音声認識とGoogle Cloud Speech-to-Text API(以下、Speech-to-Text)の実装方法について、まとめました。
- デモサイト
- Speech-To-Text使用前の設定
- 実装方法
の順に説明していきます。
有料APIのSpeech-to-Textですが、60分の無料枠があります。
無料枠に抑える方法は記事下部に記載してます。
Speech-to-Text は正常に処理された音声の長さに基づいて月ごとに請求され、15 秒単位で切り上げて計算されます。
(中略)
エラーとなったリクエストは、正常に処理されたものとしてカウントされないため、料金は発生しません。
デモサイト
機能のイメージを持って頂くためにデモサイトを作成しました。
PCのChromeで使用できます。
API使用を無料枠に収めたいので利用制限をかけています。(録音時間は最大1分)
テキスト変換出来ない場合があるのでご了承ください。
サイトイメージ
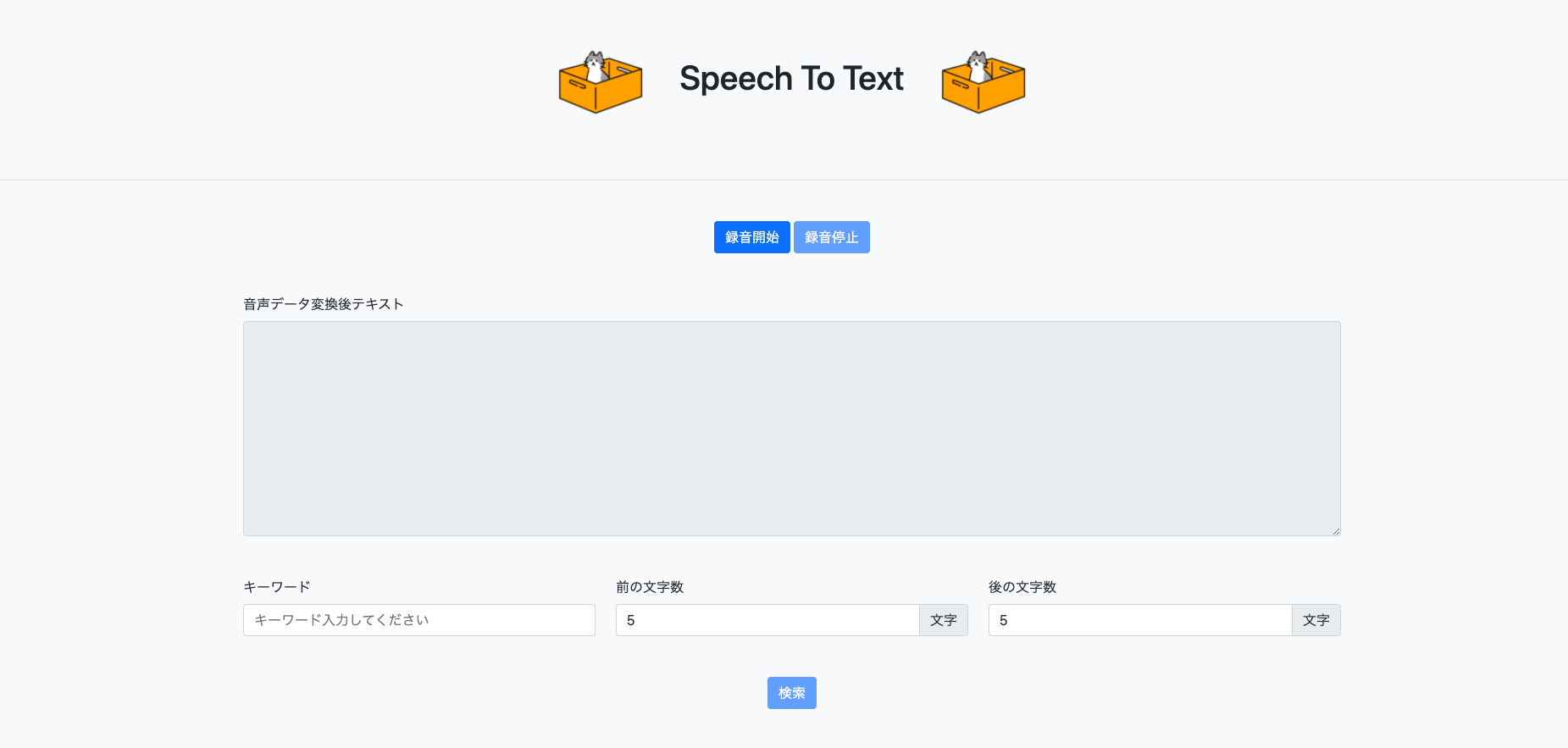
使い方
- 録音開始ボタンを押すとマイクの使用許可が求められます。許可を選択してください。
- 録音が開始されるので色々と話しかけてみてください。録音停止ボタンを押すことで録音が止まります。
- 録音停止ボタンを押したあとテキスト変換が始まります。録音に失敗した際は録音開始ボタン再度押して試してみてください。
- 変換したテキストに対してキーワード検索が出来ます。キーワードと前後に含めたい文字数を設定して検索ボタンを押してください。
- 設定した条件でキーワードが抽出され、検索ボタンの下に表示されます。
デモに使用したソースコード
デモの話はここまで
デモについては以上です。
Speech-To-Text APIやAPI使用方法についての説明に移ります。
Speech-To-Textとは?
名前の通り 音声データのテキスト変換API です。
Google Cloudでは「同期音声認識」「非同期音声認識」「ストリーミング音声認識」「無限ストリーミング音声認識」から音声認識方法を選択でき、デモは「同期音声認識」を利用してテキスト変換を行っています。
導入しやすそうなGoogle Cloudを選択しましたが、
似たサービスがあるので使い慣れている会社から選ぶのもいいと思います。
- IBM:Watson Speech to Text
- Microsoft:Speech Services
- Amazon:Amazon Transcribe
SpeechRecognition(ブラウザAPI)
実験的な機能で使用ブラウザに制限がかかりますが、
簡単に音声データをテキスト変換出来るAPIがブラウザに用意されています。
ブラウザAPIなので料金は発生しません。
- 話し初めてから少し間があくと録音停止が自動でされる
- テキスト変換はリアルタイムに処理される
触ってみた感想として、上記を理解した上でAPI選定しないと痛い目に合いそうだと思いました。
Speech-To-Textの使用前設定
Speech-To-Textを使用するために「APIの有効化」「APIキーの取得」の設定が必要です。
Speech-To-Text APIの有効化
プロジェクト未作成の場合、
GCPの「Cloud Console」から新規プロジェクトを作成してください。
プロジェクト作成後、下記手順よりSpeech-To-Text APIの有効化を行ってください。
- 左ナビゲーションメニューから「APIとサービス→ライブラリ」を選択
- 検索ボックスで「Speech To Text」を検索
- 検索結果の「Cloud Speech-to-Text」を選択
- 「有効にする」ボタンを押下
APIキーの取得
- 左ナビゲーションメニューから「APIとサービス→認証情報」を選択
- 「認証情報を作成 → API キー」を選択
- APIキーが作成されます

録音機能と録音データのテキスト変換の実装
APIキー取得まで出来れば後は実装です。
デモに使用したソースコードをベースに、
録音機能とSpeech-To-Textの使用について説明していきます。
デモサイトの画面操作(機能)やキーワード検索機能については触れません。
気になる方はソースコードをご参照ください。
音声データの取得
// ./app/main.js
// 音声フォーマット変換モジュールの読み込み
import Recorder from "./lib/recoder.js";
// 録音オブジェクト生成
let recorder = new Recorder();
// 録音開始
recorder.start();
// 録音終了
recorder.stop();
録音に必要なモジュールを読み込み、Recorderインスタンス生成。
Recorderインスタンスを使用して録音開始/録音停止を行います。
レコーダーモジュールについて
./app/lib/ 配下のライブラリはこちらを踏襲しました。
コンストラクタ
録音データ格納プロパティやwavフォーマット変換の設定値プロパティを初期化をします。
// ./app/lib/recoder.js
constructor() {
this.bufferSize = 4096;
this.wavSamples = [];
this.stream = null;
this.context = null;
this.input = null;
this.processor = null;
}
startメソッド
録音のためにマイク使用許可をユーザーに求めます。
許可されると録音可能になります。
// ./app/lib/recoder.js
async start() {
// マイク使用許可をユーザーに求める(明示的にカメラをオフに設定)
this.stream = await navigator.mediaDevices.getUserMedia({
audio: true,
video: false,
});
// 録音開始処理を実行
this.captureStart();
}
captureStartメソッド
録音処理です。
音声を扱うためのインスタンス生成や設定を行います。
// ./app/lib/recoder.js
captureStart() {
// 音声再生を管理するインスタンスを生成
this.context = new window.AudioContext();
this.input = this.context.createMediaStreamSource(this.stream);
this.processor = this.context.createScriptProcessor(this.bufferSize, 1, 1);
// 録音データをwavSamplesに格納
this.processor.onaudioprocess = (ev) => {
const sample = ev.inputBuffer.getChannelData(0);
this.wavSamples.push(new Float64Array(sample));
};
// デバイス接続処理
this.input.connect(this.processor);
this.processor.connect(this.context.destination);
}
stopメソッド
録音停止処理です。
録音停止後の後処理やSpeech-To-Textで使用可能な音声データのコーデック変換を行います。
// ./app/lib/recoder.js
stop() {
// キャプチャ状態を解除するためにマイクの開放
this.stream.getTracks().forEach((track) => track.stop());
// デバイス接続解除処理
this.input.disconnect();
this.processor.disconnect();
this.context.close();
// wav変換インスタンス生成
const encoder = new Encoder({
bufferSize: this.bufferSize,
sampleRate: this.context.sampleRate,
samples: this.wavSamples,
});
// 録音の音声形式がwebmなので、wav変換
// Google Cloud Speech To Text に音声データを連携するためにLPCM(LINEAR16)コーデックに変換
const audioBlob = encoder.exportWav();
// 録音データの初期化
this.wavSamples = [];
// 返却値はwavフォーマットのBlobを返却
return audioBlob;
}
気になった単語やAPIの仕様確認時に参照したサイト
音声形式(フォーマット)とコーデックの違いについて
Google Cloud Speech-to-Textでサポートされている音声エンコーディング
captureStartメソッドで使用しているcreateScriptProcessorですが、非推奨の機能です。
AudioWorkletsとAudioWorkletNodeに置き換えることが可能ですが、実装時間が足りずcreateScriptProcessorを使用しています![]()
Speech-To-Textの使用
Speech-To-Textを使用するために、取得したAPIキーを設定。
./app/apiKey.js
// APIキーを設定
const apiKey = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx';
export default apiKey;
録音停止メソッドの返却値(音声データ)をaudioRecognize関数に渡してテキスト変換を行います。
./app/main.js
// wav形式のblobを取得
let audioBlob = recorder.stop();
// 音声認識
audioRecognize(audioBlob);
audioRecognize関数
./app/main.js
// 音声認識APIキーの読み込み
import apiKey from './apiKey.js';
const audioRecognize = async(audioBlob) => {
// 音声ファイルをbase64エンコードするためにFileReaderインスタンスを生成
const reader = new FileReader();
// 音声ファイルをbase64エンコード
reader.readAsDataURL(audioBlob);
// base64エンコードが完了時に呼ばれる
reader.onload = () => {
// エンコード結果に音声ファイル以外の情報が入っているので取り除く
const audioBase64 = reader.result.split(',')[1];
// Speech-To-Textを使用するための設定値
const data = {
config: {
encoding: "LINEAR16", // 音声ファイルのコーデックを指定
languageCode: "ja-JP", // 音声が日本語の場合
audio_channel_count: 1
},
audio: {
content: audioBase64
}
}
// Speech-To-Textを実行
fetch('https://speech.googleapis.com/v1/speech:recognize?key=' + apiKey, {
method: 'POST',
headers: {
'Content-Type': 'application/json; charset=utf-8'
},
body: JSON.stringify(data)
}).then((response) => {
if(!response.ok) {
console.error('サーバーエラー');
}
// API実行結果を返却
return response.text();
}).then((text) => {
// API実行結果をJSONパース
let result_json = JSON.parse(text);
// API実行結果から音声認識結果を取得
text = result_json.results[0].alternatives[0].transcript;
// 画面表示したい要素に内容を上書き
speechToText.textContent = text;
}).catch((error)=>{
console.error('通信に失敗しました', error);
});
};
}
実装の説明は以上です。
後は画面操作と紐付けることでデモサイトのような挙動が実現できます。
API利用制限およびアラート設定
最後に、Speech-To-Textを無料枠で抑える方法について説明します。
APIキーが外部に見えるので、是非設定しておきましょう。
APIキーの制限
- 左ナビゲーションメニューから「APIとサービス→認証情報」を選択
- API キーに作成済みのキーがあるので名前を押下
- 「APIの制限 キーを制限」にチェック
- プルダウンが表示されるので「Cloud Speech-to-Text API」を選択
- 保存ボタンを押下

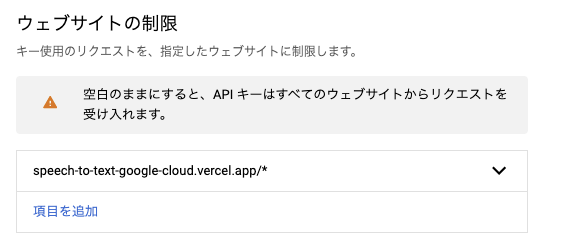
ウェブサイトの制限
デモはvercelを使用しており、
デプロイするとドメインが発行されるので、下記のように設定しています。
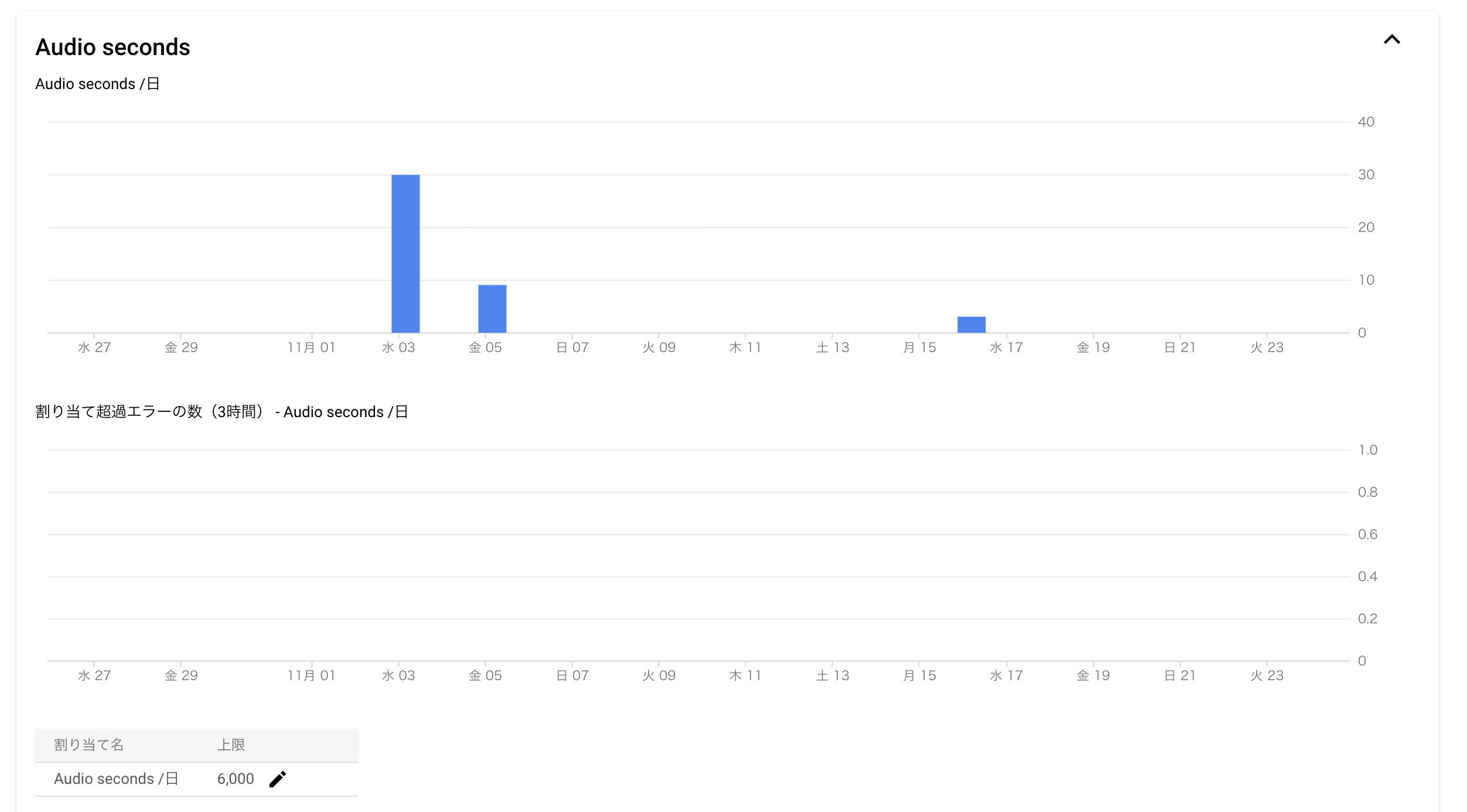
割り当て
下記リンクの左ナビゲーションメニューから「割り当て」を選択
「Audio seconds」「Requests」を開いて、無料枠の60分に収まるように上限を設定してください。

アラート設定
- 左ナビゲーションメニューから「お支払い→予算とアラート」を選択
- 「予算を作成」を押下
- 「APIの制限 キーを制限」にチェック
- 必須項目、期間、プロジェクト、金額、アクションを入力
- 保存ボタンを押下
まとめ
静的画面のコーディング経験ありましたが、デバイスを利用した実装は初めてでワクワクしました![]()
次回はWebカメラとWebAPIを組み合わせた画面を作ってみたいと思います❗
おまけ
MediaRecorder奮闘記
MediaRecorder は簡単に録音機能を実装できるブラウザAPIです。
録音処理で非推奨であるcreateScriptProcessorは使用したくない。だけど、AudioWorkletの実装は難しい。。。
そこで閃いたのがMediaRecorderを利用した方法でした。
-
MediaRecorderを使って音声を録音 - 録音データをwavに変換する
ChromeでMediaRecorderを利用して録音するとwebm音声形式のBlobが返却されます。(変更不可、インスタンス生成時にオプション指定してもダメ)
このBlobをwavフォーマットに変換できれば...
あとは変換だけ...
もう少しで出来そう...
そこから10時間奮闘しましたが、実装出来ませんでした![]()
音声データの加工は難易度が高かったみたいです![]()
実装は叶いませんでしたが、
音声データの加工について色々調べてみるのはとても楽しかったので機会があれば再挑戦してみます![]()