1. 概要と動機
[背景]
Elasticsearchをクラスタ構築してSparkでデータを投入するまでの手順を記載しています。
[動機]
- Elasticsearchが流行っているので触ってみたかった。
- 機械学習の自然言語分類で教師データを作るときに、母体のデータから教師データっぽいものを持ってくるために、全文検索が使えないか検討したかった。
- Elasticsearch以外の選択肢として、MySQL8の全文検索機能、MySQL+Mronngaを検討中ですが、indexの再構築の効率性とかを考えたときにスケールアウトしやすいほうがいいんじゃないかって思って検証してみようかと..
- 母体のデータをHDFSに持っていたのと、Sparkが入れようと思っている基盤に入っているので、使えないかと思いました。
[環境情報]
- OS: CentOS7
- Elasticsearchバージョン: 6.4
- Kibanaバージョン: 6.4
- Sparkバージョン: 2.2.0 // バージョンは2.xであればOK
- elasticsearch-sparkコネクタのバージョン: 6.3.2
- クラスタ構成台数: 3台
- 前提条件: Java8がインストールされていること
$ java -version
openjdk version "1.8.0_171"
[参考にした情報]
- Elasticsearch:
- Kibana:
- Spark
2. Elasticsearchインストール
2.1. GPG-KEYのインポート
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2.2. yumリポジトリの設定
cat <<EOF > /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
2.3. Elasticsearchインストール
yum -y install elasticsearch
2.4. サービスの起動、自動起動設定
systemctl start elasticsearch.service
systemctl enable elasticsearch.service
2.5. ディレクトリ構成メモ
| タイプ | 説明 | デフォルトロケーション | elasticsearch.ymlの設定項目 |
|---|---|---|---|
| home | Elasticsearchのホームディレクトリ | /usr/share/elasticsearch |
- |
| bin | バイナリ系のスクリプトとpluginインストールで入るスクリプト | /usr/share/elasticsearch/bin |
- |
| config | Elasticsearchの設定ファイル | /etc/elasticsearch/elasticsearch.yml |
- |
| config | Elasticsearchの環境変数設定、ヒープサイズなど | /etc/sysconfig/elasticsearch |
- |
| data | データの格納先 | /var/lib/elasticsearch |
path.data |
| logs | ログファイルの出力先 | /var/log/elasticsearch |
path.logs |
| plugins | プラグインの格納先 | /usr/share/elasticsearch/plugins |
- |
2.6. クラスタの設定
2.6.1. 設定変更
/etc/elasticsearch/elasticsearch.ymlの設定を変更する。
変更した項目は以下。
ノード全台に対して設定する。
# クラスタ名 全ノードで揃える必要がある
cluster.name: dev-application
# ノードの名前 ここだけノードごとに変更する
node.name: node1
# listenするIP
network.host: 0.0.0.0
# HTTP接続のポート
http.port: 9200
# 新しいノードが追加されたときに、新ノードに渡すノードのリスト
# 全ノードを指定する
discovery.zen.ping.unicast.hosts: ["192.168.100.120", "192.168.100.122", "192.168.100.123"]
# マスターノードを選ぶ際の master eligible node(master候補になるノード数)
discovery.zen.minimum_master_nodes: 1
2.6.2. 設定後に再起動
sudo systemctl restart elasticsearch
2.6.3. 接続確認
# 設定したクラスタ名、台数で構築できているか確認できればOK
$ curl http://192.168.100.123:9200/_cluster/health?pretty
{
"cluster_name" : "dev-application",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
# 3台で構築できているか確認
# *のついているnode2がmaster
curl http://192.168.100.123:9200/_cat/nodes
192.168.100.120 33 23 0 0.01 0.04 0.05 mdi * node2
192.168.100.122 31 46 1 0.11 0.07 0.11 mdi - node3
192.168.100.123 23 97 0 0.00 0.02 0.05 mdi - node1
# masterノードの確認
curl http://192.168.100.123:9200/_cat/master
7Vr0NVHNRJ2LvkCGLJN4HA 192.168.100.120 192.168.100.120 node2
3. Kibanaのインストール
これはオプション。
どれかのノードにインストールしておく。
3.1. GPG-KEYのインポート
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
3.2. yumリポジトリの設定
cat <<EOF > /etc/yum.repos.d/kibana.repo
[kibana-6.x]
name=Kibana repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
3.3. Kibanaインストール
yum -y install kibana
3.4. サービスの起動、自動起動設定
systemctl start kibana.service
systemctl enable kibana.service
3.5. ディレクトリ構成メモ
| タイプ | 説明 | デフォルトロケーション | kibana.ymlの設定項目 |
|---|---|---|---|
| home | Kibanaのホームディレクトリ | /usr/share/kibana |
- |
| bin | バイナリ系のスクリプトとpluginインストールで入るスクリプト | /usr/share/kibana/bin |
- |
| config | Kibanaの設定ファイル | /etc/kibana/kibana.yml |
- |
| data | データの格納先 | /var/lib/kibana |
path.data |
| optimize | プラグインなどによってトランスコードされたソースコード。特定の管理アクション?? | /usr/share/kibana/optimize |
- |
| plugins | プラグインの格納先 | /usr/share/kibana/plugins |
- |
3.6. 設定変更
/etc/kibana/kibana.ymlの以下の部分を変更する。
# KibanaをインストールしたノードのIPを指定する
# ここがlocalhostのままだと外部から接続できない
server.host: "192.168.100.123"
# elasticsearchをインストールしたノードのどれかを指定する
elasticsearch.url: "http://192.168.100.122:9200"
再起動。
systemctl restart kibana.service
3.7. 接続確認
http://[KibanaをインストールしノードのIP]:5601/で接続できればOK。
4. Sparkのインストール
Sparkのダウンロード。ここでは2.2をダウンロードしていますが、現時点の最新バージョンをダウンロードするのがいいと思います。
cd ~
curl -O http://ftp.jaist.ac.jp/pub/apache/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
tar xvfz spark-2.2.0-bin-hadoop2.7.tgz
パスの設定
echo 'export SPARK_HOME=$HOME/spark-2.3.0-bin-hadoop2.7' >> ~/.bash_profile
echo 'export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin' >> ~/.bash_profile
source ~/.bash_profile
5. Sparkを起動してElasticsearchにデータ連携する
5.1. elsticsearch-sparkコネクタのjarダウンロード
cd $HOME
wget http://central.maven.org/maven2/org/elasticsearch/elasticsearch-spark-20_2.11/6.3.2/elasticsearch-spark-20_2.11-6.3.2.jar
5.2. テストデータの準備
# ファイルのダウンロード
wget -O /tmp/akc_breed_info.csv https://query.data.world/s/msmjhcmdjslsvjzcaqmtreu52gkuno
# データ件数の確認
wc -l /tmp/akc_breed_info.csv
150
5.3. Sparkでindexを作成する
インデックスがある場合は事前にindexを削除しておく
curl -XDELETE http://192.168.100.123:9200/index/
spark-shellを起動する。
spark-shell --jars $HOME/elasticsearch-spark-20_2.11-6.3.2.jar
scala> val df = spark.read.option("header","true").csv("file:///tmp/akc_breed_info.csv")
df: org.apache.spark.sql.DataFrame = [Breed: string, height_low_inches: string ... 3 more fields]
scala> df.show
+--------------------+-----------------+------------------+--------------+---------------+
| Breed|height_low_inches|height_high_inches|weight_low_lbs|weight_high_lbs|
+--------------------+-----------------+------------------+--------------+---------------+
| Akita| 26| 28| 80| 120|
| Anatolian Sheepdog| 27| 29| 100| 150|
|Bernese Mountain Dog| 23| 27| 85| 110|
| Bloodhound| 24| 26| 80| 120|
| Borzoi| 26| 28| 70| 100|
| Bullmastiff| 25| 27| 100| 130|
| Great Dane| 32| 32| 120| 160|
| Great Pyrenees| 27| 32| 95| 120|
|Great Swiss Mount...| 23| 28| 130| 150|
| Irish Wolfhound| 28| 35| 90| 150|
| Kuvasz| 28| 30| 70| 120|
| Mastiff| 27| 30| 175| 190|
| Neopolitan Mastiff| 24| 30| 100| 150|
| Newfoundland| 26| 28| 100| 150|
| Otter Hound| 24| 26| 65| 110|
| Rottweiler| 22| 27| 90| 110|
| Saint Bernard| 25| 28| 110| 190|
| Afghan Hound| 25| 27| 50| 60|
| Alaskan Malamute| na| na| na| na|
| American Foxhound| 22| 25| 65| 70|
+--------------------+-----------------+------------------+--------------+---------------+
only showing top 20 rows
// Elasticsearchのクラスタノードを指定します。
scala> val esURL = "192.168.100.120,192.168.100.122,192.168.100.123"
esURL: String = 192.168.100.120,192.168.100.122,192.168.100.123
scala> :paste
// Entering paste mode (ctrl-D to finish)
df.write
.format("org.elasticsearch.spark.sql")
.option("es.nodes.wan.only","false")
.option("es.port","9200")
.option("es.net.ssl","false")
.option("es.nodes", esURL)
.mode("Overwrite")
.save("sample/dogs") // index: sample, type: dogsという名前で作成
// Exiting paste mode, now interpreting.
とりあえず入ったっぽいです。
5.4. データ投入後の確認
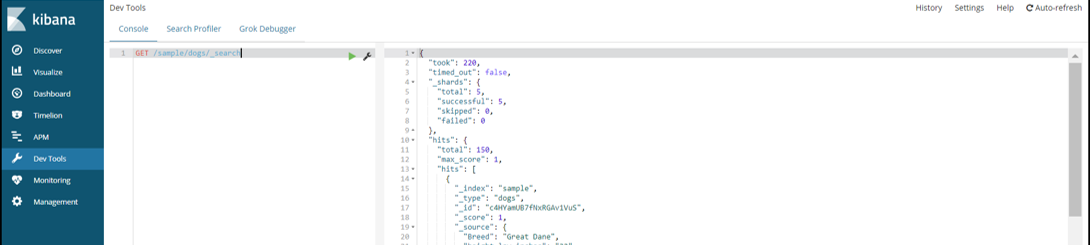
Kibanaをインストールしたので、KibanaのUIに接続して
Dev Toolsが便利そうだったのでここから..
Dev Toolsのエディタは補完が効くので使いやすかったです。
[URL]
http://[Kibanaをインストールしたノード]:5601
エディタに以下記述して、リクエストを発行して
データが投入されたか確認できます。
- 全てのドキュメントを検索
GET /sample/dogs/_search
- 指定した単語を含むドキュメント検索
GET /sample/dogs/_search
{
"query": {
"match": {
"Breed": "Rough"
}
}
}
TODO (あとで検証すること)
- 日本語形態素解析(MeCab, Kuromoji)の設定調査。
- MySQLサーバとの連携(今回はSparkと連携したが、データソースがMySQLにもあるので連携できないか調査する)