今回は、ローカルLLMでよく利用される Llama.cpp をIBM Power上で動かしてみます。
公開されているコンテナイメージを利用した手軽な方法で試してみます。
こちらでPower用にビルドしたコンテナイメージが公開されています。
https://quay.io/repository/daniel_casali/llama.cpp-mma?tab=info
イメージ名に、mma と入っていますが、これは IBM Power のプロセッサーに内蔵される行列計算を個別に実行するためのアクセラレーターのことを指します。
MMA は Matrix Math Accelerator の頭文字になっています。
※ Power10以降のプロセッサーに搭載されています。
環境
今回は、PowerVS上にインスタンスを作成してさくっと試しています。
そのため、割り当てているリソースはとても少ないです。
- サーバー : IBM Power S1022
- OS : RHEL9.4
- CPU : 3コア
- メモリー : 16GB
※rootで実行していますが、簡易的な検証のためご容赦ください。
Podmanのインストール
RHEL環境のため、Podmanを利用してコンテナを起動します。
もちろんDockerでもよいです。
Podmanがインストールされていない場合は、以下のコマンドでインストールしてください。
# dnf install podman
コンテナのデプロイ
それでは、Llama.cppのコンテナをデプロイしてみます。
ですが、その前にモデルをダウンロードしておきます。
Llama.cppでは、GGUFという形式のモデルが必要です。
今回は、IBMが提供しているGraniteをGGUF形式に変換して公開しているこちらを簡易的に使用してみます。
mkdir で models ディレクトリを作成してください。
ここにモデルをダウンロードします。
# mkdir models
# cd models/
# pwd
/root/models
models ディレクトリに移動した状態で、以下のコマンドを実行しモデルをダウンロードしてください。
curl -L https://huggingface.co/ibm-granite/granite-3.3-2b-instruct-GGUF/resolve/main/granite-3.3-2b-instruct-Q4_K_M.gguf --output granite-3.3-2b-instruct-Q4_K_M.gguf
以下でgranite-3.3-2b-instruct-Q4_K_M.ggufがダウンロードできているか確認しておきましょう。
# ls -l
total 1509088
-rw-r--r--. 1 root root 1545303328 Aug 31 04:23 granite-3.3-2b-instruct-Q4_K_M.gguf
モデルのダウンロードが完了したので、コンテナを実行します。
# podman run -d --privileged -v /root/models:/models -p 6443:8080 --name llamacpp quay.io/daniel_casali/llama.cpp-mma:v9 llama-server --host 0.0.0.0 -m /models/granite-3.3-2b-instruct-Q4_K_M.gguf
-
-v /root/models:/models: 先ほどダウンロードしたモデルが保存されているディレクトリをコンテナにマウントします。 -
-p 6443:8080: コンテナにアクセスできるポートを指定します。6443 でアクセスすることで、コンテナ側の 8080 にアクセスできます。
※PowerVSのため簡易的に使用可能な6443ポートを使っています。
実行すると以下のようにコンテナイメージをダウンロードし、コンテナが起動します。
# podman run -itd --privileged -v /root/models:/models -p 6443:8080 --name llamacpp quay.io/daniel_casali/llama.cpp-mma:v9 --host 0.0.0.0 -m /models/granite-3.3-2b-instruct-Q4_K_M.gguf -c 4096
Getting image source signatures
Copying blob bf3a6c4a822c done |
Copying blob 6f6644037ce7 done |
Copying blob 6613e90bd86b done |
Copying blob 8104dba53ad1 done |
Copying blob 4a69fffa1ed3 done |
Copying config 161a9bcb11 done |
Writing manifest to image destination
c4af46fc2d6a4e6a8809b175fc577671b3429311422b950546d6d013a36c9cd2
ブラウザから以下のURLでアクセスしてみます。
http://<サーバーIP or ホスト名>:6443
画像のように、Llama.cppのChatインターフェースが表示されるはずです。
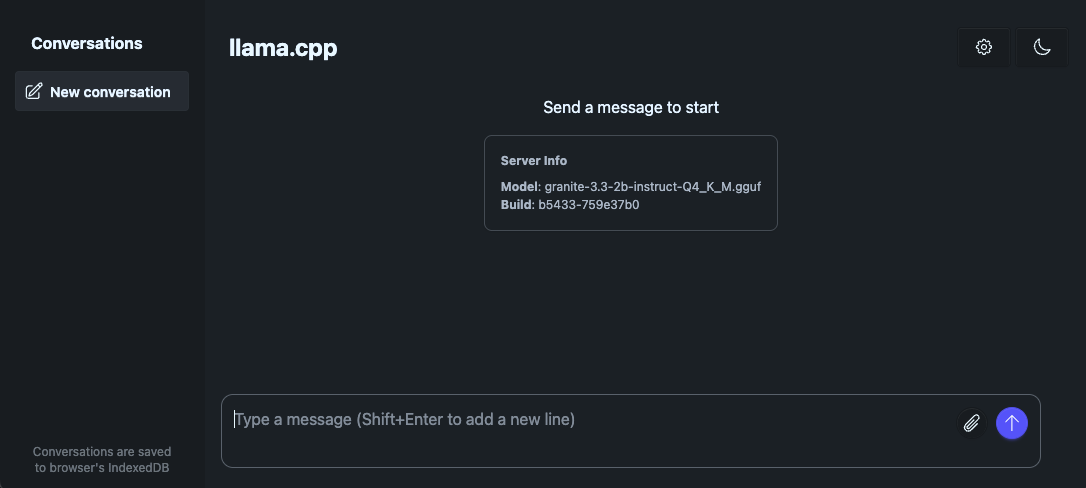
この環境は、少ないリソースで動かしていますが、それなりの速度で回答が返ってきています。

さくっと、手軽にLlama.cppをIBM Power上で動かしてみました。