はじめに
Linux(RHEL)上にApache Spark環境を構築したときのメモです。
1ノードでとりあえず動かせればいいやという簡易構成です。
spark-shellを動かすことと、Scalaのシンプルなアプリケーションを作って動かすことが目標です。ビルドツールとしてはsbtを使用しました。
環境
RHEL V7.5
Java V1.8
Apache Spark V2.4.5 (scala V2.11.12)
sbt V1.3.10
環境構築
Javaはインストール済みの前提です。
# java -version
openjdk version "1.8.0_161"
OpenJDK Runtime Environment (build 1.8.0_161-b14)
OpenJDK 64-Bit Server VM (build 25.161-b14, mixed mode)
Apache Spark
インストール
以下から、tgzファイルをダウンロード
https://spark.apache.org/downloads.html
/opt/sparkディレクトリ作成してそこに展開
[root@test08 /Inst_Image/Spark]# ls -la
合計 227088
drwxr-xr-x. 2 root root 43 4月 25 09:06 .
drwxr-xr-x. 21 root root 4096 4月 25 08:42 ..
-rwxr-xr-x. 1 root root 232530699 4月 25 09:05 spark-2.4.5-bin-hadoop2.7.tgz
[root@test08 /Inst_Image/Spark]# mkdir /opt/spark
[root@test08 /Inst_Image/Spark]# tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /opt/spark
インストールはこれで完了です。
動作確認
動作確認のため、spark-shellを実行してみます。
[root@test08 /opt/spark/spark-2.4.5-bin-hadoop2.7/bin]# ./spark-shell
20/04/25 09:25:14 WARN Utils: Your hostname, test08 resolves to a loopback address: 127.0.0.1; using 10.0.2.15 instead (on interface enp0s3)
20/04/25 09:25:14 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/04/25 09:25:14 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://10.0.2.15:4040
Spark context available as 'sc' (master = local[*], app id = local-1587428721984).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.5
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_161)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
spark-shellが起動しました。
簡単なコードを実行してみます。
scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@2f408960
scala> val test=sc.parallelize(List("str01","str02","str03","str04","str05"))
test: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> test.take(3).foreach(println)
str01
str02
str03
spark-shell起動時に「Spark context Web UI available at http://10.0.2.15:4040」というメッセージがでています。このアドレスにブラウザからアクセスすると、Web UIにて状況確認等行うことができます。
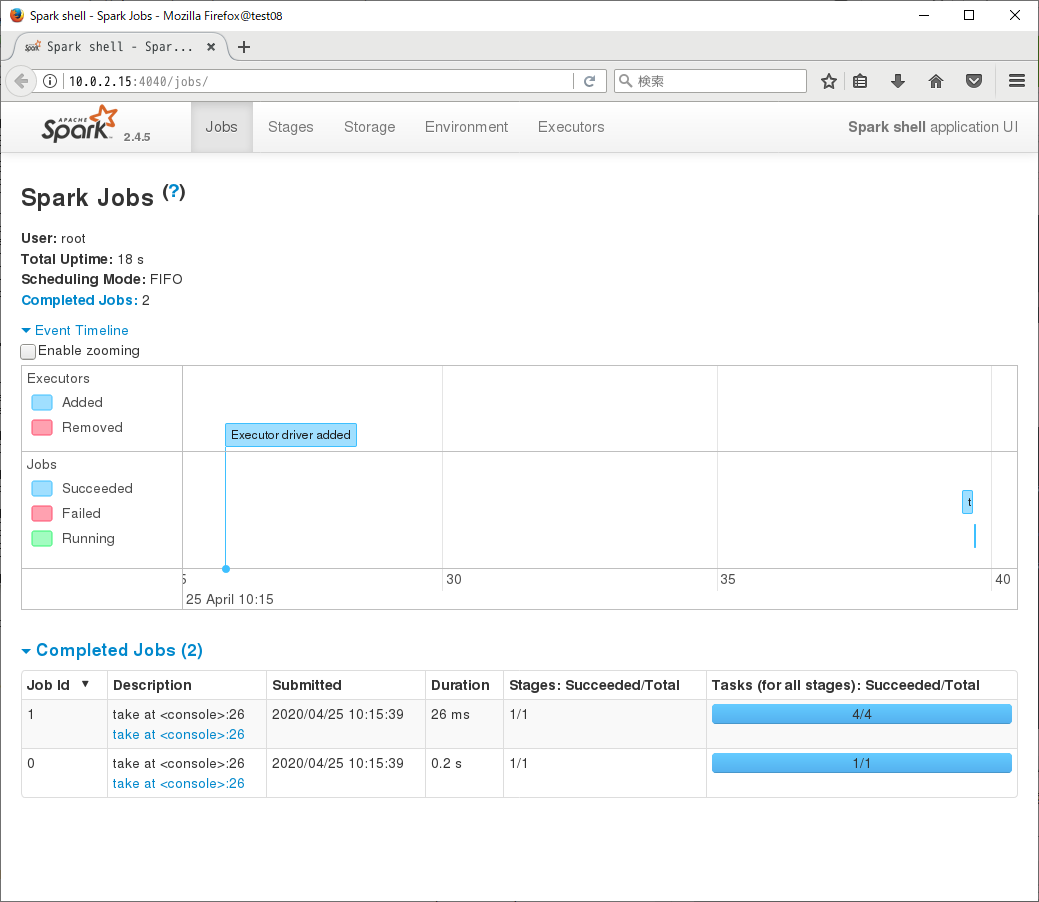
一通り動いているようなので、一旦spark-shellは 「:quit」で抜けます。
PATHに、Spark導入ディレクトリのbinを追加しておきます。
export PAHT=$PATH:/opt/spark/spark-2.4.5-bin-hadoop2.7/bin
補足: spark-shell option
[root@test08 /]# spark-shell --help
Usage: ./bin/spark-shell [options]
Scala REPL options:
-I <file> preload <file>, enforcing line-by-line interpretation
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn,
k8s://https://host:port, or local (Default: local[*]).
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.
--exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in --packages to avoid
dependency conflicts.
--repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with --packages.
--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
--files FILES Comma-separated list of files to be placed in the working
directory of each executor. File paths of these files
in executors can be accessed via SparkFiles.get(fileName).
--conf PROP=VALUE Arbitrary Spark configuration property.
--properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
This argument does not work with --principal / --keytab.
--help, -h Show this help message and exit.
--verbose, -v Print additional debug output.
--version, Print the version of current Spark.
Cluster deploy mode only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone and Mesos only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
--principal PRINCIPAL Principal to be used to login to KDC, while running on
secure HDFS.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above. This keytab will be copied to
the node running the Application Master via the Secure
Distributed Cache, for renewing the login tickets and the
delegation tokens periodically.
sbt
スタンド・アローンのアプリケーションとしてSparkのコードを動かしたいので、そのためのビルドツールをインストールします。ここではビルドツールとしてsbtを使うことにします。
インストール
[root@test08 ~]# curl https://bintray.com/sbt/rpm/rpm | tee /etc/yum.repos.d/bintray-sbt-rpm.repo
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 160 0 160 0 0 230 0 --:--:-- --:--:-- --:--:-- 231
# bintray--sbt-rpm - packages by from Bintray
[bintray--sbt-rpm]
name=bintray--sbt-rpm
baseurl=https://sbt.bintray.com/rpm
gpgcheck=0
repo_gpgcheck=0
enabled=1
[root@test08 ~]# yum install sbt
読み込んだプラグイン:langpacks, product-id, search-disabled-repos, subscription-manager
This system is not registered with an entitlement server. You can use subscription-manager to register.
bintray--sbt-rpm | 1.3 kB 00:00:00
epel/x86_64/metalink | 5.5 kB 00:00:00
epel | 4.7 kB 00:00:00
file:///run/media/root/RHEL-7.5%20Server.x86_64/repodata/repomd.xml: [Errno 14] curl#37 - "Couldn't open file /run/media/root/RHEL-7.5%20Server.x86_64/repodata/repomd.xml"
他のミラーを試します。
treasuredata | 2.9 kB 00:00:00
(1/4): epel/x86_64/group_gz | 95 kB 00:00:00
(2/4): epel/x86_64/updateinfo | 1.0 MB 00:00:00
(3/4): bintray--sbt-rpm/primary | 5.3 kB 00:00:00
(4/4): epel/x86_64/primary_db | 6.8 MB 00:00:01
bintray--sbt-rpm 49/49
依存性の解決をしています
--> トランザクションの確認を実行しています。
---> パッケージ sbt.noarch 0:1.3.10-0 を インストール
--> 依存性解決を終了しました。
依存性を解決しました
==========================================================================================================================
Package アーキテクチャー バージョン リポジトリー 容量
==========================================================================================================================
インストール中:
sbt noarch 1.3.10-0 bintray--sbt-rpm 1.2 M
トランザクションの要約
==========================================================================================================================
インストール 1 パッケージ
総ダウンロード容量: 1.2 M
インストール容量: 1.4 M
Is this ok [y/d/N]: y
Downloading packages:
sbt-1.3.10.rpm | 1.2 MB 00:00:00
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
インストール中 : sbt-1.3.10-0.noarch 1/1
検証中 : sbt-1.3.10-0.noarch 1/1
インストール:
sbt.noarch 0:1.3.10-0
完了しました!
動作確認
sbt aboutコマンドを実行してみます。最初の実行時は色々ファイルがダウンロードされたりするので時間かかります。
[root@test08 ~]# sbt about
[info] [launcher] getting org.scala-sbt sbt 1.3.10 (this may take some time)...
downloading https://repo1.maven.org/maven2/org/scala-sbt/sbt/1.3.10/sbt-1.3.10.jar ...
downloading https://repo1.maven.org/maven2/org/scala-lang/scala-library/2.12.10/scala-library-2.12.10.jar ...
:: loading settings :: url = jar:file:/usr/share/sbt/bin/sbt-launch.jar!/org/apache/ivy/core/settings/ivysettings.xml
downloading https://repo1.maven.org/maven2/org/scala-sbt/main_2.12/1.3.10/main_2.12-1.3.10.jar ...
:: loading settings :: url = jar:file:/usr/share/sbt/bin/sbt-launch.jar!/org/apache/ivy/core/settings/ivysettings.xml
:: loading settings :: url = jar:file:/usr/share/sbt/bin/sbt-launch.jar!/org/apache/ivy/core/settings/ivysettings.xml
downloading https://repo1.maven.org/maven2/org/scala-sbt/io_2.12/1.3.4/io_2.12-1.3.4.jar ...
downloading https://repo1.maven.org/maven2/org/scala-sbt/actions_2.12/1.3.10/actions_2.12-1.3.10.jar ...
:: loading settings :: url = jar:file:/usr/share/sbt/bin/sbt-launch.jar!/org/apache/ivy/core/settings/ivysettings.xml
:: loading settings :: url = jar:file:/usr/share/sbt/bin/sbt-launch.jar!/org/apache/ivy/core/settings/ivysettings.xml
downloading https://repo1.maven.org/maven2/org/scala-sbt/logic_2.12/1.3.10/logic_2.12-1.3.10.jar ...
:: loading settings :: url = jar:file:/usr/share/sbt/bin/sbt-launch.jar!/org/apache/ivy/core/settings/ivysettings.xml
[SUCCESSFUL ] org.scala-sbt#sbt;1.3.10!sbt.jar (854ms)
...(省略)...
[info] Fetched artifacts of
[info] Set current project to root (in build file:/root/)
[info] This is sbt 1.3.10
[info] The current project is ProjectRef(uri("file:/root/"), "root") 0.1.0-SNAPSHOT
[info] The current project is built against Scala 2.12.10
[info] Available Plugins
[info] - sbt.ScriptedPlugin
[info] - sbt.plugins.CorePlugin
[info] - sbt.plugins.Giter8TemplatePlugin
[info] - sbt.plugins.IvyPlugin
[info] - sbt.plugins.JUnitXmlReportPlugin
[info] - sbt.plugins.JvmPlugin
[info] - sbt.plugins.SbtPlugin
[info] - sbt.plugins.SemanticdbPlugin
[info] sbt, sbt plugins, and build definitions are using Scala 2.12.10
バージョン情報などが確認できればOKです。
補足: sbtのリポジトリについて
Automatic Dependency Management
...
Resolvers
sbt uses the standard Maven2 repository by default.
sbtで依存関係のあるライブラリを参照する先は、デフォルトだとMavenのリポジトリになっているようです。
Ivy Home Directory
By default, sbt uses the standard Ivy home directory location ${user.home}/.ivy2/. This can be configured machine-wide, for use by both the sbt launcher and by projects, by setting the system propertysbt.ivy.homein the sbt startup script (described in Setup).
また、依存関係の管理についてはivyという機能が使われているようで、ローカルのリポジトリはデフォルトで~/.ivy2/が使われるようです。
参考:
たけぞう瀕死ブログ - sbt利用上のIvyに関するハマりポイント
sbtが依存管理に使っているivyのローカルレポジトリやキャッシュについて調べた
サンプルアプリ稼働確認(Scala)
以下の記述を参考に、サンプル・アプリケーションを作成して動かしてみます。
Quick Start - Self-Contained Applications
アプリケーション作成
sbtを使う場合、ディレクトリの構造にある程度縛りがあるようなので、事前に規則に従ったディレクトリ構造を作っておきます。
適当なディレクトリ(ここではscala-test01)を作成して、その配下に以下のようなディレクトリ構造を作ります。
|-- src
| `-- main
| `-- scala
scala-test01/src/main/scala/に、ソースを作成します。(上のQuick Startのリンク先にあるソースのサンプルをコピーして、logFileの指定部分だけ修正。)
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "testData01/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
sc.stop()
}
}
testData01/README.md ファイルを読み込むようにしているので、このパスにファイルを配置します。
(scala-test01/testData01フォルダを作成して、Spark導入時に提供されるREMADME.mdファイルをコピーします。)
scala-test01/に、sbtファイルを作成します。
name := "SimpleProject01"
version := "1.0"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.5"
scalaVersionは、上でspark-shellを実行したときに表示されるScalaのバージョンに合わせて指定します。
最終的なディレクトリ、ファイルの構造は以下のようになります。
[root@test08 ~/Spark/scala-test01]# tree --charset C .
.
|-- build.sbt
|-- src
| `-- main
| `-- scala
| `-- SimpleApp.scala
`-- testData01
`-- README.md
4 directories, 3 files
コンパイル
scala-test01/に移動し、sbt packageコマンドでコンパイルします。
[root@test08 ~/Spark/scala-test01]# sbt package
[info] Loading project definition from /root/Spark/scala-test01/project
[info] Loading settings for project scala-test01 from build.sbt ...
[info] Set current project to SimpleProject01 (in build file:/root/Spark/scala-test01/)
[info] Updating
https://repo1.maven.org/maven2/org/apache/spark/spark-sql_2.11/2.4.5/spark-sql_2.11-2.4.5.pom
100.0% [##########] 13.1 KiB (17.0 KiB / s)
...(省略)...
[info] Non-compiled module 'compiler-bridge_2.11' for Scala 2.11.12. Compiling...
[info] Compilation completed in 13.033s.
[success] Total time: 40 s, completed 2020/04/25 10:40:08
1度目は必要なファイルが色々ダウンロードされるので時間がかかるかもしれません。
target/scala-2.11/simpleproject01_2.11-1.0.jar にコンパイルされた結果のjarが生成されます。
実行
コンパイルされたアプリケーションを実行してみます。
Sparkのアプリケーションを実行する際は、Spark提供のspark-submitコマンドを使います。
[root@test08 ~/Spark/scala-test01]# spark-submit --class SimpleApp --master local[*] target/scala-2.11/simpleproject01_2.11-1.0.jar
20/04/25 10:45:31 WARN Utils: Your hostname, test08 resolves to a loopback address: 127.0.0.1; using 10.0.2.15 instead (on interface enp0s3)
20/04/25 10:45:31 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/04/25 10:45:32 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
20/04/25 10:45:32 INFO SparkContext: Running Spark version 2.4.5
20/04/25 10:45:32 INFO SparkContext: Submitted application: Simple Application
20/04/25 10:45:32 INFO SecurityManager: Changing view acls to: root
20/04/25 10:45:32 INFO SecurityManager: Changing modify acls to: root
20/04/25 10:45:32 INFO SecurityManager: Changing view acls groups to:
20/04/25 10:45:32 INFO SecurityManager: Changing modify acls groups to:
20/04/25 10:45:32 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
20/04/25 10:45:32 INFO Utils: Successfully started service 'sparkDriver' on port 37148.
20/04/25 10:45:33 INFO SparkEnv: Registering MapOutputTracker
20/04/25 10:45:33 INFO SparkEnv: Registering BlockManagerMaster
20/04/25 10:45:33 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
20/04/25 10:45:33 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
20/04/25 10:45:33 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-9b3ffa63-e46c-420a-8ec3-93b8580ef622
20/04/25 10:45:33 INFO MemoryStore: MemoryStore started with capacity 366.3 MB
20/04/25 10:45:33 INFO SparkEnv: Registering OutputCommitCoordinator
20/04/25 10:45:33 INFO Utils: Successfully started service 'SparkUI' on port 4040.
20/04/25 10:45:33 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://10.0.2.15:4040
20/04/25 10:45:33 INFO SparkContext: Added JAR file:/root/Spark/scala-test01/target/scala-2.11/simpleproject01_2.11-1.0.jar at spark://10.0.2.15:37148/jars/simpleproject01_2.11-1.0.jar with timestamp 1587433533315
20/04/25 10:45:33 INFO Executor: Starting executor ID driver on host localhost
20/04/25 10:45:33 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 41211.
20/04/25 10:45:33 INFO NettyBlockTransferService: Server created on 10.0.2.15:41211
20/04/25 10:45:33 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
20/04/25 10:45:33 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 10.0.2.15, 41211, None)
20/04/25 10:45:33 INFO BlockManagerMasterEndpoint: Registering block manager 10.0.2.15:41211 with 366.3 MB RAM, BlockManagerId(driver, 10.0.2.15, 41211, None)
20/04/25 10:45:33 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 10.0.2.15, 41211, None)
20/04/25 10:45:33 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 10.0.2.15, 41211, None)
20/04/25 10:45:33 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('file:/root/Spark/scala-test01/spark-warehouse').
20/04/25 10:45:33 INFO SharedState: Warehouse path is 'file:/root/Spark/scala-test01/spark-warehouse'.
20/04/25 10:45:34 INFO StateStoreCoordinatorRef: Registered StateStoreCoordinator endpoint
20/04/25 10:45:34 INFO InMemoryFileIndex: It took 36 ms to list leaf files for 1 paths.
20/04/25 10:45:36 INFO FileSourceStrategy: Pruning directories with:
20/04/25 10:45:36 INFO FileSourceStrategy: Post-Scan Filters:
20/04/25 10:45:36 INFO FileSourceStrategy: Output Data Schema: struct<value: string>
20/04/25 10:45:36 INFO FileSourceScanExec: Pushed Filters:
20/04/25 10:45:37 INFO CodeGenerator: Code generated in 245.63025 ms
20/04/25 10:45:37 INFO CodeGenerator: Code generated in 29.18948 ms
20/04/25 10:45:37 INFO CodeGenerator: Code generated in 9.84516 ms
20/04/25 10:45:37 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 282.8 KB, free 366.0 MB)
20/04/25 10:45:37 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 23.3 KB, free 366.0 MB)
20/04/25 10:45:37 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 10.0.2.15:41211 (size: 23.3 KB, free: 366.3 MB)
20/04/25 10:45:37 INFO SparkContext: Created broadcast 0 from count at SimpleApp.scala:9
20/04/25 10:45:37 INFO FileSourceScanExec: Planning scan with bin packing, max size: 4194304 bytes, open cost is considered as scanning 4194304 bytes.
20/04/25 10:45:37 INFO SparkContext: Starting job: count at SimpleApp.scala:9
20/04/25 10:45:37 INFO DAGScheduler: Registering RDD 7 (count at SimpleApp.scala:9) as input to shuffle 0
20/04/25 10:45:37 INFO DAGScheduler: Got job 0 (count at SimpleApp.scala:9) with 1 output partitions
20/04/25 10:45:37 INFO DAGScheduler: Final stage: ResultStage 1 (count at SimpleApp.scala:9)
20/04/25 10:45:37 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
20/04/25 10:45:37 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)
20/04/25 10:45:37 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[7] at count at SimpleApp.scala:9), which has no missing parents
20/04/25 10:45:37 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 17.2 KB, free 366.0 MB)
20/04/25 10:45:37 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 7.9 KB, free 366.0 MB)
20/04/25 10:45:37 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 10.0.2.15:41211 (size: 7.9 KB, free: 366.3 MB)
20/04/25 10:45:37 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1163
20/04/25 10:45:37 INFO DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[7] at count at SimpleApp.scala:9) (first 15 tasks are for partitions Vector(0))
20/04/25 10:45:37 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
20/04/25 10:45:37 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 8257 bytes)
20/04/25 10:45:37 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
20/04/25 10:45:37 INFO Executor: Fetching spark://10.0.2.15:37148/jars/simpleproject01_2.11-1.0.jar with timestamp 1587433533315
20/04/25 10:45:37 INFO TransportClientFactory: Successfully created connection to /10.0.2.15:37148 after 32 ms (0 ms spent in bootstraps)
20/04/25 10:45:37 INFO Utils: Fetching spark://10.0.2.15:37148/jars/simpleproject01_2.11-1.0.jar to /tmp/spark-a7d8dc6c-4279-4ca3-9dfc-abb74bd20dfa/userFiles-068564c3-25b7-4988-9eab-8db2e39e4cf6/fetchFileTemp5725796940654553628.tmp
20/04/25 10:45:37 INFO Executor: Adding file:/tmp/spark-a7d8dc6c-4279-4ca3-9dfc-abb74bd20dfa/userFiles-068564c3-25b7-4988-9eab-8db2e39e4cf6/simpleproject01_2.11-1.0.jar to class loader
20/04/25 10:45:38 INFO FileScanRDD: Reading File path: file:///root/Spark/scala-test01/testData01/README.md, range: 0-3756, partition values: [empty row]
20/04/25 10:45:38 INFO CodeGenerator: Code generated in 14.511178 ms
20/04/25 10:45:38 INFO MemoryStore: Block rdd_2_0 stored as values in memory (estimated size 4.3 KB, free 366.0 MB)
20/04/25 10:45:38 INFO BlockManagerInfo: Added rdd_2_0 in memory on 10.0.2.15:41211 (size: 4.3 KB, free: 366.3 MB)
20/04/25 10:45:38 INFO CodeGenerator: Code generated in 7.058297 ms
20/04/25 10:45:38 INFO CodeGenerator: Code generated in 30.403512 ms
20/04/25 10:45:38 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1976 bytes result sent to driver
20/04/25 10:45:38 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 396 ms on localhost (executor driver) (1/1)
20/04/25 10:45:38 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
20/04/25 10:45:38 INFO DAGScheduler: ShuffleMapStage 0 (count at SimpleApp.scala:9) finished in 0.510 s
20/04/25 10:45:38 INFO DAGScheduler: looking for newly runnable stages
20/04/25 10:45:38 INFO DAGScheduler: running: Set()
20/04/25 10:45:38 INFO DAGScheduler: waiting: Set(ResultStage 1)
20/04/25 10:45:38 INFO DAGScheduler: failed: Set()
20/04/25 10:45:38 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[10] at count at SimpleApp.scala:9), which has no missing parents
20/04/25 10:45:38 INFO ContextCleaner: Cleaned accumulator 1
20/04/25 10:45:38 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 7.3 KB, free 366.0 MB)
20/04/25 10:45:38 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 3.9 KB, free 366.0 MB)
20/04/25 10:45:38 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 10.0.2.15:41211 (size: 3.9 KB, free: 366.3 MB)
20/04/25 10:45:38 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1163
20/04/25 10:45:38 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[10] at count at SimpleApp.scala:9) (first 15 tasks are for partitions Vector(0))
20/04/25 10:45:38 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks
20/04/25 10:45:38 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, executor driver, partition 0, ANY, 7767 bytes)
20/04/25 10:45:38 INFO Executor: Running task 0.0 in stage 1.0 (TID 1)
20/04/25 10:45:38 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks including 1 local blocks and 0 remote blocks
20/04/25 10:45:38 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 3 ms
20/04/25 10:45:38 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1825 bytes result sent to driver
20/04/25 10:45:38 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 42 ms on localhost (executor driver) (1/1)
20/04/25 10:45:38 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
20/04/25 10:45:38 INFO DAGScheduler: ResultStage 1 (count at SimpleApp.scala:9) finished in 0.057 s
20/04/25 10:45:38 INFO DAGScheduler: Job 0 finished: count at SimpleApp.scala:9, took 0.670259 s
20/04/25 10:45:38 INFO SparkContext: Starting job: count at SimpleApp.scala:10
20/04/25 10:45:38 INFO DAGScheduler: Registering RDD 15 (count at SimpleApp.scala:10) as input to shuffle 1
20/04/25 10:45:38 INFO DAGScheduler: Got job 1 (count at SimpleApp.scala:10) with 1 output partitions
20/04/25 10:45:38 INFO DAGScheduler: Final stage: ResultStage 3 (count at SimpleApp.scala:10)
20/04/25 10:45:38 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 2)
20/04/25 10:45:38 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 2)
20/04/25 10:45:38 INFO DAGScheduler: Submitting ShuffleMapStage 2 (MapPartitionsRDD[15] at count at SimpleApp.scala:10), which has no missing parents
20/04/25 10:45:38 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 17.2 KB, free 365.9 MB)
20/04/25 10:45:38 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 7.9 KB, free 365.9 MB)
20/04/25 10:45:38 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 10.0.2.15:41211 (size: 7.9 KB, free: 366.3 MB)
20/04/25 10:45:38 INFO SparkContext: Created broadcast 3 from broadcast at DAGScheduler.scala:1163
20/04/25 10:45:38 INFO DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 2 (MapPartitionsRDD[15] at count at SimpleApp.scala:10) (first 15 tasks are for partitions Vector(0))
20/04/25 10:45:38 INFO TaskSchedulerImpl: Adding task set 2.0 with 1 tasks
20/04/25 10:45:38 INFO TaskSetManager: Starting task 0.0 in stage 2.0 (TID 2, localhost, executor driver, partition 0, PROCESS_LOCAL, 8257 bytes)
20/04/25 10:45:38 INFO Executor: Running task 0.0 in stage 2.0 (TID 2)
20/04/25 10:45:38 INFO BlockManager: Found block rdd_2_0 locally
20/04/25 10:45:38 INFO Executor: Finished task 0.0 in stage 2.0 (TID 2). 1933 bytes result sent to driver
20/04/25 10:45:38 INFO TaskSetManager: Finished task 0.0 in stage 2.0 (TID 2) in 247 ms on localhost (executor driver) (1/1)
20/04/25 10:45:38 INFO TaskSchedulerImpl: Removed TaskSet 2.0, whose tasks have all completed, from pool
20/04/25 10:45:38 INFO DAGScheduler: ShuffleMapStage 2 (count at SimpleApp.scala:10) finished in 0.256 s
20/04/25 10:45:38 INFO DAGScheduler: looking for newly runnable stages
20/04/25 10:45:38 INFO DAGScheduler: running: Set()
20/04/25 10:45:38 INFO DAGScheduler: waiting: Set(ResultStage 3)
20/04/25 10:45:38 INFO DAGScheduler: failed: Set()
20/04/25 10:45:38 INFO DAGScheduler: Submitting ResultStage 3 (MapPartitionsRDD[18] at count at SimpleApp.scala:10), which has no missing parents
20/04/25 10:45:38 INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 7.3 KB, free 365.9 MB)
20/04/25 10:45:38 INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 3.9 KB, free 365.9 MB)
20/04/25 10:45:38 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on 10.0.2.15:41211 (size: 3.9 KB, free: 366.2 MB)
20/04/25 10:45:38 INFO SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:1163
20/04/25 10:45:38 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 3 (MapPartitionsRDD[18] at count at SimpleApp.scala:10) (first 15 tasks are for partitions Vector(0))
20/04/25 10:45:38 INFO TaskSchedulerImpl: Adding task set 3.0 with 1 tasks
20/04/25 10:45:38 INFO TaskSetManager: Starting task 0.0 in stage 3.0 (TID 3, localhost, executor driver, partition 0, ANY, 7767 bytes)
20/04/25 10:45:38 INFO Executor: Running task 0.0 in stage 3.0 (TID 3)
20/04/25 10:45:38 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks including 1 local blocks and 0 remote blocks
20/04/25 10:45:38 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 0 ms
20/04/25 10:45:38 INFO Executor: Finished task 0.0 in stage 3.0 (TID 3). 1782 bytes result sent to driver
20/04/25 10:45:38 INFO TaskSetManager: Finished task 0.0 in stage 3.0 (TID 3) in 14 ms on localhost (executor driver) (1/1)
20/04/25 10:45:38 INFO TaskSchedulerImpl: Removed TaskSet 3.0, whose tasks have all completed, from pool
20/04/25 10:45:38 INFO DAGScheduler: ResultStage 3 (count at SimpleApp.scala:10) finished in 0.024 s
20/04/25 10:45:38 INFO DAGScheduler: Job 1 finished: count at SimpleApp.scala:10, took 0.288874 s
Lines with a: 61, Lines with b: 30
20/04/25 10:45:38 INFO SparkUI: Stopped Spark web UI at http://10.0.2.15:4040
20/04/25 10:45:38 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
20/04/25 10:45:38 INFO MemoryStore: MemoryStore cleared
20/04/25 10:45:38 INFO BlockManager: BlockManager stopped
20/04/25 10:45:38 INFO BlockManagerMaster: BlockManagerMaster stopped
20/04/25 10:45:38 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
20/04/25 10:45:38 INFO SparkContext: Successfully stopped SparkContext
20/04/25 10:45:38 INFO ShutdownHookManager: Shutdown hook called
20/04/25 10:45:38 INFO ShutdownHookManager: Deleting directory /tmp/spark-2353b92f-8517-4cad-b289-8a8d5269ba1f
20/04/25 10:45:38 INFO ShutdownHookManager: Deleting directory /tmp/spark-a7d8dc6c-4279-4ca3-9dfc-abb74bd20dfa
--classオプションでは実行するクラス名を指定します。
--masterオプションでは実行環境を指定します。(local[*]の場合、ローカルモードでスレッド数はCPUのコア数)
最後にコンパイルして生成されたjarファイルを指定しています。
出力結果はINFOのメッセージがたくさん出ていて見にくいですが、最後から11行目くらいに、「Lines with a: 61, Lines with b: 30」という行が出力されています。
これが、プログラムで集計した結果を出力している部分です。
(読み込んだテキストファイルから、"a"を含む行数と、"b"を含む行数をカウントして出力しています。)
これで一通りアプリケーションを動かす所まで確認できました。