はじめに
中国の華中科技大学と北京大学による研究チームがCVPR2020の学会で「Semantically Multi-modal Image Synthesis」(SMIS)という論文を出しました。この論文によると、写真一枚から服とズボンの柄・色を変更して、仮想的な試着したような画像を生成できます。この論文では画像をオブジェクトごとにクラス分けし、部分的に画像を入れ替えて合成する深層学習ベースの手法を用いています。
今回はSMISモデルの簡単な解説と実際に試してみるやり方について説明します。動かしてみたい人は「モデルを動かしてみる」から見てください。
論文の詳細は下記になります。

論文: https://arxiv.org/abs/2003.12697
プロジェクトページ: https://seanseattle.github.io/SMIS/
Github: https://github.com/Seanseattle/SMIS
動画: http://www.youtube.com/watch?v=uarUonGi_ZU
モデルについて
服の柄・色を変更するには、まずどこの部分が服・ズボンであるかをラベリングする必要があります。
DeepFashionという服の部分をラベリングしたデータセットを用いて、画像の領域を関連付けを行うセマンティックセグメンテーションをします。
セマンティックセグメンテーショされた各クラスに応じたコントローラーで調整することで、対応する部分だけ画像を変換することができます。従来、このような画像合成では各クラスごとに生成ネットワークを構築し、異なるネットワークの出力を統合して最終的な画像を生成する手法が用いられてきました。
しかしこの手法だと、クラス数が多くなるにつれて学習時間が増加し精度が落ちてしまう課題がありました。SMISの手法は、クラスの制御を従来の畳み込みからグループ畳み込みに変更し、生成プロセスを1つのモデルに統一するネットワークGroupDNet(Group Decreasing Network)により、その課題を解決しています。

GroupDNetは、クラス間で類似する場合に(草の色と木の葉の色は似ている等)、異なるクラス間の相互相関を構築できるような能力を与え、全体的な画質を向上させます。これは、クラス数が多い場合の計算量の軽減にもつながります。これにより、意味ラベルを別の画像に変換しやすくなり、多くのクラスを持つデータセットに対しても高品質な結果を得ることができました。
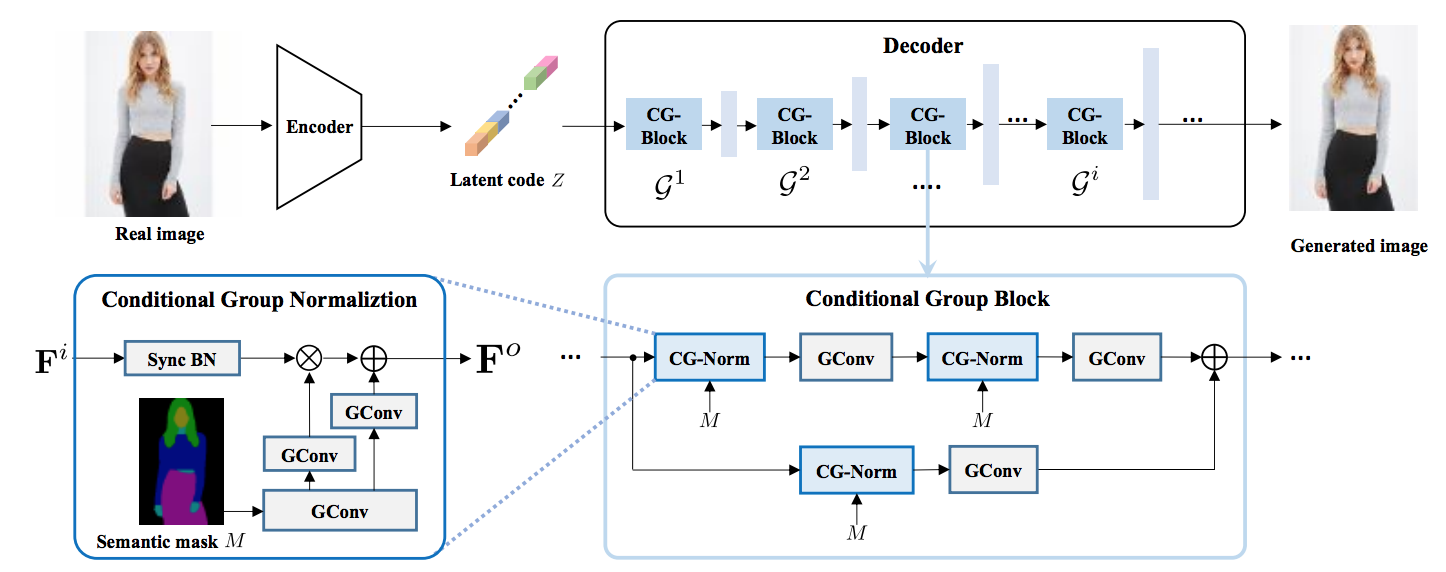
図1 GroupDNetアーキテクチャ([1]より引用)
図2に他モデルの比較を示します。生成モデルにおける生成された画像の品質をどうやって評価するのかの指標はいくつかあるのですが、その一つにFréchet Inception Distance (FID) というものがあります。実画像と生成画像の分布間の距離を測る評価指標です。このFIDにおいては他のモデルと比較して、state-of-the-artの結果となっています。しかし速度面では12.2FPSとなっており、他のモデルに比べて劣る部分もあります。
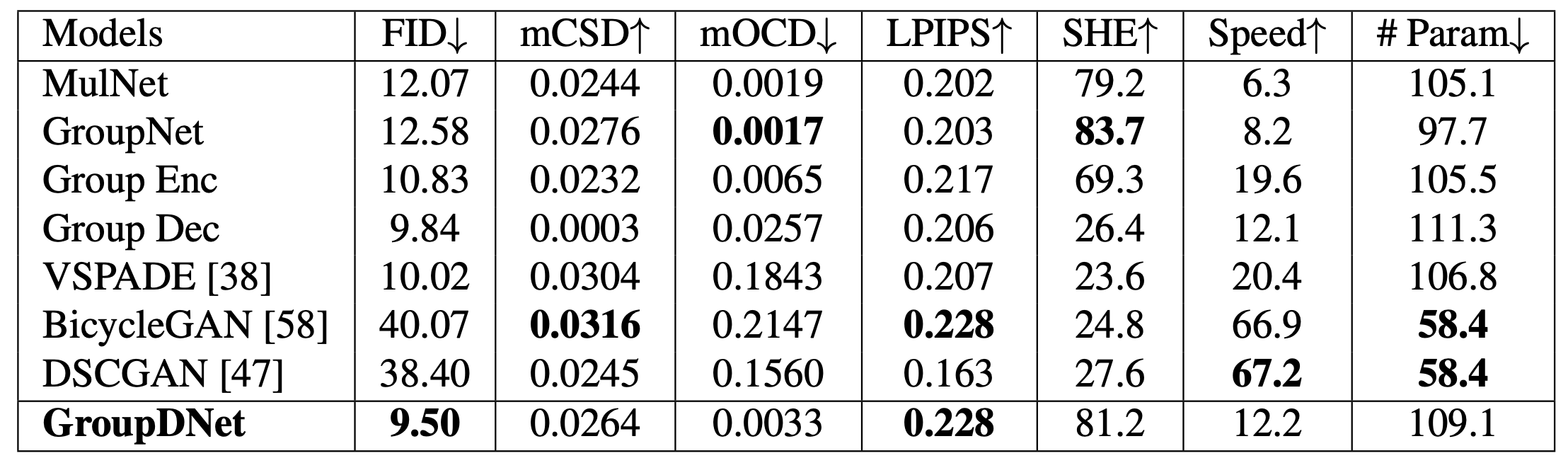
図2 他モデルとの比較([1]より引用)
この手法は図1のようにセマンティックセグメンテーションした上でスタイルを変更する方法なので、ファッションだけに限らず、建物を木に変える、何もないところにベットを挿入する等、画像から別の画像へ徐々に変化させていくモーフィングなど、さまざまな応用が可能です。
(解説に関しては一部[2]を引用しました、足らない説明や誤っている説明もあるかもしれないので、そのときはコメントください)
モデルを動かしてみる
それではSMISモデルを動かしてみましょう。研究チームはPytorchで実装したモデルをGithub上で公開してくれています。
実際に動くコードをGoogle Colaboratoryで作ってみました。次のURLから私の作成したnootebookを確認できます。このnotebookを自分のdriveにコピーして動かしてもらっても大丈夫です。(ただ上から順番にセルを実行するだけで動かすことができます)
https://colab.research.google.com/drive/1HGqqOXxFKTSJibg2tQ-Shb9ArFiX-96g?usp=sharing
作成したColaboratoryのコードをQiitaでも解説していきます。
レポジトリのクローン
Githubからレポジトリ (https://github.com/Seanseattle/SMIS) をクローンします。
!git clone https://github.com/Seanseattle/SMIS
%cd SMIS
学習済みモデルをダウンロード
次のGoogle driveから学習済みモデルをダウンロードします。
https://drive.google.com/open?id=1og_9By_xdtnEd9-xawAj4jYbXR6A9deG
学習済みモデルについてはレポジトリのREADMEに書いてあります。
Google driveから直接CUIでダウンロードするためには、cookieの情報をwgetで渡してあげる必要があるので次のようなやり方でダウンロードしています(cookieを使ったdriveのダウンロード方法についてはこちらでまとめてあります)。単純にURLをブラウザで開き、GUIでダウンロードするのも大丈夫です。
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1og_9By_xdtnEd9-xawAj4jYbXR6A9deG' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1og_9By_xdtnEd9-xawAj4jYbXR6A9deG" -O smis_pretrained.rar && rm -rf /tmp/cookies.txt
ダウンロードしたpretainデータを解凍し、フォルダ名を変更します。
!unrar x smis_pretrained.rar
!mv smis_pretrained checkpoints
DeepFashion datasetをダウンロードする
上記と同様に、次のGoogle driveのリンクからDeepFashionのデータセットをダウンロードします。trainデータとtestデータが入っています。今回はtestデータとして使用するためだけにダウンロードしています。
https://drive.google.com/open?id=1ckx35-mlMv57yzv47bmOCrWTm5l2X-zD
!wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1ckx35-mlMv57yzv47bmOCrWTm5l2X-zD' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1ckx35-mlMv57yzv47bmOCrWTm5l2X-zD" -O deepfashion.tar && rm -rf /tmp/cookies.txt
ファイルを解凍します。
!tar -xvf deepfashion.tar
必要なライブラリをインストール
このレポジトリで使用するライブラリはrequirement.txtにまとめてあります。requirement.txt内のライブラリをインストールします。
!pip install -r requirements.txt
モデルのtestを実行する
モデルを動かすにはtest.pyを実行するだけで良いです。
--gpu_idsのパラメータには、使用するgpu idを指定しましょう。gpu idについてはnvidia-smiコマンドを叩けば確認できます。
--datarootのパラメータは、先程ダウンロードしたdeepfashionのデータセットのcihp_test_maskとcihp_train_maskフォルダがどこに置いてあるかを示します。いまは同じディレクトに保存したので./を指定しています。
!python test.py --name deepfashion_smis --dataset_mode deepfashion --dataroot ./ --no_instance \
--gpu_ids 0 --ngf 160 --batchSize 4 --model smis --netG deepfashion
生成された画像は、results/deepfashion_smis/test_latest/images/内のフォルダに保存されます。
確認してみてください。
このような画像が生成されていることを確認できると思います。




終わりに
今回は、服のスタイル変換のFID指標におけるstate-of-the-artのSMISモデルについて解説から、実際に動かすところまで説明しました。画像生成形の深層学習モデルの分野は、日々新しい論文がでてきて驚きの連続です。こういった最新の技術をチェックするのはとても楽しいですね。
今回のモデルは応用先がとても明確で、ファッション業界の企業さん等も必要になってくる技術だと思います。こういった記事をきっかけとして、深層学習モデルの実用化が進んでくると嬉しいなと思います。
私はTwitterで深層学習モデル関連や個人開発についてつぶやいています→@tommy19970714
モデルの解説について、足らない説明や誤っている説明もあるかもしれないので、そのときはコメントください。
参考文献
[1] ZHU, Zhen, et al. Semantically Multi-modal Image Synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. p. 5467-5476.
[2] ITmedia 深層学習で着せ替えも簡単に 画像の一部だけを入れ替え合成する技術「SMIS」
[3] Progressive/Big/StyleGANsの概要とGANsの性能評価尺度