Serverless Days Tokyo 2019 の Zero Scale Abstraction in Knative Serving というセッションの内容を書き起こしたものです。スピーカーノートをベースに、セッションの時間内で話せなかった内容も含めて、Knative Serving についてまとめています。思った以上に長くなってしまったので、2つの記事に分割します。
いくつかリンクを貼っていますが、Google Slide や Docs は knative-users@ への参加が必要です。
Table of contents
- Knative プロジェクトとは (Part1)
- Knative Serving
- 紹介と簡単なデモ (Part1)
- ゼロスケールの仕組み (Part1)
- 優れた点
- 制約と課題
- Knative Serving の本番導入に向けて
- Why Knative?
- High-level architecture walkthrough
- gRPC load balancing
- Strategy for upgrading EKS cluster
- Event driven system
- Resource requests and limits
Introduction
Knative プロジェクトの大枠を紹介します。

Knative は Kubernetes 固有のプラットフォームで、モダンな Serverless アプリケーションをビルド、デプロイ、管理します。Knative の名前の由来は Kubernetes native platform から来ています。Knative は次の 3 つの主要なプロジェクトを中心に構成されています。
-
- HTTP リクエスト駆動でゼロスケール可能なコンテナベースのアプリケーションを管理します。
-
- イベント駆動でアプリケーションを動作させるための機構です。
- Eventing で取り扱われるイベントは HTTP リクエストベースのものが多く、GitHub の webhook や
- Kubernetes のイベントから AWS SQS や Cloud Pub/Sub、Kafka など多様です。

“Kubernetes はクラウドの世界の Linux になるだろう”と Linux Foundation の Jim Zemlin が発言しています。K8S を中心に CaaS (≒ IaaS) / PaaS / FaaS をマッピングしてみました。
諸説あるのであくまで個人の見解ですが、Knative 自体は PaaS よりの基盤に見えます。Knative の上に独自の Runtime を構築することで、FaaS の機能を提供することができます。そういう意味では、Cloud Foundry の Eirini プロジェクト (Kubernetes クラスター上で Cloud Foundry Application Runtime を管理) が最も近い存在かもしれません。
余談ですが、フルマネージドな Cloud Run は、オープンソースとして公開されている Knative を使って構築されている訳ではありません。Knative Serving の API に準拠しつつ、Google のインフラ (gVisor on Borg) に合わせて内部の実装が異なっています。ただ、Cloud Run for Anthos (Cloud Run on GKE) では、オープンソースとして公開している Knative と Istio を GKE クラスター上にデプロイすることになります。Cloud Run (fully managed) と Cloud Run for Anthos に関する詳細な情報は、公式ドキュメントを確認して下さい。

Knative の目指すべきゴールは、Cloud Foundry や Heroku と同じに見えます。

Knative — Kubernetes-native PaaS with Serverless の引用ですが、Knative プロジェクトが提供する機能はこれまでの PaaS が提供してきた機能に近いものばかりです。それらを可能な限り疎結合なコンポーネントとして提供することで、サービスプロバイダが柔軟にそれらのコンポーネントを組み立てて、自分だけのプラットフォームを構築できるようにしています。
Knative が目指している世界も PaaS がかつて目指した世界と同じで、アプリケーションのソースコードの場所を指定すれば、サービスが公開できる未来です。アプリ開発者がより自身のアプリケーションの開発に注力できるようになります。

Knative serverless Kubernetes bypasses FaaS to revive PaaS からの引用ですが、Knative の強みは Kubernetes というコンテナオーケストレーション基盤の上に構築したことです。Kubernetes の Primitive なコンポーネントを Custom Resource Definition を用いて拡張することで、Kubernetes のネイティブなプラットフォームに仕立てています。Knative を利用しても、Kubernetes の Primitive なリソースが使えなくなる訳ではありません。自身のワークロードに併せて、Knative の抽象化されたリソースを使う部分と、Kubernetes のリソースを使う部分を分けることができます。例えば、ステートフルなアプリケーションをデプロイしたい場合は、単純に Kubernetes の StatefulSet を利用すれば良いのです。

What Exactly Is Knative? からの引用ですが、CloudFoundry のメンバーも Knative プロジェクトの開発に関わっています。

Knative は、Kubernetes をより実用的に抽象化したプラットフォームです。Kubernetes を利用する上でのベストプラクティスを盛り込みつつ抽象化を試みています。Knative Serving のリードである Matt Moore のツイートにも書いてあるように、多くのユーザーがハマりがちな問題を単純化することも Knative プロジェクトの重要な要素になっています。ただ、抽象化している分、型にはまって、柔軟性の欠ける部分はあります。
Knative は様々なプラットフォームを構築するための部品の集まりです。デフォルトの Knative way に削ぐわない場合は、自身の用途に合わせてコントローラを自作すれば良いのです。私のような小さな組織の人間がコントローラを自作/管理していくのは骨が折れます。ですので、Knative way が全員ではないが大多数のベストプラクティス集として成長していくことを願いつつ、Knative への貢献を始めました。

Knative は Google 主体で様々なベンダーと協力して開発が進められています。Kubernetes の PodAutoscaler (sig/autoscaling) や既存の FaaS (OpenWisk, Kubeless) の開発メンバー、CNCF の Sandbox プロジェクト入りした CloudEvent のメンバーなど多方面から参加しています。開発も活発に行われており、6ヶ月サイクルで新バージョンがリリースされています。

それぞれのベンダーが Knative をベースに Serverless プラットフォームを提供しています。そして、ユーザーに利用してもらい、そのフィードバックを Knative に還元する形で開発を進めています。
また、プラットフォームの中には Knative の機能をフル活用しているものもあれば、Knative の一部の機能のみを利用している場合もあります。例えば、Rancher Rio は Knative Serving のオートスケーリングの機能だけを切り出して利用しています。このように Knative の特徴として各コンポーネントの疎結合性が挙げられます。必要なコンポーネントを好きに組み合わせて Serverless プラットフォームを作ることができます。
本セッションでは、Knative Serving を取り上げます。
Knative Serving

Knative Serving は Kubernetes 上に構築した Serverless プラットフォームです。
ステートレスなアプリケーションを対象に、HTTP イベント駆動で自動スケールする仕組みを提供します。
Before talking about Knative Serving...

本題に入る前に、軽く Kubernetes について触れておきます。
Kubernetes は、コンテナオーケストレーションプラットフォームのデファクトスタンダードで、様々な機能を提供します。
本日のセッションでは、kube-proxy という Kubernetes のコンポーネントが出てきます。サービスディスカバリの処理を行なっているコンポーネントの一つです。Kubernetes 内部でのみ利用可能な VIP に対するリクエストは、kube-proxy に一旦送られ、Netfilter のルールと照合します。(この処理は、ルールの数を N として、O(N) の処理になります。) そして、転送先のバックエンドをランダムに決定します。(statistic mode random probability)

本セッションに登場する Kubernetes の主要なリソースは次の 3 つです。
- Pod は、アプリケーションをホストするための最小単位のリソースです。複数のコンテナを含めることができ、ひとつの PodIP とポート空間を共有します。
- Deployment は、複数の Pod のライフサイクルを抽象化して管理します。Pod は時間とともに変動する短寿命なリソースなので、Deployment で自己回復できる仕組みを提供しています。アプリケーション開発者が触るリソースになります。
- Service は、ネットワーク関連のリソースです。クラスター内部でのみ使える VIP の提供やサービスディスカバリ、L4 レイヤーでの負荷分散など、アプリケーションをクラスター内外に公開する際に利用されます。

Kubernetes でサービスを外部に公開しようと思うと、多くのリソースを定義する必要があります。
-
VirtualService
- L7 レイヤーの機能を提供する Istio のリソースです。
- サービスに対するリクエストを制御するためのリソースです。
- トラフィック分割や Circuit Breking などの設定を行うことができます。
-
Horizontal Pod Autoscaler
- Pod がリソースの使用量によって自動的にスケールアウト/インするためのポリシーを定義します。
これとは別に ConfigMap や Secret などのアプリケーション設定に関するリソース、ServiceAccount や Role などセキュリティ関連のリソースも定義する必要があります。

先ほどのマニフェストは、次の Knative Service リソースの定義とほぼ等価です。一部異なる部分は、Horizontal Pod Autoscaler (HPA) がリソース消費量でスケールするのに対して、Knative Pod Autoscaler (KPA, Knative の独自リソース) は、リクエストの処理数でスケールします。KPA はデフォルトだと、Pod の同時処理数が 70 リクエストを越えるとスケールします。(container-concurrency-target-default x container-concurrency-target-percentage = 100 x 0.7 = 70) 前者は Knative Service 単位で指定が可能です。詳細は、Configuring the Autoscaler を確認して下さい。
また、spec.template.metadata.annotations で Pod のスケールに関する設定を行なっています。上から最小スケール数と最大スケール数を指定しています。
Demo#1 Hello Knative!

helloworld アプリをデプロイして Knative のイメージを掴みましょう。EKS クラスターに Istio と Knative をインストールしています。

helloworld アプリをデプロイして、作成されたリソースを確認してみます。
-
kn コマンドを使って、helloworld アプリをデプロイします。
- イメージと Revision の名前を指定しています。Revision は、アプリケーションのコードと設定の不変のスナップショットです。
- デプロイした helloworld アプリには
hello.example.comのホストヘッダーでアクセスできます。- ConfigMap リソース (config-network) を編集して、
domainTemplate: '{{.Name}}.{{.Domain}}'としています。 - 下のウィンドウで、http://hello.example.com にリクエストを投げて、
Hello Worldのレスポンスが返って来ていることが確認できます。
- ConfigMap リソース (config-network) を編集して、
- デプロイした helloworld アプリに対して knative-inspect を使って、Knative が裏側で作成したリソース一覧を確認しましょう。
- 1 つのアプリケーションに対して 20 個のリソースが裏側で作成されています。
- トップリソースは Knative Service リソースです。
- それ以外の Service は全て K8S Service リソースになります。
- K8S Service が複数作成されていることを確認して下さい。
- これらはスケール時に使われるリソースで、後ほど用途を説明します。

helloworld アプリのアップデートしてみます。
- 環境変数として TARGET=ServerlessDays を指定しています。これによりレスポンスの中身が
Hello ServerlessDaysに変わります。 - 新しい Revision を
hello-v2という名前で作成します。 - hello-v2 という名前の Revision に
latestという名前のタグを付けます。タグを付けることで、latest-hello.example.com({{.Tag}}-{{.Name}}.{{.Domain}}) という名前のエンドポイントが払い出されます。 - http://latest-hello.example.com にアクセスすると新しい Revision のレスポンス Hello ServerlessDays が返ってきます。
- トラフィックは古い Revision を向けたままにします。http://hello.example.com にアクセスしても、古い Revision のレスポンスが返ってきます。

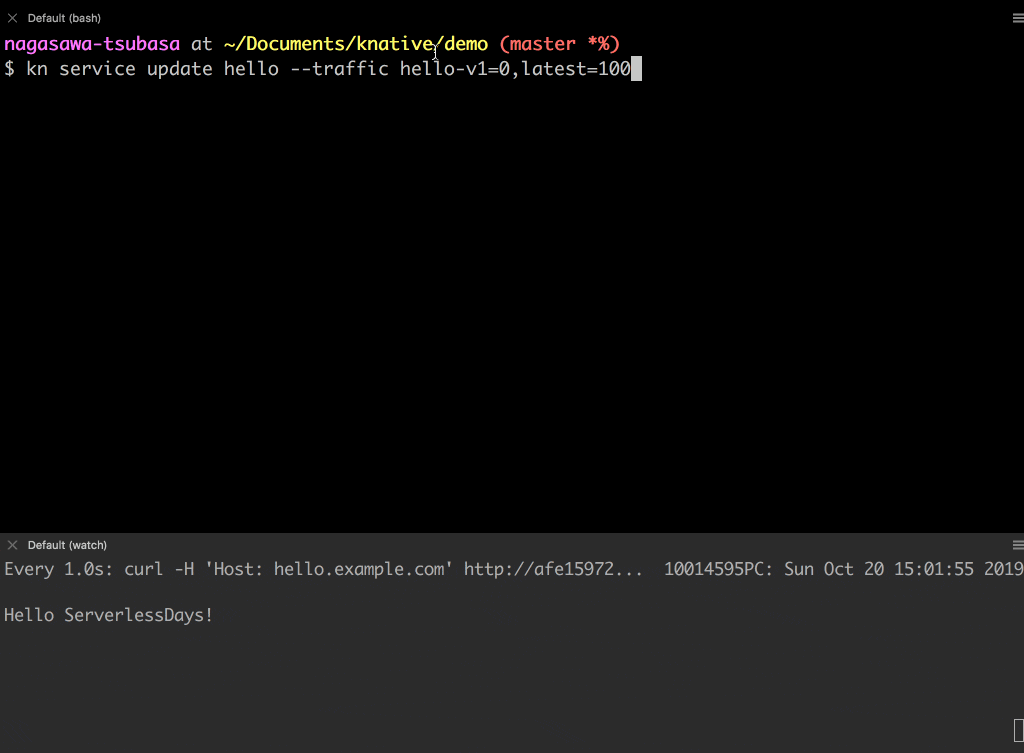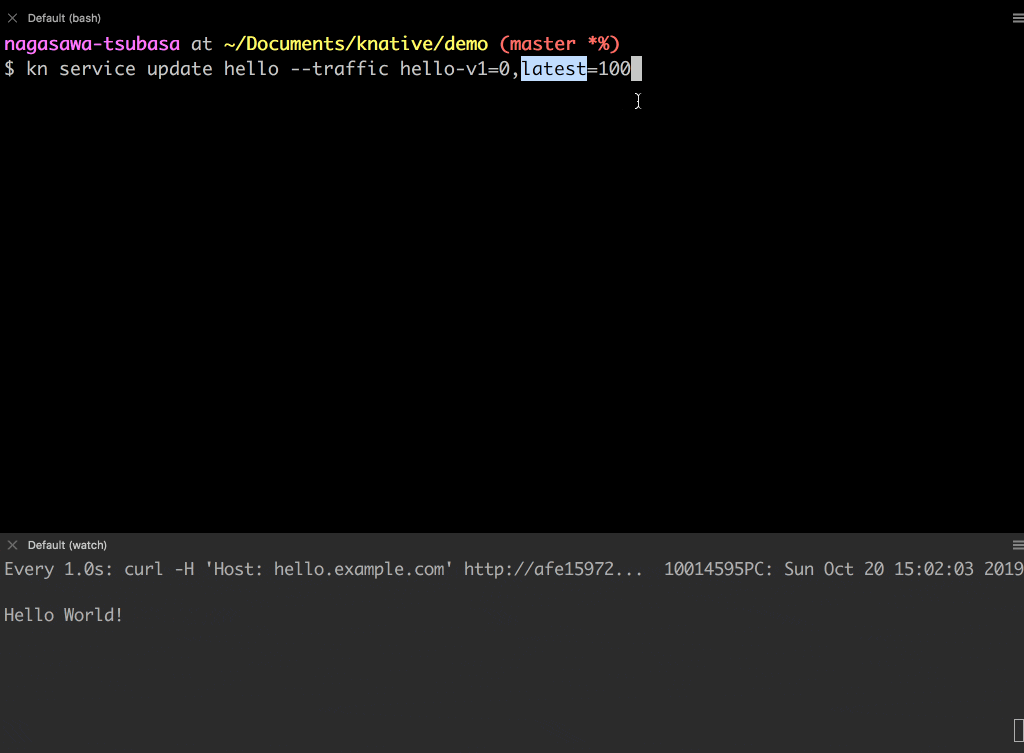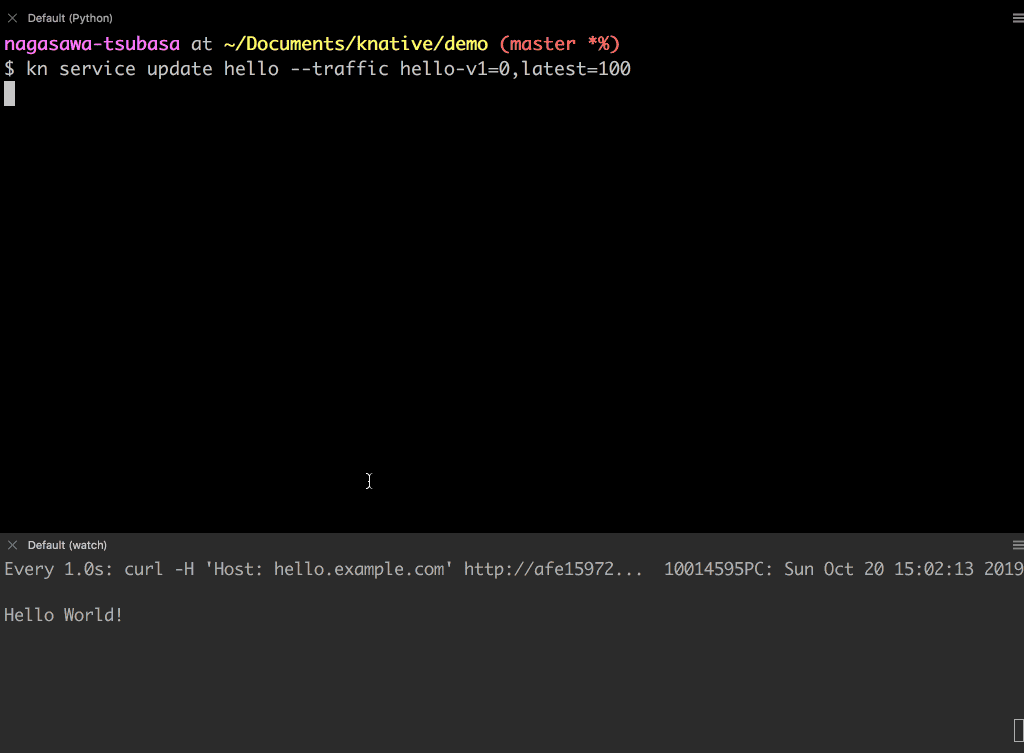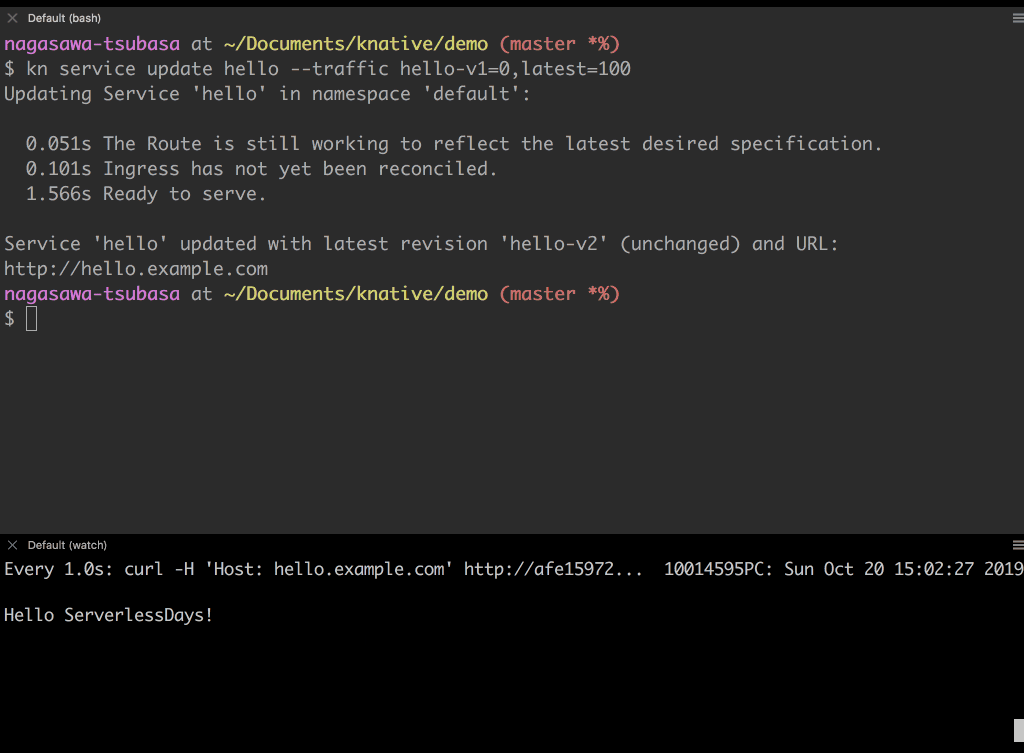
2 つの Revision hello-v1 と hello-v2 へトラフィックを分割してみましょう。
- 現在は、
hello-v1Revision にトラフィックが 100% 向いています。 -
hello-v1とhello-v2の Revision にそれぞれ 50%の割合でトラフィックを流します。 - レスポンスが
Hello WorldとHello ServerlessDaysが大体交互に表示されることが確認できます。
新しい Revision hello-v2 にトラフィックを 100% 流してみましょう。レスポンスが全て Hello ServerlessDays に切り替わったことが確認できます。
Knative Primitives

Knative Serving の主要なコンポーネントは 4 つあります。
-
Knative Service
- 多くの開発者が触れ合うことになる、Knative Serving の中で最も抽象度の高いリソースです。
- 単一の Stateless なアプリケーション (e.g. マイクロサービス) の環境をインスタンス化します。
- アプリケーションのコードと設定それからアプリケーションに接続可能なエンドポイントを保持します。
- コントローラーは内部的に Configuration と Route リソースを生成します。
-
Configuration
- 自動でスケールする単一のアプリケーションの理想的な姿を定義したものです。
- Revision リソースを生成するためのテンプレートを定義します。
- コントローラーは内部的に Revision リソースを生成します。
- Knative のリードである Matt Moore によると、Configuration は Git におけるブランチに近いものであると、Online Meetup 2 - Aug 29, 2019 - Knative and Gloo で発言しています。
-
Revision
- Stateless で自動スケールするアプリケーションのある時点での不変なスナップショットです。
- アプリケーションのコードと設定を保持します。
- アプリケーションの変更に伴うロールアウト/ロールバックを HTTP のルーティングを変更することで実現します。
- ルーティング先の Revision はサービス名と Revision 名で決定されるため、一意の Revision から生成された Pod にリクエストを流すことができます。
- Revision は不変なため、直接変更することはできません。
- 例外として、Secret/ConfigMap などの変更可能なリソースに変更が入った場合や、Knative Serving のバージョン更新によりデフォルト値が変わった場合が考えられます。
- Revision を変更したい場合は、Configuration 経由で新しい Revision を生成する必要があります。
- コントローラーは内部的には KPA (or HPA) と Deployment を生成します。
-
Route
- Revision に対する HTTP リクエストルーティングの状態を管理します。
- Service Mesh の機能が有効な場合、複数の Revision に対してパーセントベースでリクエストを分配します。
- コントローラーは内部的に IstioGateway からのリクエストを受けるための Service リソースを生成します。
v0.9.0 時点での Knative の Custom Resource Definitions (Kubernetes を独自に拡張したリソース) は 10 個あります。
certificates.networking.internal.knative.dev (Optional)
configurations.serving.knative.dev
images.caching.internal.knative.dev
ingresses.networking.internal.knative.dev
metrics.autoscaling.internal.knative.dev
podautoscalers.autoscaling.internal.knative.dev
revisions.serving.knative.dev
routes.serving.knative.dev
serverlessservices.networking.internal.knative.dev
services.serving.knative.dev

Knative Service のマニフェストに戻ります。
spec.template.metadata.name を指定しない場合、metadata.name + ランダム文字列で Revision の名前が自動的に生成されます。また、spec.traffic を明示的に指定しなくても、デフォルトでは最新の Revision に 100 パーセントのリクエストがルーティングされます。
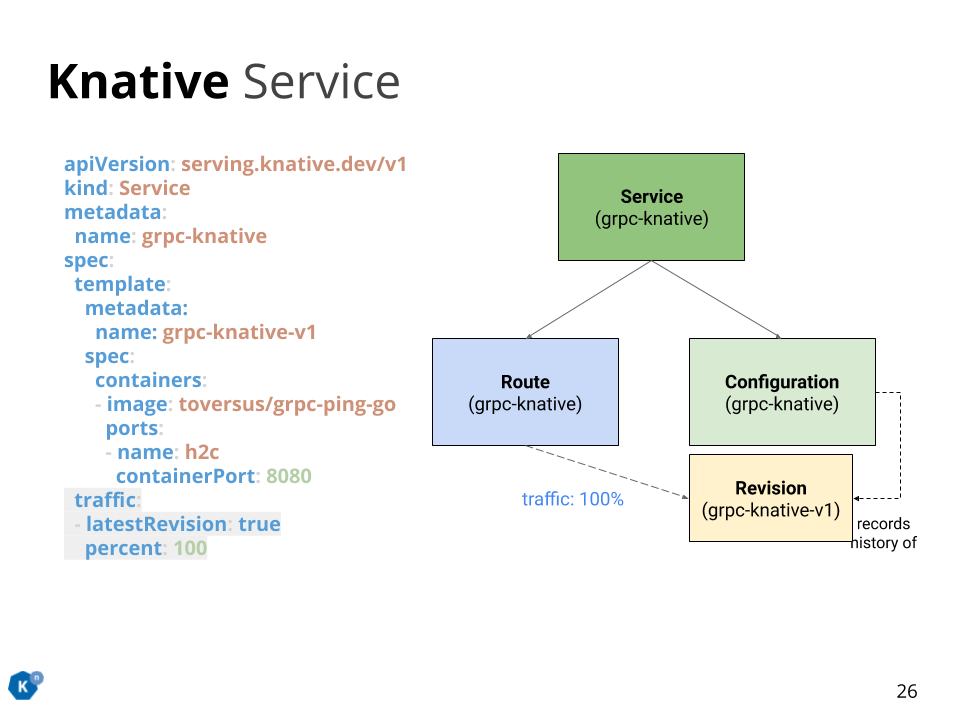
先ほどの Knative Service 定義は次の Knative Service 定義と等価です。

Knative Service でアプリケーションをローリングアップデートしてみましょう。
template.metadata.name に新しい Revision の名前を指定します。traffic ブロックでは、明示的に Revision 名を指定してルーティングの割合を指定します。まずは、古いバージョンの Revision (アプリケーション) に 100 パーセントのトラフィックを向けた状態にしておきます。

次に、新しい Revision (アプリケーション) に Traffic を向けます。古い Revision のアプリケーションの中でリクエストの処理を終えたものから次々に新しい Revision に置き換わって行きます。 正確に言うと、リクエストの処理数が 0 になって特定の時間 (デフォルトでは Terminate するかの判断に 60 秒、Graceful Shutdown の猶予期間で最大 30 秒の合計 90 秒) が経過したものから Pod が Terminate され、新しい Revision の Pod が立ち上がっていきます。
リクエストが一定期間ルーティングされず、以下の条件 (デフォルト) を満たした Revision は、GC によってお掃除されます。GC の設定は、config-gc で変更可能です。
- Revision が生成されてから 24 時間が経過している。
- Route が Revision を最後にルーティング先として指定してから 15 時間経過している。
- GC 対象と見なす Revision の保持世代数 (デフォルトで 1 世代) の範囲外である。
- Revision を GC するか判断する間隔は、5 時間毎です。Revision の annotations に付与されている。
serving.knative.dev/lastPinned: “<EpochTime Seconds>” で一つ前の GC がいつ起きたかが分かります。
Demo#2 Rolling Update

helloworld アプリよりも少しだけ現実に即したマイクロサービスの一部を用意しました。負荷を与えながらローリングアップデートしてみましょう。
- gateway サービスは GraphQL サーバです。バックエンドにある account サービスにリクエストを振り分けます。
- account サービスは gRPC サーバです。gateway サービスから送られてきた HTTP/2 のリクエストを処理します。
- account サービスは DynamoDB から必要な情報を取り出して、レスポンスを返します。ただ、今回のデモではレスポンスを返す前に 10 秒間意図的にスリープさせています。

gateway サービスと account サービスのデプロイに使ったマニフェストです。(一部 annotation を省略しています。)
-
autoscaling.knative.dev/targetは、1 つの Pod で同時に処理可能なリクエスト数です。この値にcontainer-concurrency-target-percentageのパーセントを掛け合わせた 7 個のリクエストを Pod が処理していると、Autoscaler が account/gateway サービスをスケールアウトします。 -
autoscaling.knative.dev/minScaleとautoscaling.knative.dev/maxScaleは、それぞれサービスのスケールアウトの最小値と最大値です。この場合、account/gateway サービスの Pod 数は最小で 1 台、最大で 3 台までスケールアウトします。 -
sidecar.istio.io/proxyRequestCPUやsidecar.istio.io/proxyRequestMemory、sidecar.istio.io/proxyLimitMemoryは、それぞれ istio-proxy に割り当てるリソースを調整します。istio-injector が istio-proxy を忍ばせる際のテンプレートを修正しています。詳細は、Issue コメント を参照して下さい。 -
queue.sidecar.serving.knative.dev/resourcePercentageは、アプリのコンテナに割り当てたリソース制限に対する割合で queue-proxy に割り当てるリソースを決定します。ただ、queue-proxy に割り当てるリソースの上限がハードコードされているため、こちらの値と比較して最終的に決定されます。 - account サービスに付与されているラベル
serving.knative.dev: cluster-localはサービスを外部に公開せずクラスター内部に留めるために利用します。このラベルがあるサービスは、Istio IngressGateway ではなく、Cluster IngressGateway を経由してバックエンドの Pod にリクエストが流れます。

新しい Revision を作成して、そちらにリクエストを向けます。イメージの中身は特に変更していないですが、タグを変えています。

- まず skaffold を利用して、サービスをデプロイします。リソースが作成されます。
- エンドポイントにアクセスして、レスポンスを確認しています。レスポンスが返ってくるのが遅いのは、アプリの実装で意図的に 10 秒間スリープさせているからです。
- マニフェストを変更します。イメージのタグを変更していますが、アプリの実装に変更はありません。
- v1 のサービスに負荷を掛けます。新しい Pod が立ち上がってきます。
- 負荷を掛けながら新しいサービスをデプロイし、そちらにリクエストを向けます。
- 新しい Revision の Pod が一つ作成されます。古い Revision の Pod の処理が終わり、新しい Revision へのリクエストが増えると、新しい Revision の Pod が追加されていきます。
- 古い Revision の Pod が処理を終え、一定期間リクエストを受けつけないと、Pod が停止されていきます。
- 負荷を掛け終わりました。アップグレード時にリクエストを取りこぼすことなく、新しい Revision にリクエストを向けることができました。
- 新しい Revision へのリクエストがなくなったので、Pod が停止されていきます。
- 新しい Revision の Pod が 1 台だけ残ります。

Knative Serving の内部コンポーネントやゼロスケールの仕組みを知りたい方は、KubeCon China 2019 の Inside Knative Servin の講演をまずは視聴してみて下さい。既存のデプロイ方式との比較から始まり、Activator や Autoscaler など重要なコンポーネントの概要が素晴らしく良くまとまっています。
Inside Zero Scale Abstraction
Knative Serving のゼロスケールの仕組みを見ていきましょう。

ゼロスケールした状態から必要な数の Pod がスケールアップしてくるまで、リクエストをどうやって保持すれば良いでしょうか?

ゼロスケールを実現する重要な要素はいくつかあります。
- Pod の起動待ちで処理できないリクエストを保持するためのキュー
- リクエストがタイムアウトする前にスケールアウト
- Pod へリクエストを流すパスとキューにリクエストを溜めるパスの切り替え
- 同時処理数のメトリクスを監視
- メトリクスからスケールを決定

Knative の主要なコンポーネントは次の 3 つです。
- Activator
- 中央集権的なリクエストキューです。
- Activator という名前は歴史的な背景によるもので、役割上 KQueue と呼ばれることもあります。
- 過去に一度名前の変更を試みていますが、変更箇所が大量にあり断念しています。Rename Activator to KBuffer #2380
- リクエストを適切にバックエンドにルーティング、負荷分散します。
- Activator に送られたリクエスト数をメトリクスとして Prometheus 形式で公開します。
- Autoscaler
- Activator や queue-proxy からメトリクスを収集します。
- 収集したメトリクスから必要な Pod 数を計算し、スケールの決定を下します。
- 収集する Pod の数が増えると、全ての Pod からメトリクスを収集することがボトルネックになってしまいます。そのため、統計的に収集が必要なサンプル数を動的に算出しています。詳細は、Dynamically change autoscaling metrics scraping sample size based on pod size #3831 を確認して下さい。
- queue-proxy
- 分散リクエストキューです。
- Pod の中でリクエストを最初に受ける部分です。
- リクエストをユーザーコンテナ (アプリ) に転送します。
- containerConcurrency で指定されたリクエストと現在処理中のリクエスト数を比較して、大量のリクエストが一度にアプリケーションに届かないように調整しています。
- queue-proxy に転送されたリクエスト数をメトリクスとして Prometheus 形式で公開します。
- サイドカーコンテナとしてデプロイされます。
A journey through initial scaling to zero

Istio と Knative Serving を K8S クラスターにインストールした後の状態です。まだ、Knative Service をデプロイしていません。
- Autoscaler は、WebSocket サーバを起動してメトリクスが届くのを待ちます。
- Activator は、起動時に Autoscaler に対して WebSocket のコネクションを張ります。
- Activator が提供するメトリクスは、Activator にルーティングされたリクエスト数の平均値です。
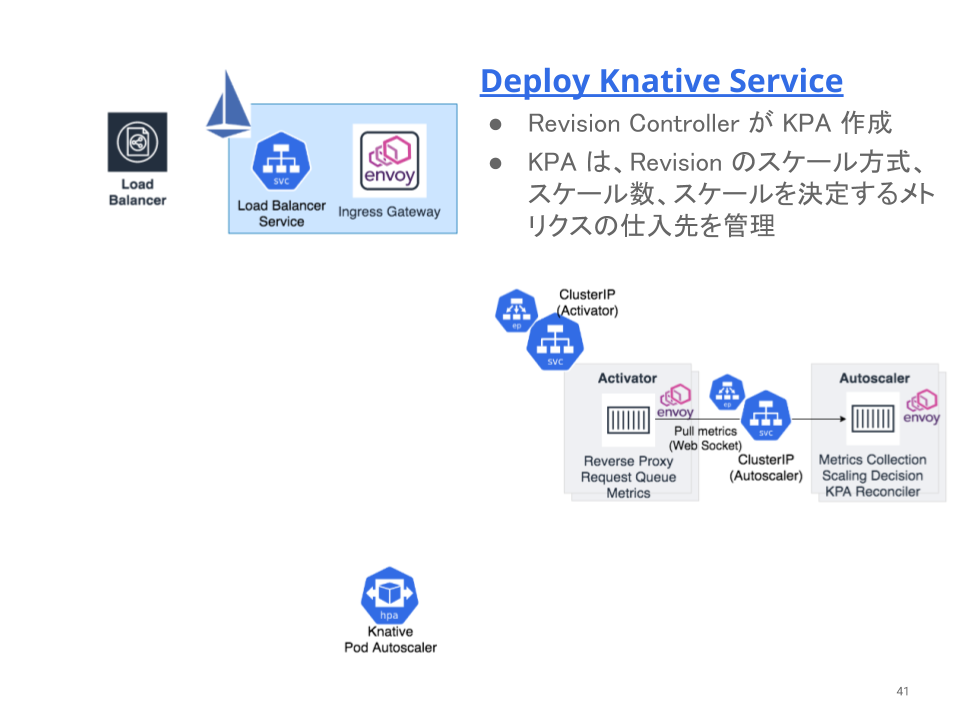
Knative Service をデプロイすると、
Revision コントローラが Knative Pod Autoscaler (KPA) を作成します。
- KPA は、HTTP リクエストに関係するメトリクスをもとに自動スケールするための、Knative の独自リソースです。
- KPA では、処理中のリクエスト数か秒間のリクエスト数 (RPS) をもとに自動スケールさせることができます。
- Horizontal Pod Autoscaler (HPA) をベースにしていますが、HPA は CPU やメモリなどのリソース使用率をベースにスケールします。
- HPA は、Pod のリソース使用率を直接監視する必要がありますが、ゼロスケール時には Pod が存在しないため、ゼロからスケールアップする判断が下せません。HPA のゼロスケールは未実装で、HPA scale-to-zero #3064 の Issue で議論が進められています。

Serverless-style Service は、K8S Service リソースを Serverlss なワークロードに合わせて抽象化したリソースです。
Serverless-style Service を作ることになった背景は、
- K8S の Service リソースは、Pod のラベルを使って Service Discovery することで、Endpoint (IP:Port) を更新します。
- K8S の Service リソースでは、Serverless なワークロードに必要なゼロスケールに対応できません。
- ゼロスケールした場合、Pod の Endpoint を紐付けることが出来ず、トラフィックを落としてしまいます。
- 実際にアプリケーションがリクエストを処理できる状態 (Serve Mode) とアプリケーションがリクエストを処理できない状態 (Proxy Mode) の切り替えが必要です。

前ページで触れたように Knative はゼロスケールを実現するために、Serve Mode と Proxy Mode を切り替えます。すなわち、Public サービスがスイッチの役割を担っています。
切り替えは、3 つの ClusterIP Service を使って行います。K8S では、通常外部公開するアプリと Service リソースは 1:1 の関係ですが、Knative では、1:3 の関係であることに注意して下さい。
- Service without selector (Public Service)
- without selector な Service であるため、Endpoints オブジェクトは自動で紐付きません。
- リクエストをアプリにルーティングするために実際に使われるスイッチの役割を担う Service です。
- Revision backed Service (Private Service)
- selector で特定の Revision ラベルを指定した Service です。
- Serve Mode 時に、Public Service に Endpoints オブジェクトをコピーするために使います。
- Endpoints オブジェクトには Revision に属する Pod 群の PodIP が含まれています。
- Metrics Service
- queue-proxy から Revision に属する Pod のメトリクスを収集するための K8S Service です。
- 通常のメトリクスとユーザーが定義可能なカスタムメトリクス用の 2 つのポートが紐付いています。
- Activator backed Service
- selector で Activator 群を指定した Service です。
- Proxy Mode 時に、Public Service に Endpoints オブジェクトをコピーするために使います。
- Endpoints オブジェクトには Activator 群の PodIP が含まれています。
Serverless-style K8S Service のデザインドキュメントは、Revision-based activation or Serverless k8s Style Services です。Revision K8S Service は、このドキュメントにおける Private Service のことです。細かい実装の部分は変わってしまっていますが、大枠がまとまっています。

Knative Service をデプロイした直後なので、アプリがリクエストを受け取る準備がまだできていません。そのため、Serverless Service はリクエストパスを ActivaPublic Service に Activator を向いている Service の Endpoint オブジェクトを紐付けます。

Activator は、Revision Backend Manager という機構を持っており、Activator からユーザーアプリケーションにリクエストを転送しても良いかを監視しています。正確に言うと、以下の 2 つのヘルスチェックを並列して行い、より早く正常性が確認できた IP に対してリクエストを転送します。
- Revision K8S Service の ClusterIP
- Revision K8S Service の Endpoints から得られる PodIP
- 正確には PodIP を使って queue-proxy のヘルスチェックを送っています。
なぜ、2つのヘルスチェックを並列して行なっているかと言うと、
- Endpoints の ClusterIP への反映は kube-proxy の iptables の更新が必要
- iptables の更新タイミングは kube-proxy の iptables-min-sync-period によって決まる
ネットワークプログラミングのオーバーヘッドにより ClusterIP に対するヘルスチェックの通過が遅れるからです。iptables-min-sync-period の指定はクラウドプロバイダー毎に異なります。GKE の場合だと 10s になっているようですが、EKS の場合は 0s です。
EKS の場合
I1004 07:40:39.361635 1 flags.go:33] FLAG: --iptables-min-sync-period="0s"
詳細は、iptables-min-sync-period が Knative に与えた影響については、Cold start latency exacerbated by iptables-min-sync-period を確認して下さい。

Pod 内部の全てのコンテナの readinessProbe が成功して初めて、kubelet によって Pod が正常だと判断されます。
Activator が PodIP か ClusterIP どちらかの正常性を確認できました。
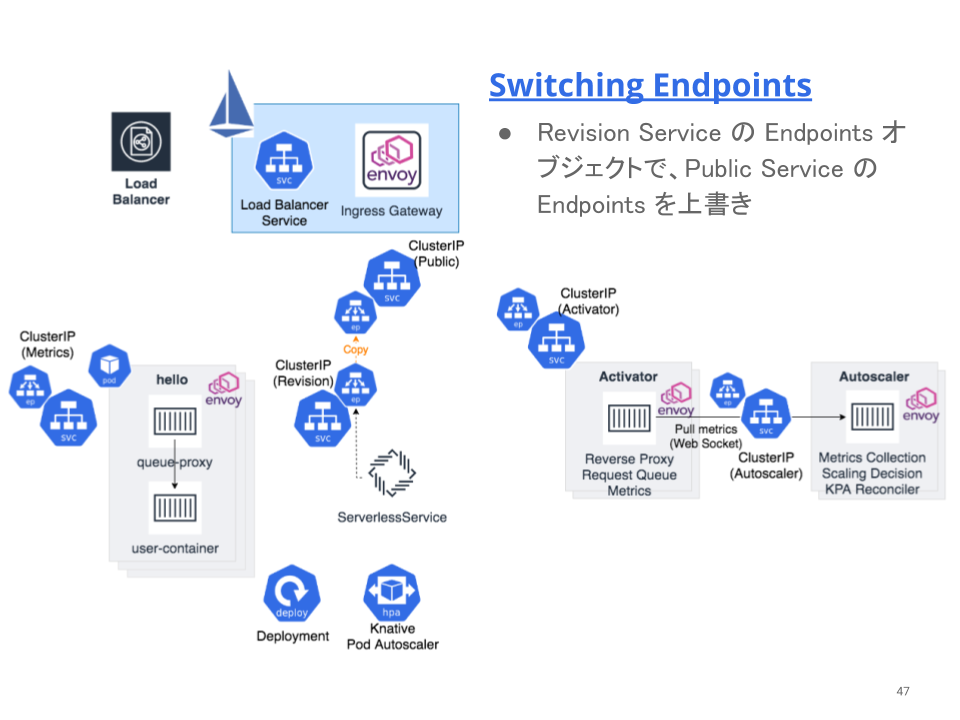
Serverless Service は、Revision Service の Endpoints オブジェクトを監視しているので、同時もしくは少し遅れた段階で、Public Service の Endpoints オブジェクトを Revision Service の Endpoints オブジェクトで上書きします。これにより、それ以降のリクエストは IngressGateway から Activator を経由せず、直接 Revision に属する Pod に向かいます。

queue-proxy は、受け取ったリクエスト数や user-container に転送したリクエスト数などの情報を Prometheus 形式で公開しています。詳細は、queue-proxy のコードを確認して下さい。
- queue-proxy が受け取ったリクエスト数
- queue-proxy のレスポンス時間
- user-container に転送されたリクエスト数
- user-container のレスポンス時間
- queue-proxy で溜めているリクエストキューの深さ
Autoscaler はこれらの情報をスクレイプし、Activator からのメトリクスと合わせてスケールの判断を下します。
Autoscaler のスケールの決定を決定する際に全ての queue-proxy からメトリクスを収集しているとレイテンシが悪化します。そのため、統計的に信頼できるサンプル数を計算して、その数だけスクレイプします。詳細は、Autoscaler のコード を確認して下さい。サンプリングする対象のサイズは、統計を元に決定しています。

ゼロスケールする前に今度は、Activator の Endpoints オブジェクトで Public Service の Endpoints オブジェクトを上書きします。これにより、ゼロスケール時にリクエストが入ってきても Activator のリクエストキューに溜めることができます。

Knative Service をデプロイして外部からリクエストが一切入って来なかったので、そのままゼロスケールしました。
A journey through scaling from zero

初めて Knative Service をデプロイし、ゼロスケールした後の状態です。
外部からリクエストが来ると、クラウドロードバランサーがリクエストを受け、Kubernetes のワーカーノードにリクエストを振り分けます。

Service type LoadBalancer は、Kubernetes のワーカーノードで特定のポートへのリクエストを待ち受けており、クラウドロードバランサーから振り分けられたリクエストをキャッチします。

Service type LoadBalancer は、nodePort で受けたリクエストを Istio Ingress Gateway (Front Envoy) に転送します。

Istio Ingress Gateway は、リクエストのホストヘッダーを見て、転送先の Knative Service を識別し、その Public Service にリクエストを転送します。

Public Service の Endpoints は Activator を向いているため、リクエストを Activator に転送します。Activator は、送られてきたリクエストをキューに溜めます。また、Activator は自身が公開しているメトリクスを更新します。

Autoscaler は、Activator のメトリクスを収集し、特定の Knative Service の Pod をスケールする必要があることに気付きます。Autoscaler は、KPA をリコンサイルして必要な Pod 数を指定します。

KPA は Deployment のレプリカ数をゼロから必要数に変更します。Pod が起動され始めます。

Activator は、以下の2つのタスクを並列実行し、健全な IP アドレスを見つけ、ユーザーリクエストの転送先を決定します。
- Revision K8S Service の Cluster IP に対して HTTP Get リクエストを送信し、queue-proxy の正常性を監視します。
- Revision K8S Service のイベントを監視し、Endpoints オブジェクトが紐づけられるのを待ちます。紐付けられた場合、その Endpoints に対して HTTP Get リクエストを送信し、queue-proxy の正常性を確認します。

Activator は、ClusterIP もしくは PodIP に対してユーザーリクエストを転送します。転送されたリクエストは queue-proxy を経由してアプリケーションに送られます。

Serverless Service は、Public Service の Endpoints オブジェクトを Revision Service の Endpoints で上書きします。

以降のリクエストは Activator を経由せず、Revision の Pod をバックエンドに持つ ClusterIP に転送します。

スケール時など Activator にリクエストが Proxy される場合のトレーシング結果と Activator を経由しない通常時のトレーシング結果です。ゼロスケール時は 2 度 proxy されているのが分かります。逆に通常時は 1 度だけ proxy されています。
Autoscaling ultimate goal

Autoscaling Working Group の究極的なゴールは、ゼロスケールの仕組みを Kubernetes に取り込む or 還元することです。L4 リソースの K8S Service もしくは L7 リソースの Ingress を使って、ゼロスケールする仕組みを作り上げたいのです。そのため、Ingress v2 の Proposal である [PUBLIC] A sketch of the API にも早い段階からフィードバックを積極的に行なっています。
Kubernetes の HPA の現状は、API レベルで minReplicas: 0 をサポートした段階です。まだ、Kubernetes のリソースとしてリクエストをバッファする仕組みはありません。そのため、外部のメトリクスをベースにゼロスケールを判断する必要があります。
また、Knative のコアメンバーで、現在は kubernetes/sig-autoscaling のメンバーである Joe Burnett が Slack で発言しているように、HPA のスケールは遅いです。
hpa will scale up from zero when it notices the custom or external metric warrants a scale-up. the controller evaluates every hpa each 15 seconds, so the delay could be that long, which is why knative scale-from-zero is "faster". the activator (or similar component) is required to serve synchronous request traffic because it "holds" the request until a pod is available. another component could be used, such as kubeproxy (see the knative scaling wg when Rajat Sharma presented such a design: https://docs.google.com/document/d/1FoLJqbDJM8_tw7CON-CJZsO2mlF8Ia1cWzCjWX8HDAI/edit#heading=h.w7c11tvi3emt) the activator is not strictly necessary for scale-from-zero, it just provides a fast signal that the metric has changed and should be reevaluated. @markusthoemmes has proposed (https://docs.google.com/document/d/1jARPGYAwievgzFTN7YYZ7a8Jaz2NUGq-fXTeeBHk5X0/edit#) a custom metrics watch api which could be used to provide the same fast signal to the hpa. with such a mechanism, the activator could inform the knative metric controller about pending requests, which could notify the hpa via the watch api, which could immediately evaluate the hpa for a new scale. this would make the hpa "fast" like the kpa and could be a path toward converging the autoscaler implementations. (note: cm watch and hpa use of watch are not implemented or planned for implementation currently).

kube-proxy を使ったゼロスケールの仕組みも Proposal 段階ですが、存在します。先ほどの Joe Burnett のコメントに当時 Knative で議論した内容の録画が載っているので興味があれば見てみると良いと思います。
Knative のゼロスケールの仕組みは Osiris による影響が大きいです。Endpoints を手動で付け替える部分は Osiris を参考にしています。ただ、Osiris の場合は、2 つの K8S Service を使ってリクエストパスを切り替えているようで、K8S Service のネットワークプログラミングのラグが影響しないのか気になるところです。