TL;DR
-
YouTubeから動画を拾ってTweetするbotをPythonで開発し、AWS Lambdaに載せてみました
- TwitterAPIを使ってプログラムからツイートしてみます
- YouTubeのページを構文解析し、文字列操作を使って動画URLを抽出してみます
- LambdaおよびCloudWatchと連携し、指定時間での自動ツイートを実現します
動機
新しい職場にて初めてAWSを触ることになったので、これを機にと個人アカウントを取ってみました。チュートリアルだけというのももったいないので、何か自分のためのサービスを作って載せると面白そうです。
で、Twitterのbot開発にはもともと興味があったので、これも前から興味を持ちつつ触ってなかったPythonでbotを作り、lambdaを使って運用してみようと思い立ちました。AWS lambdaは2017年4月からPython3系を扱えるようになったので、心置き無く最新バージョンで書けそうだなー、というのも狙いです。
ユーザーストーリー
毎日の退勤をもう少し楽しみにするために、定時になると自分が興味ありそうなYouTube動画をbotが勝手に検索して、自分のTwitterアカウントに届けてくれるようにしたい。

前提
- 開発にはMacを使用します
- Pythonは3.6系を使用します
- pyenvもvirtualenvも使用しません。議論はあろうかと思いますが、個人開発なので。。
- で、開発環境構築はこちらの記事等を参照しました
- bot化したいTwitterアカウントはあらかじめ用意してあるものとします
TwitterAPIを使ってプログラムに呟かせる
アクセスキーの取得
bot化したいアカウントでTwitter Application Managementにログインすると、アプリケーションの作成とConsumer Key、及びAccess Tokenの取得ができます。
なお、Appの作成にはTwitterアカウントが電話番号認証済みである必要があります。認証済みでないと怒られるので、エラーメッセージ中のリンクからさらっと済ませておきましょう。
- Consumer Key
- Consumer Key Secret
- Access Token
- Access Token Secret
以上の4パラメータがあればプログラムからのツイートができます。コピーしてこんな感じのファイルを作っておきましょう。
CONSUMER_KEY = "xxxxxxxxxxxxxxxxx"
CONSUMER_SECRET = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
ACCESS_TOKEN = "yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy"
ACCESS_TOKEN_SECRET = "yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy"
複数の外部ユーザーからアクセスがあるようなアプリケーションの場合(=「このアプリケーションとの連携を許可しますか?」など出るやつ)はそれぞれの役割についてもう少し説明が必要ですが、今回はある程度一緒くたに考えてしまっても実装に支障ありません。
PythonでOAuth認証
ライブラリの導入と管理
Pythonのライブラリは、パッケージ管理ツールであるpipでインストールできます。仮想環境がない場合、オプション無しで勝手にglobalに入るのがうーん、という感じですがまあそれは置いておいて。
PythonでHttp通信を行うライブラリとしては、requestsがポピュラーなようです。また、今回はTwitterAPIを使うための認証が必要なので、OAuth認証を扱えるライブラリも必須です。ここはrequestsと同じところが公開しているrequests_oauthlibを使用しました。
pip3 install requests requests_oauthlib
さて、インストールはできましたが、今度は開発するプロジェクトがこれらのライブラリに依存していることを表明しておくのがマナーです。js界隈で言うところのpackage.jsonですね。
Pythonでは依存関係を記したrequirements.txtなどを作っておくケースが多いようです。
requests==2.18.4
requests-oauthlib==0.8.0
ちなみに、pip3 freeze > requirements.txtでインストールされた依存関係をrequirements.txtに吐き出せます。
逆に.txtファイルを元に一括インストールする場合は、-rオプションを用いてpip3 install -r requirements.txtなどと書けます。結構便利です。
つぶやいてみる
from requests_oauthlib import OAuth1Session
import config, json
twAuth = OAuth1Session(
config.CONSUMER_KEY,
config.CONSUMER_SECRET,
config.ACCESS_TOKEN,
config.ACCESS_TOKEN_SECRET)
apiURL = "https://api.twitter.com/1.1/statuses/update.json"
params = { "status": "プログラムにツイートさせてみるテスト" }
res = twAuth.post(apiURL, params = params)
print(json.loads(res.text))
先ほど作ったconfig.pyをimportして、これだけ。思ったよりだいぶ手軽です。Twitterにアクセスして実際にツイートされたことを確認しましょう!
また、せっかくなのでレスポンスをjsonライブラリでロードして吐き出してみます。
{'created_at': 'Wed Dec 06 14:00:00 +0000 2017', 'id': 9384076800000000, 'id_str': '9384076800000000', 'text': 'プログラム
にツイートさせてみるテスト', 'truncated': False,
...(中略)...
'retweeted': False, 'lang': 'ja'}
思ったよりいろんな属性があることがわかりますね。深掘りは公式のリファレンスにて。
YouTubeから動画のURLを拾ってくる
続いて、YouTubeから動画を探してくるパートです。
Webクローリング
この分野では、「クローリング」や「スクレイピング」と言った言葉が有名です。
クローリングはウェブサイトからHTMLや任意の情報を取得する技術・行為で、 スクレイピングは取得したHTMLから任意の情報を抽出する技術・行為のことです。
たとえば、あるブログの特徴を分析したい場合を考えてみましょう。
この場合、作業の流れは
- そのブログサイトをクローリングする。
- クローリングしたHTMLからタイトルや記事の本文をスクレイピングする。
- スクレイピングしたタイトルや記事の本文をテキスト解析する。
というようになります。
今回は、YouTubeをクローリングし、その中から動画のURLをスクレイピングすることになりますね。
Webページのクローリングとスクレイピングを行う際は、それがどんな目的のものであれ、HTMLを構文解析することが必須となります。Pythonでは、これを強力に支援するBeautifulSoupと言うライブラリがあります。執筆時点で最新のbeautifulsoup4を導入してみます。
pip3 install beautifulsoup4
早速使ってみましょう。Qiitaのトップページから<a>タグを探し、その中に含まれるhref属性の値を取得してみます。
import requests
from bs4 import BeautifulSoup
URL = "https://qiita.com/"
resp = requests.get(URL)
soup = BeautifulSoup(resp.text)
# aタグの取得
a_tags = soup.find_all("a", href=True)
for a in a_tags:
print(a["href"])
結果
/about
https://qiita.com/sessions/forgot_password
https://oauth.qiita.com/auth/github?callback_action=login_or_signup
https://oauth.qiita.com/auth/twitter?callback_action=login_or_signup
・・・(中略)
https://qiita.com/api/v2/docs
https://teams.qiita.com/
http://kobito.qiita.com
いい感じです!
HTMLパーサーについて
さて、先のコードを実際に試すと、HTMLパーサーが明示されていないために警告が出ます。これは実際の解析時に使われるパーサーが実行時の環境に依存するためです。異なる環境下で同じ振る舞いを期待するには、使用するHTMLパーサーを明示してあげる必要があります。
デフォルトではhtml.parserが使われますが、lxmlかhtml5libを導入してこちらを明示してあげるのが無難なようです。このあたりの情報は下記の記事をだいぶ参考にさせていただきました。パーサーの選択だけでなくスクレイピング全般の情報が非常によくまとまっているエントリなので、オススメです。
PythonでWebスクレイピングする時の知見をまとめておく - Stimulator
パーサの良し悪しを考えるとlxmlでチャレンジしてダメならhtml5libを試すのが良さそう。
今回はこの1文に愚直に従ってみます。事前にpip3 install lxml html5libも忘れずに。
import requests
from bs4 import BeautifulSoup
URL = "https://qiita.com/"
resp = requests.get(URL)
+try:
+ soup = BeautifulSoup(resp.text, "lxml")
+except:
+ soup = BeautifulSoup(resp.text, "html5lib")
-soup = BeautifulSoup(resp.text)
# ...以下は先ほどと同様
Crawlerクラスを作ってみる
すでにPythonでオブジェクト指向な書き方を経験している方はこの辺りを飛ばしていただいて構いません。せっかくHTMLを解析してくれるコードができたので、クラスとして書き換えてみます。
import requests
from bs4 import BeautifulSoup
class Crawler:
def hrefs_from(self, URL):
a_tags = self.soup_from(URL).find_all("a", href=True)
return set(map(lambda a:a["href"], a_tags))
def soup_from(self, URL):
res_text = requests.get(URL).text
try:
return BeautifulSoup(res_text, "lxml")
except:
return BeautifulSoup(res_text, "html5lib")
個人的にはインスタンスメソッドの第1引数が常にselfでなければならないのは書く量が増えるので少しもどかしいですね。ハマりポイントにもなりかねない…。
ちなみに、ここではラムダ式を使用し、hrefs_fromメソッドの戻り値の型をsetにしてみました。これは、今回のユースケースを鑑みてリンク先URLの重複を排除した方が便利と判断したためです。出現頻度など解析したい場合はまた改めて設計を考える必要があるでしょう。
継承と、YouTubeへのアクセス
YouTubeをクローリングするにあたって、「検索文字列を与えたら検索結果のページをクローリングし、動画を探してくる」などの機能があると便利そうです。先ほどのクラスを継承して、実装してみます。
import random
import re
from crawler import Crawler
class TubeCrawler(Crawler):
URLBase = "https://www.youtube.com"
def hrefs_from_query(self, key_phrase):
"""
検索文字列を与えると検索結果ページに含まれるhref属性の値を全て返す
"""
return super().hrefs_from(self.URLBase + \
"/results?search_query=" + key_phrase.replace(" ", "+"))
def movies_from_query(self, key_phrase, max_count = 10):
"""
検索文字列を与えると検索結果ページに含まれる動画のビデオIDを返す
"""
return self.__select_movies(self.hrefs_from_query(key_phrase), max_count)
def __select_movies(self, hrefs, max_count):
"""
privateメソッド。href属性の値のsetからビデオIDのみを返す
"""
filtered = [ re.sub( "^.*/watch\?v=", "", re.sub( "&(list|index)=.*$", "", href )) \
for href in hrefs if "/watch?v=" in href ]
return filtered[:min(max_count, len(filtered))]
def choose(self, movie_ids, prefix = "https://youtu.be/"):
"""
渡した文字列のリスト(ビデオIDのリストを想定)から1つを選び、prefixをつけて返す
"""
return prefix + random.choice(movie_ids)
文法的には継承とprivateメソッドの書き方あたりが新しい話題となります。この記事の主題ではないので特段の説明は省きます。
実際に試すとわかるのですが、検索結果のページにノイズとなるリンクが多いばかりか、再生リストへのリンクなど紛らわしいものも多く、その辺を適切に弾いていくのに手こずりました。おかげでfilter関数や正規表現に少し強くなれた気がします。
正規表現についてはこちらの記事をだいぶ参考にしました。
繋げてみる
準備が整ったので検索->ツイートの流れを試してみます。
# !/usr/bin/env python3
# -*- coding:utf-8 -*-
from tube_crawler import TubeCrawler
from tweeter import Tweeter
import config
def main():
t = TubeCrawler()
movies = t.movies_from_query("Hybrid Rudiments")
chosen = t.choose(movies)
# ツイートする部分をクラス化したもの
tw = Tweeter()
tw.reply(config.REPLY_TO, chosen)
if __name__ == '__main__':
main()
エントリーポイントとなる関数が必要かなー、と思ったので何気なく(そう、本当に何気なく。これで良いと思っていたんですLambdaを使うまでは…)main関数を作成。
直接./main.pyでも呼べるようにこの辺からShebangを記述し始めました。また、末尾はファイル名で直接実行した場合にmain()を呼ぶためのおまじない。Rubyにも似たやつがありますね。あとはターミナルから呼んで動作確認するだけです。
$ ./main.py
実行したところ問題なく動きそうだったので、AWS Lambdaに載せていきます。
AWS Lambda
AWS Lambda はサーバーをプロビジョニングしたり管理しなくてもコードを実行できるコンピューティングサービスです。…コードが実行中でなければ料金はかかりません。
「一定の時刻に起動してツイート」さえしてくれればいいようなbotを動かすには、常時起動のサーバは必須ではありません。Lambdaのようなプラットフォームは今回のユースケースにうってつけと言えます。
関数をアップロードしておき、任意のイベントによって関数をトリガーするのがLambdaの基本的な使い方です。実際にやってみます。
ハンドラ関数の定義
イベントハンドラであるところのLambda関数はeventとcontextを受けるのが基本ですから、その形に沿ったハンドラ定義が必要です。以下を追加します。(mainが残ってるのが読みづらいけど今回は無視します)
# !/usr/bin/env python3
# -*- coding:utf-8 -*-
from tube_crawler import TubeCrawler
from tweeter import Tweeter
import config
def main():
t = TubeCrawler()
movies = t.movies_from_query("Hybrid Rudiments")
chosen = t.choose(movies)
tw = Tweeter()
tw.reply(config.REPLY_TO, chosen)
+ return chosen
+def lambda_handler(event, context):
+ result = main()
+ return { 'tweetedURL': result }
if __name__ == '__main__':
main()
パッケージング
Lambda 関数を作成するには、最初に Lambda 関数デプロイパッケージ (コードと依存関係で構成される .zip ファイル) を作成します。
ということで、プロジェクトのディレクトリに依存関係をインストールし、ZIP化する必要があります。pipのオプションでライブラリのインストール先は指定できるので、プロジェクトディレクトリに移動して…
$ pip3 install -r requirements.txt -t .
こんな感じでカレントディレクトリにインストールすれば一旦は大丈夫(平置きだと運用が厳しいのでベスプラを探った方が良さそう)。
ただし、HomeBrewでPython導入しているとpip3 install -tが失敗する
表題通りで、下記エラーが出る場合があります。
DistutilsOptionError: must supply either home or prefix/exec-prefix — not both
StackOverflowに同様の問題があるので、詳しくはこちらから。
ホームディレクトリに.pydistutils.cfgという名前のファイルを作って、以下の設定(というか、空のprefixを指定するハック)を書けば通るようになります。
[install]
prefix=
アップロードとハンドラの指定
AWS Lambdaのコンソールに移ります。関数を作成、ランタイムには"Python3.6"を選びます。コードエントリで「.ZIPファイルをアップロード」を選び、作ったZipをアップしましょう。
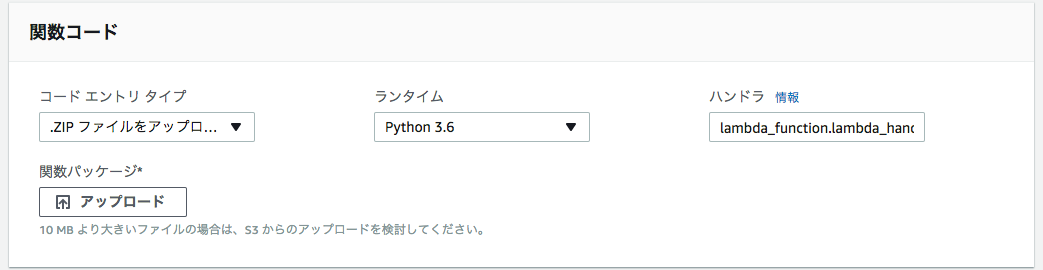
「ハンドラ」で処理の起点となる関数の名前を指定します。公式の説明では、
関数の filename.handler-method 値。たとえば、「main.handler」は、main.py で定義されたハンドラーメソッドを呼び出します。
すなわち[ファイル名].[関数名]とすれば良いので、main.lambda_handlerをハンドラに指定すればOKです。
定期実行
zipをアップロードしたら、次は定時実行の仕組みを作ります。
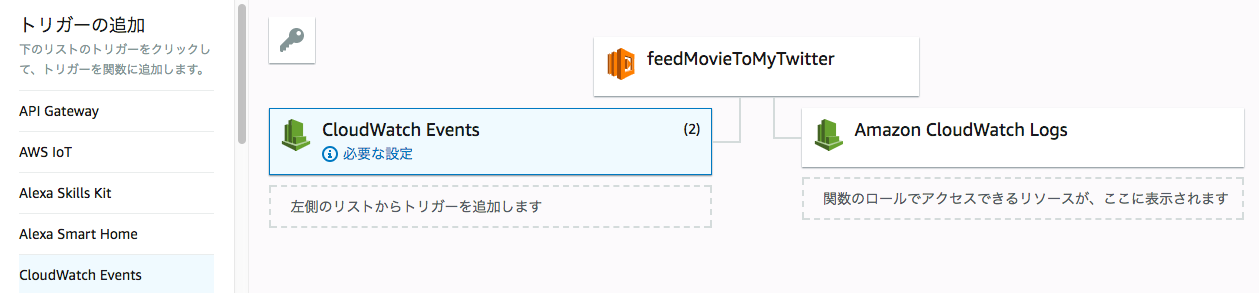
コンソール画面の「トリガーの追加」から「CloudWatch Events」を選びます。トリガーのルールにcron式を選べば、今回やりたいことは実現できますね。
- 日または週日の値は疑問符である必要がある
- UTCしか使用できない(ので、日本時間に合わせてずらす)
あたりが注意点でしょうか。今回は平日の定時につぶやいて欲しいので、こんな式にしてみます。
cron(15 10 ? * MON-FRI *)
運用してみて
運用して1週間ほど様子を見てみましたが、無料利用の範囲内でおおむね問題なく動いております。
今度はTedみたいな勉強系の動画やらブログ記事やら拾わせても面白いかもしれませんね。
よかったこと
一気通貫して人が使えるサービスの形まで持って行くと、否応無しに広く技術をさらうことになります。インフラ寄りに苦手意識があったので半ば無理やりにでも触るのはいい経験になりました。
反省
- YouTubeAPIとか使えばもっと楽に実装できたんじゃないか疑惑
- パッケージングとAWS周りでハマりすぎた。アップロードが絡むあたりからはTry&Errorより前にドキュメントを読もう
お読みいただきありがとうございました。
ソース
[https://github.com/to-lz1/tube_searcher_bot]
(https://github.com/to-lz1/tube_searcher_bot)