この記事はRust Advent Calendar 2021 カレンダー2の1日目の記事です。
はじめに
エンジニアは一度はJSONパーサーをフルスクラッチで実装したほうが良いという天啓を受け、RFC 8259を読みつつRustでJSONパーサーを実装してみました。パーサーの実装は面白く勉強になり満足しましたが折角なのでhands-on形式の記事にしようと思いこの記事を書きました。
Rustの基本的な文法が分かる方向けに記事を書きましたが、これからRustを勉強してみたい方にもぜひ挑戦してほしいです。
複雑な機能は使っていないので、分からない文法や標準ライブラリは公式ドキュメントを読めば十分補完できると思います。
monkey-json
本記事ではRustでJSONパーサー(monkey-json)を実装して、最終的に簡易JSON prettierコマンドラインツールmjを作ることにします。
実装は全て標準ライブラリ内で収めました。実装はRFC 8259準拠なゆるふわJSONパーサーになっています。
monkey-jsonのソースコードはGitHubで管理しています。
内容の不備等はコメントでご指摘いただけると助かります。
今回のプロジェクト構成は以下の通りです。
src
├── bin
│ └── mj.rs # 自作jsonパーサーを利用した簡易prettier
├── lexer.rs # lexerの実装
├── lib.rs # jsonライブラリの実装
└── parser.rs # parserの実装
進め方としてはコードを書きながら、それに対応するテストコード(cargo testでテスト実行)も書いていきます。ぜひ皆さんも自分の手を動かして実装してみてください。
JSONとは
JSONとはJavaScript Object Notation(JSON)の略で、軽量かつ言語非依存のデータ記述形式です。
以下が具体的なJSONの例です。基本的にはkey-valueの形式でデータが格納されています。
{
"key0": "screwsat",
"key1": 10,
"key2": true,
"key3": false,
"key4": null,
"key5": {
"key1": [1, 2, 3, 4, null, "togatoga"],
"key2": "あいうえお",
"key3": "\" \\ \/ \b \f \n \r \t"
},
"key6": -11.0111,
"key7": 1e-10
}
ただし以下のようなValueしかないJSONも合法です。
null
123
JSONは4つの基本的な型と2つの構造的な型で表すことができます。型の一覧とValueの例です。
- 基本的な型
- strings / string
-
"togatoga","rust"
-
- numbers / number
-
1000000007,1e10,0.1234,-11.45
-
- booleans / boolean
-
true,false
-
- null
null
- strings / string
- 構造的な型
- objects / object
{"key": "value"}
- arrays / array
[1,2,3][true, {"キー": null}]
- objects / object
JSONパーサーの実装
入力文字列を愚直にパースしてJSONの値に変換していく実装は複雑でバグを埋め込みやすいです。(e.g. 不要な空白の扱い, Key-Valueのパース, ネストされたJSON)
今回、実装するJSONパーサーは文字列から最終的なJSONの値を得るのに2つのステップを行います。
文字列(String) -> 字句解析(lexer,tokenizer) -> 構文解析(parser)
難しい漢字が出てきてましたが、やってることはとてもシンプルです。
-
字句解析とは文字列をこれ以上分割することができない
Token単位に分割する- 入力: 文字列
- 出力: Tokenの配列
-
構文解析とは字句解析で得られたTokenの配列をParse(評価)してJSONの値を返す
- 入力: Tokenの配列
- 出力: JSONの値
それでは最初に字句解析を行うプログラムであるLexer(字句解析器)を実装していきましょう。
Lexer(字句解析器)の実装(lexer.rs)
ここでは文字列をTokenに分割する字句解析の実装を行います。
今回はここ
|
v
文字列 -> 字句解析(tokenize) -> 構文解析
例えば、以下のようなJSONがあった場合
{
"number":123,
"boolean":true,
"string":"togatoga",
"object":{
"number":2E10
}
}
このJSONを字句解析した結果は以下のようになります。
[
// start {
Token::LeftBrace,
// begin: "number": 123,
Token::String("number".to_string()),
Token::Colon,
Token::Number(123f64),
Token::Comma,
// end
// begin: "boolean": true,
Token::String("boolean".to_string()),
Token::Colon,
Token::Bool(true),
Token::Comma,
// end
// begin: "string": "togatoga",
Token::String("string".to_string()),
Token::Colon,
Token::String("togatoga".to_string()),
Token::Comma,
// end
// begin: "object": {
Token::String("object".to_string()),
Token::Colon,
Token::LeftBrace,
// begin: "number": 2E10
Token::String("number".to_string()),
Token::Colon,
Token::Number(20000000000f64),
// end
Token::RightBrace,
// end
Token::RightBrace,
// end
]
未知な変数(Token)が出現すると頭が混乱しますよね。
JSONのStringが与えられたら、Tokenの配列が得られる事が理解できれば十分です。
型と構造体を定義
lexer.rsにTokenを定義します。
#[derive(Debug, PartialEq, Clone)]
pub enum Token {
String(String), // 文字列
Number(f64), // 数値
Bool(bool), // 真偽値
Null, // Null
WhiteSpace, // 空白
LeftBrace, // { JSON object 開始文字
RightBrace, // } JSON object 終了文字
LeftBracket, // [ JSON array 開始文字
RightBracket, // ] JSON array 終了文字
Comma, // , JSON value 区切り文字
Colon, // : "key":value 区切り文字
}
字句解析を行うLexerの構造体を定義する。
/// JSONの文字列をParseして`Token`単位に分割
pub struct Lexer<'a> {
/// 読み込み中の先頭文字列を指す
chars: std::iter::Peekable<std::str::Chars<'a>>,
}
LexerはJSONの文字列を先頭から一文字ずつ読み込み。読み込み中の先頭の文字がTokenのどれかに一致するかを確かめます。一致した場合は読み込み中の先頭文字を一致したTokenの文字列分だけ移動(seek)させる必要が有ります。
このような処理はstd::iter::Peekableを用いることで効率的に実現することが出来ます。
字句解析中エラーを表すLexerErrorの構造体を定義する。このエラーは文字列がJSONとして不正な場合エラーが発生する。
/// 字句解析中に発生したエラー
#[derive(Debug)]
pub struct LexerError {
/// エラーメッセージ
pub msg: String,
}
impl LexerError {
fn new(msg: &str) -> LexerError {
LexerError {
msg: msg.to_string(),
}
}
}
字句解析で必要となる関数を全て定義する。
impl<'a> Lexer<'a> {
/// 文字列を受け取りLexerを返す
pub fn new(input: &str) -> Lexer {
Lexer {
chars: input.chars().peekable(),
}
}
/// 文字列を`Token`単位に分割をする
pub fn tokenize(&mut self) -> Result<Vec<Token>, LexerError> {
let mut tokens = vec![];
while let Some(token) = self.next_token()? {
match token {
// 空白は今回は捨てるがデバッグ情報として使える(行、列)
Token::WhiteSpace => {}
_ => {
tokens.push(token);
}
}
}
Ok(tokens)
}
/// 一文字分だけ読み進め、tokenを返す
fn next_return_token(&mut self, token: Token) -> Option<Token> {
self.chars.next();
Some(token)
}
/// 文字列を読み込み、マッチしたTokenを返す
fn next_token(&mut self) -> Result<Option<Token>, LexerError> {
unimplemented!()
}
/// nullの文字列をparseする
fn parse_null_token(&mut self) -> Result<Option<Token>, LexerError> {
unimplemented!()
}
/// (true|false)の文字列をparseする
fn parse_bool_token(&mut self, b: bool) -> Result<Option<Token>, LexerError> {
unimplemented!()
}
/// 数字として使用可能な文字まで読み込む。読み込んだ文字列が数字(`f64`)としてParseに成功した場合Tokenを返す。
fn parse_number_token(&mut self) -> Result<Option<Token>, LexerError> {
unimplemented!()
}
/// 終端文字'\"'まで文字列を読み込む。UTF-16(\u0000~\uFFFF)や特殊なエスケープ文字(e.g. '\t','\n')も考慮する
fn parse_string_token(&mut self) -> Result<Option<Token>, LexerError> {
unimplemented!()
}
/// utf16のバッファが存在するならば連結しておく
fn push_utf16(result: &mut String, utf16: &mut Vec<u16>) -> Result<(), LexerError> {
unimplemented!()
}
}
tokenizeが動作するための関数を順に実装していきましょう。
next_tokenの実装
先頭の文字を読み込み、マッチしたTokenを返します。先頭の文字をTokenの開始文字として扱うことで開始文字にマッチしたら残りの部分まで一気にパースを行う。例えば、先頭の文字がtなら、残りはtrueだと仮定してパースを行う。
/// 先頭の文字からマッチしたTokenを返す
fn next_token(&mut self) -> Result<Option<Token>, LexerError> {
// 先頭の文字列を読み込む
match self.chars.peek() {
Some(c) => match c {
// 一文字分だけ読み進め、Tokenを返す
// WhiteSpaceは' 'もしくは'\n'
c if c.is_whitespace() || *c == '\n' => {
Ok(self.next_return_token(Token::WhiteSpace))
}
'{' => Ok(self.next_return_token(Token::LeftBrace)),
'}' => Ok(self.next_return_token(Token::RightBrace)),
'[' => Ok(self.next_return_token(Token::LeftBracket)),
']' => Ok(self.next_return_token(Token::RightBracket)),
',' => Ok(self.next_return_token(Token::Comma)),
':' => Ok(self.next_return_token(Token::Colon)),
// Note
// 以下のマッチ条件は開始文字が該当するTokenの開始文字なら、Tokenの文字列分だけ読み進める
// Stringは開始文字列 '"'
// e.g. "togatoga"
'"' => {
// parse string
self.chars.next();
self.parse_string_token()
}
// Numberは開始文字が[0-9]もしくは('+', '-', '.')
// e.g.
// -1235
// +10
// .00001
c if c.is_numeric() || matches!(c, '+' | '-' | '.') => self.parse_number_token(),
// Booleanの"true"の開始文字は 't'
// e.g.
// true
't' => self.parse_bool_token(true),
// Boolean("false")の開始文字は'f'
// e.g.
// false
'f' => self.parse_bool_token(false),
// Nullの開始文字は'n'
// e.g.
// null
'n' => self.parse_null_token(),
// 上のルールにマッチしない文字はエラー
_ => Err(LexerError::new(&format!("error: an unexpected char {}", c))),
},
None => Ok(None),
}
}
Nullのparse(parse_null_token)実装
文字列としてはnull以外はありえないので非常にシンプルです。
nullはn,u,l,lの4文字で構成されてるので4文字分読み込み連結した文字列が"null"だった場合はToken::Nullを返すようにします。
/// nullの文字列をparseする
fn parse_null_token(&mut self) -> Result<Option<Token>, LexerError> {
let s = (0..4).filter_map(|_| self.chars.next()).collect::<String>();
if s == "null" {
Ok(Some(Token::Null))
} else {
Err(LexerError::new(&format!(
"error: a null value is expected {}",
s
)))
}
}
テストを書いて実際に正しいかどうかを確認しましょう。cargo test(テスト指定: cargo test lexer::tests::test_null)
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_null() {
let null = "null";
let tokens = Lexer::new(null).tokenize().unwrap();
assert_eq!(tokens[0], Token::Null);
}
}
Boolのparse(parse_bool_token)実装
trueもしくはfalseなのでparse_null_tokenと一緒で文字数分まで読み進めて連結した文字列がtrueならToken::Bool(true)を返し、falseならToken::Bool(false)を返すように実装します。
/// (true|false)の文字列をparseする
fn parse_bool_token(&mut self, b: bool) -> Result<Option<Token>, LexerError> {
if b {
let s = (0..4).filter_map(|_| self.chars.next()).collect::<String>();
if s == "true" {
Ok(Some(Token::Bool(true)))
} else {
Err(LexerError::new(&format!(
"error: a boolean true is expected {}",
s
)))
}
} else {
let s = (0..5).filter_map(|_| self.chars.next()).collect::<String>();
if s == "false" {
Ok(Some(Token::Bool(false)))
} else {
Err(LexerError::new(&format!(
"error: a boolean false is expected {}",
s
)))
}
}
}
trueとfalseの2つのパターンのテストコードです。
#[test]
fn test_bool() {
let b = "true";
let tokens = Lexer::new(b).tokenize().unwrap();
assert_eq!(tokens[0], Token::Bool(true));
let b = "false";
let tokens = Lexer::new(b).tokenize().unwrap();
assert_eq!(tokens[0], Token::Bool(false));
}
Numberのparse(parse_number_token)実装
Numberは符号付き整数(+1000,-25,30)や小数(1.0000,-0.5,.111111)や指数(1e10や1E-10)があるため実装が大変です。今回は簡単な実装を選ぶことにしました。まずNumberは整数型も小数も全てf64の浮動小数点として扱うことにします。
符号、小数、指数に必要な記号(+,-,e,E,.)もしくは数字(0-9)文字を全て読み込み連結します。連結した文字列がRustのf64として解釈可能ならToken::Numberを返します。RFC8259 Numbersの仕様にないNumberまでパース可能となります。
/// 数字として使用可能な文字まで読み込む。読み込んだ文字列が数字(`f64`)としてParseに成功した場合Tokenを返す。
fn parse_number_token(&mut self) -> Result<Option<Token>, LexerError> {
let mut number_str = String::new();
while let Some(&c) = self.chars.peek() {
// 数字に使いそうな文字は全て読み込む
// 1e10, 1E10, 1.0000
if c.is_numeric() | matches!(c, '+' | '-' | 'e' | 'E' | '.') {
self.chars.next();
number_str.push(c);
} else {
break;
}
}
// 読み込んだ文字列が`f64`としてparse出来た場合、Tokenを返す
match number_str.parse::<f64>() {
Ok(number) => Ok(Some(Token::Number(number))),
Err(e) => Err(LexerError::new(&format!("error: {}", e.to_string()))),
}
テストコードです。
#[test]
fn test_number() {
//integer
let num = "1234567890";
let tokens = Lexer::new(num).tokenize().unwrap();
assert_eq!(tokens[0], Token::Number(1234567890f64));
let num = "+123";
let tokens = Lexer::new(num).tokenize().unwrap();
assert_eq!(tokens[0], Token::Number(123f64));
//float
let num = "-0.001";
let tokens = Lexer::new(num).tokenize().unwrap();
assert_eq!(tokens[0], Token::Number(-0.001));
let num = ".001";
let tokens = Lexer::new(num).tokenize().unwrap();
assert_eq!(tokens[0], Token::Number(0.001));
// exponent
let num = "1e-10";
let tokens = Lexer::new(num).tokenize().unwrap();
assert_eq!(tokens[0], Token::Number(0.0000000001));
let num = "+2E10";
let tokens = Lexer::new(num).tokenize().unwrap();
assert_eq!(tokens[0], Token::Number(20000000000f64));
}
Stringのparse(parse_string_token)実装
Stringのparse実装はエスケープされた文字(改行:\n,タブ:\t UTF-16:\ud83e\udd14 = 🤔)を考慮する必要がありますが、基本的に先頭の2つの文字をチェックすることで比較的簡単に実装することが出来ます。
(エスケープ文字の種類はRFC8259のStringsをご参照ください)
今回はエスケープ文字の中でUTF-16だけデコード処理(\uD83E\uDD7A => 🥺)をしてそれ以外のエスケープ文字(\n)は入力のまま格納します。UTF-16は簡単に説明すると16bitを1つの単位とし1もしくは2つで構成される文字(\u3006 = 〆, \uD83D\uDE4F = 🙏)です。(Lexerでは1単位=\uxxxx=5文字)
先頭文字がエスケープ開始文字\の場合、次の文字も続けて読み込み。UTF-16の開始文字(\u,xxxx)だった場合残りの4文字(xxxx)を読み込みUTF-16のバッファに保存しておきます。UTF-16以外の文字の追加や関数のreturn前にバッファの中身を全て文字列に連結するようにしましょう。(push_utf16)
/// 終端文字'\"'まで文字列を読み込む。UTF-16(\u0000~\uFFFF)や特殊なエスケープ文字(e.g. '\t','\n')も考慮する
fn parse_string_token(&mut self) -> Result<Option<Token>, LexerError> {
let mut utf16 = vec![];
let mut result = String::new();
while let Some(c1) = self.chars.next() {
match c1 {
// Escapeの開始文字'\\'
'\\' => {
// 次の文字を読み込む
let c2 = self
.chars
.next()
.ok_or_else(|| LexerError::new("error: a next char is expected"))?;
if matches!(c2, '"' | '\\' | '/' | 'b' | 'f' | 'n' | 'r' | 't') {
// 特殊なエスケープ文字列の処理
// https://www.rfc-editor.org/rfc/rfc8259#section-7
// utf16のバッファを文字列にpushしておく
Self::push_utf16(&mut result, &mut utf16)?;
// 今回はエスケープ処理はせずに入力のまま保存しておく
result.push('\\');
result.push(c2);
} else if c2 == 'u' {
// UTF-16
// \u0000 ~ \uFFFF
// \uまで読み込んだので残りの0000~XXXXの4文字を読み込む
// UTF-16に関してはエスケープ処理を行う
let hexs = (0..4)
.filter_map(|_| {
let c = self.chars.next()?;
if c.is_ascii_hexdigit() {
Some(c)
} else {
None
}
})
.collect::<Vec<_>>();
// 読み込んだ文字列を16進数として評価しutf16のバッファにpushしておく
match u16::from_str_radix(&hexs.iter().collect::<String>(), 16) {
Ok(code_point) => utf16.push(code_point),
Err(e) => {
return Err(LexerError::new(&format!(
"error: a unicode character is expected {}",
e.to_string()
)))
}
};
} else {
return Err(LexerError::new(&format!(
"error: an unexpected escaped char {}",
c2
)));
}
}
// 文字列の終端'"'
'\"' => {
// utf16のバッファを文字列にpushしておく
Self::push_utf16(&mut result, &mut utf16)?;
return Ok(Some(Token::String(result)));
}
// それ以外の文字列
_ => {
// utf16のバッファを文字列にpushしておく
Self::push_utf16(&mut result, &mut utf16)?;
result.push(c1);
}
}
}
Ok(None)
}
/// utf16のバッファが存在するならば連結しておく
fn push_utf16(result: &mut String, utf16: &mut Vec<u16>) -> Result<(), LexerError> {
if utf16.is_empty() {
return Ok(());
}
match String::from_utf16(utf16) {
Ok(utf16_str) => {
result.push_str(&utf16_str);
utf16.clear();
}
Err(e) => {
return Err(LexerError::new(&format!("error: {}", e.to_string())));
}
};
Ok(())
}
テストコードです。emojiが可愛いですね。
#[test]
fn test_string() {
let s = "\"togatoga123\"";
let tokens = Lexer::new(s).tokenize().unwrap();
assert_eq!(tokens[0], Token::String("togatoga123".to_string()));
let s = "\"あいうえお\"";
let tokens = Lexer::new(s).tokenize().unwrap();
assert_eq!(tokens[0], Token::String("あいうえお".to_string()));
let s = r#""\u3042\u3044\u3046abc""#; //あいうabc
let tokens = Lexer::new(s).tokenize().unwrap();
assert_eq!(tokens[0], Token::String("あいうabc".to_string()));
let s = format!(r#" " \b \f \n \r \t \/ \" ""#);
let tokens = Lexer::new(&s).tokenize().unwrap();
assert_eq!(
tokens[0],
Token::String(r#" \b \f \n \r \t \/ \" "#.to_string())
);
let s = r#""\uD83D\uDE04\uD83D\uDE07\uD83D\uDC7A""#;
let tokens = Lexer::new(&s).tokenize().unwrap();
assert_eq!(tokens[0], Token::String(r#"😄😇👺"#.to_string()));
}
tokenizeのテストを追加
lexer.rsに必要な全ての関数を実装することが出来ました。最後にtokenizeのテストを追加して確認しましょう。
#[test]
fn test_tokenize() {
let obj = r#"
{
"number": 123,
"boolean": true,
"string": "togatoga",
"object": {
"number": 2E10
}
}
"#;
// object
let tokens = Lexer::new(obj).tokenize().unwrap();
let result_tokens = [
// start {
Token::LeftBrace,
// begin: "number": 123,
Token::String("number".to_string()),
Token::Colon,
Token::Number(123f64),
Token::Comma,
// end
// begin: "boolean": true,
Token::String("boolean".to_string()),
Token::Colon,
Token::Bool(true),
Token::Comma,
// end
// begin: "string": "togatoga",
Token::String("string".to_string()),
Token::Colon,
Token::String("togatoga".to_string()),
Token::Comma,
// end
// begin: "object": {
Token::String("object".to_string()),
Token::Colon,
Token::LeftBrace,
// begin: "number": 2E10,
Token::String("number".to_string()),
Token::Colon,
Token::Number(20000000000f64),
// end
Token::RightBrace,
// end
Token::RightBrace,
// end
];
tokens
.iter()
.zip(result_tokens.iter())
.enumerate()
.for_each(|(i, (x, y))| {
assert_eq!(x, y, "index: {}", i);
});
// array
let a = "[true, {\"キー\": null}]";
let tokens = Lexer::new(a).tokenize().unwrap();
let result_tokens = vec![
Token::LeftBracket,
Token::Bool(true),
Token::Comma,
Token::LeftBrace,
Token::String("キー".to_string()),
Token::Colon,
Token::Null,
Token::RightBrace,
Token::RightBracket,
];
tokens
.iter()
.zip(result_tokens.iter())
.for_each(|(x, y)| assert_eq!(x, y));
以上でlexer.rsの実装は完了です。最後にテストがすべて通るか確認しましょう。
% cargo test lexer
Finished test [unoptimized + debuginfo] target(s) in 0.00s
Running unittests (target/debug/deps/monkey_json-cf488cbc24c6e4aa)
running 5 tests
test lexer::tests::test_bool ... ok
test lexer::tests::test_number ... ok
test lexer::tests::test_null ... ok
test lexer::tests::test_string ... ok
test lexer::tests::test_tokenize ... ok
それでは次にJSONパーサーを実装しましょう。
JSON Value(lib.rs)とパーサーの実装(parser.rs)
この章では構文解析を実装します。
構文解析では字句解析のtokenizeで得られたTokenを評価してJSON Valueに変換します。
今回はここ
|
v
文字列 -> 字句解析(tokenize) -> 構文解析
parser.rsの実装に入る前にlib.rsにJSON Valueを表すenumを定義しましょう。
ついでにJSON Valueに対してpython-likeな方法でアクセスできるようにコードを追加しましょう。
use std::collections::BTreeMap;
#[derive(Debug, Clone, PartialEq)]
pub enum Value {
String(String), // 文字列
Number(f64), // 数値
Bool(bool), // 真偽値
Null, // Null
Array(Vec<Value>), // JSON Array
Object(BTreeMap<String, Value>), // JSON Object
}
/// ユーザーのエンドポイント
/// 入力のJSONの文字列から`Value`を返す
pub fn parse(input: &str) -> Result<Value, ParserError> {
todo!()
}
/// {"key": true}
/// v["key"] => Value::Bool(true)
impl std::ops::Index<&str> for Value {
type Output = Value;
fn index(&self, key: &str) -> &Self::Output {
match self {
Value::Object(map) => map
.get(key)
.unwrap_or_else(|| panic!("A key is not found: {}", key)),
_ => {
panic!("A value is not object");
}
}
}
}
/// [null, false, 3]
/// v[3] => Value::Number(3f64)
impl std::ops::Index<usize> for Value {
type Output = Value;
fn index(&self, idx: usize) -> &Self::Output {
match self {
Value::Array(array) => &array[idx],
_ => {
panic!("A value is not array");
}
}
}
}
これで準備が整いましたのでパーサーの実装をしていきましょう。
パーサーの構造体を定義
parser.rsにParserを定義します。
パースに必要な関数とエラーの構造体を定義し、空のテストコードを追加しておきましょう。
use crate::{lexer::Token, Value};
#[derive(Debug, Clone)]
pub struct ParserError {
pub msg: String,
}
impl ParserError {
pub fn new(msg: &str) -> ParserError {
ParserError {
msg: msg.to_string(),
}
}
}
pub struct Parser {
/// `Lexer`で`tokenize`した`Token`一覧
tokens: Vec<Token>,
/// `tokens`の先頭
index: usize,
}
impl Parser {
/// `Token`の一覧を受け取り`Parser`を返す。
pub fn new(tokens: Vec<Token>) -> Parser {
Parser { tokens, index: 0 }
}
/// `Array`のパースを行う。
/// [1, 2, 3, null, "string"]
fn parse_array(&mut self) -> Result<Value, ParserError> {
todo!()
}
/// `Object`のパースを行う。
/// {
/// "key1": 12345,
/// "key2": 6789
/// }
fn parse_object(&mut self) -> Result<Value, ParserError> {
todo!()
}
/// `Token`を評価して`Value`に変換する。この関数は再帰的に呼び出される。
pub fn parse(&mut self) -> Result<Value, ParserError> {
todo!()
}
/// 先頭の`Token`を返す。
fn peek(&self) -> Option<&Token> {
self.tokens.get(self.index)
}
/// 先頭の`Token`を返す。(先頭に`Token`があることを想定してる)
fn peek_expect(&self) -> Result<&Token, ParserError> {
self.peek()
.ok_or_else(|| ParserError::new("error: a token isn't peekable"))
}
/// 先頭の`Token`を返して、1トークン進める。
fn next(&mut self) -> Option<&Token> {
self.index += 1;
self.tokens.get(self.index - 1)
}
/// 先頭の`Token`を返して、1トークン進める。(先頭に`Token`があることを想定してる)
fn next_expect(&mut self) -> Result<&Token, ParserError> {
self.next()
.ok_or_else(|| ParserError::new("error: a token isn't peekable"))
}
}
#[cfg(test)]
mod test {
use std::collections::BTreeMap;
use crate::{lexer::Lexer, Value};
use super::Parser;
#[test]
fn test_parse_object() {
}
#[test]
fn test_parse_array() {
}
#[test]
fn test_parse() {
}
}
parse -> parse_object -> parse_array 関数の順で実装していきましょう。
JSON parse実装(parse:parser.rs)
parse関数はJSON Valueのパースを行います。
parse関数の処理は以下の通りです。
- 先頭の
Tokenの読み込む-
TokenがObjectの開始文字(Token::LeftBrace)-
parse_objectの返り値を返す
-
-
TokenがArrayの開始文字(Token::LeftBracket)-
parse_arrayの返り値を返す
-
- それ以外(
String,Number,Bool,Null)- 値をそのまま返す
-
/// `Token`を評価して`Value`に変換する。この関数は再帰的に呼び出される。
pub fn parse(&mut self) -> Result<Value, ParserError> {
let token = self.peek_expect()?.clone();
let value = match token {
// { はObjectの開始文字
Token::LeftBrace => self.parse_object(),
// [ はArrayの開始文字
Token::LeftBracket => self.parse_array(),
Token::String(s) => {
self.next_expect()?;
Ok(Value::String(s))
}
Token::Number(n) => {
self.next_expect()?;
Ok(Value::Number(n))
}
Token::Bool(b) => {
self.next_expect()?;
Ok(Value::Bool(b))
}
Token::Null => {
self.next_expect()?;
Ok(Value::Null)
}
_ => {
return Err(ParserError::new(&format!(
"error: a token must start {{ or [ or string or number or bool or null {:?}",
token
)))
}
};
value
}
残りのparse_objectとparse_arrayの実装をしていきましょう。
JSON Objectのparse実装(parse_object)
parse_object関数はJSON Objectのパースを行います。
JSON Objectの基本的な構造は{ "key" : JSON Value }です。複数のkey-valueの場合は{ "key1" : JSON Value1 , "key2" : JSON Value2 }という構造です。
「JSONの"key"とkey-valueの区切り文字:を読み込み、parse関数を呼び出してJSON Valueを読み込む」処理を1つのセットだと考えます。1セットを読み込んだ直後のTokenがObjectの終端文字(})なら処理を打ち切り値を返します、key-valueの区切り文字(,)の場合は次の1セットを読み込みます。
parse_objectの処理は以下の通りです。
-
JSON Objectの開始文字であるToken::LeftBraceを読み捨てる -
Tokenを読み込みTokenがToken::RightBrace- 空のObjectを返す
- 2文字分の
Tokenを読み込む- 2つの
TokenがJSON Valueのkey(Token::String)とkey-valueの区切り文字(Token::Colon)-
parse関数を呼び出してJSON Valueを読み込む -
Tokenを読み込む-
TokenがObjectの終端文字(Token::RightBrace)- パースした結果を返す
-
TokenがJSON Valueの区切り文字(Token::Comma)- 先頭の処理(2文字分の
Tokenを読み込む)に戻る
- 先頭の処理(2文字分の
-
-
- 2つの
/// `Object`のパースを行う。
/// {
/// "key1": 12345,
/// "key2": 6789
/// }
fn parse_object(&mut self) -> Result<Value, ParserError> {
// 先頭は必ず {
let token = self.peek_expect()?;
if *token != Token::LeftBrace {
return Err(ParserError::new(&format!(
"error: JSON object must starts {{ {:?}",
token
)));
}
// { を読み飛ばす
self.next_expect()?;
let mut object = std::collections::BTreeMap::new();
// } なら空の`Object`を返す
if *self.peek_expect()? == Token::RightBrace {
// } を読み飛ばす
self.next_expect()?;
return Ok(Value::Object(object));
}
loop {
// 2文字分の`Token`を読み出す
let token1 = self.next_expect()?.clone();
let token2 = self.next_expect()?;
match (token1, token2) {
// token1とtoken2はそれぞれ"key"(`Token::String`)と:(`Token::Colon`)であることを想定してる
// e.g. "key" : 12345
// "key" (`Token::String`)
// : (`Token::Colon`)
(Token::String(key), Token::Colon) => {
// 残りの`Value`(12345)をパースする。
object.insert(key, self.parse()?);
}
// それ以外はエラー
_ => {
return Err(ParserError::new(
"error: a pair (key(string) and : token) token is expected",
));
}
}
// `Object`が終端かもしくは次の要素(key-value)があるか
let token3 = self.next_expect()?;
match token3 {
// } `Object`の終端だったら`object`を返す
Token::RightBrace => {
return Ok(Value::Object(object));
}
// , なら次の要素(key-value)のパースする
// {
// "key1": 12345,
// "key2": 6789
// }
Token::Comma => {
continue;
}
_ => {
return Err(ParserError::new(&format!(
"error: a {{ or , token is expected {:?}",
token3
)));
}
}
}
}
parse_object関数のテストコードです。
#[test]
fn test_parse_object() {
let json = r#"{"togatoga" : "monkey-json"}"#;
let value = Parser::new(Lexer::new(json).tokenize().unwrap())
.parse()
.unwrap();
let mut object = BTreeMap::new();
object.insert(
"togatoga".to_string(),
Value::String("monkey-json".to_string()),
);
assert_eq!(value, Value::Object(object));
let json = r#"
{
"key": {
"key": false
}
}
"#;
let value = Parser::new(Lexer::new(json).tokenize().unwrap())
.parse()
.unwrap();
let mut object = BTreeMap::new();
let mut nested_object = BTreeMap::new();
nested_object.insert("key".to_string(), Value::Bool(false));
object.insert("key".to_string(), Value::Object(nested_object));
assert_eq!(value, Value::Object(object));
}
JSON Arrayのparse実装(parse_array)
parse_array関数はJSON Arrayのパースを行います。
JSON Arrayの基本的な構造は[ JSON Value, JSON Value ]という構造です。,で区切られてるJSON Valueを読み込み続け、終了文字]を読み込んだら結果を返します。parse_objectと同様の処理を行います。
-
JSON Arrayの開始文字であるToken::LeftBracketを読み捨てる -
Tokenを読み込みToken::RightBracket- 空のArrayを返す
-
parse関数を呼び出してJSON Valueを読み込む-
Tokenを読み込む-
TokenがObjectの終端文字(Token::RightBracket)- パースした結果を返す
-
TokenがJSON Valueの区切り文字(Token::Comma)- 先頭の処理(
JSON Valueを読み込む)に戻る
- 先頭の処理(
-
-
/// `Array`のパースを行う。
/// [1, 2, 3, null, "string"]
fn parse_array(&mut self) -> Result<Value, ParserError> {
// 先頭は必ず [
let token = self.peek_expect()?;
if *token != Token::LeftBracket {
return Err(ParserError::new(&format!(
"error: JSON array must starts [ {:?}",
token
)));
}
// [ を読み飛ばす
self.next_expect()?;
let mut array = vec![];
let token = self.peek_expect()?;
// ] なら空配列を返す
if *token == Token::RightBracket {
// ] を読み飛ばす
self.next_expect()?;
return Ok(Value::Array(array));
}
loop {
// 残りの`Value`をパースする
let value = self.parse()?;
array.push(value);
// `Array`が終端もしくは次の要素(`Value`)があるかを確認
let token = self.next_expect()?;
match token {
// ] は`Array`の終端
Token::RightBracket => {
return Ok(Value::Array(array));
}
// , なら次の要素(`Value`)をパースする
Token::Comma => {
continue;
}
_ => {
return Err(ParserError::new(&format!(
"error: a [ or , token is expected {:?}",
token
)));
}
}
}
}
parse_array関数のテストコードです。
#[test]
fn test_parse_array() {
let json = r#"[null, 1, true, "monkey-json"]"#;
let value = Parser::new(Lexer::new(json).tokenize().unwrap())
.parse()
.unwrap();
let array = Value::Array(vec![
Value::Null,
Value::Number(1.0),
Value::Bool(true),
Value::String("monkey-json".to_string()),
]);
assert_eq!(value, array);
let json = r#"[["togatoga", 123]]"#;
let value = Parser::new(Lexer::new(json).tokenize().unwrap())
.parse()
.unwrap();
let array = Value::Array(vec![Value::Array(vec![
Value::String("togatoga".to_string()),
Value::Number(123.0),
])]);
assert_eq!(value, array);
}
以上でparse_arrayとparse_objectの実装が完了したので最後にparse関数のテストコードを追加しましょう。
#[test]
fn test_parse() {
let json = r#"{"key" : [1, "value"]}"#;
let value = Parser::new(Lexer::new(json).tokenize().unwrap())
.parse()
.unwrap();
let mut object = BTreeMap::new();
object.insert(
"key".to_string(),
Value::Array(vec![Value::Number(1.0), Value::String("value".to_string())]),
);
assert_eq!(value, Value::Object(object));
let json = r#"[{"key": "value"}]"#;
let value = Parser::new(Lexer::new(json).tokenize().unwrap())
.parse()
.unwrap();
let mut object = BTreeMap::new();
object.insert("key".to_string(), Value::String("value".to_string()));
let array = Value::Array(vec![Value::Object(object)]);
assert_eq!(value, array);
}
JSON Valueのparse関数の実装(parse:lib.rs)
ユーザーのエンドポイントであるparse関数を実装しましょう。
/// ユーザーのエンドポイント
/// 入力のJSON文字列から`Value`を返す
pub fn parse(input: &str) -> Result<Value, ParserError> {
match Lexer::new(input).tokenize() {
Ok(tokens) => Parser::new(tokens).parse(),
Err(e) => Err(ParserError::new(&e.msg)),
}
}
以上でJSONパーサーが完成しました。お疲れ様でした。最後にテストがすべて通るか確認しましょう。
% cargo test parser
Finished test [unoptimized + debuginfo] target(s) in 0.00s
Running unittests (target/debug/deps/monkey_json-cf488cbc24c6e4aa)
running 3 tests
test parser::test::test_parse_object ... ok
test parser::test::test_parse ... ok
test parser::test::test_parse_array ... ok
簡易JSON prettierなコマンドラインツールの実装(src/bin/mj.rs)
実装したJSONパーサーmonkey-jsonを使って、簡易JSON prettierなコマンドラインツールを作成しましょう。
use std::{
env,
fs::read_to_string,
io::{stdin, Read},
process::exit,
};
use monkey_json::Value;
fn usage() {
eprintln!("mj - command line JSON minimum prettier");
eprintln!("USAGE:");
eprintln!(" mj [OPTIONS...] [FILE] [OPTIONS...]");
eprintln!("ARGS:");
eprintln!(" <FILE> A JSON file");
eprintln!("OPTIONS:");
eprintln!(" -h,--help Print help information");
eprintln!(" -c,--color Color JSON output");
eprintln!(" -m,--minimize Minimize JSON output");
}
fn red(s: &str) -> String {
format!("\x1b[31m{}\x1b[m", s)
}
fn green(s: &str) -> String {
format!("\x1b[32m{}\x1b[m", s)
}
fn yellow(s: &str) -> String {
format!("\x1b[33m{}\x1b[m", s)
}
fn do_minimum_output(value: &Value, color: bool) {
match value {
Value::Number(v) => {
print!("{}", v);
}
Value::Bool(v) => {
print!("{}", v);
}
Value::String(s) => {
let s = if color { green(s) } else { s.to_string() };
print!("\"{}\"", s);
}
Value::Array(vs) => {
print!("[");
vs.iter().enumerate().for_each(|(i, v)| {
do_minimum_output(v, color);
if i != vs.len() - 1 {
print!(",");
}
});
print!("]");
}
Value::Object(vs) => {
print!("{{");
vs.iter().enumerate().for_each(|(i, (k, v))| {
let k = if color { yellow(k) } else { k.to_string() };
print!("\"{}\":", k);
do_minimum_output(v, color);
if i != vs.len() - 1 {
print!(",");
}
});
print!("}}");
}
Value::Null => {
let v = if color {
red("null")
} else {
"null".to_string()
};
print!("{}", v);
}
}
}
fn do_output(value: &Value, color: bool, indent: usize, special: bool) {
match value {
Value::Number(v) => {
print!("{}", v);
}
Value::Bool(v) => {
print!("{}", v)
}
Value::String(s) => {
let s = if color { green(s) } else { s.to_string() };
print!("\"{}\"", s);
}
Value::Array(vs) => {
if special {
println!("[");
} else {
println!("{:indent$}[", "", indent = indent);
}
vs.iter().enumerate().for_each(|(i, v)| {
print!("{:indent$}", "", indent = indent + 3);
match &v {
Value::Object(_) | Value::Array(_) => {
do_output(v, color, indent + 3, true);
}
_ => {
do_output(v, color, indent + 3, false);
}
};
if i != vs.len() - 1 {
println!(",");
} else {
println!();
}
});
print!("{:indent$}]", "", indent = indent);
}
Value::Object(vs) => {
if special {
println!("{{");
} else {
println!("{:indent$}{{", "", indent = indent);
}
vs.iter().enumerate().for_each(|(i, (k, v))| {
let k = if color { yellow(k) } else { k.to_string() };
print!("{:indent$}\"{}\": ", "", k, indent = indent + 3);
match &v {
Value::Object(_) | Value::Array(_) => {
do_output(v, color, indent + 3, true);
}
_ => {
do_output(v, color, indent + 3, false);
}
};
if i != vs.len() - 1 {
println!(",");
} else {
println!();
}
});
print!("{:indent$}}}", "", indent = indent);
}
Value::Null => {
let v = if color {
red("null")
} else {
"null".to_string()
};
print!("{}", v);
}
}
}
fn main() {
let (args, options): (Vec<String>, Vec<String>) = env::args()
.into_iter()
.skip(1)
.partition(|str| !str.starts_with('-'));
let mut color_output = false;
let mut minimize_output = false;
options
.into_iter()
.for_each(|option| match option.as_str() {
"-h" | "--help" => {
usage();
exit(0);
}
"-c" | "--color" => {
color_output = true;
}
"-m" | "--minimize" => {
minimize_output = true;
}
_ => {
eprintln!("error: an unrecognized option {}", option);
usage();
exit(1);
}
});
if args.len() > 1 {
eprintln!("error: the number of argument must be 0 or 1");
usage();
exit(1);
}
let input_json = if let Some(file_name) = args.first() {
read_to_string(file_name)
.ok()
.unwrap_or_else(|| panic!("error: can't open a file {}", file_name))
} else {
let mut buffer = String::new();
stdin()
.read_to_string(&mut buffer)
.expect("error: can't read a string from stdin");
buffer
};
let json_value = monkey_json::parse(&input_json).expect("error: failed to parse json");
if minimize_output {
do_minimum_output(&json_value, color_output);
} else {
do_output(&json_value, color_output, 0, false);
}
}
以上でmjが完成しました。色々なJSONを使って遊んでみてください。
% cargo run --bin mj -- --help
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/mj --help`
mj - command line JSON minimum prettier
USAGE:
mj [OPTIONS...] [FILE] [OPTIONS...]
ARGS:
<FILE> A JSON file
OPTIONS:
-h,--help Print help information
-c,--color Color JSON output
-m,--minimize Minimize JSON output
[main][togatoga] ~/src/github.com/togatoga/monkey-json
% cat example.json
{
"boolean": true,
"null": null,
"number":
123,
"object":
{
"array": [null,
2e10]
},
"string": "togatoga",
"utf16": "\uD83D\uDE04\uD83D\uDE07\uD83D\uDC7A"
}
[main][togatoga] ~/src/github.com/togatoga/monkey-json
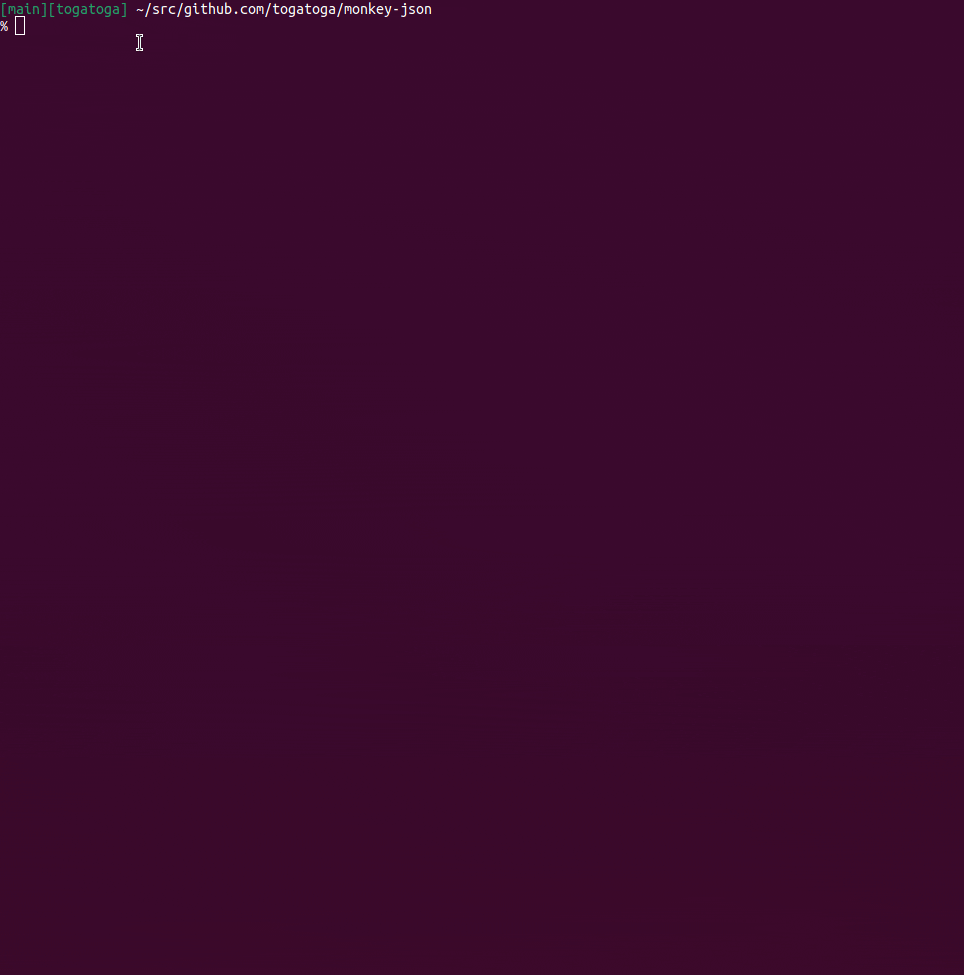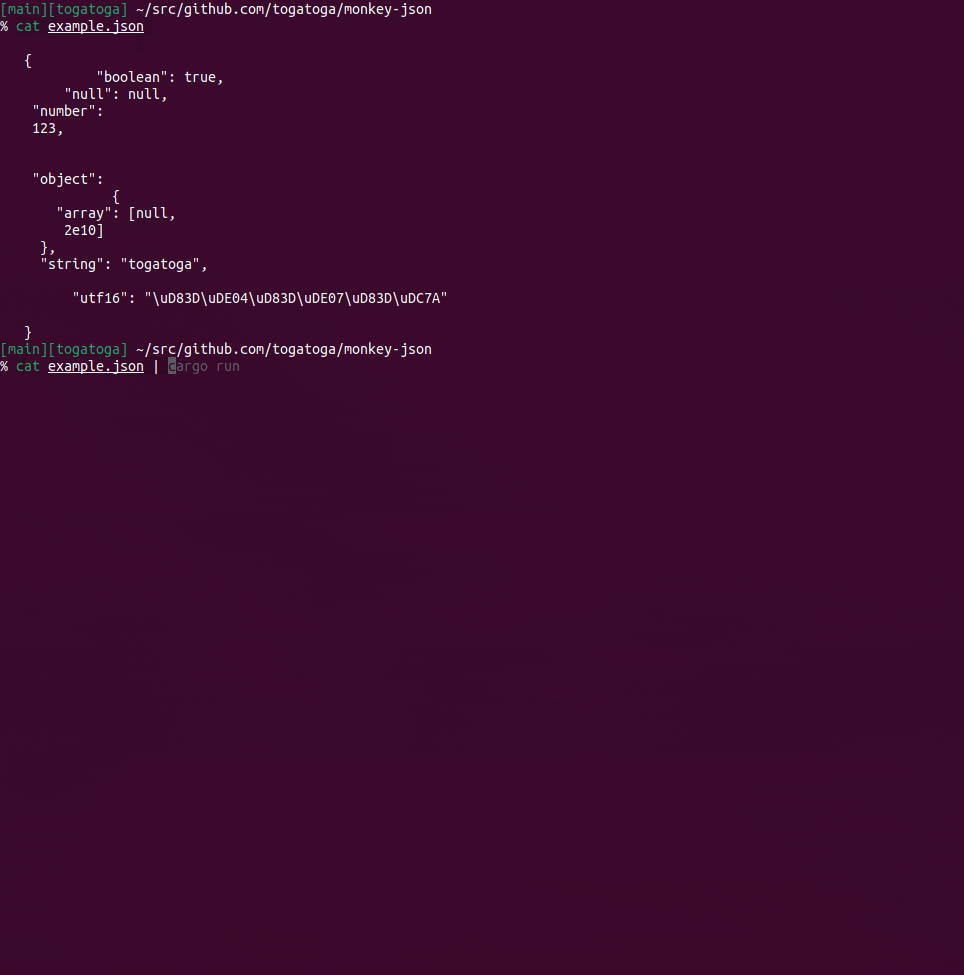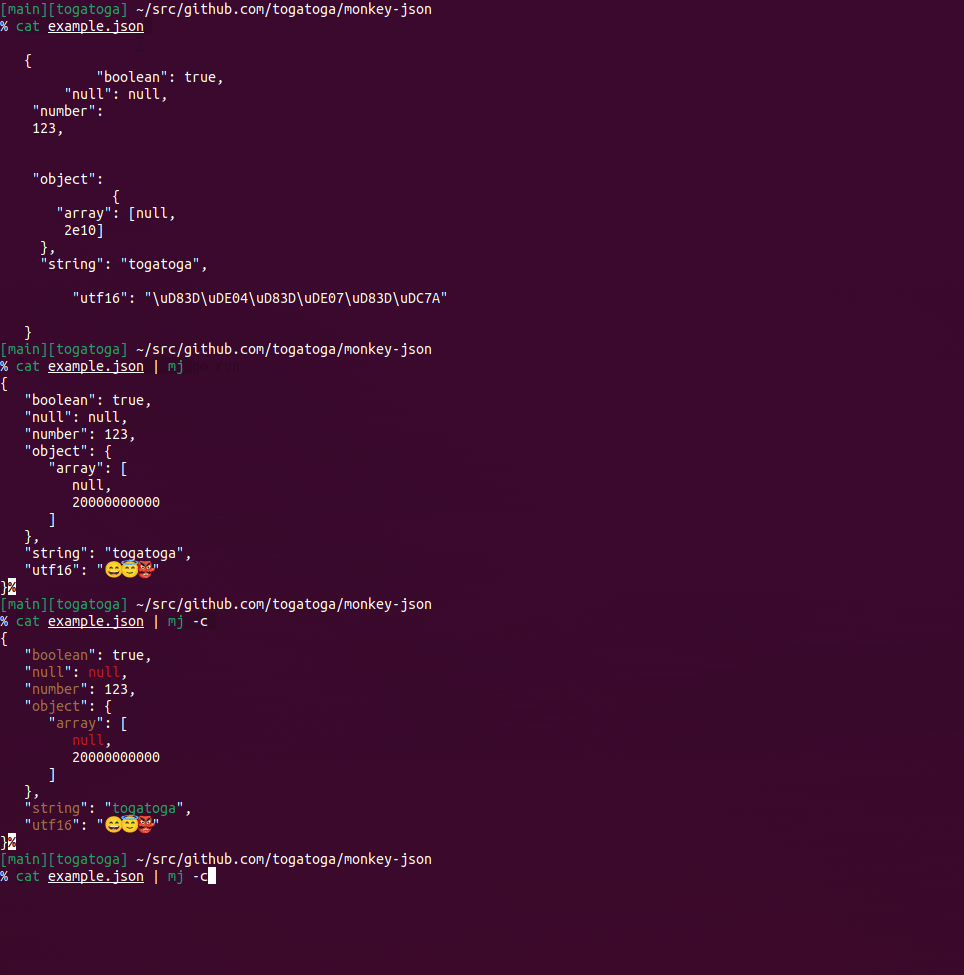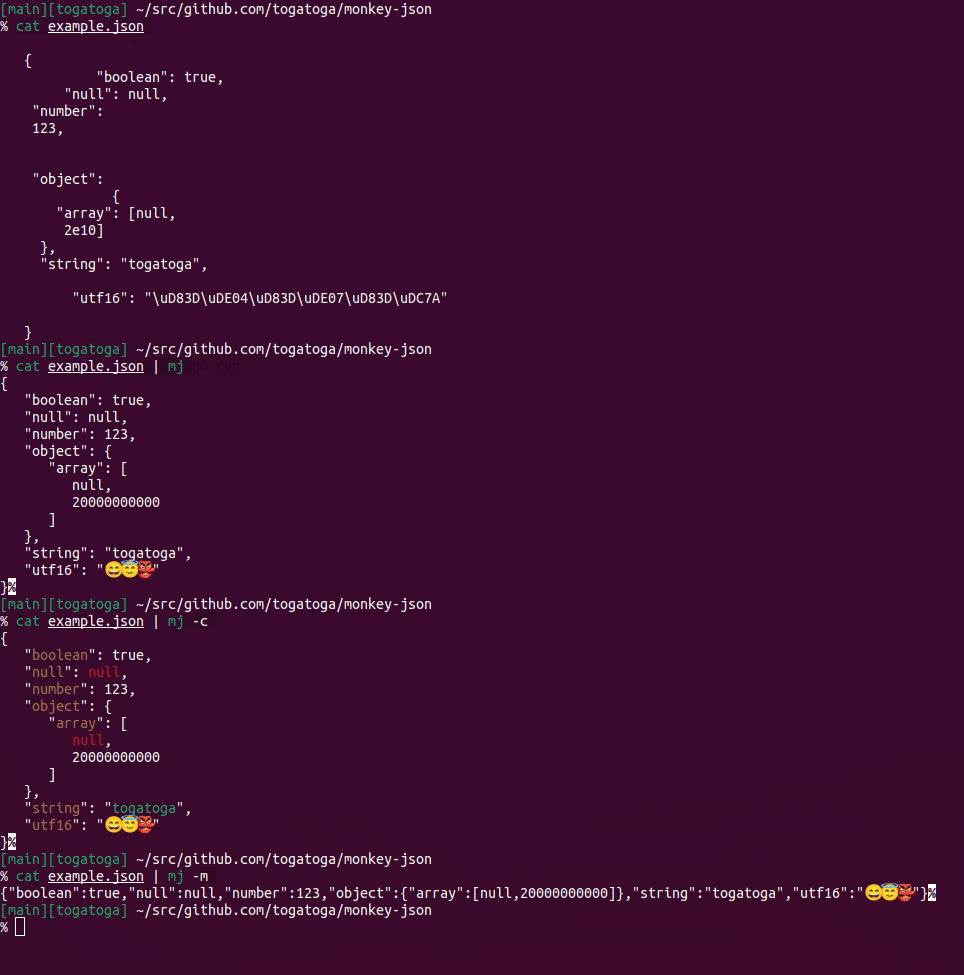
% cat example.json | cargo run --bin mj
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/mj`
{
"boolean": true,
"null": null,
"number": 123,
"object": {
"array": [
null,
20000000000
]
},
"string": "togatoga",
"utf16": "😄😇👺"
}%
おわりに
本記事ではフルスクラッチでJSONパーサーと簡易JSON prettierなコマンドラインツールを作成しました。
monkey-jsonの実装はerrorハンドリングが甘かったり、実装が愚直だったり、テストが少なかったり、様々な課題があります。ぜひ改良に挑戦してみてください。
(例えば、keyをBTreeMapで格納してるため、入力のJSONのkeyの順序と出力するkeyの順序が必ずしも一致しません。これはユーザーの直感に反します。デモはそれっぽく動かすためにJSONを弄ってます)
この記事がよかったらLGTMやmonkey-jsonにスターを頂ければ励みになります。
参考文献・実装
- RFC8259
-
tinyjson
Rustで書かれた綺麗なJSONパーサー実装。stringとutf16のparse実装を参考にしました。 -
sqlparser-rs
SQLのパーサー実装。コードの設計やparse処理を参考にしました。