そもそも自然順ってなに?
エクスプローラーのソートで数字部分を数値の大きさとして比較してくれるアレです。

名称としてこれが本当に正しいのか分からないんですけど、英語サイトでは Natural Sort なんて書いてあったりするのでたぶんそれの直訳なのかな?
もし上のファイルを単純にファイル名でソートすると以下のようになります。
- hoge1.txt
- hoge10.txt
- hoge15.txt
- hoge2.txt
- hoge3.txt
この結果を望むケースは少ないですよねー。
エクスプローラーさんは、なにげにお利口です。
私はニコ厨なのです(`・ω・´)
ニコニコ動画のゲーム実況を見るのが大好きで、夜中にふと寂しくなったときとか、人の声が聞きたくなったときに見ますw
部屋が無音だと寂しいから見もしないのにテレビ付けてる人っていますよね?
あれに近い感覚なのかなぁ。
実況動画は大抵ゲーム開始からエンディングまでに動画が3~100本とかなり幅はありますが、長期のシリーズ物になることが多いんです。
完結までの投稿期間が2年以上になることも珍しくないので、投稿者さまが動画に付けるタイトルに揺れが生じます(´・ω・`)
数字が全角だったり半角だったり、タイトルとパートの番号の間に空白があったりなかったり様々です。
そうすると自前のツールで動画を一覧表示したときに綺麗に並んでくれないわけです(;´д`)
そこで気の利いたライブラリがないか調べてみたんですけど、なさそうな感じだったので作っちゃいました。
比較する文字列同士の先頭から1文字ずつカレントカルチャで比較していって、数字に読める文字が見つかったら、数字に読めない文字が見つかるまでの固まりを一つの数値として評価するようにしています。
[Flags()]
public enum NaturalComparerOptions
{
/// <summary>アラビア数字。</summary>
Number = 0x1,
/// <summary>ASCIIローマ数字。</summary>
RomanNumber = 0x2,
/// <summary>日本語ローマ数字。</summary>
JpRomanNumber = 0x4,
/// <summary>日本語丸数字。</summary>
CircleNumber = 0x8,
/// <summary>日本語漢数字。</summary>
KanjiNumber = 0x10,
/// <summary>すべての数字。</summary>
NumberAll = Number | RomanNumber | JpRomanNumber | CircleNumber | KanjiNumber,
/// <summary>空白文字の存在を無視。</summary>
IgnoreSpace = 0x10000,
/// <summary>数字表現の違いを無視。</summary>
IgnoreNumber = 0x20000,
/// <summary>全角半角の違いを無視。</summary>
IgnoreWide = 0x40000,
/// <summary>大文字小文字の違いを無視。</summary>
IgnoreCase = 0x80000,
/// <summary>カタカナひらがなの違いを無視。</summary>
IgnoreKana = 0x100000,
/// <summary>すべての無視条件。</summary>
IgnoreAll = IgnoreSpace | IgnoreNumber | IgnoreWide | IgnoreCase | IgnoreKana,
/// <summary>既定の比較オプション。</summary>
Default = NumberAll | IgnoreSpace | IgnoreNumber | IgnoreWide | IgnoreCase,
}
綺麗に実装できればよかったんですけど、私の実力不足でコードがかなり長くなってしまいました。
コアの比較処理が100行、クラス全体では1600行弱にもなります(;´д`)
書いた時期が古く私の実力も今よりポンコツだったし、.NET2.0 前提なのも原因というのは言い訳です(ノ▽≦*)
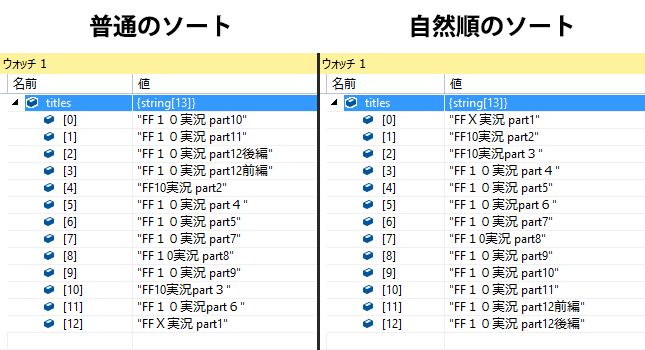
試しにサンプルデータを自然順でソートしてみる
static void Main()
{
// これが正しい並び順
string[] titles = new string[] {
"FFⅩ実況 part1",
"FF10実況 part2",
"FF10実況part3",
"FF10実況 part4",
"FF10実況 part5",
"FF10実況part6",
"FF10実況 part7",
"FF10実況 part8",
"FF10実況 part9",
"FF10実況 part10",
"FF10実況 part11",
"FF10実況 part12前編",
"FF10実況 part12後編",
};
// 普通のソート
Array.Sort(titles, StringComparer.CurrentCulture);
// 自然順のソート
Array.Sort(titles, new NaturalComparer());
}
普通のソートでは前編と後編もひっくり返っています。
コード的には 前>後、上>下 だったりするので、こういう並びになるんですね。
興味がある方はデバッグ触ってみてください。
NaturalComparer.cs