はじめに
- 本記事はOpenCV Advent Calendar 2022 の9日目の記事です。
- 8日目の記事は@ChaoticActivity先生によるcv::VideoCaptureで動画から読んだRGB画素値の誤差についてです。是非お読み下さい。
- その他の記事は目次をご覧ください。
- 自分のアドベントカレンダーの記事を見返していて、数年単位で「dispatch機能について解説する」という詐欺みたいな行為12を働いていたのでいい加減書くことにした。
dispatch機能とは
- OpenCV 3.3ぐらいから入った機能で、簡単に言うと拡張命令を正しく選択して実行する機能です
- dispatch機能がなかった時代のOpenCV
- OpenCVにはSSEを始めとしたSIMD命令を利用した実装が多数存在しました
- 更にはむかし、SSEが提供されないCPUというのも存在したので、拡張命令(SIMD)を使う場合は基本的にCPUの拡張命令が提供されているかのフラグをチェックする必要がありました
- さて、時代は流れてAVXがやってきました
- AVXはSSEの後継なのでSSE5とでも呼ぶべき位置ですが、ベクトル幅が256bitに拡張されたので、あたらしくAVXというブランド名を与えられました。
- AVXをVisual Studioでコンパイルする場合、明示的にプロジェクトごとに「フラグを設定する」必要がありました

- 図中の
Enable Enhanced Instruction Setがそれに該当します - こいつはファイル全体にわたって有効にされ、それより小さい単位では管理できません
- ここに、オートベクタライザの弊害が現れます
- オートベクタライザは主に
forループで同じ処理を繰り返し行っていることをコンパイラが検知した場合、当該ループをSIMD化してくれる便利な機能です
- オートベクタライザは主に
- 前述したようにAVX命令の利用はプロジェクト単位/ファイル単位で有効化されます
- ファイル内では拡張命令を使う直前に拡張命令が使えるかのチェックが入ってはいますが、オートベクトライザのおかげでそれ以外のところにもAVXの命令が生成される可能性があります
-
forループの中でなくても、例えばdouble4つの構造体を同じ値を設定する場合でも、オートベクタライザによりAVXの命令が生成される可能性があります
-
- こうすると、AVX命令に対応してないCPUでプログラムを実行した場合、実行時エラーが発生します
- 一方で、画像処理の速度の観点から行って、SIMD命令は外すことのできない重要なテクニックです
- ここで速度と安全性とポータビリティの観点からジレンマが発生します
- 速度第一で考えた場合、AVX命令は有効にするべきだが、その場合当該プログラムが他のマシンで動くためにはAVX命令必須となり、安全性が失われる
- 安全第一で考えた場合、AVX命令は無効にするべきだが、その場合すべての実装でAVX命令が無効化され、CPUのパフォーマンスを発揮できない
- OpenCVを利用するマシン上で、対応する命令を有効にしてOpenCVをビルドすれば速度も安全性も担保できるが、デモ用のマシンなど、Visual Studioをインストールできない状況も十二分に考えられる。
- と、かなり悩ましい状況に陥りいます(ジレンマは2点の間で揺れ動くことなので、この場合はトリレンマが正しい?)
- というわけでdispatch機能がOpenCVに実装されます3
Dispatch機能を使うために
- さて、AVX命令を使い、かつ他の部分でAVX命令を使わないためには、解決策は1つしかありません。
- AVXを使う部分をプロジェクトとして切り出し、そのプロジェクトでだけAVXを有効にすることです
- 具体的には以下の手順でdispatch機能を実装します
- 関数内の最内ループでSIMD化できる箇所だけを関数として独立させる
- 独立させた関数を、命名規則に則った別ファイルとして独立させる
- 必要なヘッダや宣言を埋め込む
- CMakeに当該ファイルはdispatch対応と記述する
- とりあえず意味不明ですね。もう少し具体例を踏まえて見ていきましょう
-
現行の最新版である 4.6.0 をVisual Studio でビルドしようとすると、以下のように複数のプロジェクトが生成されます
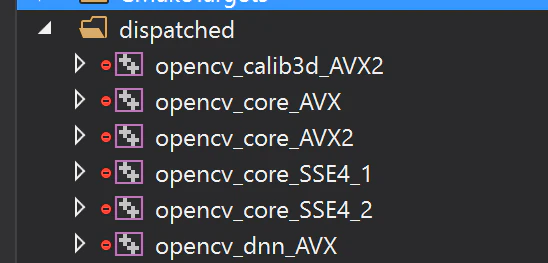
-
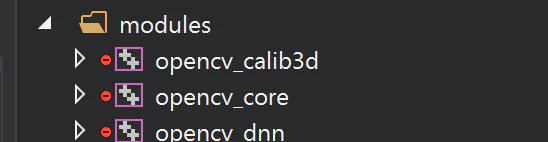
このうち、
-
opencv_core_AVX、opencv_claib3d_AVX2など末尾にSIMD拡張命令の名前がついてるやつがdispatch用プロジェクト -
opencv_core、opencv_calib3dなど末尾に何もつかないやつがライブラリとしてビルドされるプロジェクトです
-
-
各プロジェクトの設定項目をみると、たしかに項目名に対応したSIMD命令有効フラグが使われています
-
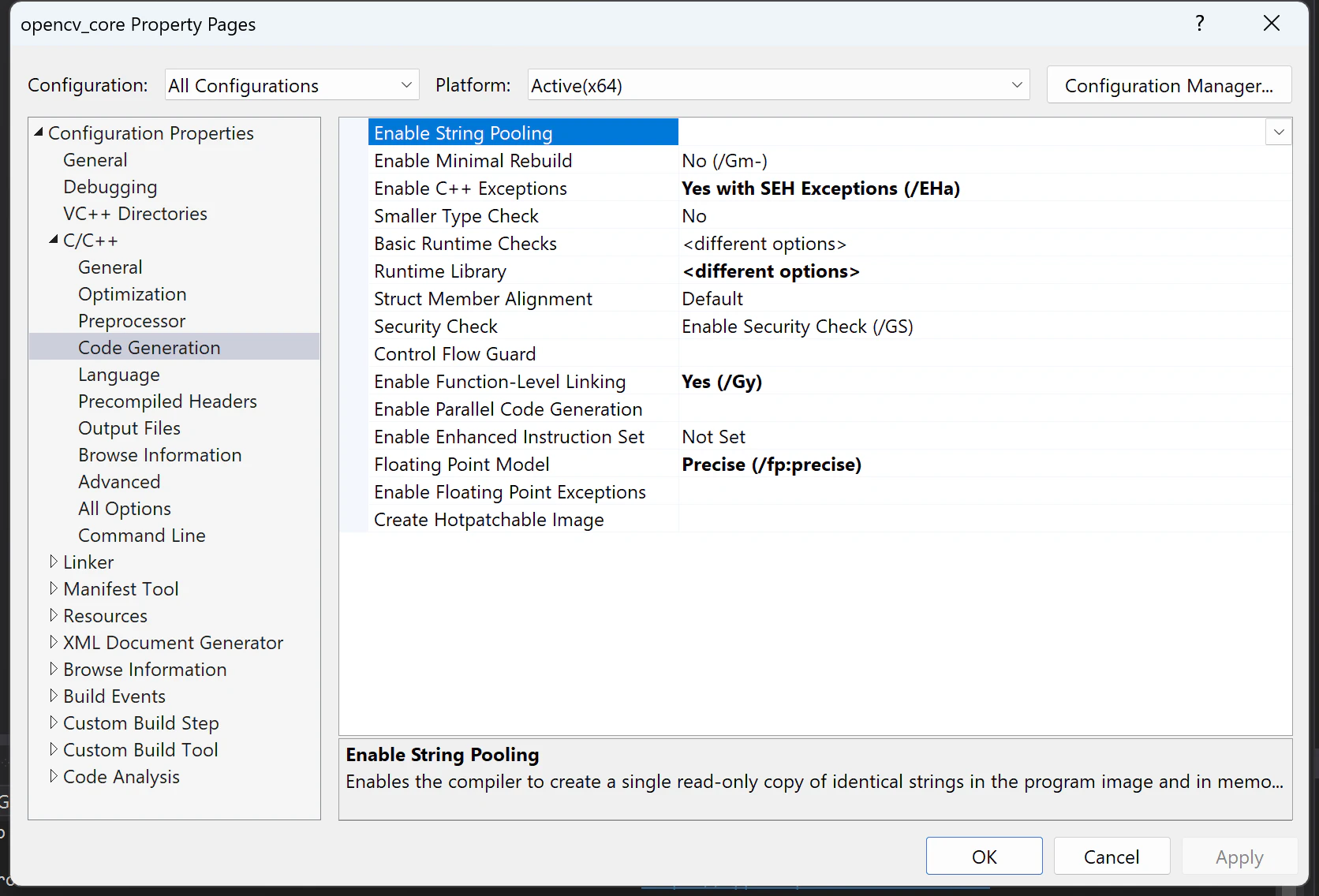
以下は
opencv_coreプロジェクトの設定。前述の"Enable Enhanced Instruction Set"項目が"Not Set"になっています
-
本文中ではWindowsのVisual Studioのスクリーンショットを使いましたが、Linux+Makeでも状況は同じで、 CMakeで記述/コンフィグした通りに opencv_xxx_AVX といった命名規則に則ったターゲットが生成されます。
- ではだんだん中を見ていきましょう。
- opencv_core_AVX2プロジェクトにはAVX2命令で実装された関数がファイルごとに羅列されています。

-
arithm.avx2.cppからsum.avx2.cppまで合計11ファイルが登録されています。- 試しにファイルを覗いてみましょう。
#include "C:/opencv/modules/core/src/precomp.hpp"
#include "C:/opencv/modules/core/src/arithm.simd.hpp"
- 衝撃の短さです
- 以前紹介したtest_main.cpp並の短さですが、こちらはわずか2行です。
- 6年ぶりの記録更新です
- というわけで、大体大事なものは実は
arithm.simd.hppに入っています。- ちなみに、各命令セットごとに内容は全く同じですが、ファイルの実体はそれぞれ別物です。
#include "C:/opencv/modules/core/src/precomp.hpp"
#include "C:/opencv/modules/core/src/arithm.simd.hpp"
#include "C:/opencv/modules/core/src/precomp.hpp"
#include "C:/opencv/modules/core/src/arithm.simd.hpp"
dispatch機能対応するために、コンパイルフラグの影響を受ける実装はすべてxxxx.simd.hppというファイルに詰め込みましょう
呼ぶ方の実装
- 呼ぶ方の実装を追ってみましょう
- ここでは単純に和の
addを追ってみましょう - 要素ごとの
addはたどると、以下の型別の関数に到着します。
static BinaryFuncC* getAddTab()
{
static BinaryFuncC addTab[] =
{
(BinaryFuncC)GET_OPTIMIZED(cv::hal::add8u), (BinaryFuncC)GET_OPTIMIZED(cv::hal::add8s),
(BinaryFuncC)GET_OPTIMIZED(cv::hal::add16u), (BinaryFuncC)GET_OPTIMIZED(cv::hal::add16s),
(BinaryFuncC)GET_OPTIMIZED(cv::hal::add32s),
(BinaryFuncC)GET_OPTIMIZED(cv::hal::add32f), (BinaryFuncC)cv::hal::add64f,
0
};
return addTab;
}
DEFINE_SIMD_ALL(add, op_add)
- プリプロセスにより以下のように展開されます(一部抜粋)
namespace cv { namespace hal {
void add8u(...)
{
if ((cv::checkHardwareSupport(11)))
return (opt_AVX2::add8u (src1, step1, src2, step2, dst, step, width, height));
if ((cv::checkHardwareSupport(6)))
return (opt_SSE4_1::add8u (src1, step1, src2, step2, dst, step, width, height));
return (cpu_baseline::add8u (src1, step1, src2, step2, dst, step, width, height));
}
-
この
add8uはDEFINE_SIMD_ALL(add, op_add)がマクロ展開され宣言/定義されます -
checkHardwareSupportで実際にプログラムが走ってるCPUの拡張機能を調べ、拡張命令が提供されている場合、対応する名前空間のコードを呼びます- AVX2命令が提供されている場合、
opt_AVX2::add8uを - SSE4.1命令が提供されている場合、
opt_SSE4_1::add8uを - どちらも提供されない場合、
cpu_baseline::add8uをそれぞれ呼びます
- AVX2命令が提供されている場合、
-
実際に呼ばれるコードは、Universal Intrinsicと同じく、アーキテクチャの違いをヘッダファイルに押し込むことで、呼んでる方はへんてこな
ifdefは必要ありません。
namespace cv { namespace hal {
namespace opt_AVX2 {
void add8u(...);
-
add8uはbin_loopを呼び、bin_loopまでたどると、だんだんifdefが効いてくるのが見えます
static void bin_loop(const T1* src1, size_t step1, const T1* src2, size_t step2, T1* dst, size_t step, int width, int height)
{
(中略)
for (; height--; src1 += step1, src2 += step2, dst += step)
{
int x = 0;
#if CV_SIMD
#if !CV_NEON && !CV_MSA
if (is_aligned(src1, src2, dst))
{
for (; x <= width - wide_step_l; x += wide_step_l)
{
ldr::la(src1 + x, src2 + x, dst + x);
#if CV_SIMD_WIDTH == 16
ldr::la(src1 + x + wide_step, src2 + x + wide_step, dst + x + wide_step);
#endif
}
}
else
#endif
for (; x <= width - wide_step_l; x += wide_step_l)
{
ldr::l(src1 + x, src2 + x, dst + x);
#if !CV_NEON && CV_SIMD_WIDTH == 16
ldr::l(src1 + x + wide_step, src2 + x + wide_step, dst + x + wide_step);
#endif
}
- 流石にこのレベルまで来ると
ifdefの嵐で流石にみにくくはありますが、ポイントは、保持するコードは1つのファイルでよい、という点です。 - 実際、dispatch機能は、ソースコードの途中で
CV_CPU_DISPATCHというマクロに突き当たります。
#undef DISPATCH_SIMD_FUN
#define DISPATCH_SIMD_FUN(fun, _T1, _Tvec, _OP) \
void fun(BIN_ARGS(_T1), void*) \
{ \
CV_INSTRUMENT_REGION(); \
CALL_HAL(fun, __CV_CAT(cv_hal_, fun), BIN_ARGS_PASS) \
ARITHM_CALL_IPP(__CV_CAT(arithm_ipp_, fun), BIN_ARGS_PASS) \
CV_CPU_DISPATCH(fun, (BIN_ARGS_PASS), CV_CPU_DISPATCH_MODES_ALL); \
}
-
arithm.simd.hppではマクロに囲われているので見えませんが、このマクロが前述のカスケードした関数コールにたどり着きます
dispatch機能を使うと、いずれCV_CPU_DISPATCHマクロにたどり着き、こいつが名前空間の違う実装を順番に試してコールする
dispatch機能を使う際は、CV_CPU_DISPATCHマクロを使いましょう。
マクロによって違う名前空間の違う実装を順番に試してコールしてくれます
CMake部分
- すごいのはここからです
- dispatch機能を実現するためには、複数のステップが必要です
-
CV_CPU_DISPATCHマクロを必要な関数コールに展開する - 基本的な実装を詰め込んだ
arithm.simd.hppファイルに対して、拡張命令ごとに複数のソースから適切なマクロを定義したあとにincludeする
-
CV_CPU_DISPATCH
- まずはここから行きましょう
- このマクロは
cv_cpu_dispatch.hで定義されています
#define __CV_CPU_DISPATCH_CHAIN_END(fn, args, mode, ...) /* done */
#define __CV_CPU_DISPATCH(fn, args, mode, ...) __CV_EXPAND(__CV_CPU_DISPATCH_CHAIN_ ## mode(fn, args, __VA_ARGS__))
#define __CV_CPU_DISPATCH_EXPAND(fn, args, ...) __CV_EXPAND(__CV_CPU_DISPATCH(fn, args, __VA_ARGS__))
#define CV_CPU_DISPATCH(fn, args, ...) __CV_CPU_DISPATCH_EXPAND(fn, args, __VA_ARGS__, END) // expand macros
- これは任意の長さのパラメータを受け取るマクロを展開するときの方法なので、ここまでは割りと普通です
- この
CV_CPU_DISPATCHをarithm.dispatch.cppで呼ぶ時に、マクロを呼びます
CV_CPU_DISPATCH(fun, (BIN_ARGS_PASS), CV_CPU_DISPATCH_MODES_ALL);
- この
CV_CPU_DISPATCH_MODES_ALLはどこからくるのか? - たどると、
arithm.simd_declarations.hppに定義があります
#define CV_CPU_DISPATCH_MODES_ALL AVX2, SSE4_1, BASELINE
- では、この
arithm.simd_declarations.hppはどこに存在するのか?- このファイルはgitリポジトリ内では管理されていません
- これがCMakeでコンフィグするときに生成されます
コンフィグ結果に依存するヘッダファイル xxxx.simd_declarations.hppはCMakeでコンフィグ時に生成されます
拡張命令ごとに複数のソースを用意する
- 現状のarithmではAVX2版、SSE4.1版、そしてSSSE3までを使ったベースラインの実装が必要になります
- SSSE3までの実装は
arithm.dispatch.cppに埋め込まれます。 - AVX2版とSSE4.1版はそれぞれ
arithm.avx2.cppとarithm.sse4_1.cppが生成されます - こいつもcmakeが生成します
# ここでarithm.xxx.cppの内容を__codestrに代入します
macro(__ocv_add_dispatched_file filename target_src_var src_directory dst_directory precomp_hpp optimizations_var)
if(NOT OPENCV_INITIAL_PASS)
set(__codestr "
#include \"${src_directory}/${precomp_hpp}\"
#include \"${src_directory}/${filename}.simd.hpp\"
")
# 中略
# ここでファイル名を決めます
set(__file "${CMAKE_CURRENT_BINARY_DIR}/${dst_directory}${filename}.${OPT_LOWER}.cpp")
# 中略
# 実際のファイルをここで生成します
file(WRITE "${__file}" "${__codestr}")
# 前述の arithm.simd_declarations.hpp もここで生成されます
set(__declarations_str "${__declarations_str}
#define CV_CPU_DISPATCH_MODE ${OPT}
#include \"opencv2/core/private/cv_cpu_include_simd_declarations.hpp\"
")
# 中略
set(__declarations_str "${__declarations_str}
#define CV_CPU_DISPATCH_MODES_ALL ${__dispatch_modes}
#undef CV_CPU_SIMD_FILENAME
")
# 中略
file(WRITE "${__file}" "${__declarations_str}")
dispatchされるソースコードxxxx.avx.cpp などは、xxxx.simd_declarations.hpp同様、CMakeでコンフィグ時に生成されます
実装を追加する場合
- 今年、NEONの内積命令をOpenCVに追加しました
- その際の手順の備忘録です
名前を決める
- そもそも、利用する拡張命令の一覧は、OpenCV内部に情報として保存されます
- x86向けのビルドでは
SSSE3がベースライン、AVX、AVX2などがdispatchとして利用されます- いずれもCMakeでコンフィグする際に変更可能です
- 今回、NEONの内積命令はLinuxの
cpuinfoではasimddpで表示されます。 - 最初は
DOTPRODというキーワードで提案しましたが、レビューの結果NEON_DOTPRODに落ち着きました。 - この
NEON_DOTPRODをまず、OpenCVCompilerOptimizations.cmakeに追記します
-list(APPEND CPU_ALL_OPTIMIZATIONS NEON VFPV3 FP16)
+list(APPEND CPU_ALL_OPTIMIZATIONS NEON VFPV3 FP16 NEON_DOTPROD)
- この時点でビルドすると、勝手に
cv_cpu_helper.hが更新されます
+#if !defined cv_disable_optimization && defined cv_enable_intrinsics && defined cv_cpu_compile_neon_dotprod
+# define cv_try_neon_dotprod 1
+# define cv_cpu_force_neon_dotprod 1
+# define cv_cpu_has_support_neon_dotprod 1
+# define cv_cpu_call_neon_dotprod(fn, args) return (cpu_baseline::fn args)
+# define cv_cpu_call_neon_dotprod_(fn, args) return (opt_neon_dotprod::fn args)
+#elif !defined cv_disable_optimization && defined cv_enable_intrinsics && defined cv_cpu_dispatch_compile_neon_dotprod
+# define cv_try_neon_dotprod 1
+# define cv_cpu_force_neon_dotprod 0
+# define cv_cpu_has_support_neon_dotprod (cv::checkhardwaresupport(cv_cpu_neon_dotprod))
+# define cv_cpu_call_neon_dotprod(fn, args) if (cv_cpu_has_support_neon_dotprod) return (opt_neon_dotprod::fn args)
+# define cv_cpu_call_neon_dotprod_(fn, args) if (cv_cpu_has_support_neon_dotprod) return (opt_neon_dotprod::fn args)
+#else
+# define cv_try_neon_dotprod 0
+# define cv_cpu_force_neon_dotprod 0
+# define cv_cpu_has_support_neon_dotprod 0
+# define cv_cpu_call_neon_dotprod(fn, args)
+# define cv_cpu_call_neon_dotprod_(fn, args)
+#endif
+#define __cv_cpu_dispatch_chain_neon_dotprod(fn, args, mode, ...) cv_cpu_call_neon_dotprod(fn, args); __cv_expand(__cv_cpu_dispatch_chain_ ## mode(fn, args, __va_args__))
- この
cv_cpu_helper.hはgitで管理されているファイルですが、実はCMakeによってコンフィグされる際に毎回上書きされています - この定型処理はヒューマンエラーが入らないようにCMakeで実現されています。かしこいですね!
macro(ocv_compiler_optimization_fill_cpu_config)
# 中略
foreach(OPT ${CPU_ALL_OPTIMIZATIONS}) if(NOT DEFINED CPU_${OPT}_FEATURE_ALIAS OR NOT "x${CPU_${OPT}_FEATURE_ALIAS}" STREQUAL "x")
set(OPENCV_CPU_CONTROL_DEFINITIONS_CONFIGMAKE "${OPENCV_CPU_CONTROL_DEFINITIONS_CONFIGMAKE}
#if !defined CV_DISABLE_OPTIMIZATION && defined CV_ENABLE_INTRINSICS && defined CV_CPU_COMPILE_${OPT}
# define CV_TRY_${OPT} 1
# define CV_CPU_FORCE_${OPT} 1
# define CV_CPU_HAS_SUPPORT_${OPT} 1
# define CV_CPU_CALL_${OPT}(fn, args) return (cpu_baseline::fn args)
# define CV_CPU_CALL_${OPT}_(fn, args) return (opt_${OPT}::fn args)
#elif !defined CV_DISABLE_OPTIMIZATION && defined CV_ENABLE_INTRINSICS && defined CV_CPU_DISPATCH_COMPILE_${OPT}
# define CV_TRY_${OPT} 1
# define CV_CPU_FORCE_${OPT} 0
# define CV_CPU_HAS_SUPPORT_${OPT} (cv::checkHardwareSupport(CV_CPU_${OPT}))
# define CV_CPU_CALL_${OPT}(fn, args) if (CV_CPU_HAS_SUPPORT_${OPT}) return (opt_${OPT}::fn args)
# define CV_CPU_CALL_${OPT}_(fn, args) if (CV_CPU_HAS_SUPPORT_${OPT}) return (opt_${OPT}::fn args)
#else
# define CV_TRY_${OPT} 0
# define CV_CPU_FORCE_${OPT} 0
# define CV_CPU_HAS_SUPPORT_${OPT} 0
# define CV_CPU_CALL_${OPT}(fn, args)
# define CV_CPU_CALL_${OPT}_(fn, args)
#endif
#define __CV_CPU_DISPATCH_CHAIN_${OPT}(fn, args, mode, ...) CV_CPU_CALL_${OPT}(fn, args); __CV_EXPAND(__CV_CPU_DISPATCH_CHAIN_ ## mode(fn, args, __VA_ARGS__))
")
endif()
endforeach()
ヒューマンエラーを避けるためにも、定型処理は必ずCMakeに任せましょう
実装する
- つづいては実装部分です。
- 飛び込む前に、拡張命令を単純にOpenCVの関数内部にベタ書きすると、残念ながらPRは承認されません。
we do not accept native optimizations any longer.
It would be just impossible for our tiny team to maintain all those branches.
Please, rewrite the native NEON code using our universal intrinsics.
- というわけでいきなりintrinsicをベタ書きするのでなく、Universal Intrinsicに
dot命令を追記していくことになります
#ifdef CV_NEON_DOT
#define OPENCV_HAL_IMPL_NEON_DOT_PRODUCT_OP(_Tpvec1, _Tpvec2, suffix) \
inline _Tpvec1 v_dotprod_expand(const _Tpvec2& a, const _Tpvec2& b) \
{ \
return _Tpvec1(vdotq_##suffix(vdupq_n_##suffix(0), a.val, b.val));\
} \
inline _Tpvec1 v_dotprod_expand(const _Tpvec2& a, const _Tpvec2& b, const _Tpvec1& c) \
{ \
return _Tpvec1(vdotq_##suffix(c.val, a.val, b.val)); \
}
OPENCV_HAL_IMPL_NEON_DOT_PRODUCT_OP(v_uint32x4, v_uint8x16, u32)
OPENCV_HAL_IMPL_NEON_DOT_PRODUCT_OP(v_int32x4, v_int8x16, s32)
#else
- ここではマクロを使ってまとめましたが、内部では
vdotqというキーワードが見えます。
実装にintrinsicベタ書きは実質認められない。Universal Intrinsicを使いましょう。
CMakeの更新
- 最後に、対応する関数を使いたいモジュールのCMakeLists.txtファイルに
NEON_DOTPRODを追記します
-ocv_add_dispatched_file(matmul SSE2 SSE4_1 AVX2 AVX512_SKX)
+ocv_add_dispatched_file(matmul SSE2 SSE4_1 AVX2 AVX512_SKX NEON_DOTPROD)
- もともと内積命令は
matmul.cpp内で使われており、このファイルはすでにdispatch対応されていました。 - これの選択肢に
NEON_DOTPRODを追加してだいたいおしまいです。 - dispatch機能がすでに実装されているおかげで、「同じ作業」は「なるだけCMake」にまとめられています
- いいですね!
その他
- ビルド時及び実行時に拡張命令対応を調べるテスコード、及び拡張命令にユニークなIDと名前を記述するステップがありますが、ここでは割愛します
おわりに
- 長くなりましたが、OpenCVではdispatch機能を実装しており、ビルド時、実行時にどう振る舞うかを紹介しました
- 具体的には実装の大部分はヘッダに実装を押し込み、cmakeで自動生成する機能に頼っています
- DRYの原則に則った、美しい実装だと思います
- ところで、OpenCVは最近5.0のリリースに注力している模様で、4系列のリリースも半年以上ありません。
- 例年通りクリスマスシーズンにリリースされるのかもしれませんが、今のところ不明です
- 件のPRは半年近く前にマージされたのに、まだ3系、4系、いずれの正式リリースにも含まれてないのはぐぬぬな感じです
- 明日は@Kazuma_Kikuyaさんの投稿でタイトルは「CLIP STUDIOのベクターレイヤをOpenCVとCatmull-Romスプライン曲線で実装してみた話」です。お楽しみに!
参考資料
- https://github.com/alalek/opencv/wiki/CPU-optimizations-build-options : OpenCV 公式Wikiによる解説
- https://github.com/opencv/opencv/pull/7462 : dispatch機能を追加した最初のPR
-
4年前に書いた記事その2で「別記事で解説しようと思います」と書いてました ↩
-
さもdispatch機能が実装された理由がAVXだけ、かのように書きましたが、実際のところはNEONを始めとするx86_64アーキテクチャ以外のSIMD対応が進んでいた時期であり、一概に「AVXがために」というわけではなさそうです。ただし、筆者が見てきた範囲だとAVXがdispatch機能実装の理由の一つであることは間違いなさそうです。 ↩