでやってみます。(ここでは、上のselectに加えてfilterを指定しています。)
filter条件は、AND条件、OR条件をそれぞれ &&, || でつなげて複数指定できます。
まず、時系列データの時刻範囲を指定してみます。
.filter($"@timestamp" >= "2020-04-01 11:23:02" && $"@timestamp" < "2020-04-01 11:26:05")
scala> :paste
// Entering paste mode (ctrl-D to finish)
val df01 = {
spark.read
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port", "9200")
.option("es.resource", "sample-data01")
.load()
.select($"@timestamp",$"key01",$"key02",$"field01")
.filter($"@timestamp" >= "2020-04-01 11:23:02" && $"@timestamp" < "2020-04-01 11:26:05")
}
// Exiting paste mode, now interpreting.
df01: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [@timestamp: timestamp, key01: string ... 2 more fields]
scala> df01.show
+-------------------+-----+-----+-------+
| @timestamp|key01|key02|field01|
+-------------------+-----+-----+-------+
|2020-04-01 11:23:02| AAA|COR01| 55|
|2020-04-01 11:23:02| AAA|COR02| 66|
|2020-04-01 11:23:02| BBB|COR01| 77|
|2020-04-01 11:23:02| BBB|COR02| 88|
|2020-04-01 11:24:03| CCC|COR01| 11|
|2020-04-01 11:25:04| DDD|COR01| 11|
|2020-04-01 11:25:04| DDD|COR01| 22|
|2020-04-01 11:25:04| DDD|COR01| 33|
+-------------------+-----+-----+-------+
日付単位で絞り込みを行いたい場合はこんな感じでできます。
.filter(to_date($"@timestamp") > "2020-04-01")
scala> :paste
// Entering paste mode (ctrl-D to finish)
val df01 = {
spark.read
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port", "9200")
.option("es.resource", "sample-data01")
.load()
.select($"@timestamp",$"key01",$"key02",$"field01")
.filter(to_date($"@timestamp") > "2020-04-01")
}
// Exiting paste mode, now interpreting.
df01: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [@timestamp: timestamp, key01: string ... 2 more fields]
scala> df01.show
+-------------------+-----+-----+-------+
| @timestamp|key01|key02|field01|
+-------------------+-----+-----+-------+
|2020-05-02 11:22:01| AAA|COR01| 11|
|2020-05-02 11:22:01| AAA|COR02| 22|
|2020-05-02 11:22:01| BBB|COR01| 33|
|2020-05-02 11:22:01| BBB|COR02| 44|
|2020-05-02 11:23:02| AAA|COR01| 55|
|2020-05-02 11:23:02| AAA|COR02| 66|
|2020-05-02 11:23:02| BBB|COR01| 77|
|2020-05-02 11:23:02| BBB|COR02| 88|
|2020-05-02 11:24:03| CCC|COR01| 11|
|2020-05-02 11:25:04| DDD|COR01| 11|
|2020-05-02 11:25:04| DDD|COR01| 22|
|2020-05-02 11:25:04| DDD|COR01| 33|
|2020-05-02 11:26:05| EEE|COR01| 12|
|2020-05-02 11:26:05| EEE|COR02| 23|
+-------------------+-----+-----+-------+
特定のカラムが、ある特定の値と一致/不一致の条件指定
.filter(($"key01" === "AAA" || $"key01" === "EEE") && $"key02" =!= "COR01")
この条件指定例は、「key01がAAAまたはEEEで、key02がCOR01ではないもの」を抽出した例です。
一致、不一致はそれぞれ、===, =!=で指定します。
scala> :paste
// Entering paste mode (ctrl-D to finish)
val df01 = {
spark.read
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port", "9200")
.option("es.resource", "sample-data01")
.load()
.select($"@timestamp",$"key01",$"key02",$"field01")
.filter(($"key01" === "AAA" || $"key01" === "EEE") && $"key02" =!= "COR01")
}
// Exiting paste mode, now interpreting.
df01: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [@timestamp: timestamp, key01: string ... 2 more fields]
scala> df01.show
+-------------------+-----+-----+-------+
| @timestamp|key01|key02|field01|
+-------------------+-----+-----+-------+
|2020-04-01 11:22:01| AAA|COR02| 22|
|2020-04-01 11:23:02| AAA|COR02| 66|
|2020-04-01 11:26:05| EEE|COR02| 23|
|2020-05-02 11:22:01| AAA|COR02| 22|
|2020-05-02 11:23:02| AAA|COR02| 66|
|2020-05-02 11:26:05| EEE|COR02| 23|
+-------------------+-----+-----+-------+
列単位の加工
上で抽出したdf01というデータフレームを元に、列単位でデータを加工するパターンをいくつか試してみます。
(1) field01の値に一定の計算処理をして、それを別の列として追加してみます。
ここでは、field01の値を10倍して+5したnew01という列を追加し、新たにdf04というデータフレームを作成しています。
scala> var df04 = df01.withColumn("new01", ($"field01" * 10) + 5)
df04: org.apache.spark.sql.DataFrame = [@timestamp: timestamp, key01: string ... 3 more fields]
scala> df04.show
+-------------------+-----+-----+-------+-----+
| @timestamp|key01|key02|field01|new01|
+-------------------+-----+-----+-------+-----+
|2020-04-01 11:22:01| AAA|COR02| 22| 225|
|2020-04-01 11:23:02| AAA|COR02| 66| 665|
|2020-04-01 11:26:05| EEE|COR02| 23| 235|
|2020-05-02 11:22:01| AAA|COR02| 22| 225|
|2020-05-02 11:23:02| AAA|COR02| 66| 665|
|2020-05-02 11:26:05| EEE|COR02| 23| 235|
+-------------------+-----+-----+-------+-----+
(2) field01の最小、最大、平均を取得してみます。
scala> df01.agg(min($"field01"),mean($"field01"),max($"field01")).show
+------------+------------+------------+
|min(field01)|avg(field01)|max(field01)|
+------------+------------+------------+
| 22| 37.0| 66|
+------------+------------+------------+
scala> val field01_summary=df01.agg(min($"field01"),mean($"field01"),max($"field01")).head()
field01_summary: org.apache.spark.sql.Row = [22,37.0,66]
scala> val field01_min=field01_summary(0)
field01_min: Any = 22
scala> val field01_ave=field01_summary(1)
field01_ave: Any = 37.0
scala> val field01_max=field01_summary(2)
field01_max: Any = 66
(3) (2)で取得したfield01の平均と、field01の差分を示す列を追加してみます。
scala> var df04 = df01.withColumn("diff_ave", ($"field01" - field01_ave))
df04: org.apache.spark.sql.DataFrame = [@timestamp: timestamp, key01: string ... 3 more fields]
scala> df04.show
+-------------------+-----+-----+-------+--------+
| @timestamp|key01|key02|field01|diff_ave|
+-------------------+-----+-----+-------+--------+
|2020-04-01 11:22:01| AAA|COR02| 22| -15.0|
|2020-04-01 11:23:02| AAA|COR02| 66| 29.0|
|2020-04-01 11:26:05| EEE|COR02| 23| -14.0|
|2020-05-02 11:22:01| AAA|COR02| 22| -15.0|
|2020-05-02 11:23:02| AAA|COR02| 66| 29.0|
|2020-05-02 11:26:05| EEE|COR02| 23| -14.0|
+-------------------+-----+-----+-------+--------+
(4) (2)で取得したfield01の最大値を一律指定した列を追加してみます。
scala> var df04 = df01.withColumn("max", lit(field01_max))
df04: org.apache.spark.sql.DataFrame = [@timestamp: timestamp, key01: string ... 3 more fields]
scala> df04.show
+-------------------+-----+-----+-------+---+
| @timestamp|key01|key02|field01|max|
+-------------------+-----+-----+-------+---+
|2020-04-01 11:22:01| AAA|COR02| 22| 66|
|2020-04-01 11:23:02| AAA|COR02| 66| 66|
|2020-04-01 11:26:05| EEE|COR02| 23| 66|
|2020-05-02 11:22:01| AAA|COR02| 22| 66|
|2020-05-02 11:23:02| AAA|COR02| 66| 66|
|2020-05-02 11:26:05| EEE|COR02| 23| 66|
+-------------------+-----+-----+-------+---+
(5) field01,maxの2つの列の計算処理をし、結果を別の列に追加してみます。
scala> df04 = df04.withColumn("percentage", $"field01" / $"max" * 100)
df04: org.apache.spark.sql.DataFrame = [@timestamp: timestamp, key01: string ... 4 more fields]
scala> df04.show
+-------------------+-----+-----+-------+---+-----------------+
| @timestamp|key01|key02|field01|max| percentage|
+-------------------+-----+-----+-------+---+-----------------+
|2020-04-01 11:22:01| AAA|COR02| 22| 66|33.33333333333333|
|2020-04-01 11:23:02| AAA|COR02| 66| 66| 100.0|
|2020-04-01 11:26:05| EEE|COR02| 23| 66|34.84848484848485|
|2020-05-02 11:22:01| AAA|COR02| 22| 66|33.33333333333333|
|2020-05-02 11:23:02| AAA|COR02| 66| 66| 100.0|
|2020-05-02 11:26:05| EEE|COR02| 23| 66|34.84848484848485|
+-------------------+-----+-----+-------+---+-----------------+
複数データフレームの連結(union)
Elasticsearch上のIndexは日付単位などに分かれて保持されていることも多いかと思います。複数Indexにまたがるデータをまとめて取り扱いたい場合など、複数回データフレームにIndexを読み込んで、それらを1つのデータフレームにまとめて操作をしたいことがあるかもしれません。
同じ構造の複数のデータフレームをまとめるにはunionが使えます(スキーマが一致している必要あり)。
ここでは疑似的に、sample-data01から以下のように2つのデータフレームを作ります。
scala> :paste
// Entering paste mode (ctrl-D to finish)
val df01_A = {
spark.read
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port", "9200")
.option("es.resource", "sample-data01")
.load()
.filter($"key01" === "AAA")
}
// Exiting paste mode, now interpreting.
df01_A: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [@timestamp: timestamp, field01: bigint ... 3 more fields]
scala> df01_A.show
+-------------------+-------+-------+-----+-----+
| @timestamp|field01|field02|key01|key02|
+-------------------+-------+-------+-----+-----+
|2020-04-01 11:22:01| 11| 22.22| AAA|COR01|
|2020-04-01 11:22:01| 22| 33.33| AAA|COR02|
|2020-04-01 11:23:02| 55| 66.66| AAA|COR01|
|2020-04-01 11:23:02| 66| 77.77| AAA|COR02|
|2020-05-02 11:22:01| 11| 22.22| AAA|COR01|
|2020-05-02 11:22:01| 22| 33.33| AAA|COR02|
|2020-05-02 11:23:02| 55| 66.66| AAA|COR01|
|2020-05-02 11:23:02| 66| 77.77| AAA|COR02|
+-------------------+-------+-------+-----+-----+
scala> :paste
// Entering paste mode (ctrl-D to finish)
val df01_B = {
spark.read
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port", "9200")
.option("es.resource", "sample-data01")
.load()
.filter($"key01" === "BBB")
}
// Exiting paste mode, now interpreting.
df01_B: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [@timestamp: timestamp, field01: bigint ... 3 more fields]
scala> df01_B.show
+-------------------+-------+-------+-----+-----+
| @timestamp|field01|field02|key01|key02|
+-------------------+-------+-------+-----+-----+
|2020-04-01 11:22:01| 33| 44.44| BBB|COR01|
|2020-04-01 11:22:01| 44| 55.55| BBB|COR02|
|2020-04-01 11:23:02| 77| 88.88| BBB|COR01|
|2020-04-01 11:23:02| 88| 99.99| BBB|COR02|
|2020-05-02 11:22:01| 33| 44.44| BBB|COR01|
|2020-05-02 11:22:01| 44| 55.55| BBB|COR02|
|2020-05-02 11:23:02| 77| 88.88| BBB|COR01|
|2020-05-02 11:23:02| 88| 99.99| BBB|COR02|
+-------------------+-------+-------+-----+-----+
df01_Aとdf01_Bを結合します。
scala> val df01_AB = df01_A.union(df01_B)
df01_AB: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [@timestamp: timestamp, field01: bigint ... 3 more fields]
scala> df01_AB.show
+-------------------+-------+-------+-----+-----+
| @timestamp|field01|field02|key01|key02|
+-------------------+-------+-------+-----+-----+
|2020-04-01 11:22:01| 11| 22.22| AAA|COR01|
|2020-04-01 11:22:01| 22| 33.33| AAA|COR02|
|2020-04-01 11:23:02| 55| 66.66| AAA|COR01|
|2020-04-01 11:23:02| 66| 77.77| AAA|COR02|
|2020-05-02 11:22:01| 11| 22.22| AAA|COR01|
|2020-05-02 11:22:01| 22| 33.33| AAA|COR02|
|2020-05-02 11:23:02| 55| 66.66| AAA|COR01|
|2020-05-02 11:23:02| 66| 77.77| AAA|COR02|
|2020-04-01 11:22:01| 33| 44.44| BBB|COR01|
|2020-04-01 11:22:01| 44| 55.55| BBB|COR02|
|2020-04-01 11:23:02| 77| 88.88| BBB|COR01|
|2020-04-01 11:23:02| 88| 99.99| BBB|COR02|
|2020-05-02 11:22:01| 33| 44.44| BBB|COR01|
|2020-05-02 11:22:01| 44| 55.55| BBB|COR02|
|2020-05-02 11:23:02| 77| 88.88| BBB|COR01|
|2020-05-02 11:23:02| 88| 99.99| BBB|COR02|
+-------------------+-------+-------+-----+-----+
スタンドアロンアプリの作成
ここまでは、spark-shellによるインタラクティブな操作を行う例を見てきましたが、それらを踏まえて、スタンドアロンのアプリとしてElasticsearchのデータを加工するプログラムを作成してみます。
言語はそのままScalaを使い、ビルドツールはsbtを使用します。
開発
以下のような構造で、ビルド定義 build.sbtとソース ElasticSample01.scalaを作ります。
[root@test08 ~/Spark/elastic01]# tree --charset -C .
.
|-- build.sbt
`-- src
`-- main
`-- scala
`-- ElasticSample01.scala
3 directories, 2 files
name := "ElasticSampleProject01"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-sql" % "2.4.5",
"org.elasticsearch" %% "elasticsearch-spark-20" % "7.6.2"
)
/* ElasticSample01.scala */
import org.apache.spark.sql.SparkSession
import org.elasticsearch.spark._
import org.apache.spark.sql.functions._
object ElasticSample01 {
def main(args: Array[String]) {
val spark = SparkSession.builder.appName("ElasticSample01").getOrCreate()
import spark.implicits._
println("******** read sample-data01 from Elasticsearch")
val df01 = {
spark.read
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port", "9200")
.option("es.resource", "sample-data01")
.load()
}
df01.show()
println("******** read sample-data02 from Elasticsearch")
val df02 = {
spark.read
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port", "9200")
.option("es.resource", "sample-data02")
.load()
}
df02.show()
println("******** join")
var df03 = {
df01
.join(df02, Seq("@timestamp","key01","key02"), "left")
}
df03.show()
println("******** add new field")
df03 = df03.withColumn("new01", $"field01" * $"field04")
df03.show()
println("******** write sample-data03 to Elasticsearch")
df03.write
.format("org.elasticsearch.spark.sql")
.option("es.nodes", "localhost")
.option("es.port","9200")
.option("es_resource", "sample-data03")
.save()
spark.stop()
}
}
このアプリでは、sample-data01とsample-data02を読み取って、@timestamp, key01, key02をキーにleft joinしています。さらに、field01とfield04を掛算した結果をnew01というフィールドに追加し、その結果をsample-data03という名前のIndexでElasticsearchに書き込んでいます。
補足:
データフレームのカラムを指定するところで$"field01"という書き方をしてますが、これを使用するには、import spark.implicits._を指定する必要がありました(指定位置に注意)。
代わりにcol("field01")という書き方もできますが、その場合は先頭にimport org.apache.spark.sql.functions._が必要になります。
コンパイル
[root@test08 ~/Spark/elastic01]# sbt package
[info] Loading project definition from /root/Spark/elastic01/project
[info] Loading settings for project elastic01 from build.sbt ...
[info] Set current project to ElasticSampleProject01 (in build file:/root/Spark/elastic01/)
[warn] There may be incompatibilities among your library dependencies; run 'evicted' to see detailed eviction warnings.
[success] Total time: 5 s, completed 2020/04/25 11:27:34
~/Spark/elastic01/targtet/scala-2.11/elasticsampleproject01_2.11-1.0.jar が生成されました。
実行
[root@test08 ~/Spark/elastic01]# spark-submit --class ElasticSample01 --master local[*] --jars /Inst_Image/elastic/elasticsearch-spark-20_2.11-7.6.2.jar target/scala-
2.11/elasticsampleproject01_2.11-1.0.jar
20/04/25 11:57:48 WARN Utils: Your hostname, test08 resolves to a loopback address: 127.0.0.1; using 10.0.2.15 instead (on interface enp0s3)
20/04/25 11:57:48 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/04/25 11:57:49 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
20/04/25 11:57:49 INFO SparkContext: Running Spark version 2.4.5
20/04/25 11:57:49 INFO SparkContext: Submitted application: ElasticSample01
20/04/25 11:57:49 INFO SecurityManager: Changing view acls to: root
20/04/25 11:57:49 INFO SecurityManager: Changing modify acls to: root
20/04/25 11:57:49 INFO SecurityManager: Changing view acls groups to:
20/04/25 11:57:49 INFO SecurityManager: Changing modify acls groups to:
20/04/25 11:57:49 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
...
******** read sample-data01 from Elasticsearch
...
20/04/25 11:57:54 INFO DAGScheduler: Job 0 finished: show at ElasticSample01.scala:21, took 0.520051 s
+-------------------+-------+-------+-----+-----+
| @timestamp|field01|field02|key01|key02|
+-------------------+-------+-------+-----+-----+
|2020-04-01 11:22:01| 11| 22.22| AAA|COR01|
|2020-04-01 11:22:01| 22| 33.33| AAA|COR02|
|2020-04-01 11:22:01| 33| 44.44| BBB|COR01|
|2020-04-01 11:22:01| 44| 55.55| BBB|COR02|
|2020-04-01 11:23:02| 55| 66.66| AAA|COR01|
|2020-04-01 11:23:02| 66| 77.77| AAA|COR02|
|2020-04-01 11:23:02| 77| 88.88| BBB|COR01|
|2020-04-01 11:23:02| 88| 99.99| BBB|COR02|
|2020-04-01 11:24:03| 11| 11.11| CCC|COR01|
|2020-04-01 11:25:04| 11| 11.11| DDD|COR01|
|2020-04-01 11:25:04| 22| 22.22| DDD|COR01|
|2020-04-01 11:25:04| 33| 33.33| DDD|COR01|
|2020-04-01 11:26:05| 12| 34.56| EEE|COR01|
|2020-04-01 11:26:05| 23| 45.67| EEE|COR02|
|2020-05-02 11:22:01| 11| 22.22| AAA|COR01|
|2020-05-02 11:22:01| 22| 33.33| AAA|COR02|
|2020-05-02 11:22:01| 33| 44.44| BBB|COR01|
|2020-05-02 11:22:01| 44| 55.55| BBB|COR02|
|2020-05-02 11:23:02| 55| 66.66| AAA|COR01|
|2020-05-02 11:23:02| 66| 77.77| AAA|COR02|
+-------------------+-------+-------+-----+-----+
only showing top 20 rows
...
******** read sample-data02 from Elasticsearch
...
20/04/25 11:57:54 INFO DAGScheduler: Job 1 finished: show at ElasticSample01.scala:33, took 0.048927 s
+-------------------+-------+-------+-----+-----+
| @timestamp|field03|field04|key01|key02|
+-------------------+-------+-------+-----+-----+
|2020-04-01 11:22:01| 99| 88.88| AAA|COR01|
|2020-04-01 11:22:01| 88| 77.77| AAA|COR02|
|2020-04-01 11:22:01| 77| 66.66| BBB|COR01|
|2020-04-01 11:22:01| 66| 55.55| BBB|COR02|
|2020-04-01 11:23:02| 55| 44.44| AAA|COR01|
|2020-04-01 11:23:02| 44| 33.33| AAA|COR02|
|2020-04-01 11:23:02| 33| 22.22| BBB|COR01|
|2020-04-01 11:23:02| 22| 11.11| BBB|COR02|
|2020-04-01 11:24:03| 11| 11.11| CCC|COR01|
|2020-04-01 11:24:03| 22| 22.22| CCC|COR01|
|2020-04-01 11:24:03| 33| 33.33| CCC|COR01|
|2020-04-01 11:25:04| 11| 11.11| DDD|COR01|
|2020-04-01 11:26:05| 12| 34.56| FFF|COR01|
|2020-04-01 11:26:05| 23| 45.67| FFF|COR02|
|2020-05-02 11:22:01| 99| 88.88| AAA|COR01|
|2020-05-02 11:22:01| 88| 77.77| AAA|COR02|
|2020-05-02 11:22:01| 77| 66.66| BBB|COR01|
|2020-05-02 11:22:01| 66| 55.55| BBB|COR02|
|2020-05-02 11:23:02| 55| 44.44| AAA|COR01|
|2020-05-02 11:23:02| 44| 33.33| AAA|COR02|
+-------------------+-------+-------+-----+-----+
only showing top 20 rows
...
******** join
...
20/04/25 11:57:56 INFO DAGScheduler: Job 6 finished: show at ElasticSample01.scala:40, took 0.217572 s
+-------------------+-----+-----+-------+-------+-------+-------+
| @timestamp|key01|key02|field01|field02|field03|field04|
+-------------------+-----+-----+-------+-------+-------+-------+
|2020-04-01 11:25:04| DDD|COR01| 11| 11.11| 11| 11.11|
|2020-04-01 11:25:04| DDD|COR01| 22| 22.22| 11| 11.11|
|2020-04-01 11:25:04| DDD|COR01| 33| 33.33| 11| 11.11|
|2020-05-02 11:26:05| EEE|COR01| 12| 34.56| null| null|
|2020-05-02 11:23:02| AAA|COR01| 55| 66.66| 55| 44.44|
|2020-04-01 11:26:05| EEE|COR02| 23| 45.67| null| null|
|2020-05-02 11:22:01| BBB|COR02| 44| 55.55| 66| 55.55|
|2020-05-02 11:23:02| AAA|COR02| 66| 77.77| 44| 33.33|
|2020-04-01 11:24:03| CCC|COR01| 11| 11.11| 11| 11.11|
|2020-04-01 11:24:03| CCC|COR01| 11| 11.11| 22| 22.22|
|2020-04-01 11:24:03| CCC|COR01| 11| 11.11| 33| 33.33|
|2020-04-01 11:22:01| AAA|COR01| 11| 22.22| 99| 88.88|
|2020-04-01 11:23:02| BBB|COR01| 77| 88.88| 33| 22.22|
|2020-05-02 11:26:05| EEE|COR02| 23| 45.67| null| null|
|2020-04-01 11:23:02| BBB|COR02| 88| 99.99| 22| 11.11|
|2020-04-01 11:23:02| AAA|COR01| 55| 66.66| 55| 44.44|
|2020-05-02 11:22:01| BBB|COR01| 33| 44.44| 77| 66.66|
|2020-04-01 11:22:01| BBB|COR01| 33| 44.44| 77| 66.66|
|2020-04-01 11:26:05| EEE|COR01| 12| 34.56| null| null|
|2020-05-02 11:22:01| AAA|COR02| 22| 33.33| 88| 77.77|
+-------------------+-----+-----+-------+-------+-------+-------+
only showing top 20 rows
...
******** add new field
...
20/04/25 11:57:58 INFO DAGScheduler: Job 11 finished: show at ElasticSample01.scala:44, took 0.172990 s
+-------------------+-----+-----+-------+-------+-------+-------+---------+
| @timestamp|key01|key02|field01|field02|field03|field04| new01|
+-------------------+-----+-----+-------+-------+-------+-------+---------+
|2020-04-01 11:25:04| DDD|COR01| 11| 11.11| 11| 11.11| 122.21|
|2020-04-01 11:25:04| DDD|COR01| 22| 22.22| 11| 11.11| 244.42|
|2020-04-01 11:25:04| DDD|COR01| 33| 33.33| 11| 11.11|366.62997|
|2020-05-02 11:26:05| EEE|COR01| 12| 34.56| null| null| null|
|2020-05-02 11:23:02| AAA|COR01| 55| 66.66| 55| 44.44| 2444.2|
|2020-04-01 11:26:05| EEE|COR02| 23| 45.67| null| null| null|
|2020-05-02 11:22:01| BBB|COR02| 44| 55.55| 66| 55.55| 2444.2|
|2020-05-02 11:23:02| AAA|COR02| 66| 77.77| 44| 33.33| 2199.78|
|2020-04-01 11:24:03| CCC|COR01| 11| 11.11| 11| 11.11| 122.21|
|2020-04-01 11:24:03| CCC|COR01| 11| 11.11| 22| 22.22| 244.42|
|2020-04-01 11:24:03| CCC|COR01| 11| 11.11| 33| 33.33| 366.63|
|2020-04-01 11:22:01| AAA|COR01| 11| 22.22| 99| 88.88| 977.68|
|2020-04-01 11:23:02| BBB|COR01| 77| 88.88| 33| 22.22| 1710.94|
|2020-05-02 11:26:05| EEE|COR02| 23| 45.67| null| null| null|
|2020-04-01 11:23:02| BBB|COR02| 88| 99.99| 22| 11.11| 977.68|
|2020-04-01 11:23:02| AAA|COR01| 55| 66.66| 55| 44.44| 2444.2|
|2020-05-02 11:22:01| BBB|COR01| 33| 44.44| 77| 66.66| 2199.78|
|2020-04-01 11:22:01| BBB|COR01| 33| 44.44| 77| 66.66| 2199.78|
|2020-04-01 11:26:05| EEE|COR01| 12| 34.56| null| null| null|
|2020-05-02 11:22:01| AAA|COR02| 22| 33.33| 88| 77.77| 1710.94|
+-------------------+-----+-----+-------+-------+-------+-------+---------+
only showing top 20 rows
...
******** write sample-data03 to Elasticsearch
...
こんな感じで実行できました。
補足: spark-submitコマンドの--jarsオプションで、elasticsearch-sparkコネクタのjarを明示していしないとClass Not Foundでエラーになってしまいました。sbtってその辺の依存関係をよろしくやってくれるんじゃないの?と思うのですが、ちょっとこの辺で力尽きたので必要に迫られたら調べることにします。
Kibanaでみても、ちゃんと意図したようにIndex作成されてました。