これまでの振り返り
ここまで機械学習の自動化ツールであるDriverless AIの起動からモデルの作成、予測結果の取得やモデルの評価について書きました。
前回の記事はこちら!
モデルの外部実行 Driverless AI -MLの自動化ツール- Part 4
Driverless AIは日本語化もされているので、その情報はこちらをご覧ください。
Driverless AI ついに日本語化!
前回の記事では、MOJOパイプラインを使ってDriverless AIが動いていない環境でもモデルを使って予測してみました。
予測は業務プログラムに組み込んで使えるようになったわけですが、Experiment(学習)を実行するためにはブラウザ上で操作しなければいけないのかと。
検証しているときはいいですが、定期的に再学習してモデルを更新していきたい!となったとき大変ですよね。
ということで、ブラウザ以外でDriverless AIを使う場面に沿って一通り動かしてみます。
今回は、Driverless AI v1.8.0で試しています。
公式のドキュメントはこちらから
Python Client
Driverless AIには、Python Clientが用意されています。
これを使うことで、Pythonのプログラムからブラウザ上でのDriverless AIの操作ができるようになります。
つまり、ブラウザ上で設定項目をクリックしながら動かしていたところ。

以下のようなコードで実行できます。
target="default payment next month"
exp_preview = h2oai.get_experiment_preview_sync(dataset_key= train.key
, validset_key=''
, classification=True
, dropped_cols=[]
, target_col=target
, is_time_series=False
, enable_gpus=False
, accuracy=5
, time=5
, interpretability=5
, reproducible=True
, resumed_experiment_id=''
, config_overrides=None)
これができると、日々溜まっていくデータに対してどんどん新しいモデルを作ったりできます。
Python Clientは学習だけでなくてブラウザ操作でできることほとんどが実行できるようです。
実際に動かしてみる
今回はAquariumの環境を使ってPython Clientを試してみます。
Aquariumの使い方はこちらをご覧ください。
まずは起動から!Driverless AI -MLの自動化ツール- Part 1
データはAquariumの環境上にあるデータをダウンロードして使っています。
ファイルシステム上のパス /data/kaggle/CreditCard にデータがあるのでインポート後にダウンロードしています。

Python Clientのインストール
Python Clientは、Pythonのライブラリをインストールすることで使えるようになります。
Driverless AIのブラウザで、RESOURCES を選択するとメニューがいくつか表示されます。

この表示の中にある、PYTHON CLIENTを選択します。
そうすると、Python Client用のライブラリであるh2oai_clientのwheelがダウンロードされます。

このwheelを、Python Clientを動かしたい環境にコピーします。
Python Clientのインストール
Pythonのバージョンは 3.6 が必須です。
インストールする場合は、下記のコマンドを実行します。
pip install h2oai_client-1.8.0-py3-none-any.whl
データのアップロード
ブラウザを使うときは、学習やテスト用のデータをドラッグ&ドロップでアップロードすることが多いと思います。
(簡易的に試す分には、楽でわかりやすいのでよく使います)
このデータアップロードをPython Clientを使って行ってみます。
使うソースコードはこんな感じです。
<address>, <user>, <password>はお使いの環境に合わせて設定してください。
DAIにアップロードしたいファイルパスを<upload_file_name>に設定します。
from h2oai_client import Client
# Driverless AIへの接続
address = '<address>'
username = '<user>'
password = '<password>'
h2oai = Client(address = address, username = username, password = password)
# データのアップロード
train_data = h2oai.upload_dataset_sync('<upload_file_name>')
Python Clientには、DAIのアドレス、ユーザー情報とそのパスワードが必要です。
Aquariumの場合は、このページの一番したにある Lab URLを使います。
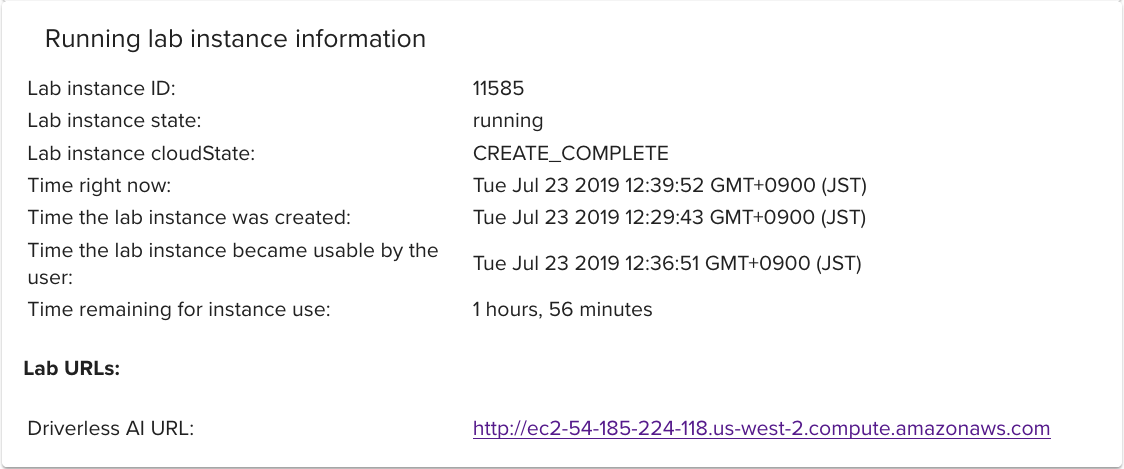
ユーザーとパスワードは、ADMINで大丈夫です。
アップロード対象のデータが**/home/work/data/CreditCard-train.csv**とします。
これらの情報を入れると下のコードになります。
from h2oai_client import Client
# Driverless AIへの接続
address = 'http://ec2-54-185-224-118.us-west-2.compute.amazonaws.com'
username = 'ADMIN'
password = 'ADMIN'
h2oai = Client(address = address, username = username, password = password)
# データセットのリスト
datasets = h2oai.list_datasets(offset=0, limit=100, include_inactive=False)
dataset_list = list(map(lambda x: {"name" : x.name, "key" : x.key}, datasets.datasets))
print('現在のデータセット:')
for data in dataset_list:
print(data['name'])
train_data_path = '/home/work/data/CreditCard-train.csv'
print('\n学習用データのアップロード中 : ', train_data_path)
train_data = h2oai.upload_dataset_sync(train_data_path)
print('\n学習用データ : ' + train_data.name + ', ' + train_data.key)
print('データアップロード完了')
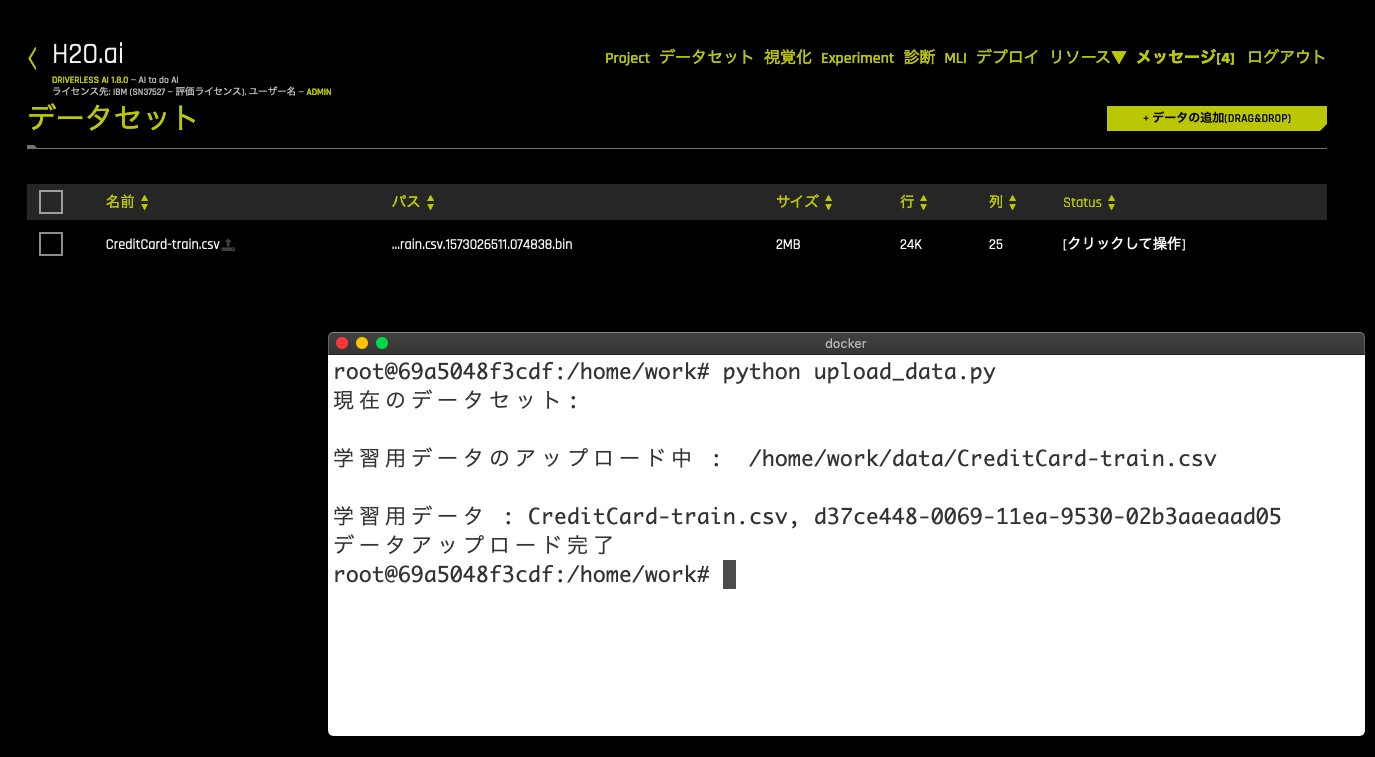
実行するとローカルのCSVファイルがDAI上にアップロードされます。
※スクリーンショットは、Aquariumの環境では無いので日本語になっています。
Experimentの実行
次は、Experiment (学習) をPython Clientから実行してみます。
Experimentは下の表のように設定します。
| 設定項目 | 設定値 |
|---|---|
| 表示名 | start_from_client |
| データ | CreditCard-train.csv |
| ターゲット | default payment next month |
| 精度 | 5 |
| 時間 | 4 |
| 解釈可能性 | 6 |
| スコアラー | AUC |
| 分類 | True |
学習用のデータ CreditCard-train.csv がDAI上にアップロードされている状態とします。
1つ目のデータアップロードを実行したあとの状態です。
Experimentの実行のソースコードはこちらになります。
このソースコードを実行すると、自動的にExperimentが始まります。
from h2oai_client import Client
# Driverless AIへの接続
address = '<address>'
username = '<user>'
password = '<password>'
h2oai = Client(address = address, username = username, password = password)
# データセット一覧の取得
datasets = h2oai.list_datasets(offset=0, limit=100, include_inactive=False)
dataset_list = list(map(lambda x: {"name" : x.name, "key" : x.key}, datasets.datasets))
# 使用データセットのKey取得
for dataset in dataset_list:
if dataset['name'] == 'CreditCard-train.csv':
train_data_key = dataset['key']
# Experimentの設定
target = 'default payment next month'
accuracy = 5
time = 4
interpretability = 6
experiment_name = 'start_from_client'
# Expermentの実行
print('\nExperimentの開始')
experiment = h2oai.start_experiment_sync(dataset_key = train_data_key,
testset_key = '',
target_col = target,
is_classification = True,
accuracy = accuracy,
time = time,
interpretability = interpretability,
scorer = "AUC",
experiment_name = experiment_name)
# モデルのスコア確認
print('\nExperimentの終了')
print("最終モデルのスコア Validation Data: " + str(round(experiment.valid_score, 3)))
ソースコードを動かしてみるとしたのスクリーンショットのようになります。

GIF動画も作ってみました。
プログラムを実行して、Experimentが始まるまでの動画です。

予測の実行
データのアップロード、モデルの作成までPython Clientで実行できました。
あとは、作成されたモデルで予測をする部分をPython Clientで動かしてみます。
予測用のデータを用意しました。
元からあるデータ CreditCard-train.csv の上から5行を抜き出しています。
このデータをCreditCard-pred.csvとして保存しておきます。
(保存場所は学習用のデータと同じ /home/work/data にしています)
| ID | LIMIT_BAL | SEX | EDUCATION | ・・・ | PAY_AMT6 | default payment next month |
|---|---|---|---|---|---|---|
| 24001 | 50000 | 1 | 2 | ・・・ | 707 | 0 |
| 24002 | 60000 | 1 | 2 | ・・・ | 1120 | 1 |
| 24003 | 400000 | 1 | 2 | ・・・ | 959 | 0 |
| 24004 | 20000 | 1 | 5 | ・・・ | 0 | 0 |
| 24005 | 50000 | 1 | 3 | ・・・ | 100 | 0 |
今回は検証のために、正解値がCSV内に入っています。
実際に予測をする場合は、default payment next monthの値がないCSVになると思います。
こちらが、データのアップロードから予測までを行うソースコードです。
同じデータセットがアップロード済みであれば、それを削除して新しいデータをアップロードするようになっています。
from h2oai_client import Client
# Driverless AIへの接続
address = '<address>'
username = '<user>'
password = '<password>'
h2oai = Client(address = address, username = username, password = password)
pred_data_path = '/home/work/data/CreditCard-pred.csv'
# データセットの削除
for dataset in dataset_list:
if dataset['name'] == 'CreditCard-pred.csv':
print('データセットの削除: ', dataset['name'])
h2oai.delete_dataset(dataset['key'])
# 予測用データのアップロード
print('予測用データのアップロード : ', pred_data_path)
pred_data = h2oai.upload_dataset_sync(pred_data_path)
pred_data_key = pred_data.key
# モデルの取得・表示
models = h2oai.list_models(offset=0, limit=100)
models_list = list(map(lambda x: {"name" : x.description, "model_key" : x.key, "key" : x.key}, models.models))
# 使用モデルのKey取得
for model in models_list:
if model['name'] == 'start_from_client':
model_key = model['key']
# 予測の実行
print('\n予測実行開始')
pred = h2oai.make_prediction_sync(
model_key = model_key,
dataset_key = pred_data_key,
output_margin = False,
pred_contribs = False,
keep_non_missing_actuals = False,
include_columns = ['ID', 'default payment next month'])
print('予測実行終了')
# 予測結果のダウンロード
download = h2oai.download(src_path=pred.predictions_csv_path, dest_dir="./result/")
# Option (Pandasで予測結果表示)
import pandas as pd
df = pd.read_csv(download)
print(df)
実行してみます。
root@69a5048f3cdf:/home/work# python test_prediction.py
予測用データのアップロード : /home/work/data/CreditCard-pred.csv
予測用データのkey : e6cd2dba-0059-11ea-9530-02b3aaeaad05
モデル一覧
start_from_client : 62fcdab4-002f-11ea-9530-02b3aaeaad05
予測実行開始
予測実行終了
保存先: ./result/62fcdab4-002f-11ea-9530-02b3aaeaad05_preds_c4e536aa.csv
ID default payment next month default payment next month.0 default payment next month.1
0 24001 0 0.367182 0.632818
1 24002 1 0.853887 0.146113
2 24003 0 0.944019 0.055981
3 24004 0 0.503080 0.496920
4 24005 0 0.875502 0.124498
作成したモデルの精度が良くないので結果は良くないですが、予測結果の取得方法もソースコード内で設定できます。
ダウンロードしたCSVファイルを読み取ってDBに書き込むことでBIツールなどに連携したり、予測結果の参照がしやすくなりそうです。
今回は長めにPython Client試してみました。
手元にあるデータだったり、Aquariumにはファイルシステム内にいくつかテスト用のデータがあるのでそちらを使ってみてください。
これまでの書いた記事一覧
まずは起動から!Driverless AI -MLの自動化ツール- Part 1
学習の実行!Driverless AI -MLの自動化ツール- Part 2
モデルの評価! Driverless AI -MLの自動化ツール- Part 3
モデルの外部実行 Driverless AI -MLの自動化ツール- Part 4
Driverless AI ついに日本語化!