1. はじめに
松尾研LLMコンペ2025の予選に、私たちは30名体制で挑みました。大規模なGPU環境(H100×288基を12チームでシェア)と、多彩なバックグラウンドを持つメンバーが集まる場は、まさに人と技術の総合力が試される舞台でした。
しかし、実際に一番の壁になったのはGPUの性能差でもモデル精度の限界でもなく、「人の動き」と「チームの設計」でした。本記事では、予選を通じて見えてきた課題とデータに基づく学びを振り返り、大人数チームに限らず小規模でも参考になる示唆をまとめます。
2. 活動時間のリアル
まず浮き彫りになったのは、活動時間の偏りです。メンバーの7割以上が「平日夜」に活動しており、日中に動けるのはごく少数。平均すると週あたり 12.8時間の稼働でした。
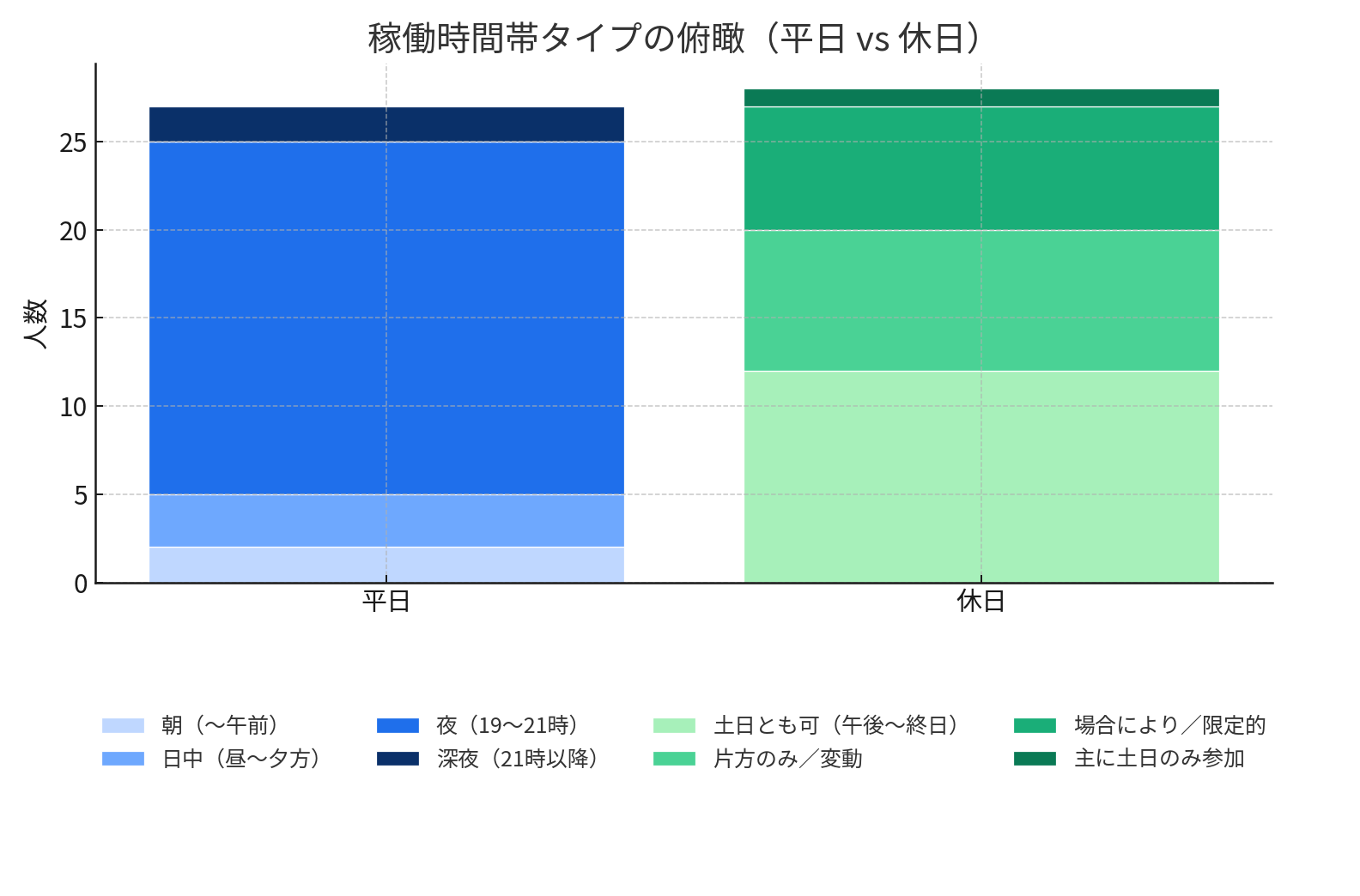
図1. 稼働時間帯タイプの俯瞰(平日 vs 休日)―平日は夜型が支配的、休日は分散傾向
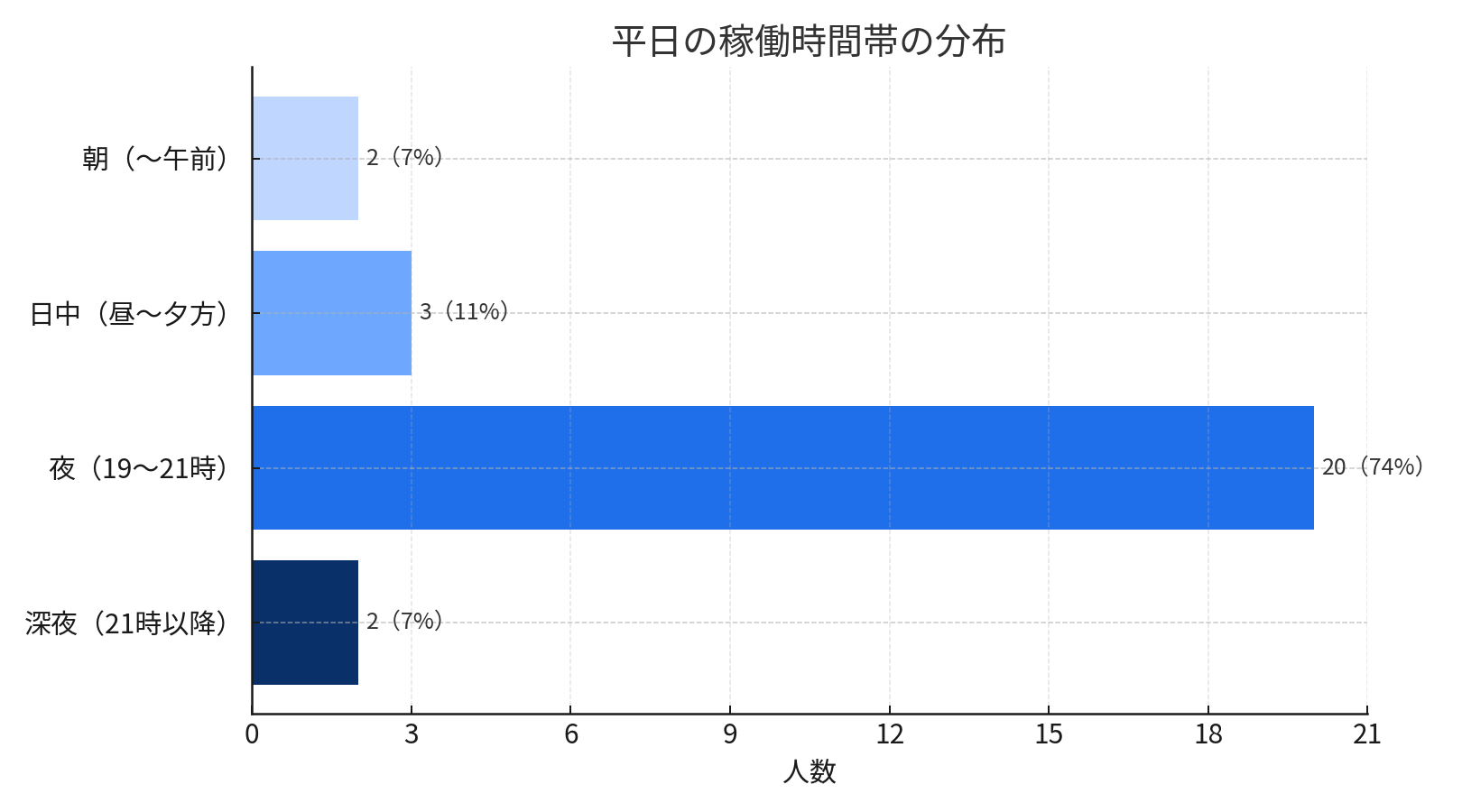
図2. 平日の稼働時間帯の分布(人数+%、夜に集中)

図3. 休日(土日・祝日)の稼働タイプ(人数+%、二極化が顕著)
- 週に20時間以上フルコミットできるメンバーもいれば、4時間程度しか取れない人もいる。実態は二極化していた
- 休日は「終日稼働できる人」と「限定的な人」に分かれ、全員で一斉に作業するのは難しかった
- その結果、GPUジョブを平日日中に安定的に流せる人材が限られ、効率を落とす要因となった
教訓:チーム会議は夜21時前後に集中させ、日中は「数少ない日中稼働メンバー」にモデル開発、ジョブ管理を任せる体制を取るべきでした。
3. チームの特徴傾向
性格的な傾向も興味深いデータが出ました。
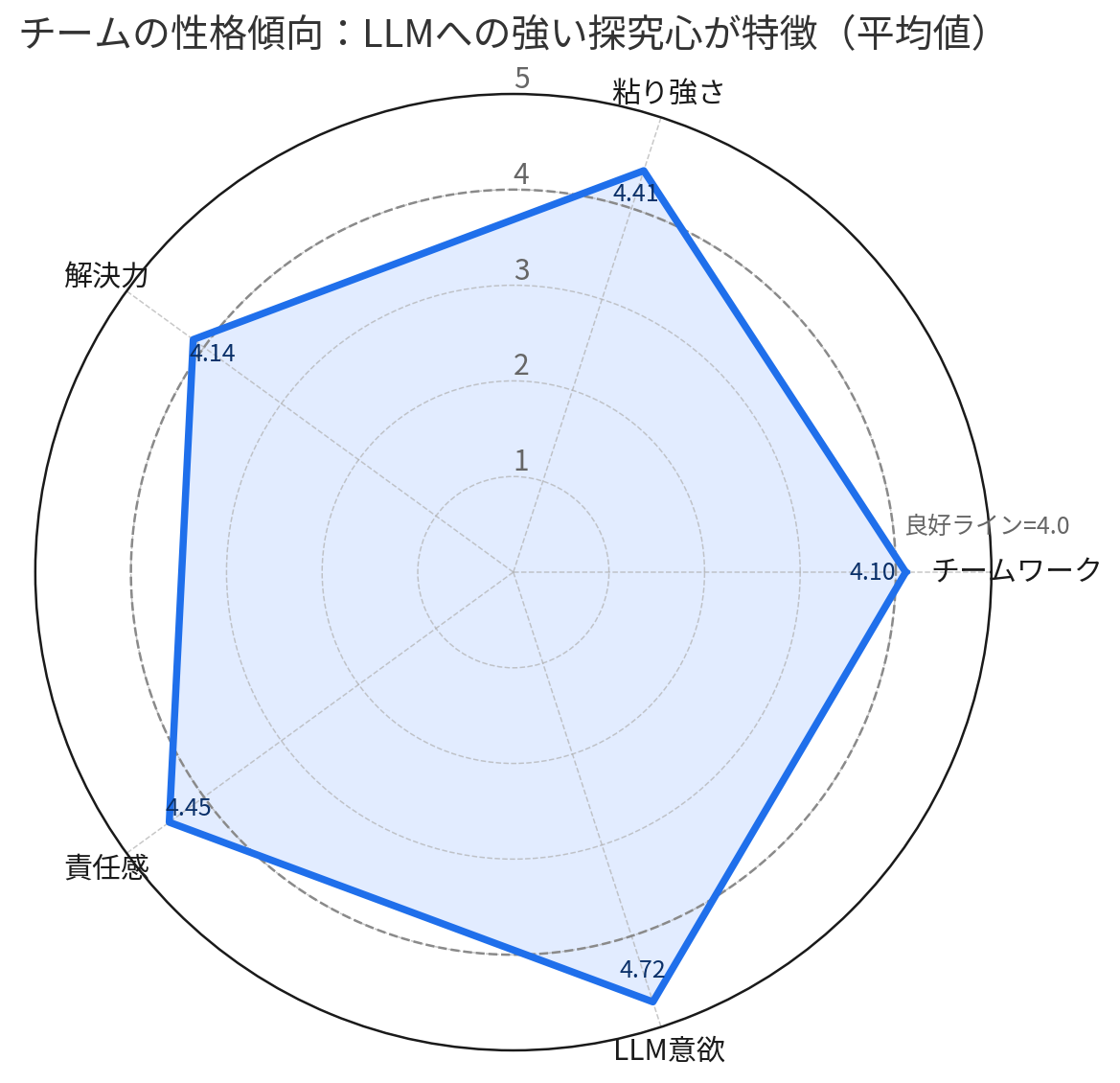
図4. チームの性格傾向(LLM意欲が突出し、連携が相対的に課題)
- LLM開発意欲は平均4.7/5で突出。ほとんど全員が「やりたい!」という思いを持っていました
- 粘り強さ(4.41)と責任感(4.45)も高水準で、継続力と遂行力が強み
- チームワーク(報連相) は4.10と他指標に比べて 相対的に低め。水準としては十分だが、意思決定と情報連携の“詰め”が課題でした
※良好ライン=4.0(図中の破線)。全体として“穴は小さい五角形”だが、最も強いのはLLM意欲、詰め所は連携という形。
この傾向は大人数チーム特有の問題に見えますが、実は5〜10人規模の小さなチームでも同じです。
報連相が曖昧だと「誰かがやってくれるだろう」と思われがちで、成果物が統合されないまま流れてしまう――そんな罠はどの規模でも起こり得ます。
4. 技術的な理解度の分布
知識面では、基礎的な理解は十分に広がっていました。
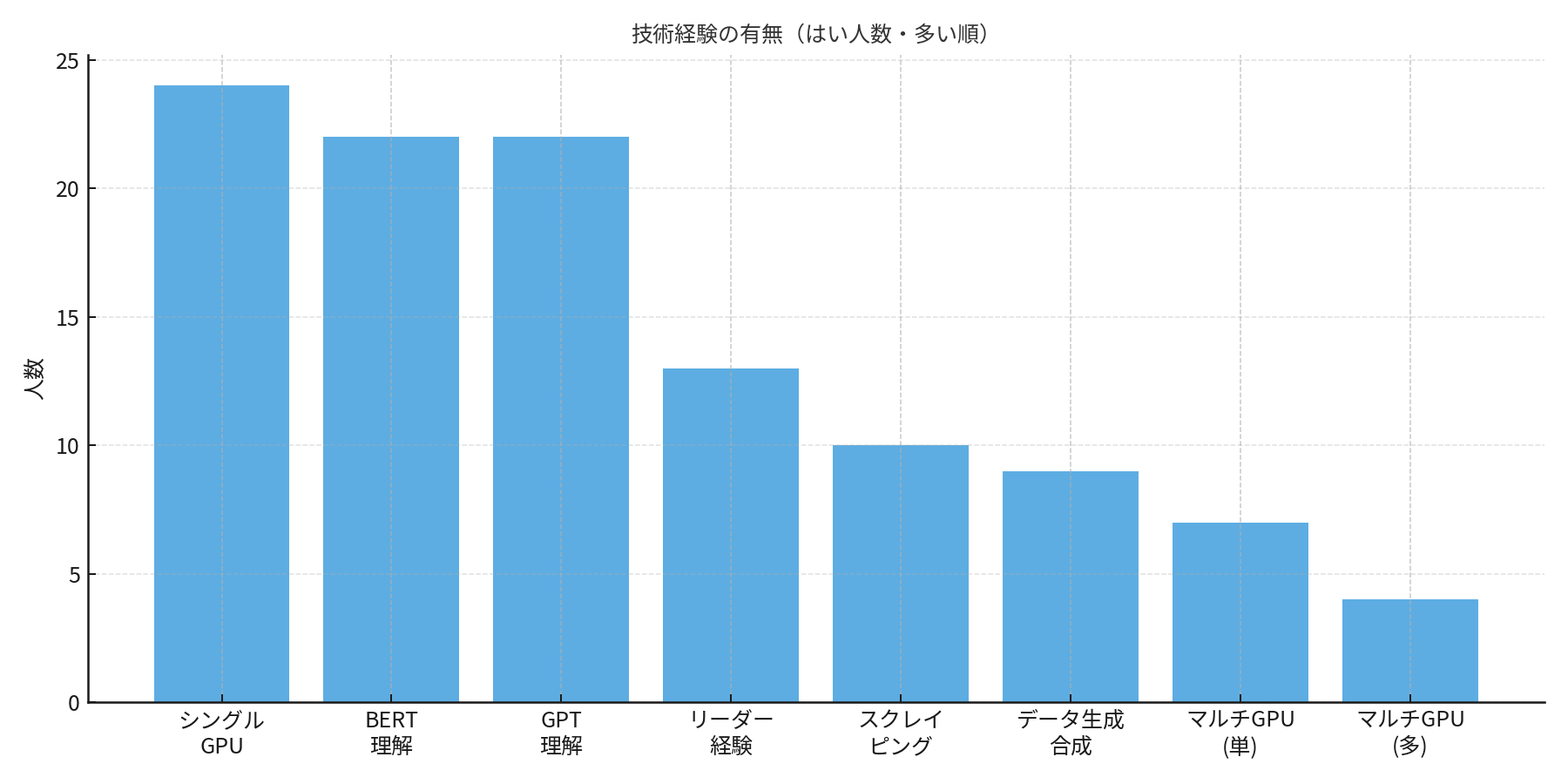
図5. 技術スキルの分布(基礎スキルは厚いが、マルチGPU経験は少数)
- BERT/GPTの理解:7割以上
- シングルGPUでの学習:8割以上
一方で、
- シングルノードマルチGPU:24%
- マルチノード:14%
というように、スケールアウト経験はほとんどありませんでした。
また、Pythonの実装スキルは厚かった一方で、Linux操作やSlurmを用いたジョブ管理に習熟している人材は限られており、実験運用が属人化していた。この偏りが、GPUリソース活用の足かせとなった。
結果として、マルチノード学習の挑戦は遅れ気味で、GPUリソースを十分に活かせなかったのです。挑戦枠としては有意義でしたが、主戦に据えるにはリスクが高すぎました。
5. 実際に直面した課題
データが示す通り、以下のような問題が現場で繰り返し起きました。
-
方向性が不明確で動きづらい
「リーダーが最終的にGPUで回すから」と思われがちで、メンバーの着手が遅れました -
リサーチ結果が形にならない
良いアイデアや調査が共有されても、タスクに変換されず消えるケースが多発 -
マルチノード挑戦が進まない
経験者が少なく、環境構築の段階で停滞。結果的に時間切れとなりました -
直前のGRPO失敗
提出直前に強化学習を試みたものの性能が下がり、SFTモデルを提出
6. 得られた教訓
予選を終えて見えたのは、次の3つのポイントでした。
-
人の分布を読むことが最初の戦略
夜型が多いなら夜に集中。マルチノード経験が薄ければ挑戦は「時間箱=作業時間をあらかじめ区切る方法」に閉じ込めるべきでした -
自律だけでは動けない
自由に任せても、経験不足だと「動けない人」が増えます。例えば、締切1週間前で候補凍結、締切3日前で最終案を一つにまとめるような“段階的な締切”を設けるべきでした -
不採用タスクも資産化する仕組み
「やったのに使われなかった」で不満が残る。たとえ不採用でもWiki化し、次の参考に残すべきでした
7. 反省とアンチパターン(今回の学びを一般化)
予選を通じて「これはやってはいけない」というパターンも明確になりました。次のような行動は、大人数チームでは失敗の再現性が高いことが分かりました。
-
自主性に振り切る
→ 経験不足の環境では手が止まります。意思決定やタスク化がないと動けなくなる人が続出しました -
直前の新規RL導入(強化学習による微調整)
→ 勝率を下げる典型。短期間ではチューニング不足のまま評価に突入してしまい、精度劣化を招きました -
「毎日Slackハドル=親切」と思う
→ リーダーが常時ハドル(Slackでできる簡単なWeb会議)を開き、誰でも相談できる場を用意していた。自由参加の雰囲気は良かったが、意思決定や優先順位整理には使われず、結局“何をやるか決まらない場”になってしまった -
成果の不採用を黙殺する
→ 貢献が承認されないと、やる気のカーブが急速に下がります。小さくても承認の仕組みが必要でした -
マルチノードを主戦に直結させる
→ マルチノード担当が稼働できず、モデル学習が属人化してしまいました。結果的に提出用の主戦GPUを限られた人が抱え込む形となり、リスクの高い運用に。挑戦枠は「別枠」で管理し、主戦環境とは切り離すべきでした
8. まとめ
GPUやモデルの力だけでは勝てない。予選を通じて痛感したのは、人と時間の設計こそ最大の鍵だということです。心理的安全性を確保しつつ、ルールで動きをデザインする。
今回の経験から得られたこの視点は、大人数チームだけでなく、5〜10人の小規模チームでも同じように役立つはずです。
私たちが学んだ「落とし穴と打ち手」、そして「反省とアンチパターン」が、これから挑むチームや運営の参考になれば幸いです。
本プロジェクトは、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の「日本語版医療特化型LLMの社会実装に向けた安全性検証・実証」における基盤モデルの開発プロジェクトの一環として行われます。