何がしたいか
サーバまでBGP接続したFull IP Fabric(Pure IP fabric??)上でコンテナ間ネットワークの動作を確認する.
結論として動作を確認できた.
背景
- サーバエンドまでL3接続する事例が2018年から見受けられる
- cumulusも以前から関心があるようだ
- Baremetal 単独(linux) なら容易にできそう
- コンテナOSまでL3接続されているケース (1) (2)
- なぜサーバまでルーティングさせたいか?(ネットワークエンジニア目線)
- オープンスタンダードな技術であるBGPで経路を完全フルコントロール
- ダウンタイムなしでToRのメンテ/upgradeができる
- ネットワークインフラを常に最新の状態に維持できる
- ダウンタイムなしでToRのメンテ/upgradeができる
-
MLAG的なL2のトラブルシューティングからの解放 - ラックに縛られないIPアドレスアサインが可能
- IPアドレス管理コストの低減、リソースの有効活用
- オープンスタンダードな技術であるBGPで経路を完全フルコントロール
要件
ネットワークエンジニアからのリクエスト
- 新しいプラットフォームはサーバエンドまで
完全IP-fabricやからな-
L2接続は提供しないつもりだからそこんとこヨロシク - (
VXLAN/EVPNも考えたけど複雑すぎてな...サーバまでログインしてトラシューはしんどい..)
-
- ToRスイッチとのL3接続は
IPv6 Unnumberedやからそこんとこヨロシク- 大規模展開だと Unnumbered 便利すぎてもう戻れない
- (スイッチのコンフィグはシンプルにしたいし管理や自動化の手間がかかるからね)
K8S管理者からのリクエスト
- コンテナOSは
CoreOSを使う. VMでなくベアメタルサーバに直接インストールする- 物理サーバ性能をフルに使いたいから
- コンテナ間通信でパケットをカプセル化するのはオーバヘッドあるからやめたい
- flannel で VXLAN はやりたくない
- Calico で IP-IP はやりたくない
- ToRにコンテナルート広報許可希望
- ルートリフレクタは自前で管理したくない
- node-port を使用した NAT をやめたいので足掛かりがほしい
-
/26を物理サーバの台数分ね!
ネットワーク構成
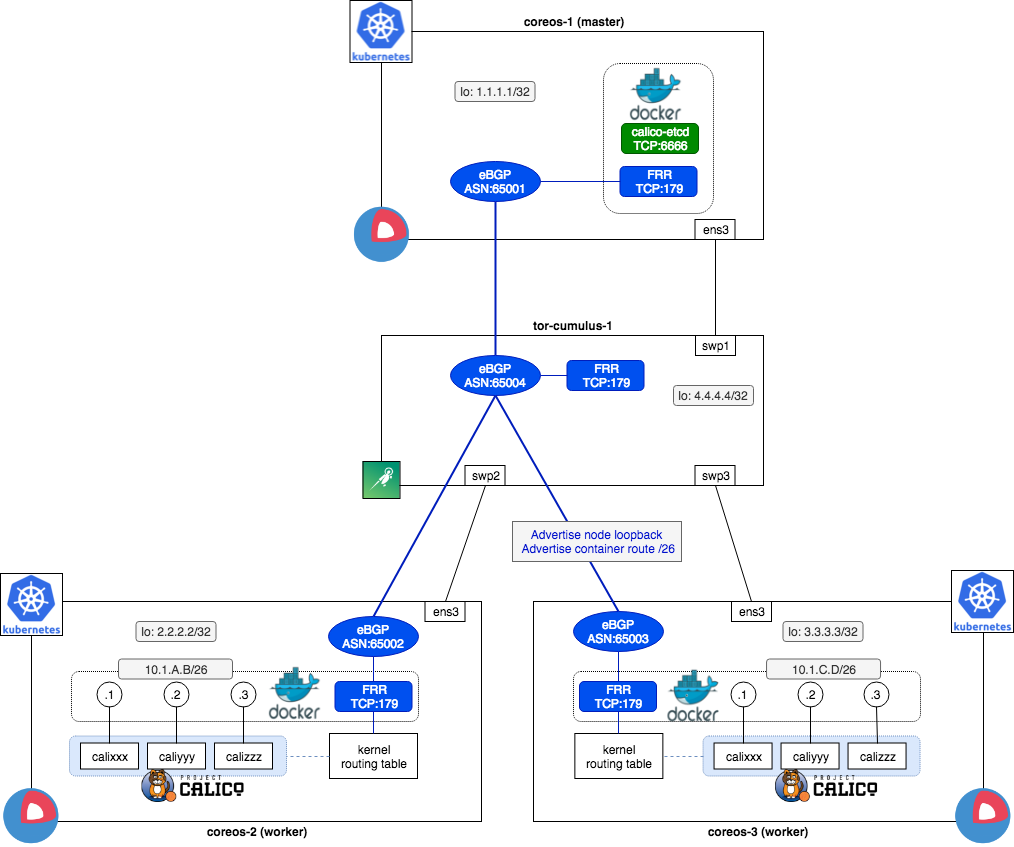
今回検証する構成はこちら. 設計と設定は参考までに.
- ToRと接続するルーティングデーモンは
FRRを選択 - Calico v3系からDocker単体をサポートしなくなっていたので(仕方なく)
K8Sも導入 - 要件としてCoreOSを使用したが Ubuntuなどで代替してもよい
- AS per compute モデルを採用. ASデザインはこちらが参考になる
| カテゴリ | バージョン |
|---|---|
| コンテナOS | CoreOS 2079.3.0 |
| オーケストレーション | Kubernetes v1.15.0 |
| CNI | Calico 3.4.4 |
| ToR スイッチ | Cumulus 3.7.5 |
| サーバ側ルータ | FRR 7.1 |
Out of Scope
- CoreOSの初期デプロイ(L2からL3接続への切替)
- 外部からコンテナへの接続 (追加考慮必須)
- ECMP (問題ないはず)
- 経路フィルタ(スケール時の事故予防のため対策必須)
検証環境構築
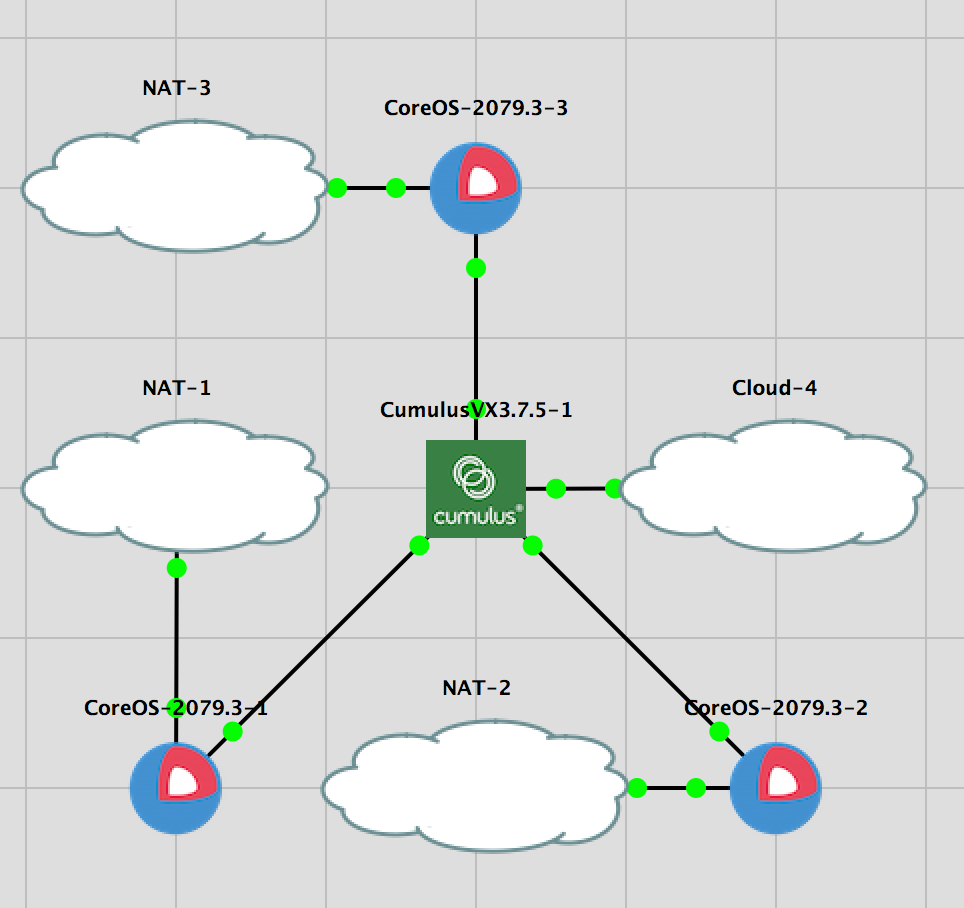
GNS3 上の構築イメージ. CoreOSにはインターネット接続が必要.
ToR (Cumulus-VX) の設定
downlink に Unnumbered で eBGP接続するように設定.
# ----------------------------------------------
# Basic Cumulus
# ----------------------------------------------
net add hostname tor-cumulus-1
net add loopback lo ip address 4.4.4.4/32
net pending
net commit
# ----------------------------------------------
# eBGP
# ----------------------------------------------
# BGP
net add bgp autonomous-system 65004
net add bgp router-id 4.4.4.4
net add bgp bestpath as-path multipath-relax
net add bgp bestpath compare-routerid
net add bgp ipv4 unicast redistribute connected
net pending
net commit
# BGP Unnumbered IF
net add interface swp1-3 ipv6 nd ra-interval 5
net add interface swp1-3 ipv6 nd ra-lifetime 15
net add interface swp1-3 stp bpduguard
net add interface swp1-3 stp portbpdufilter
net pending
net commit
# BGP (downlink)
net add bgp neighbor COMPUTE peer-group
net add bgp neighbor swp1-3 interface peer-group COMPUTE
net add bgp neighbor COMPUTE remote-as external
net add bgp neighbor COMPUTE soft-reconfiguration inbound
net pending
net commit
CoreOS の設定
- docker pull の proxy は重要なので環境に合わせて設定
DNS_SERVER=x.x.x.x
# coreos-1
HOSTNAME=c1
LOOPBACK=1.1.1.1
# coreos-2
HOSTNAME=c2
LOOPBACK=2.2.2.2
# coreos-3
HOSTNAME=c3
LOOPBACK=3.3.3.3
# --------------------------------------------------
# Set Loopback IP
# --------------------------------------------------
# https://coreos.com/os/docs/latest/network-config-with-networkd.html
cat > /etc/systemd/network/static.network <<EOF
[Match]
Name=lo
[Network]
Address=${LOOPBACK}/32
DNS=${DNS_SERVER}
EOF
systemctl restart systemd-networkd
# --------------------------------------------------
# Proxy for docker pull
# --------------------------------------------------
# https://coreos.com/os/docs/latest/customizing-docker.html
# https://docs.docker.com/config/daemon/systemd/
# NO_PROXY doesn't support IP range
mkdir /etc/systemd/system/docker.service.d
cat > /etc/systemd/system/docker.service.d/http-proxy.conf <<EOF
[Service]
Environment="HTTP_PROXY=http://PROXY-SERVER:20080"
Environment="HTTPS_PROXY=http://PROXY-SERVER:20080"
Environment="NO_PROXY=localhost,1.1.1.1,2.2.2.2,3.3.3.3"
EOF
systemctl daemon-reload
systemctl restart docker
systemctl status docker --no-pager
systemctl show --property=Environment docker --no-pager
systemctl enable docker
# --------------------------------------------------
# sysctl
# --------------------------------------------------
# https://coreos.com/os/docs/latest/other-settings.html
cat > /etc/sysctl.d/coreos-routing.conf <<EOF
net.ipv4.ip_forward = 1
net.ipv4.tcp_l3mdev_accept = 1
net.ipv4.udp_l3mdev_accept = 1
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.all.rp_filter = 0
EOF
sysctl --system
# Reboot
reboot
FRRコンテナ の設定
FRR コンテナの生成
- 公式に FRR の Dockerfile が用意されてあるのでありがたく利用
# --------------------------------------------------
# Build FRR7.1 container image
# --------------------------------------------------
# https://github.com/FRRouting/frr/blob/master/docker/debian/Dockerfile
git clone https://github.com/FRRouting/frr.git
cd docker/debian
docker build -t frr-debian:latest .
PROXY=http://PROXY-SERVER:20080
docker build --build-arg https_proxy=${PROXY} --build-arg http_proxy=${PROXY} -t frr-debian:v7.1 .
# If you face "gpg no valid OpenPGP data found" Try to edit Dockerfile
# --- a/docker/debian/Dockerfile
# +++ b/docker/debian/Dockerfile
# -RUN curl -s https://deb.frrouting.org/frr/keys.asc | apt-key add -
# +RUN wget https://deb.frrouting.org/frr/keys.asc && apt-key add ./keys.asc && rm ./keys.asc
# Try to boot a container
docker run -itd --net=host --privileged --name frr frr-debian:v7.1
docker exec -it frr bash
# Stop container
docker rm -f frr
CoreOS 用に調整
FRR はコンテナ化されているが下記設定を入れることでホストのプロセスのごとく使用可能.
- OS起動時に自動起動
-
間違ってkillされても蘇生するように(
Restart=always) - configファイルを物理ノードと共有
ssh core@COREOS
# --------------------------------------------------------------------
# Prepare for config files
# --------------------------------------------------------------------
mkdir -p /var/log/frr
mkdir -p /etc/frr
# config-file: daemons
cat > /etc/frr/daemons <<EOF
bgpd=yes
vtysh_enable=yes
zebra_options="-A 127.0.0.1 -s 90000000"
bgpd_options="-A 127.0.0.1"
EOF
# config-file: frr.conf
cat > /etc/frr/frr.conf <<EOF
log syslog informational
EOF
# config-file: vtysh.conf
cat > /etc/frr/vtysh.conf <<EOF
service integrated-vtysh-config
EOF
# (custom) config-file: frr-systemctl.env
cat > /etc/frr/frr-systemctl.env <<EOF
FRR_DOCKER_IMAGE=frr-debian
FRR_VERSION=v7.1
EOF
# frr user & group
# check uid & group id
docker run -it frr id frr
# > uid=106(frr) gid=109(frr) groups=109(frr),108(frrvty)
groupadd -g 109 frr
useradd -u 106 -g 109 frr --no-create-home -s /sbin/nologin
chmod 666 /etc/frr/*
# --------------------------------------------------------------------
# boot a container
# --------------------------------------------------------------------
docker run -itd --net=host --privileged --name frr \
-v /var/log/frr:/var/log/frr \
-v /etc/frr:/etc/frr \
frr-debian:v7.1
docker exec -it frr bash
exit
# --------------------------------------------------------------------
# Autostart FRR via systemd
# --------------------------------------------------------------------
cat > /etc/systemd/system/frr.service <<EOF
[Unit]
Description=frr
After=docker.service
Requires=docker.service
[Service]
EnvironmentFile=/etc/frr/frr-systemctl.env
ExecStartPre=/usr/bin/docker rm -f frr
ExecStart=/usr/bin/docker run \
--net=host --privileged --name frr \
-v /var/log/frr:/var/log/frr \
-v /etc/frr:/etc/frr \
\${FRR_DOCKER_IMAGE}:\${FRR_VERSION}
ExecStop=-/usr/bin/docker stop frr
ExecReload=/usr/bin/docker exec -t frr /usr/lib/frr/frr-reload
Restart=always
StartLimitBurst=5
StartLimitInterval=30s
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable frr
systemctl start frr
# After rebooting, FRR container will be up automatically
reboot
# You can configure frr.conf directly from coreos
# vi /etc/frr/frr.conf
# systemctl reload frr
eBGP 接続
# --------------------------------------------------------------------
# coreos-1
# --------------------------------------------------------------------
ssh core@coreos-1
docker exec -it frr vtysh
conf t
router bgp 65001
bgp router-id 1.1.1.1
neighbor TOR peer-group
neighbor TOR remote-as external
neighbor TOR ebgp-multihop 255
neighbor ens3 interface peer-group TOR
!
address-family ipv4 unicast
network 1.1.1.1/32
neighbor TOR soft-reconfiguration inbound
end
show run bgp
write memory
exit
# Check
docker exec -it frr vtysh -c "show bgp summary"
# --------------------------------------------------------------------
# coreos-2
# --------------------------------------------------------------------
ssh core@coreos-2
docker exec -it frr vtysh
conf t
router bgp 65002
bgp router-id 2.2.2.2
neighbor TOR peer-group
neighbor TOR remote-as external
neighbor TOR ebgp-multihop 255
neighbor ens3 interface peer-group TOR
!
address-family ipv4 unicast
network 2.2.2.2/32
neighbor TOR soft-reconfiguration inbound
end
show run bgp
write memory
exit
# Check
docker exec -it frr vtysh -c "show bgp summary"
# --------------------------------------------------------------------
# coreos-3
# --------------------------------------------------------------------
ssh core@coreos-3
docker exec -it frr vtysh
conf t
router bgp 65003
bgp router-id 3.3.3.3
neighbor TOR peer-group
neighbor TOR remote-as external
neighbor TOR ebgp-multihop 255
neighbor ens3 interface peer-group TOR
!
address-family ipv4 unicast
network 3.3.3.3/32
neighbor TOR soft-reconfiguration inbound
end
show run bgp
write memory
exit
# Check
docker exec -it frr vtysh -c "show bgp summary"
物理ノード間の接続確認
# IPv6 で BGP:179 が LISTEN しているかどうか
ss -tl6 | grep bgp
# > LISTEN 0 128 *:bgp *:*
# 各ノードの loopback が広報されてきているか
ip route
# > c1 ~ # ip route
# > default via x.x.x.x dev ens4 proto dhcp src y.y.y.y metric 1024
# > 2.2.2.2 via 169.254.0.1 dev ens3 proto 186 metric 20 onlink
# > 3.3.3.3 via 169.254.0.1 dev ens3 proto 186 metric 20 onlink
# > 4.4.4.4 via 169.254.0.1 dev ens3 proto 186 metric 20 onlink
# 各ノードに loopback で到達できるかどうか (例:coreos-1)
ping -c2 -I 1.1.1.1 2.2.2.2
ping -c2 -I 1.1.1.1 3.3.3.3
ping -c2 -I 1.1.1.1 4.4.4.4
K8S の設定
- kubeadm が GAになったのでありがたく利用させてもらう
-
HTTPS_PROXYの有無を切り替えながら各コマンドを実行 - Master node:
c1 - Worker node:
c2,c3 - POD_NETWORK:
10.1.0.0/16
全ノード共通
# --------------------------------------------------
# Install kubeadm (Run every 3 nodes)
# --------------------------------------------------
# https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
# Proxy
export https_proxy=http://PROXY-SERVER:20080
# Install CNI plugin
CNI_VERSION="v0.7.5"
mkdir -p /opt/cni/bin
curl -L "https://github.com/containernetworking/plugins/releases/download/${CNI_VERSION}/cni-plugins-amd64-${CNI_VERSION}.tgz" | tar -C /opt/cni/bin -xz
# Install crictl
CRICTL_VERSION="v1.12.0"
mkdir -p /opt/bin
curl -L "https://github.com/kubernetes-incubator/cri-tools/releases/download/${CRICTL_VERSION}/crictl-${CRICTL_VERSION}-linux-amd64.tar.gz" | tar -C /opt/bin -xz
# Install kubeadm, kubelet, kubectl
# RELEASE="$(curl -sSL https://dl.k8s.io/release/stable.txt)"
RELEASE=v1.15.0
mkdir -p /opt/bin
cd /opt/bin
curl -L --remote-name-all https://storage.googleapis.com/kubernetes-release/release/${RELEASE}/bin/linux/amd64/{kubeadm,kubelet,kubectl}
chmod +x {kubeadm,kubelet,kubectl}
curl -sSL "https://raw.githubusercontent.com/kubernetes/kubernetes/${RELEASE}/build/debs/kubelet.service" | sed "s:/usr/bin:/opt/bin:g" > /etc/systemd/system/kubelet.service
mkdir -p /etc/systemd/system/kubelet.service.d
curl -sSL "https://raw.githubusercontent.com/kubernetes/kubernetes/${RELEASE}/build/debs/10-kubeadm.conf" | sed "s:/usr/bin:/opt/bin:g" > /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
# Unset proxy
unset {http_proxy,https_proxy}
# Enable and start kubele --> Failed. No problem
systemctl enable kubelet
systemctl daemon-reload
systemctl restart kubelet
Master Node のデプロイ
- Master node のIFは loopback(1.1.1.1) で待ち受けるように設定
unset {http_proxy,https_proxy}
APISERVER_IF=1.1.1.1
POD_NETWORK=10.1.0.0/16
kubeadm init --dry-run
kubeadm init --apiserver-advertise-address=${APISERVER_IF} --pod-network-cidr=${POD_NETWORK}
systemctl status kubelet
# > Your Kubernetes control-plane has initialized successfully!
#
# > To start using your cluster, you need to run the following as a regular user:
#
# > mkdir -p $HOME/.kube
# > sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# > sudo chown $(id -u):$(id -g) $HOME/.kube/config
#
# > You should now deploy a pod network to the cluster.
# > Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
# > https://kubernetes.io/docs/concepts/cluster-administration/addons/
#
# > Then you can join any number of worker nodes by running the following on each as root:
#
# > kubeadm join 1.1.1.1:6443 --token xxxxxxx --discovery-token-ca-cert-has sha256:yyyyyyyyyy
#
# Follow instruction
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
Worker Node のデプロイ
- うまく
kubeletが起動しない場合はkubeadm resetを試行してみる
unset {http_proxy,https_proxy}
kubeadm join 1.1.1.1:6443 --token xxxxxx --discovery-token-ca-cert-hash sha256:yyyyyyyyyyy
systemctl status kubelet
# > working
# Check on Master node
kubectl get nodes -o wide
# > name status roles age version
# > c1 ready master 3d23h v1.15.0
# > c2 ready <none> 3d8h v1.15.0
# > c3 ready <none> 3d23h v1.15.0
# coredns は正しく設定していないので無視
kubectl get pods --all-namespaces -o wide
# > kube-system coredns-5c98db65d4-5vmch 0/1 CrashLoopBackOff
# > kube-system coredns-5c98db65d4-whcfz 0/1 CrashLoopBackOff
# > kube-system etcd-c3 1/1 Running
# > kube-system kube-apiserver-c3 1/1 Running
# > kube-system kube-controller-manager-c3 1/1 Running
# > kube-system kube-proxy-gn4b5 1/1 Running
# > kube-system kube-proxy-ksddj 1/1 Running
# > kube-system kube-proxy-nqmwr 1/1 Running
# > kube-system kube-scheduler-c3 1/1 Running
# -------------------------------------------------
# Reset worker node (Revert kubeadm if you need)
# -------------------------------------------------
# Reset on Master
kubectl delete node c2
# Reset on worker
kubeadm reset
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
# Rejoin
kubeadm join 1.1.1.1:6443 --token xxxx --discovery-token-ca-cert-hash sha256:yyyyyyyyyyy
systemctl status kubelet --no-pager
Calico の設定
- Master-node で全て実施する
Calico のダウンロード
# ------------------------------------------------------
# Download Calico
# ------------------------------------------------------
# https://docs.projectcalico.org/v3.4/getting-started/kubernetes/
# https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/calico#installing-with-the-etcd-datastore
# Set proxy
export https_proxy=http://PROXY-SERVER:20080
# Download deployment file
curl -k https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/hosted/etcd.yaml > etcd.yaml
curl -k https://docs.projectcalico.org/v3.4/getting-started/kubernetes/installation/hosted/calico.yaml > calico.yaml
# calicoctl
export https_proxy=http://PROXY-SERVER:20080
curl -O -L https://github.com/projectcalico/calicoctl/releases/download/v3.4.4/calicoctl
unset {http_proxy,https_proxy}
chmod +x calicoctl
cp calicoctl /opt/bin/
calicoctl version
# Client Version: v3.4.4
# Git commit: e3ecd927
# no etcd endpoints specified
Calico のコンフィグ
- calico etcd は Master-node にいるので修正
etcd_endpoints: "http://1.1.1.1:6666"
- BIRD の無効化 (
calico_backend: "none") - コンテナMTU の修正 (
veth_mtu:1450-->1500) - calico-node 起動時に使用するIFの設定
- ここはハマった. calico-node が Master-node(1.1.1.1)に到達できるIF(今回はホストのloopback)を使うように指示
IP_AUTODETECTION_METHOD: "can-reach=1.1.1.1"- calico-node のIPアドレス選択ロジック
# ------------------------------------------------------
# Configuration etcd.yaml
# ------------------------------------------------------
cp etcd.yaml{,.bak}
vi etcd.yaml
# Delete Service part
< ---
<
< # This manifest installs the Service which gets traffic to the Calico
< # etcd.
< apiVersion: v1
< kind: Service
< metadata:
< labels:
< k8s-app: calico-etcd
< name: calico-etcd
< namespace: kube-system
< spec:
< # Select the calico-etcd pod running on the master.
< selector:
< k8s-app: calico-etcd
< # This ClusterIP needs to be known in advance, since we cannot rely
< # on DNS to get access to etcd.
< clusterIP: 10.96.232.136
< ports:
< - port: 6666
# ------------------------------------------------------
# Configuration calico.yaml
# ------------------------------------------------------
cp calico.yaml{,.bak}
vi calico.yaml
# c1 ~ # diff backup/calico.yaml calico.yaml
# 16c16
# < etcd_endpoints: "http://10.96.232.136:6666"
# ---
# > etcd_endpoints: "http://1.1.1.1:6666"
# 24c24
# < calico_backend: "bird"
# ---
# > calico_backend: "none"
# 27c27
# < veth_mtu: "1440"
# ---
# > veth_mtu: "1500"
# 56c56
# < "snat": true,
# ---
# > "snat": false,
# 216c216
# < value: "Always"
# ---
# > value: "Off"
# 227c227
# < value: "192.168.0.0/16"
# ---
# > value: "10.1.0.0/16"
# 241a242,244
# > # CUSTOM
# > - name: IP_AUTODETECTION_METHOD
# > value: "can-reach=1.1.1.1"
Calico のデプロイ
- calico-etcd は Master-node:6666 でデプロイされる
- calico-node は全てのノードにデプロイされる
- 各calico-node から Master-node:6666 にTCPセッションが張れていればOK
# ------------------------------------------------------
# Deploy Calico
# ------------------------------------------------------
kubectl apply -f ./etcd.yaml
kubectl apply -f ./calico.yaml
# Check
# 1台IPアドレスがおかしいcalico-node がいるが無視. READYも0/1になってる.. 謎い
kubectl get pods --namespace=kube-system -o wide | grep calico
# > NAME READY STATUS RESTARTS AGE IP NODE
# > calico-etcd-s9bbx 1/1 Running 0 2d9h 1.1.1.1 c1
# > calico-kube-controllers-8f569859f-fvbh4 1/1 Running 0 2d9h 2.2.2.2 c2
# > calico-node-529jg 0/1 Running 0 2d9h 2.2.2.2 c2
# > calico-node-9qflt 0/1 Running 0 2d9h 192.168.254.132 c3
# > calico-node-rn85g 0/1 Running 0 2d9h 1.1.1.1 c1
# Check
export ETCD_ENDPOINTS=http://1.1.1.1:6666
export ETCDCTL_API=3
calicoctl node status
# BIRD が動作していないことを確認
calicoctl node status
# > c1 ~ # calicoctl node status
# > Calico process is running.
# >
# > None of the BGP backend processes (BIRD or GoBGP) are running.
calicoctl get node --output wide
# > c1 ~ # calicoctl get node -o wide
# > NAME ASN IPV4 IPV6
# > c1
# > c2
# > c3
# Check on worker node
# calico-node connects to etcd:6666 ??
ss -tn4
# > c3 ~ # ss -tn4 | grep 6666
# > ESTAB 0 0 3.3.3.3:47050 1.1.1.1:6666
# > ESTAB 0 0 3.3.3.3:47052 1.1.1.1:6666
# ------------------------------------------------------
# Retry if you face error
# ------------------------------------------------------
kubectl delete -f calico.yaml
kubectl delete -f etcd.yaml
rm -rf /var/etcd/calico-data/
kubectl apply -f etcd.yaml
kubectl apply -f calico.yaml
コンテナ用IPアドレスレンジ設定
IP-IPとNATを無効化したIPアドレスプール設定かどうか確認.
export ETCD_ENDPOINTS=http://1.1.1.1:6666
export ETCDCTL_API=3
calicoctl get ipPool --output=wide
calicoctl get ipp -o yaml
# Delete default pool
calicoctl delete pool default-ipv4-ippool
# https://docs.projectcalico.org/v3.4/usage/changing-ip-pools
cat > ip_pool.yml <<EOF
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: new-IPpool-1
spec:
cidr: 10.1.0.0/16
ipipMode: Never
natOutgoing: false
disabled: false
EOF
calicoctl replace -f ip_pool.yml
calicoctl get ipPool --output=wide
# > c1 ~ # calicoctl get ipPool --output=wide
# > NAME CIDR NAT IPIPMODE DISABLED
# > new-ippool-1 10.1.0.0/16 false Never false
コンテナ間通信の確認
コンテナのデプロイ
ping確認用にAlpineをばら撒く.
# Deploy Alpine linux container
cat > alpine_test.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: alpine-deployment
spec:
selector:
matchLabels:
app: alpine
replicas: 8
template:
metadata:
labels:
app: alpine
spec:
containers:
- name: alpine
image: alpine:latest
command: [ "sleep", "360000000" ]
EOF
kubectl apply -f alpine_test.yaml
# Check
kubectl get pods --namespace=default
# > c1 ~ # kubectl get pods --namespace=default -o wide
# > NAME READY STATUS RESTARTS AGE IP NODE
# > alpine-deployment-6d6d594b98-n5qls 1/1 Running 0 2d8h 10.1.8.195 c1
# > alpine-deployment-6d6d594b98-wplgn 1/1 Running 0 2d8h 10.1.8.197 c1
# > alpine-deployment-6d6d594b98-z4xnp 1/1 Running 0 2d8h 10.1.8.196 c1
# > alpine-deployment-6d6d594b98-86lf7 1/1 Running 0 2d8h 10.1.71.196 c2
# > alpine-deployment-6d6d594b98-bz44d 1/1 Running 0 2d8h 10.1.71.195 c2
# > alpine-deployment-6d6d594b98-swb2n 1/1 Running 0 2d8h 10.1.71.197 c2
# > alpine-deployment-6d6d594b98-zbk9x 1/1 Running 0 2d8h 10.1.240.3 c3
# > alpine-deployment-6d6d594b98-59qv9 1/1 Running 0 2d8h 10.1.240.2 c3
# coreosごとに割り当てられた/26のIPアドレスレンジが確認できる
コンテナIPアドレスレンジの広報
今回はcalico-birdがいないので物理ノードごとにアサインされた/26のルートを広報する設定をFRRに手動投入. 物理ノードがもつIPレンジ内(/26)に存在しないコンテナへの通信がきた場合、デフォルトルートに転送されてしまうのを防ぐためblackholeでパケットを破棄する設定を入れておく.
# c1: 10.1.8.192/26
# c2: 10.1.71.192/26
# c3: 10.1.240.0/26
# --------------------------------------------------------------------
# coreos-1
# --------------------------------------------------------------------
ssh core@coreos-1
docker exec -it frr vtysh
conf t
router bgp 65001
address-family ipv4 unicast
network 10.1.8.192/26
end
show run bgp
write memory
exit
# Add blackhole
ip route add blackhole 10.1.8.192/26
# --------------------------------------------------------------------
# coreos-2
# --------------------------------------------------------------------
ssh core@coreos-2
docker exec -it frr vtysh
conf t
router bgp 65002
address-family ipv4 unicast
network 10.1.71.192/26
end
show run bgp
write memory
exit
# Add blackhole
ip route add blackhole 10.1.71.192/26
# --------------------------------------------------------------------
# coreos-3
# --------------------------------------------------------------------
ssh core@coreos-3
docker exec -it frr vtysh
conf t
router bgp 65003
address-family ipv4 unicast
network 10.1.240.0/26
end
show run bgp
write memory
exit
# Add blackhole
ip route add blackhole 10.1.240.0/26
# --------------------------------------------------------------------
# Check
# --------------------------------------------------------------------
docker exec -it frr vtysh -c "show bgp summary"
# > c1 ~ # docker exec -it frr vtysh -c "show bgp summary"
# > IPv4 Unicast Summary:
# > BGP router identifier 1.1.1.1, local AS number 65001 vrf-id 0
# > BGP table version 16
# > RIB entries 15, using 2400 bytes of memory
# > Peers 1, using 21 KiB of memory
# > Peer groups 1, using 64 bytes of memory
# >
# > Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
# > ens3 4 65004 97209 97206 0 0 0 3d08h59m 6
# >
# > Total number of neighbors 1
ip route
# > c1 ~ # ip route
# > default via x.x.x.x dev ens4 proto dhcp src y.y.y.y metric 1024
# > 2.2.2.2 via 169.254.0.1 dev ens3 proto 186 metric 20 onlink
# > 3.3.3.3 via 169.254.0.1 dev ens3 proto 186 metric 20 onlink
# > 4.4.4.4 via 169.254.0.1 dev ens3 proto 186 metric 20 onlink
# > 10.1.8.192 dev cali6f4dad4308f scope link <------ blackhole を作るとcalico が自動生成
# > blackhole 10.1.8.192/26 <------ このレンジ内のコンテナが存在しない場合、パケット破棄
# > 10.1.8.195 dev calib7851807e18 scope link <------ 自コンテナへの経路
# > 10.1.8.196 dev cali65f73545565 scope link
# > 10.1.8.197 dev cali9e70c7d2b28 scope link
# > 10.1.71.192/26 via 169.254.0.1 dev ens3 proto 186 metric 20 onlink <----- c2配下のコンテナへの経路
# > 10.1.240.0/26 via 169.254.0.1 dev ens3 proto 186 metric 20 onlink <----- c3配下のコンテナへの経路
ping 疎通確認
# ping 疎通確認(c1コンテナ --> c2コンテナ)
# Master node
ssh core@core-1
kubectl exec -it alpine-deployment-6d6d594b98-n5qls sh
ip addr show dev eth0
# > 4: eth0@if19: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
# > link/ether 82:01:1a:39:77:7f brd ff:ff:ff:ff:ff:ff
# > inet 10.1.8.195/32 scope global eth0
# > valid_lft forever preferred_lft forever
ping 10.1.71.195
# > PING 10.1.71.195 (10.1.71.195): 56 data bytes
# > 64 bytes from 10.1.71.195: seq=0 ttl=61 time=1.334 ms
# > 64 bytes from 10.1.71.195: seq=1 ttl=61 time=1.065 ms
# ping 疎通確認(c1コンテナ --> c1コンテナ)
ping 10.1.71.196
# > PING 10.1.71.196 (10.1.71.196): 56 data bytes
# > 64 bytes from 10.1.71.196: seq=0 ttl=61 time=1.608 ms
# > 64 bytes from 10.1.71.196: seq=1 ttl=61 time=1.485 ms
考察
今回の構成のメリット
- CoreOS 上で FRRコンテナを稼働させることで
IPv6 UnnumberedでToRとL3接続可能- コンテナプラットフォームにおいても Full IP fabric のメリットを享受
- ToR が cumulus であれば双方
FRRなので相性が良い
- コンテナの経路をネットワーク機器(ToR)に広報することで外部からコンテナに直接アクセスできる
- 構成のシンプル化
- ルートリフレクタ不要
-
IP-IP不要
- 実戦で使うには追加の実装が必要
- Service x ContainerIP の紐づけを取得し動的に設定を変更する仕組みが必要
-
node-portを使用しなくてよい可能性
- 構成のシンプル化
-
FRRを使用することで経路制御やフィルタリングが容易-
calico-node内蔵のBIRDでは柔軟に設定ができないように見えた
-
今回の構成のデメリット
- 物理ノードごとに割り当てられた
/26を広報する設定をFRRに入れる必要がある- calico の IPアドレスレンジ割当ロジックを確認して自動化したい
-
calico-birdなら自動でやってくれていた箇所 -
prefix-listでフィルタしてredistribute connectedでもいいと思ったが、caliIF自体にIPアドレスがついているわけではないので広報されない
-
- ネットワーク管理者とK8Sアドミンの管理境界が
FRRでかぶってしまう
- calico の IPアドレスレンジ割当ロジックを確認して自動化したい
- 障害点が増える(FRR)
- FRR が落ちるとその物理ノードのネットワークはダウンする
- FRR コンテナを K8S の管理対象にできない
- FRR がそもそもUPしてないと
masterとworker間の通信が成立しないため
- FRR がそもそもUPしてないと
- コンテナの経路が
ToRにも広報されてくる- 今回は物理ノードごとに
/26なので経路数的に問題になることはないはずだがネットワークエンジニアは気にしておくべき
- 今回は物理ノードごとに
おわりに
Full IP fabric なネットワーク構成上で K8SxCoreOSxCalicoを使用したコンテナネットワークの動作を確認できた. Calico のデフォルトルーティングデーモンであるBIRDを、あえてFRRに置き換えることでネットワークエンジニア、K8S管理者双方でメリットを得られる構成となった. 今回はCalicoで検証したが、CNI周りはまだデファクトが決まっていない状況に見えるので今後も動向を注視していきたい.