はじめに
- この記事はひとりNEONアドベントカレンダー2020 4日目の記事です
- 昨日のaddに引き続き、今日は水平加算系の命令を紹介する
水平加算命令
- 水平加算は、ベクトル内の全要素の和を取る命令
- 入力は複数だけど、出力は単一の要素 (なので、厳密には SI M Dではない、と誰かが言っていた)
- 水平加算系というだけあって、いくつかあるので、
padd、paddl、addv、addlvの4つの命令を紹介する- ちなみに、名前からして一見水平加算しそうな
hadd命令はhalving addで、和を取ったあと右に1bitシフトする命令。つまり水平加算ではない。
- ちなみに、名前からして一見水平加算しそうな
- 本当に
add命令多すぎである。
padd命令
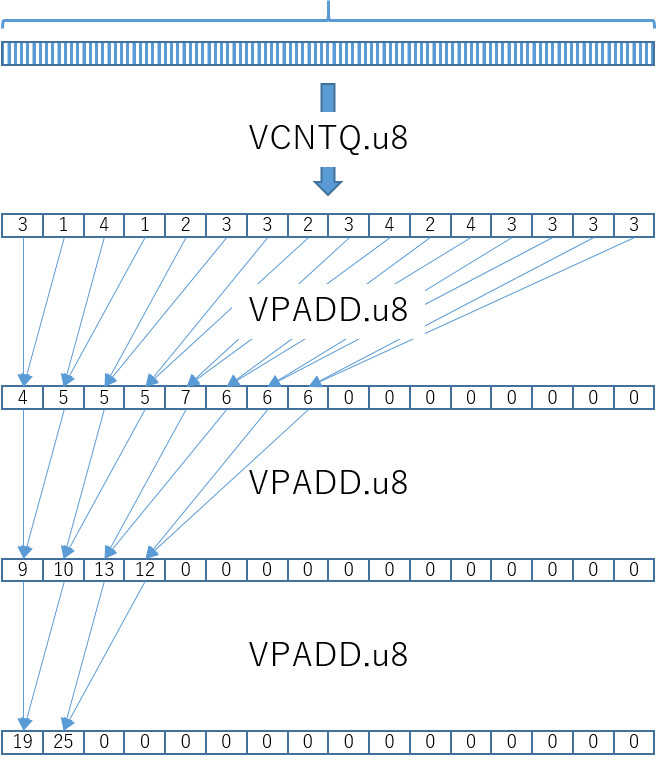
-
この図は4年前に使ったやつの再掲だけど、基本的に結果の
n番目の要素には、入力レジスタの(n*2番目の要素+n*2+1番目の要素)が格納される。 -
intrinsic関数のシグネチャとしては引数は、2つのベクトルを取り、同じ型を返す。(ex:
uint8x16_t vpaddq_u8(uint8x16_t a, uint8x16_t b)) -
先の図は
vpadd_u8(64bit幅の命令)を表した図だが、vpaddq_u8(128bit幅の命令)でも、1つ目のレジスタと2つ目のレジスタをあわせて256bit幅の仮想的なレジスタに対して処理が行われる。入力レジスタのn*2番目の要素とn*2+1番目の要素の和が、出力レジスタのn番目の要素として格納される-
vpadd命令であれば入力は64bit幅のレジスタ2つで128bit幅。総和を計算するには4回の命令(演算)が必要になる。 -
vpaddq命令であれば同5回の命令(演算)が必要になる
-
-
SSEでは、一発で水平加算を求める命令があったが、NEONにはこの
padd命令しかなかった。 いままでは。
addv命令
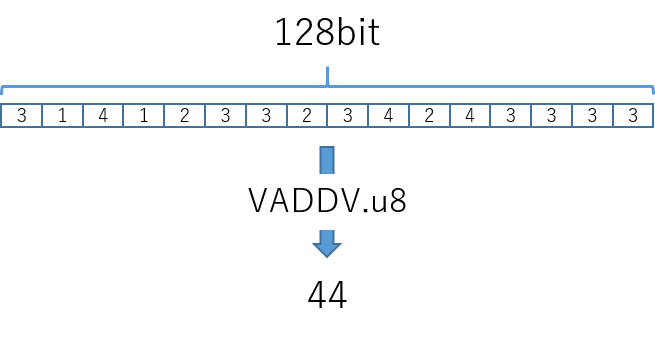
- NEONは、Arm v8の命令セットに含まれた、と何度も書いたけれど、実はその際、
double演算を始めとする、Arm v7時代には存在しなかった命令たちが追加されている - 前述の図は
vaddvq_u8で128bit幅のレジスタの、8bit整数型の各要素の和を1回で計算している1 -
addv命令もその一つで、こちらは、SSEの水平加算命令よろしく、一発で各要素ごとの和を求めてくれる - 戻り値は、各要素の型が使われる(
vaddv_u8ならばuint8_t型、vaddv_s32ならint32_t型)
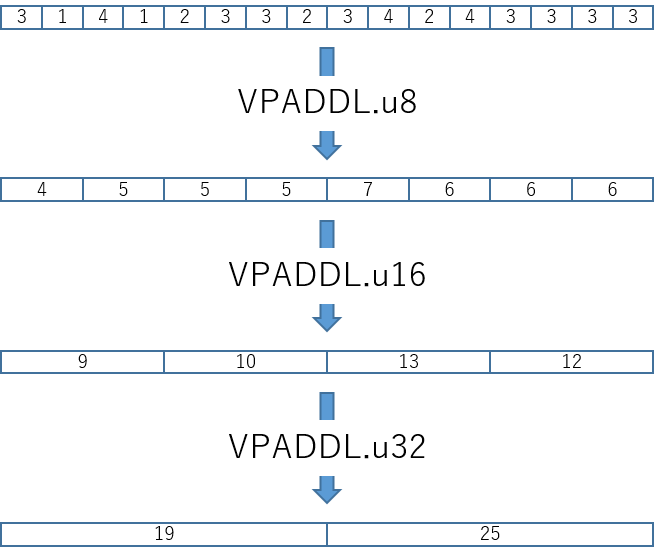
paddl命令
-
paddl命令では加算する際に各要素をbit拡張する。これにより演算結果がオーバーフローすることを防げる。 -
paddl命令は単一のレジスタしか受け付けない。 - 隣り合う要素ごと加算し、結果を倍の要素に格納して返す。(ex:
uint8x16_tを受けてuint16x8_t型を返す)
addlv命令
- この流れで行くとなんとなく分かると思うけれど、
addv命令の結果を、オーバーフローを防ぐために要素の型より一段広い型で返す- ex:
vaddlv_u8命令だと、各要素はuint8_tだが、処理結果はuint16_t型で返ってくる - こちらも、入力として64bit幅、128bit幅、どちらも受け取る
- ex:
その他
-
vpadd_f16ならびにvpaddq_f16命令が存在するが、こいつらはArm v8.2拡張命令セットなので、実行時にCPUがサポートしているかチェックが必要
おわりに
- 本当に
add命令多すぎである - 明日も私の担当の予定です
-
今気づいたんだけれど、4年前の記事は無駄に
padd命令を何回も計算してたから、addv命令でハミング距離を再計算したら結果が覆る可能性が微レ存? ↩