ロジバンとは
ロジバンとは人工言語です。普段私たちが喋っている日本語や英語などは自然言語と呼ばれますが、人工言語は語彙や文法が人工的に作られた言語です。人工言語といえば、エスペラント語などが有名ですが、ロジバンは1997年にできた比較的新しい人工言語で、wikipediaによると以下の特徴を持つようです1。
- 当初の開発者および現在の話者たちに一貫して、自己の文化的な背景に流れず努めて中立を保つことが志されている。
- ロジバンの表記法や統語法はいかなる不規則性もきたさないように設計されているため、コンピュータによる解析や人による読解が容易である。
- 言語表現の論理的な構造を正確に(そしてしばしば簡潔に)記述するために開発されてきた述語論理を文法の基盤としている。
順番に見ていきましょう。まず文化的に中立の部分ですが、人工言語の仲間であるエスペラント語は語彙などがヨーロッパの諸言語を参考にしているため非ヨーロッパ言語話者には難しいとの批判もありますが、ロジバンの語根は複数の言語の単語からミックスされて機械的に作られています。
次に、いかなる不規則性もきたさないような設計についてです。ロジバンの単語は語末や子音を見るだけで品詞が一意に決まります(名称語の語末は必ず子音など)。また、文の構文情報が一意に決まるなどの特徴もあります。日本語では、以下の文は「赤い魚」なのか「頭が赤い猫」なのかなど複数の解釈ができます。
頭が赤い魚を食べた猫
しかし、ロジバンなら起こりうるすべての構文情報を書き分けられます2。以下にその一部を示します。
lo stedu xunre ke finpe citka mlatu
lo stedu xunre finpe citka mlatu
lo stedu ke xunre finpe citka ke'e mlatu
lo stedu cu xunre finpe citka mlatu
lo stedu cu xunre ke finpe citka mlatu
他にも、音声とテキストを一致させるための工夫もあります。ある文字列の発音は一意に決まりますし、アクセントの位置さえ教えれば、空白文字なしでも構文解析できます。以下の例3では、大文字がアクセントを表しています。
.o’imuXAGjisofyBAKnicuZVAtilePURdi
o’i [{<mu BOI> <xagji sofybakni> KU} cu] [zvati {le purdi KU} VAU]
3つ目の述語論理についてです。基本的に文を作ると述語論理の式になります。つまり、書いた文を一階述語論理の命題として扱うことができます。さらに二階述語論理の式も作れますし、自由変項としても書くことができます。このような性質からロジバンを使ってプログラミング言語として用いようと試している人もいます4。
このように魅力的な特徴を持つロジバンですが、述語論理を理論的基礎としていることや多くの自然言語話者に馴染みのない文法のため難しいという人も多いらしいです。本当にそうなのでしょうか?日本語や英語などの言語に馴れているだけで、実は赤ちゃんなどの言語未習得者にとっては難解な言葉で書かれた規則集を用いなくても学びやすい可能性もあります。そこで、ロジバンの規則を規則集を用いずに獲得できるのか、またその規則獲得のしやすさを実験的に示してみたいと思います。それを示す一つの目安として、テキストデータと機械学習技術を用いてロジバンの規則を経験的に獲得できるのかを調査します。各言語の獲得のしやすさを定量的に図る方法を知らないのでこの方法を採用しました。機械学習技術を用いて規則を経験的に獲得できることが人間にとっても容易に獲得できることとは異なりますが、ある程度の相関はあるだろうと考えてます。
実験
データセット
ロジバンから規則獲得のしやすさを評価するといっても比較対象が必要です。そのためには、複数の言語で同じ内容を記述しているようなものがあると好都合です。今回は「星の王子さま」を実験データとして用いました。以下のURLから英語やフランス語、ドイツ語、エスペラント語、ロジバンで書かれた「星の王子さま」の本文をスクレイピングしました。エスペラント語は、おそらく世界で最も普及している人工言語です。名詞の語末は「o」や形容詞の語末は「a」など、活用のある単語の品詞は語末で決まるなどの特徴があり、習得しやすくするための工夫が多数盛り込まれています。最も普及している人工言語と比べてロジバンがどのような性質を持つのかも見ていきます。
https://www.odaha.com/antoine-de-saint-exupery/maly-princ/the-little-prince
https://mw.lojban.org/papri/le_cmalu_noltru
| 行数* | 単語(総数) | 単語(異なり数)** | 文字(総数) | 文字(異なり数) | |
|---|---|---|---|---|---|
| 英語 | 1,672 | 17,125 | 3,576 | 72,750 | 74 |
| フランス語 | 730 | 14,060 | 3,875 | 66,773 | 80 |
| ドイツ語 | 734 | 14,267 | 4,051 | 72,894 | 76 |
| エスペラント語 | 1,395 | 12,084 | 3,806 | 58,721 | 65 |
| ロジバン | 736 | 18,102 | 1,503 | 62,408 | 45 |
*ここでいう行数とは文数ではなく、スクレイピングした結果のテキストファイルの行数です。
** ここでは単純に半角の空白文字区切ったものを単語としてます。例えば、「"That is a hat."」という文があった場合、「"」「That」「is」 「a」「hat」「.」「"」を単語とするのではなく、「"That」「is」 「a」「hat."」を単語としてます。理由は上記すべての言語で前処理するのがめんどくさかったからです。
スクレイピングしてきたテキストの前半の行80%を学習データとし、残りの20%をテストデータとしました。また、ハイパーパラメータは最初に直感で決めたものを用いており、開発データ等で探索は行いませんでした(めんどくさかったので)。
教師あり単語分割
ロジバンでは、文字列から構文解析結果を一意に定めることができるという性質を紹介しました。では、ロジバンの規則を知らない人が文字列とその単語分割結果のペアに触れるだけで規則獲得できるのでしょうか。ここでは、「ni'okomifraxudoiverbalonumisalcilomakcuprenulodeicukta」のような半角空白をすべて取り去った文字列から元の単語境界が明示的な文「ni'o ko mi fraxu doi verba lo nu mi salci lo makcu prenu lo dei cukta」を復元できるかを実験します。
BiLSTM-CNN-CRF5で単語境界タグの推定を行います。例えば、文字列「Thisisapen.」を入力し、「BIIIBIBBIIB」となるような2値の単語境界タグ列を予測するようなモデルです。
実装
https://github.com/tomoris/rapid_prototyping_seq_tagger
| Precision | Recall | F score | |
|---|---|---|---|
| 英語 | 0.861 | 0.857 | 0.859 |
| フランス語 | 0.852 | 0.857 | 0.855 |
| ドイツ語 | 0.809 | 0.801 | 0.805 |
| エスペラント語 | 0.829 | 0.829 | 0.829 |
| ロジバン | 0.961 | 0.956 | 0.959 |
ロジバンは他の言語と比べて、きちんと単語境界を復元できているようです。ドイツ語は長い単語が多いので今回の実験設定では不利だったのかもしれません。意外にもエスペラント語では単語境界を復元することは難しいみたいです。
余談ですが、ラベル付きデータを大量に用意すると日本語や中国語のような元々分かち書きされていないような言語でも単語分割精度(F score) 0.95~0.99程度は達成できます6。おそらく上記のロジバン以外の言語でも学習データを増やせば十分に高精度を達成することができると思います。今回の実験では、丁寧に設計すれば少量の学習データでも高精度を達成できる、人間に置き換えると少ない労力で規則獲得できることが示唆されたと考えています。ただし、異なる言語に対してこのような比較していいのかは自信がないです。
教師なし単語分割
上記では、半角空白をすべて取り去った文字列と単語境界タグ列の関係を学習しました。ではロジバンにおいて、単語境界タグ列が与えられない場合、つまり半角空白をすべて取り去った文字列だけから単語列を推定できるのでしょうか。ここでは、教師なし単語分割問題として考えてみます。
教師なし単語分割モデルとして、 Nested Pitman-Yor Language Model7 を用います。これは入力文字列から、言語モデルが良くなるような単語境界を推定するようなモデルです。
実装
https://github.com/tomoris/PYHSMM
| Precision | Recall | F score | |
|---|---|---|---|
| 英語 | 0.417 | 0.390 | 0.403 |
| フランス語 | 0.318 | 0.323 | 0.320 |
| ドイツ語 | 0.368 | 0.449 | 0.405 |
| エスペラント語 | 0.352 | 0.390 | 0.403 |
| ロジバン | 0.559 | 0.442 | 0.494 |
教師なし学習なので精度は下がりましたが、ロジバンが最も単語分割しやすそうです。ただし、前述のとおり、単語を分割するための基準として言語モデルを用いています。言語モデルが良くなるような単語分割が、必ずしも人間の基準とは一致しないので参考程度の結果です。
実際に推定された単語列を見てみましょう。以下は英語の例です。頻出する「you」「will」という文字列を一つの単語とみなしたり、頻出する接頭辞「com」を一つの単語とみなし「comfort」を「com」「fort」という2つに分割しているなど原因で精度低下しているようです。しかし、人目にはある程度自然な分割結果が得られているように見えます。
look atit carefully so that youwill be sure to recognize it
incase you travel some day tothe africa n desert .and , if you should come upon
this spot, please donot hurry on . wait for a time , exactly underthe star . then ,
if alittle man appear swholaughs ,who has golden hair and who refusesto
answer question s , youwill know who heis . if this should happen, please com fort
me. send me wor dthat he has come back .
以下は、ロジバンの例です。残念ながら私はロジバンをほとんど読めないのでエラー分析ができないですが、英語の例のように、ある程度自然な分割になっているように見えます。例えば、「.i」は文頭に来て文区切りを明示する単語で、「lo」は述語の前に持ってきて名詞句を作り出す機能語ですが、おおむね正しく分割できているように見えます。
ni'o ko catlu lotsani .iko sezy retsku di'e .ipauxu lo lanpan zi pu citka lo xrula .i doba jimpe lodu'u roda cenba
ni'o iaze'ekuno makcu prenu ba jimpe lodu'u la'edi'u tai vajn i
以下が元々の単語列です。見比べると不自然な切れ目がほとんどなく、主に単語を連結しすぎたために精度低下しているように見えます。
ni'o ko catlu lo tsani .i ko sezyretsku di'e .i pau xu lo lanpanzi pu citka lo xrula .i do ba jimpe lo du'u ro da cenba
ni'o ia ze'eku no makcu prenu ba jimpe lo du'u la'e di'u tai vajni
教師なし品詞推定
今度は教師なし学習で品詞推定をしてみましょう。ここでは、単語列 $\boldsymbol{s} = w_1, w_2, ..., w_N$ を生成する潜在変数列 $\boldsymbol{z} = z_1, z_2, ..., z_N$ を与えれた単語列のみから推定し、それを品詞列とみなします。ロジバンもエスペラント語も単語の文字情報を見るだけで品詞がわかりますが、ここでは文字の情報は使わないことにします。
Bayesian HMM8 を用いて教師なし品詞推定します。以下の式で品詞列の事後分布を推定することでモデルを学習していきます。
p(\boldsymbol{z}|\boldsymbol{s}) \propto p(\boldsymbol{s}|\boldsymbol{z}) p(\boldsymbol{z})
このとき、$p(\boldsymbol{z})$は品詞 $n$-gram モデルから計算されます。
実装は以下を用いました。
https://github.com/tomoris/BayesianHMM
本来は、テスト時にはビタビアルゴリズムを用いて最適な品詞列を出力するべきですが、この実装では先頭から 1 best を順に出力します。
以下がエスペラント語での結果です。
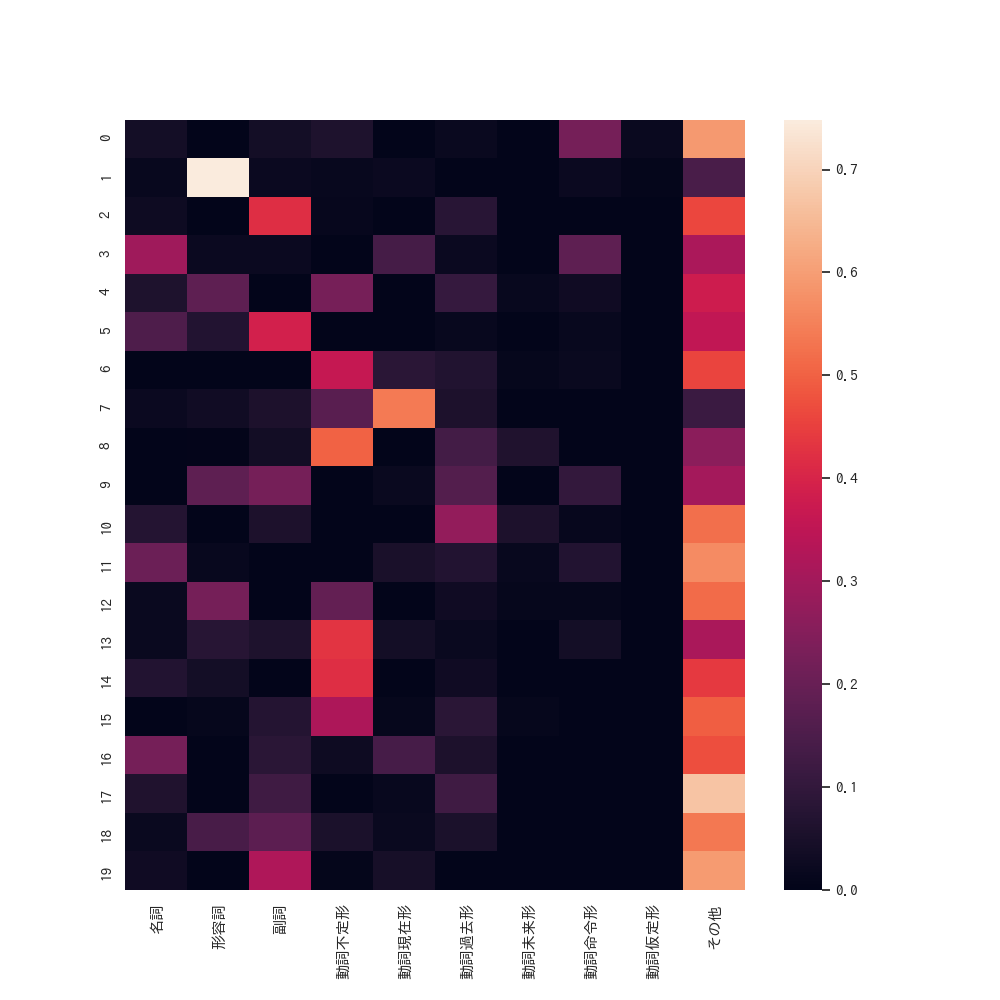
単語の語末から機械的に判別できる品詞との比較です。潜在変数1は形容詞の品詞と強く共起してますね。
以下がロジバンでの結果です。
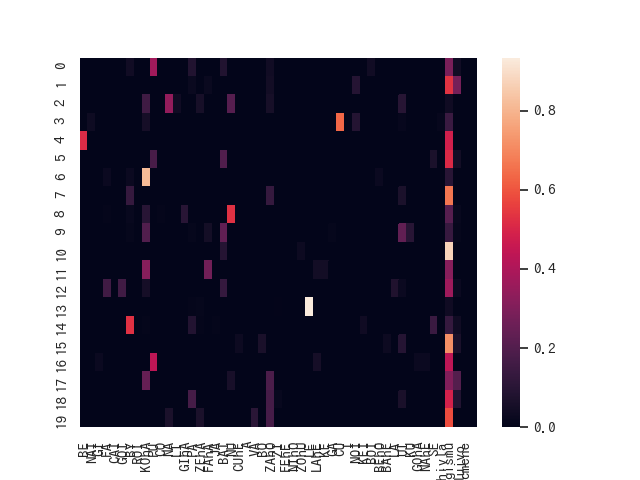
横軸の右から4つ以外は、 cmavo (機能語)です。残り3つが brivla (内容語)、一番右が cmene (名称語)です。エスペラント語に比べると各潜在変数は複数の品詞にまたがらず、よく分離できているようです。各潜在変数に満遍なく分布している品詞は brivla に属する gismu (語根)です。
言語モデル
言語モデルでも評価してみます。
ある文 $\boldsymbol{s} = w_1, w_2, ..., w_N$ の確率は以下の式で計算されます。
p(\boldsymbol{s}) = \prod_{n=1}^{N} p(w_n|w_{n-1}, ..., w_0)
$w_0$ は文頭の特別な記号です。今回は文字レベルのスムージングを行います。つまり、ある単語 $w_n$ は文字列 $c_1, c_2, ..., c_{M}$ から構成され、その確率は以下で計算されます。
p(w_n|h_{n-1}) = (1 - g) \cdot p_w(w_n|h_{n-1}) + g \cdot p_c(w_n|h_{n-1}), \\
p_c(w_n|h_{n-1}) = \prod_{m=1}^{M} p(c_m|c_{m-1}, ..., c_{1}, h_{n-1}), \\
h_{n-1} = w_{n-1}, ..., w_0
ここで、$p_w(w_n|h_{n-1})$は文字レベルを考慮しない単語レベルの確率です。
今回はLSTM言語モデルを用いて評価します。先ほどの $p(\boldsymbol{s})$ を最大化することで学習します。スムージング係数 $g$ も文脈 $h_{n-1}$ により変化するよう学習しました。このモデルは、先頭から順番に単語を予測していくことで文に対する確率を計算します。ロジバンの文法規則などは考慮してません。
実装
https://github.com/tomoris/LSTM_LM
言語モデルの評価指標には以下を用います。1つは Perplexity で、次の式の定義を用います。言語モデルの評価によく用いられ、数値が低いほど良い性能です。
H = -\frac{1}{N} \sum_{w_n} \log_2 p(w_n), \\
Perplexity = 2^H
2つ目はコーパス全体のスコアとして、以下のものを用いました。高いほど性能が良いです。
score = \frac{1}{|\boldsymbol{S}|} \sum_{\boldsymbol{s} \in \boldsymbol{S}} \log p(\boldsymbol{s})
語彙サイズの違う言語間を比較するので、どのような評価指標を使うべきか分かりませんが、今回はこの2つを用います。
| score $\uparrow$ | Perplexity $\downarrow$ | |
|---|---|---|
| 英語 | -65.8 | 3.69 |
| フランス語 | -132.4 | 3.69 |
| ドイツ語 | -118.0 | 3.15 |
| エスペラント語 | -67.9 | 4.08 |
| ロジバン | -102.0 | 2.21 |
Perplexity を見ると、ロジバンが最も良い性能となりました。ただし、scoreを見ると英語やエスペラント語と比べて優れているわけではないようです。おそらくこれは、スクレイピングしてきたテキストの行数が大きく異なるため、英語・エスペラント語とそれ以外の言語の score の比較はフェアではないようです。そう考えると、語彙サイズの異なるものを Perplexity で評価するのもフェアでないように思えます。異なる言語をフェアに比較する方法についてご存じの方は教えてください。
おわりに
この記事では、人工言語ロジバンについて紹介しました。ロジバンを自然言語処理技術で扱ってみて、ロジバンの規則獲得の容易さについて雑に示しました(機械学習技術でデータから規則を良く近似できたとしても、それが人間にとって容易に獲得できるというわけではありません)。時間があれば教師なし構文解析とかも試してみたいです。
ロジバンのことを初めて知って面白そうだと思った方はぜひ勉強してみてはいかがですか。ロジバンの文法規則が難しそうで敬遠していた方や挫折していた方も、文法規則は一旦置いて実際のロジバンのテキストに触れてみてはいかかですか。
-
https://ja.wikipedia.org/wiki/%E3%83%AD%E3%82%B8%E3%83%90%E3%83%B3 ↩
-
https://cogas.github.io/hajiloji/article/nunctu_remai/2.html ↩
-
Xuezhe Ma and Eduard H. Hovy. 2016. End-to-end sequence labeling via bi-directional LSTM-CNNs-CRF. In ACL. ↩
-
Taku Kudo, Kaoru Yamamoto, and Yuji Matsumoto. 2004. Applying conditional random fields to Japanese morphological analysis. In EMNLP. ↩
-
Daichi Mochihashi, Takeshi Yamada, and Naonori Ueda. 2009. Bayesian unsupervised word segmentation with nested pitman-yor language modeling. In ACL-IJCNLP. ↩
-
Sharon Goldwater and Thomas L. Griffiths. 2007. A fully Bayesian approach to unsupervised part-of-speech tagging. In ACL. ↩