はじめに — 何を作ったのか
「MCPサーバーを自作して、GitHub Copilotのチャット欄からナレッジグラフを読み書きできる仕組み」を作りました。
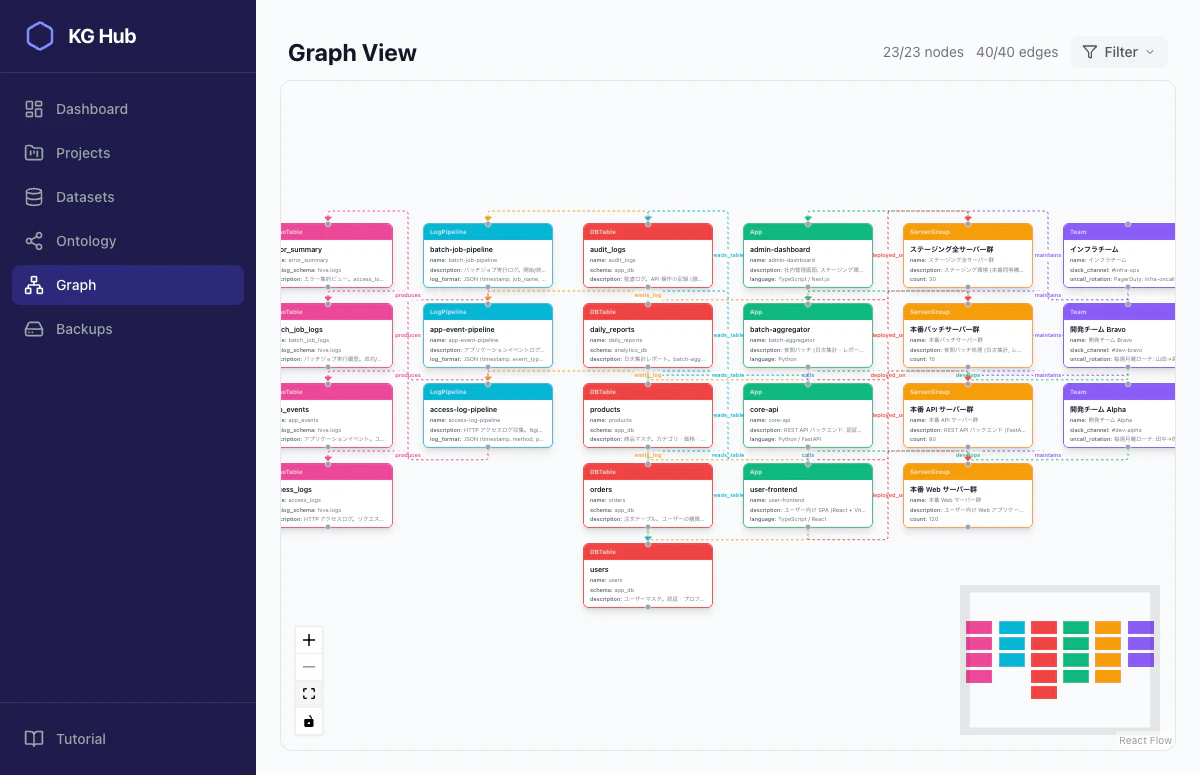
プロジェクト名は KG Hub (Knowledge Graph Hub)。ノードの型とリンクの型を定義してデータを構造化するナレッジグラフプラットフォームです。Web UIでグラフを可視化できますが、本命は MCPサーバー経由でCopilotから直接操作できるインタフェース の方です。
技術スタックはこんな感じです。
| レイヤー | 技術 |
|---|---|
| フロントエンド | React 18 / TypeScript / Vite / TailwindCSS |
| バックエンド | Python / FastAPI / SQLAlchemy 2.0 (async) |
| データベース | PostgreSQL 16 |
| グラフ描画 | React Flow |
| MCP | mcp SDK (Python) — SSE トランスポート |
リポジトリ: https://github.com/cacapouh/knowledge-graph-hub
課題 — なぜ作ったのか
アプリやサーバーの依存関係、すぐに答えられますか?
- 「このアプリどのDB読んでる?」「ログどこ行ってる?」 — 調べようにも、まずgitリポジトリを探索したり、その結果をSlackで聞いたりで、毎回それなりの時間が溶ける。
- サーバーの所在が不明になる問題 — 開発チームがサービスイン / サービスアウトの状態に自信が持てず、サーバーを管理しているチームや関係者に毎回確認する。Slackが飛んで → 返事を待って → 作業再開、で時間ロス。
- 「誰に聞けばいい?」 — 調査業務が発生したとき、そのサーバーを管理しているチームがわからない。gitリポジトリや仕様書を特定したりして、場合によっては仕様書が古くて結局聞き回る羽目になる。
じゃあConfluenceに書けばいいじゃん、という話なんですが、書いた瞬間から腐り始めるんですよね。ドキュメントは「書く場所」と「使う場所」が離れているから、更新されない。
サーバーやアプリの数が増えてくると、この手の「聞かないとわからない情報」がどんどん膨らんでいきます。
これはインフラに限った話ではなくて、組織のナレッジが人の頭やバラバラのドキュメントに散在している — いわゆる データのサイロ化 の一例です。AIを活用して業務を効率化しようにも、そもそもナレッジが構造化されていなければAIに渡しようがない。この課題をどうにかしたくて作り始めました。
アプローチ — なぜナレッジグラフ+MCPか
ドキュメントが腐る根本原因は 「書く場所」と「使う場所」が離れていること です。じゃあ、エンジニアが一番長く滞在する場所にナレッジへの入口を作ればいいのでは?
エンジニアが一番長くいる場所 — それはエディタです。
MCPを使えば、Copilotのチャット欄がそのままUIになります。専用画面を開く必要がない。「ついでにグラフも更新しておくか」が自然に起きる導線を作れる。
Web UIはあくまで可視化・全体把握用。日常的なデータの読み書きはMCP経由が本命です。
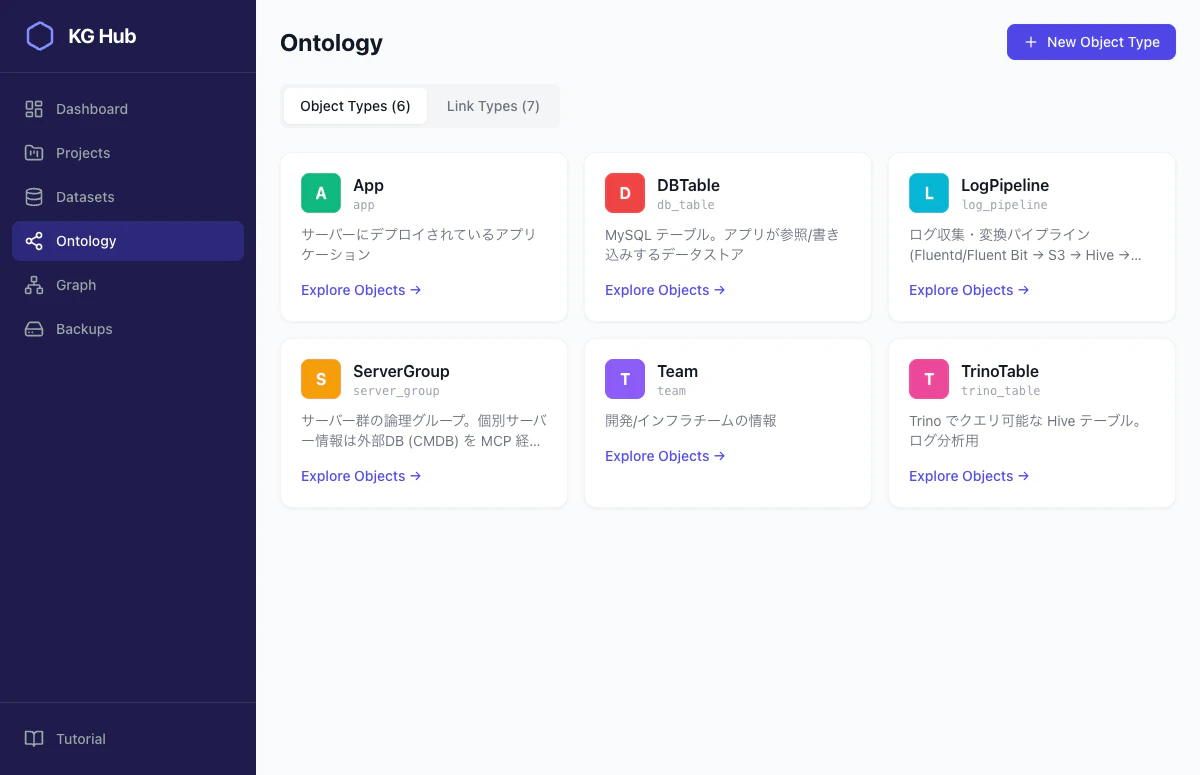
グラフの型定義 — チュートリアルシナリオで説明
やっていることは 「どんな種類のノードがあって、どんなリンクで繋がるか」を定義するだけ です。
チュートリアルシナリオとして「サーバー管理ナレッジグラフ」を用意しました。seed_tutorial.py でデータを投入すると、こんなグラフができます。
グラフの構造はこうなっています。
Team ──maintains──▶ ServerGroup
│ ▲
│develops deployed_on
▼ │
App ───calls───▶ App
│ │
│reads_table │emits_log
▼ ▼
DBTable LogPipeline ──produces──▶ TrinoTable
この程度の型定義だけで、かなりの暗黙知が構造化できます。
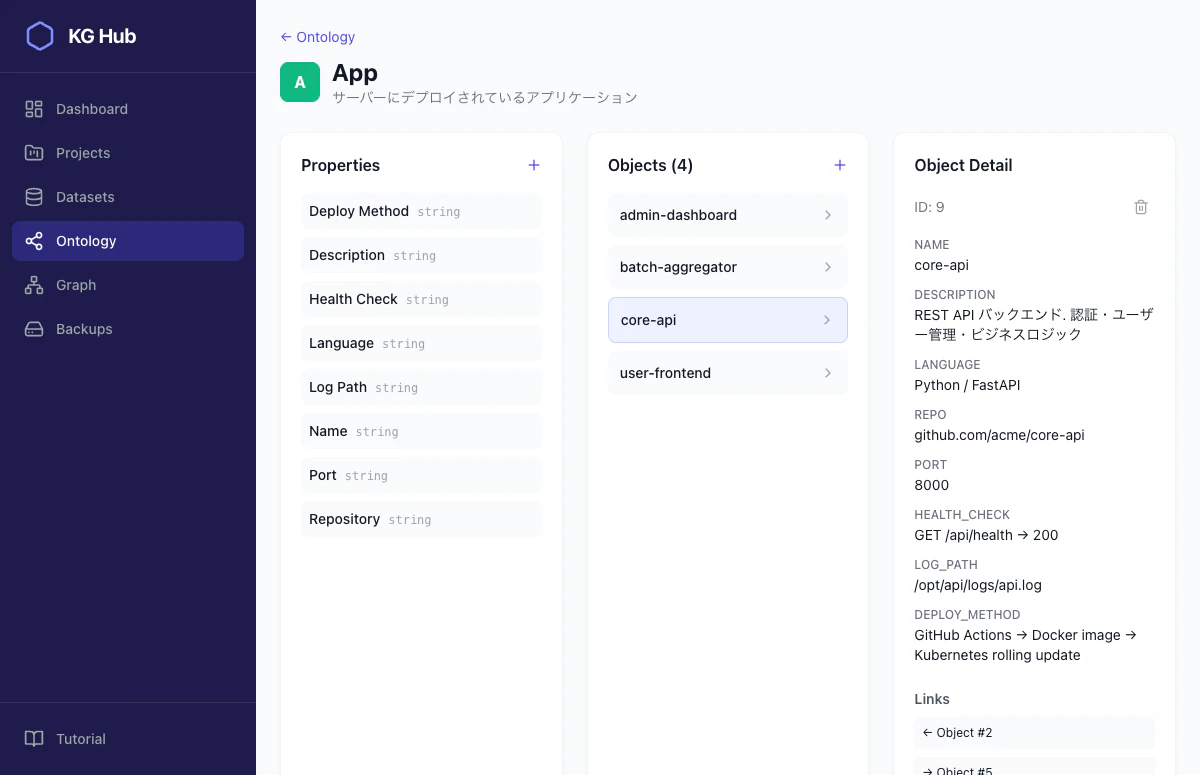
ObjectType の例: App
app_type = post("/ontology/object-types", {
"name": "App",
"api_name": "app",
"project_id": pid,
"description": "サーバーにデプロイされているアプリケーション",
"color": "#10b981",
"title_property": "name",
})
プロパティとして name, description, language, repo, port, health_check, log_path, deploy_method を定義しています。アプリの基本情報がこれで構造化される。
LinkType の例: reads_table (App → DBTable)
lt_reads = post("/ontology/link-types", {
"name": "reads_table",
"api_name": "app_reads_table",
"project_id": pid,
"source_object_type_id": a_tid,
"target_object_type_id": db_tid,
"cardinality": "many_to_many",
"description": "アプリが参照/書き込みする MySQL テーブル",
"inverse_name": "used_by",
})
inverse_name に "used_by" を指定しておくと、逆方向の探索(「このテーブルを使っているアプリは?」)にも名前が付きます。「このアプリはどのDBテーブルを読んでるの?」がリンクを辿るだけで一発でわかるようになります。
ログ分析パスの設計
特に工夫したのがログ分析パスです。App → emits_log → LogPipeline → produces → TrinoTable というパスを辿ると、「このアプリのログは最終的にどのTrinoテーブルに届くのか」がわかります。
lt_emits = post("/ontology/link-types", {
"name": "emits_log",
"api_name": "app_emits_log",
"project_id": pid,
"source_object_type_id": a_tid,
"target_object_type_id": lp_tid,
"cardinality": "many_to_many",
"description": "アプリがログを出力するパイプライン",
"inverse_name": "collects_from",
})
lt_produces = post("/ontology/link-types", {
"name": "produces",
"api_name": "pipeline_produces_table",
"project_id": pid,
"source_object_type_id": lp_tid,
"target_object_type_id": tt_tid,
"cardinality": "one_to_many",
"description": "パイプラインが生成する Trino クエリ可能テーブル",
"inverse_name": "produced_by",
})
各TrinoTableの mcp_hint プロパティにはサンプルクエリも入れてあります。
{
"name": "access_logs",
"catalog_schema": "hive.logs",
"description": "HTTP アクセスログ。リクエスト単位のレイテンシ・ステータスコード・ユーザー分析",
"mcp_hint": "Trino MCP → trino.internal:8443\n"
"SELECT app_name, status,\n"
" COUNT(*) AS cnt,\n"
" AVG(latency_ms) AS avg_latency,\n"
" APPROX_PERCENTILE(latency_ms, 0.99) AS p99_latency\n"
" FROM hive.logs.access_logs\n"
" WHERE dt >= CURRENT_DATE - INTERVAL '7' DAY\n"
" AND app_name = '<アプリ名>'\n"
" GROUP BY app_name, status\n"
" ORDER BY cnt DESC;",
}
Copilotがリンクを辿ってこの mcp_hint に到達すると、そのままTrinoクエリのサンプルを回答に含めてくれます。
MCP実装 — コード抜粋+解説
MCPサーバーの実装は mcp_server.py 1ファイル です。やっていることは「httpxでバックエンドAPIを叩くだけ」のシンプルな構成。
MCPサーバーの初期化
import os
import httpx
from mcp.server.fastmcp import FastMCP
API_BASE = os.environ.get("API_BASE", "http://127.0.0.1:8000/api")
FRONTEND_BASE = os.environ.get("FRONTEND_BASE", "http://localhost:5173")
MCP_HOST = os.environ.get("MCP_HOST", "127.0.0.1")
MCP_PORT = int(os.environ.get("MCP_PORT", "8002"))
mcp = FastMCP(
"KG Hub",
instructions=(
"Knowledge Graph Hub の MCP サーバーです。"
"社内インフラのナレッジグラフ (Team, ServerGroup, App, DBTable, "
"LogPipeline, TrinoTable など) を閲覧・編集できます。"
),
host=MCP_HOST,
port=MCP_PORT,
)
def _client() -> httpx.Client:
return httpx.Client(base_url=API_BASE, timeout=30)
def _graph_url(highlight_id: int | None = None) -> str:
"""Graph View のプレビュー URL を生成する。"""
if highlight_id is not None:
return f"{FRONTEND_BASE}/graph?highlight={highlight_id}"
return f"{FRONTEND_BASE}/graph"
FastMCP に instructions を渡しておくと、CopilotがMCPサーバーの概要を把握してくれます。SSEトランスポートで動作するので、Docker Composeでサーバーを起動しておけばVS Codeから接続できます。
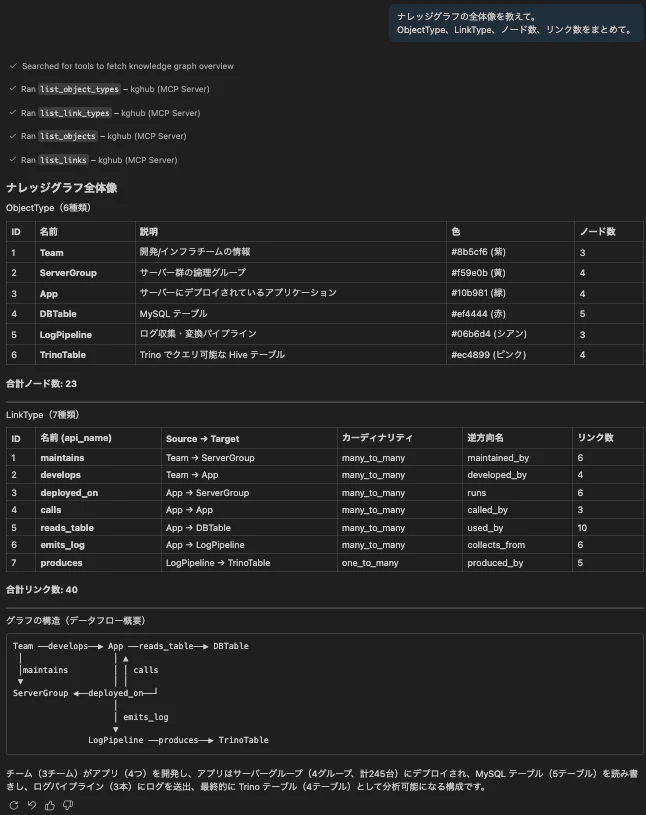
search_graph ツール — 全体像把握の入口
グラフ全体のサマリーを返すツールです。「ナレッジグラフの全体像を教えて」と聞くとこれが呼ばれます。
@mcp.tool()
def search_graph() -> str:
"""グラフ全体のサマリーを取得する。全 ObjectType、LinkType、ノード数、リンク数を返す。"""
with _client() as c:
ot_resp = c.get("/ontology/object-types")
ot_resp.raise_for_status()
object_types = ot_resp.json()
lt_resp = c.get("/ontology/link-types")
lt_resp.raise_for_status()
link_types = lt_resp.json()
obj_resp = c.get("/ontology/objects", params={"limit": 500})
obj_resp.raise_for_status()
objects = obj_resp.json()
link_resp = c.get("/ontology/links", params={"limit": 1000})
link_resp.raise_for_status()
links = link_resp.json()
lines = [f"=== Knowledge Graph Summary ==="]
lines.append(f"Total ObjectTypes: {len(object_types)}")
for ot in object_types:
count = sum(1 for o in objects if o["object_type_id"] == ot["id"])
lines.append(f" - {ot['name']} (id={ot['id']}, color={ot['color']}, instances={count})")
lines.append(f"\nTotal LinkTypes: {len(link_types)}")
for lt in link_types:
count = sum(1 for l in links if l["link_type_id"] == lt["id"])
lines.append(f" - {lt['name']} (id={lt['id']}, {lt['source_object_type_id']}→{lt['target_object_type_id']}, links={count})")
lines.append(f"\nTotal Nodes: {len(objects)}")
lines.append(f"Total Links: {len(links)}")
return "\n".join(lines)
4つのAPIを叩いてテキストに整形しているだけですが、Copilotはこの返り値を要約して「6種類のObjectTypeに23ノード、7種類のLinkTypeで39本のリンクがあります」みたいに返してくれます。
他のツールも基本的に同じパターンで、引数を受け取って httpx でAPIを叩いて結果を返すだけです。ちょっとした工夫として、書き込み系ツール(create_object / create_link など)のレスポンスには Graph View の URL を含めている ので、Copilotの回答からワンクリックでグラフ上の該当ノードを確認できます。
18ツールの一覧
| カテゴリ | ツール | 説明 |
|---|---|---|
| Object Types | list_object_types |
ObjectType 一覧取得 |
get_object_type |
ObjectType 詳細取得 | |
create_object_type |
ObjectType 新規作成 | |
update_object_type |
ObjectType 更新 | |
delete_object_type |
ObjectType 削除 | |
| Property Types | list_properties |
PropertyType 一覧取得 |
create_property |
PropertyType 新規作成 | |
| Object Instances | list_objects |
ObjectInstance 一覧取得 |
get_object |
ObjectInstance 詳細取得 | |
create_object |
ObjectInstance 新規作成 | |
update_object |
ObjectInstance プロパティ更新 | |
delete_object |
ObjectInstance 削除 | |
| Link Types | list_link_types |
LinkType 一覧取得 |
create_link_type |
LinkType 新規作成 | |
| Link Instances | list_links |
LinkInstance 一覧取得 |
create_link |
LinkInstance 新規作成 | |
delete_link |
LinkInstance 削除 | |
| Graph | search_graph |
グラフ全体サマリー |
全ツールが httpx でバックエンドAPIを叩くだけのシンプルな構成です。特別なことは何もしていません。
VS Code の設定
.vscode/mcp.json に以下を追記するだけで使えます。Docker Compose で MCPサーバーが http://localhost:8002 で起動するので、SSE タイプで接続先を指定します。
{
"servers": {
"kghub": {
"type": "sse",
"url": "http://127.0.0.1:8002/sse"
}
}
}
使ってみた — Copilotとの対話例
シナリオA: 全体像の把握
ナレッジグラフの全体像を教えて。
ObjectType、LinkType、ノード数、リンク数をまとめて。
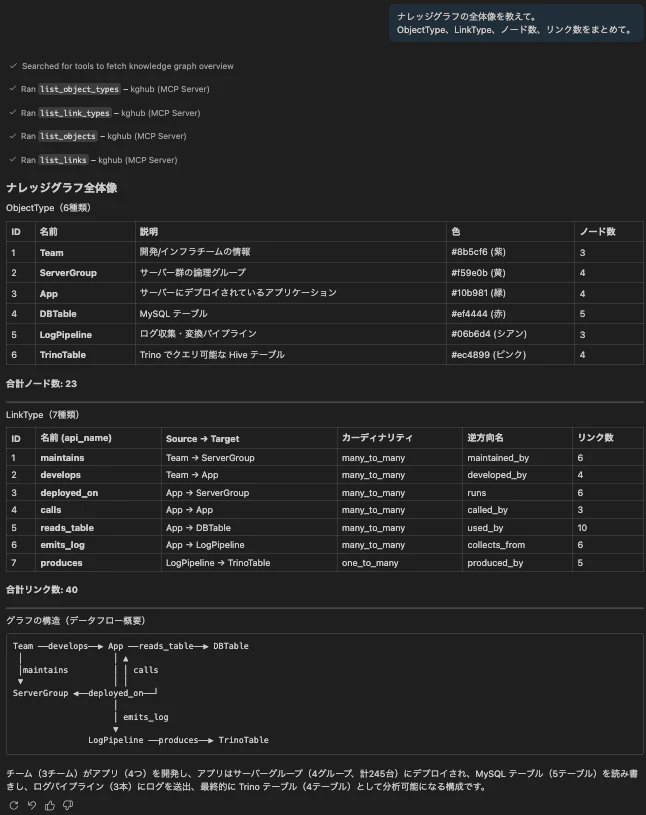
Copilotが search_graph() を呼んで、6つのObjectType (Team, ServerGroup, App, DBTable, LogPipeline, TrinoTable) に23ノード、7つのLinkTypeで39本のリンクがある、という全体像をまとめてくれます。
シナリオB: ログ分析パスの探索
payment-api のログはどこに流れてる?
emits_log と produces のリンクを辿って、最終的にどの Trino テーブルに届くか教えて。
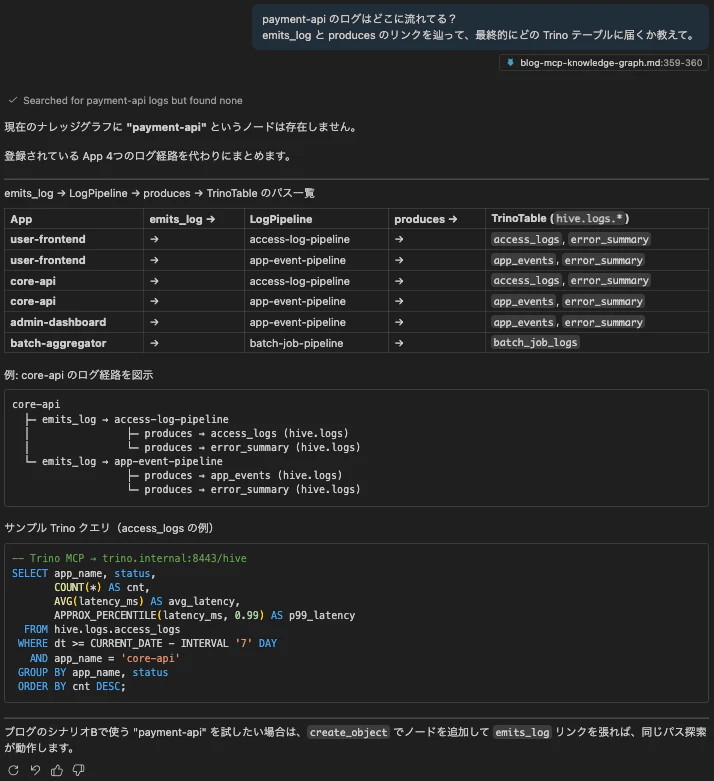
Copilotが list_links + list_objects を組み合わせて emits_log → LogPipeline → produces → TrinoTable のパスを辿ります。最終的に hive.logs.access_logs や hive.logs.app_events に届くことを教えてくれて、各テーブルの mcp_hint に入っているサンプルTrinoクエリまで表示してくれるのが便利です。
シナリオC: 依存関係の調査
order-db テーブルを読んでいるアプリの一覧と、
それぞれのアプリがデプロイされているサーバーグループを教えて。
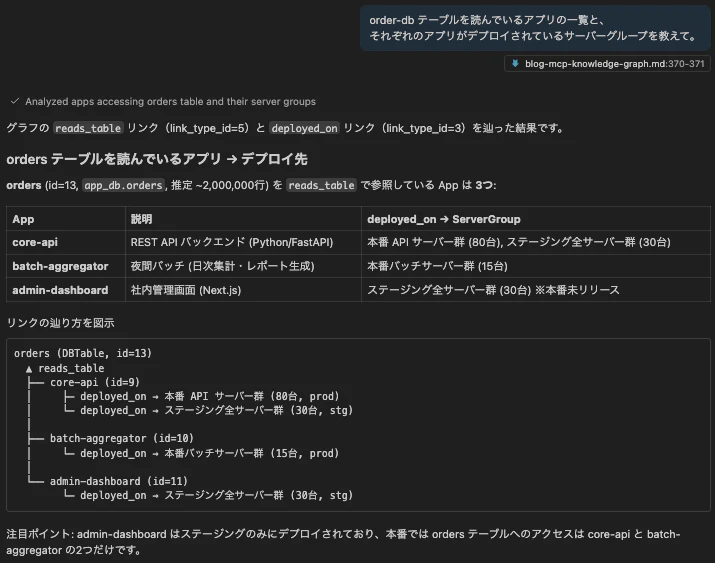
reads_table リンクの逆引きで orders テーブルに繋がっているアプリ (core-api, batch-aggregator, admin-dashboard) を見つけ、さらに deployed_on リンクでそれぞれのサーバーグループまで辿ってくれます。これは従来のスプレッドシートやCMDBでは一発で引くのが困難だった横断クエリです。
シナリオD: ノードの追加
新しいAppノードを追加して。
名前は "notification-service"、言語は Go、
チームは Platform Team が開発、web-server-group にデプロイされている設定で。
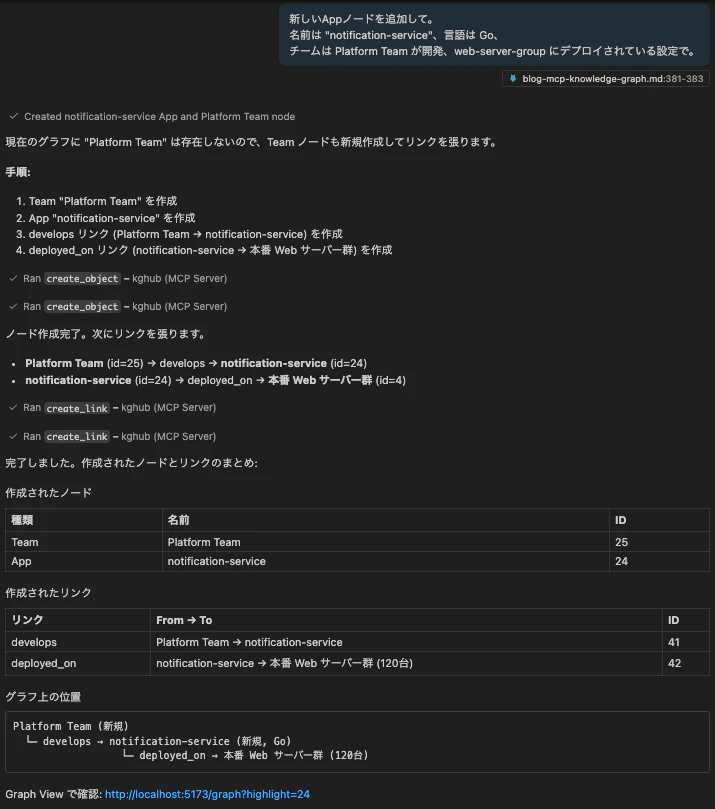
Copilotが create_object でノードを作り、create_link でリンクも張ってくれます。レスポンスにGraph ViewのURLが含まれるので、ワンクリックで作成したノードを確認できます。
まとめ — 今後やりたいこと
「とりあえず動くもの」を作って手触りを確かめてみました。MCPをインタフェースにすることで、Copilotのチャット欄がそのままナレッジグラフのクライアントになる、という体験は思ったよりいい感じです。
正直、Web UIを開いてポチポチする体験より、Copilotに雑に聞いてリンクを辿ってもらう方がずっと楽。「ドキュメントを書く」から「グラフを育てる」へ 、というパラダイムシフトのきっかけになるかもしれません。
今後やりたいこと
- 実務で使えるか検証したい。 今はチュートリアルデータでの検証段階。実データを入れたときに何が起きるかが一番知りたい
-
Trino連携: TrinoTableの
mcp_hintにサンプルクエリを入れてあるが、実際にMCP経由でTrinoクエリを実行できるようにしたい -
CMDB参照: ServerGroupの
mcp_hintに外部DBへの接続情報を持たせているので、MCP経由でCMDBに直接クエリを投げる仕組みを作りたい - パイプラインによる自動同期: Ansible/Terraformの出力からServerオブジェクトを自動更新。SIN/SOUTの変更も自動反映されて、グラフが常に最新になる世界
リポジトリは公開しているので、興味がある方は触ってみてください。以下のコマンドで起動できます。
# 全サービス起動 (backend, frontend, mcp, postgres, redis, minio)
docker compose up -d --build
# チュートリアルデータ投入
python seed_tutorial.py
# アクセス先
# Frontend: http://localhost:5173
# Backend: http://localhost:8000
# MCP (SSE): http://localhost:8002/sse