はじめに
こちらは「機械学習を使って一番安い家賃の家に住む。〜前処理編〜」の続きになります。
前回の記事はこちらから。
行ったこと
1 SUUMOから物件データをスクレイピング
2 前処理
3 lightGBMを使って学習、予測。←今回はここ。
4 最安値の家に住み、めでたしめでたし。
環境
・Mac OS Big sur
・Jupyter Lab
・Python 3.7.0
・Google Chrome
そもそもこのやり方はリークを起こす。
これからやる手法は機械学習ではタブーの手法です。何がだめかと言うと予測したいデータが学習データに含まれているからです。これをリークといいます。
**「今掲載されている物件データ」は学習に使ってはいけないので、「スクレイピングして学習するデータ」は過去に掲載されたデータを使い、それらから作成されたモデルを使って「今掲載されている物件データ」**を別でスクレイピングして予測する必要があります。
(掲載が終わると「掲載終了されました。」表示されるので、そのページだけスクレイピングしてくればいいので現実的には可能だと思います。)
今回はがっつりリークを起こしてますが、それでも安い物件は分かるのでこのやり方で行きます。
早速やってみる。
まずは必要なモジュールをimportします。
import pandas as pd
import numpy as np
from optuna.integration import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
import japanize_matplotlib
*前回は時間がなかったので西多摩郡にしましたが、約300行と流石に学習するに足りなかったで、今回は西東京市の物件データを使用しています。約10,000件あります。
データの分割と変換
train_test_splitで分割します。
lightGBMは生のデータは使えず、lgb.Datasetを通してからモデルにいれます。
# データの分割
train, test = train_test_split(df, test_size=0.33, random_state=0)
X_train = train.drop('rent', axis=1)
y_train = train['rent']
X_test = test.drop('rent', axis=1)
y_test = test['rent']
# データの変換
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
パラメータチューニング
lightGBMではパラメータをいじることで大きく精度が上がることはあまりないので、パラメータを自動設定出来るoptunaを使って自動設定します。
boosting_type、objective、metricはこちらで設定します。
# ハイパーパラメータをoptunaで自動設定
params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'rmse'
}
best_params, history = {}, []
model = lgb.train(params,
lgb_train,
valid_sets=[lgb_train,lgb_eval],
verbose_eval=False,
num_boost_round=10
)
best_params_ = model.params
学習、予測
import lightgbm as lgb_orig
model = lgb_orig.train(best_params_,
train_set=lgb_train,
valid_sets=lgb_eval,
)
prediction=model.predict(df)#リーク
結果を表示
評価指標はr2スコアを採用しています。
r2スコアについてはこちらから。
要は決定係数です。目安は以下のとおりです。

print(r2_score(df["rent"], prediction))
lgb.plot_importance(model, figsize=(12, 6))
plt.show()
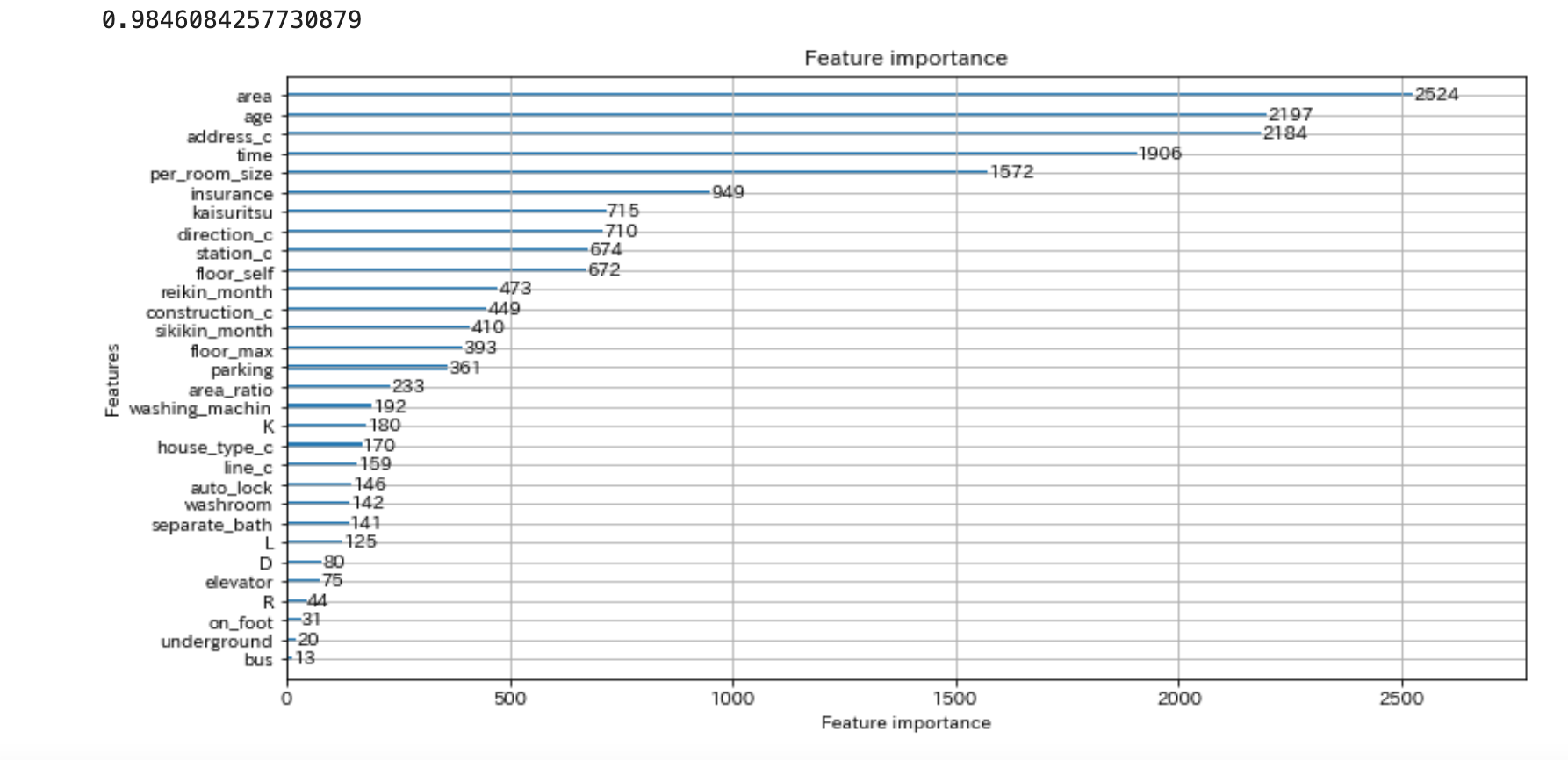
リークしてるので当たり前ですが、r2スコアは0.98とがっつり過学習してますね。
feature_importanceについてはarea(専有面積)が一番重要と判断しているようです。
address_c(市以降の住所)がベスト3となっているのは少し意外ですね。
では最後に予測した家賃と実際の家賃との差を計算して、ソートさせてみます。
otoku=pd.read_csv("suumo.csv")#元データを再度読み込み
df["url"]=pd.Series(url_syosai_lists)#urlのリストを結合
prediction_s=pd.Series(prediction,name="prediction")#予測した家賃
otoku["difference"]=df["rent"]-prediction_s#実際の家賃と予測した家賃の差
otoku[["price","layout","area","age","nearest_station","construction","difference"]].sort_values(by="difference",ascending=True)#お得順に表示。
*url_syosai_listsについてはスクレイピング編で定義したものです。
urlをスクレイピングするだけなので、30分もかからないと思いますが、物件データは頻繁に増えたり減ったりしているので、前処理や学習している間に数が変わってしまいます。
よって、スクレイピングしたままこの学習、予測編をやるのがいいと思います。
結果は以下のとおりです。

お得な物件ベスト5と相場より高い物件ワースト5になります。(一応家の名前は伏せてます。)
一番お得な物件めちゃくちゃ安くないですか!?2SLDKの105m2あって家賃9.3万円!!!
個人的には木造がちょっと気になりますが。。。笑
逆に一番相場より高い家は6SLDKで29万円。うーん、6SLDKってどのくらいですかね。笑
イマイチ想像は付きませんが、29万円は高いですね。
条件を追加したければ、df[df["construction"]=="鉄筋"]とかすればフィルタリング出来ます。
おわりに
今回はSUUMOからスクレイピングをして、機械学習を使って予想してみました。
リークを起こしてしまうため手法としてはNGですが、最終的には結構いい物件を見つけられましたね。
これから引越しの際はこちらを活用して安い家に住みたいと思います。
ここまでご覧いただきありがとうございました!