6/22時点の課題
先日(6/19)発表されたAzure OpenAIのAdd your dataの機能を使うと簡単に独自データと連携できることを前回の記事で記載しました。「Upload files」を使うと手元にあるPDFをアップロードするだけで、チャンク分割からインデックス作成までワンクリックで自動実行され、GPTと連携することができます。
しかし、Add your data経由でCognitive Searchのインデックスを自動作成した場合、いくつかの課題があります。
- [検索精度] Add your data経由でインデックスを作ると、contentフィールドの言語アナライザーが英語(デフォルト)になり、Cognitive Search自身の日本語の検索精度が少し悪い。使えないことは無いけど本番化にあたってはもう少し頑張ってほしいレベル。
- [更新の自動化] Cognitive Searchにインデクサーが作成されないので、ナレッジベースを更新する際は手動でインデックスを更新する必要がある。インデクサーがあれば、データソースに対して定期的にスキャンをかけてインデックスを更新できるのだが。。。
Cognitive Searchを自分で構築すれば上記の二つの課題は解決されるのですが、インデックスの作成、インデクサーのマッピング、チャンク分割、など、Cognitive Searchに精通している人でも結構しんどい作業が待ち受けています。特にチャンク分割に関しては、生成AI流行前は需要が無かったので実装に関する情報が少ないです。
といったこともあり、何とかAdd your dataのインデックス自動作成機能だけ上手く使いたい、というモチベーションがあります。今回は1を解決するために公式が用意しているデータ準備ツールを紹介します。
データ準備ツール
公式が用意しているデータ準備ツール(リンク)の挙動は下記の通りです(ドキュメントがPDFの場合)。
- ローカルのドキュメントをForm Recognizerでテキスト化
- テキストをチャンクに分割
- 分割されたテキストをCognitive Searchのインデックスとして作成
事前にCognitive SearchとForm Recognizerを準備する必要があります。Form Recognizerのリソース作成方法はこちらをご参照ください。
Cognitive Searchのリソース作成方法はこちらをご参照ください。Cognitive Searchの価格プランですが「Basic」以上のプランでなければ、Azure OpenAI側から連携できませんのでご注意ください(Freeプランは連携不可)。
記事の開発環境は以下の通りです。
- Ubuntu 22.04 on WSL2
- python 3.10.6
事前準備として、pipのインストールとAzure CLIのインストールを実施します。
$ sudo apt-get update
$ apt install python3-pip
Ubuntuの場合このコマンドでAzure CLIをインストールできます。
curl -sL https://aka.ms/InstallAzureCLIDeb | sudo bash
データ準備ツールのレポジトリは下記です。
まずはこちらのリポジトリをローカルにクローンし、pythonライブラリをインストールします。
$ git clone https://github.com/microsoft/sample-app-aoai-chatGPT.git
$ pip install -r requirements-dev.txt
次にドキュメントをアップロードするためのフォルダを作成して、PDFファイルをフォルダにアップロードしましょう。
$ mkdir data
次にscriptsディレクトリへ移動して、config.jsonを編集します。データ準備ツールを実行すると、config.jsonに記載された設定で既存のリソースがあれば、それを利用、ない場合は新規作成、という挙動になります。
[
{
"data_path": "<path to data>",
"location": "<azure region, e.g. 'westus2'>",
"subscription_id": "<subscription id>",
"resource_group": "<resource group name>",
"search_service_name": "<search service name to use or create>",
"index_name": "<index name to use or create>",
"chunk_size": 1024, // set to null to disable chunking before ingestion
"token_overlap": 128 // number of tokens to overlap between chunks
"semantic_config_name": "default",
"language": "en" // setting to set language of your documents. Change if your documents are not in English. Look in data_preparation.py for SUPPORTED_LANGUAGE_CODES
}
]
| 項目 | 説明 | 例 |
|---|---|---|
| data_path | ドキュメントのディレクトリパス | ../../data |
| location | Cognitive Searchリソースのリージョン | japaneast |
| subscription_id | Cognitive Searchリソースのサブスクリプション | 5290deef-ab3d-4e26-90bb-2296ecd99c71 |
| resource_group | Cognitive Searchリソースのリソースグループ | cognitive-handson |
| search_service_name | Cognitive Searchリソースのリソース名 | cg-instance-115 |
| index_name | Cognitive Searchのインデックス名 | openai-doc-ja |
| chunk_size | ドキュメントを分割する際のチャンクサイズ | 1024 |
| token_overlap | 分割する際のオーバーラップ(文脈が途切れないように) | 128 |
| semantic_config_name | セマンティック検索に関する設定名(使わないのでdefaultでOK) | default |
| language | 言語アナライザーの言語。確実に変更しましょう! | ja |
Cognitive Searchの設定に関してはポータルから確認できます。

PDFをドキュメントへ変換するためにForm Recognizerを活用します。Form Recognizerの設定を確認します。

プログラムを実行する前にaz loginコマンドを実行し、AD認証を行います。
$ az login
AD認証完了後、データ準備ツールを実行します。
$ python data_preparation.py --config config.json --njobs=1 --form-rec-resource fr-instance-115 --form-rec-key XXXXXXXX
Cognitive Searchのインデックスへアクセスし、きちんとインデックスが作成されていることを確認します。
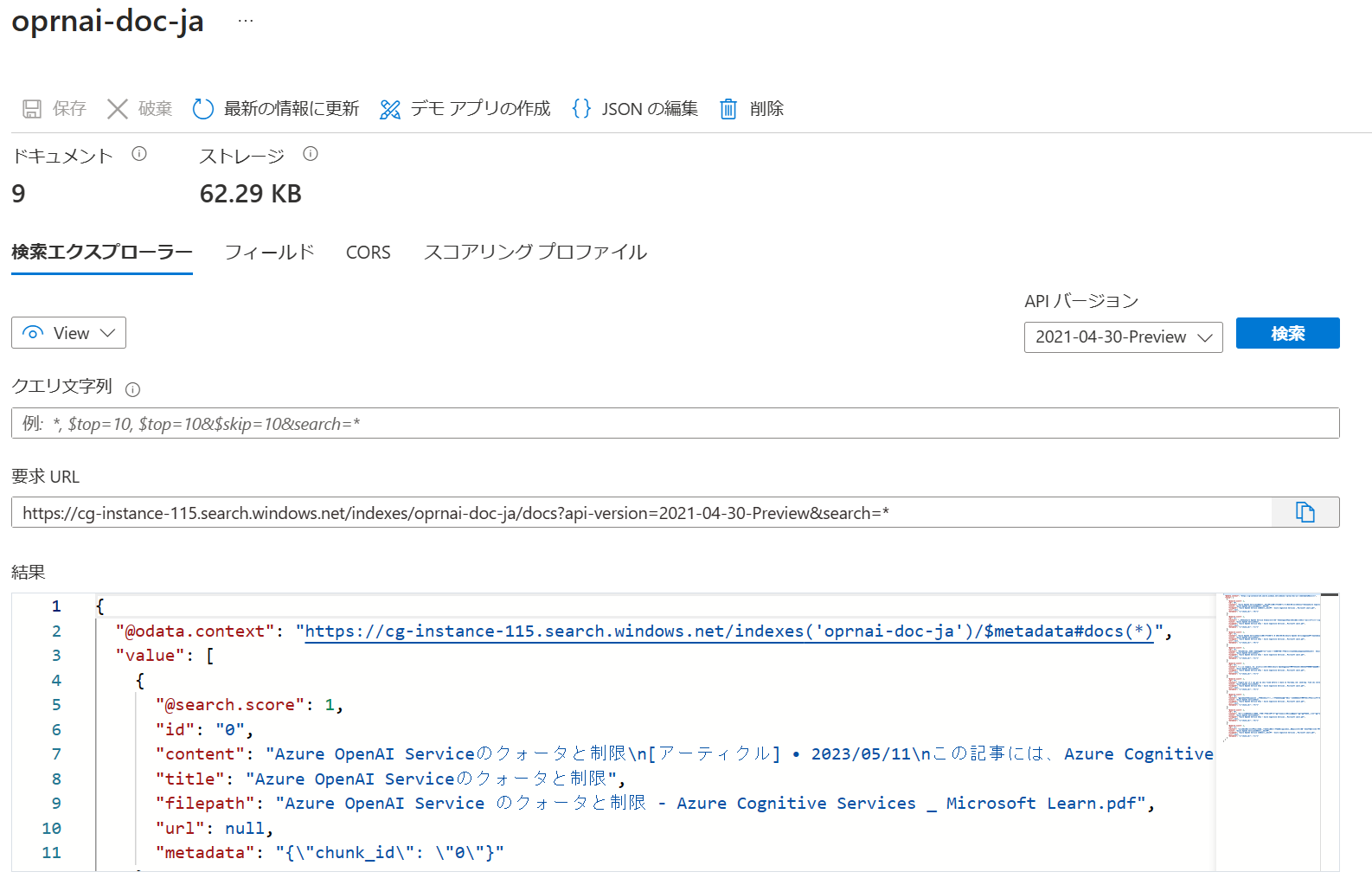
アナライザーも日本語になっていますね。

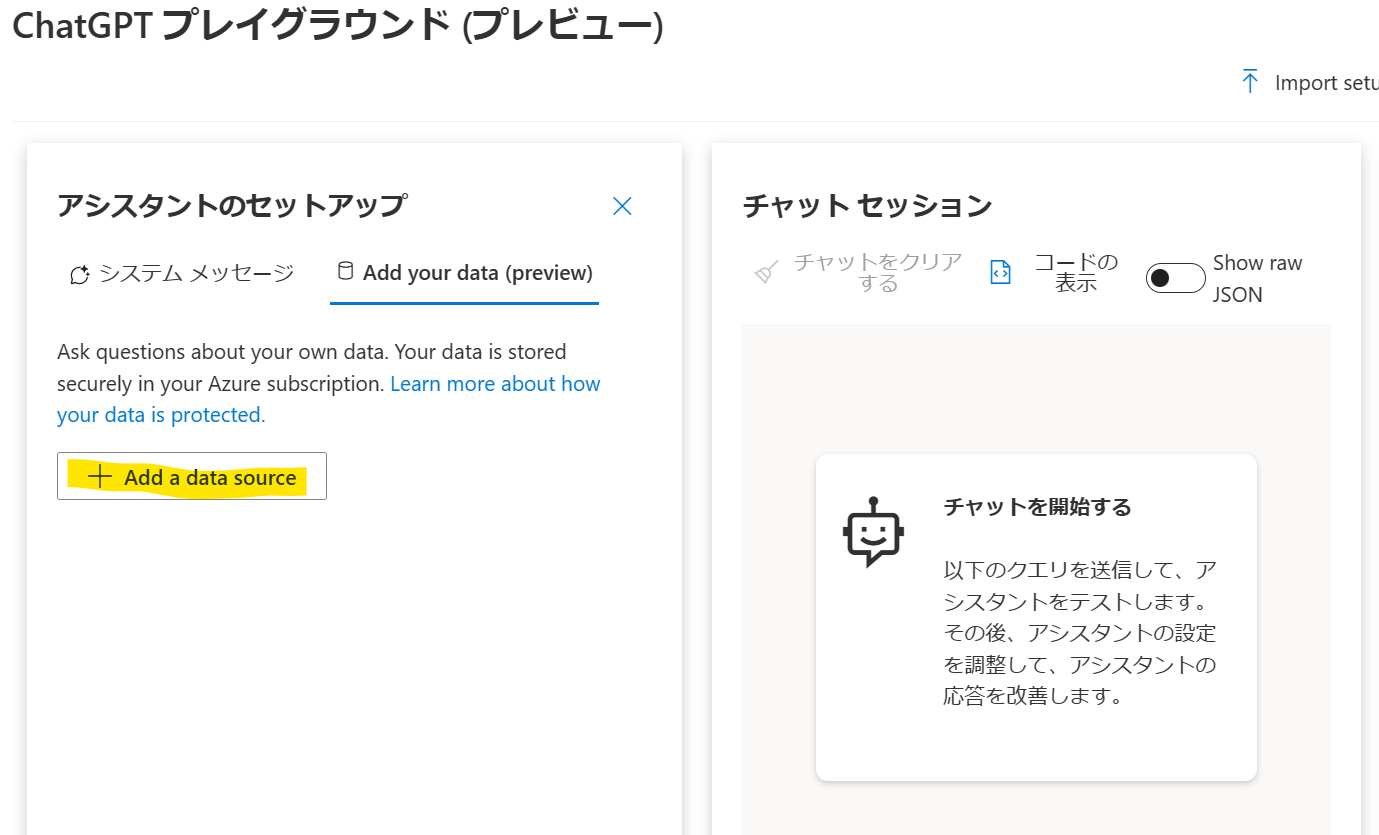
それではAdd your dataで連携してみましょう。Azure OpenAI Studioへアクセスし、[Add a data source]をクリックします。
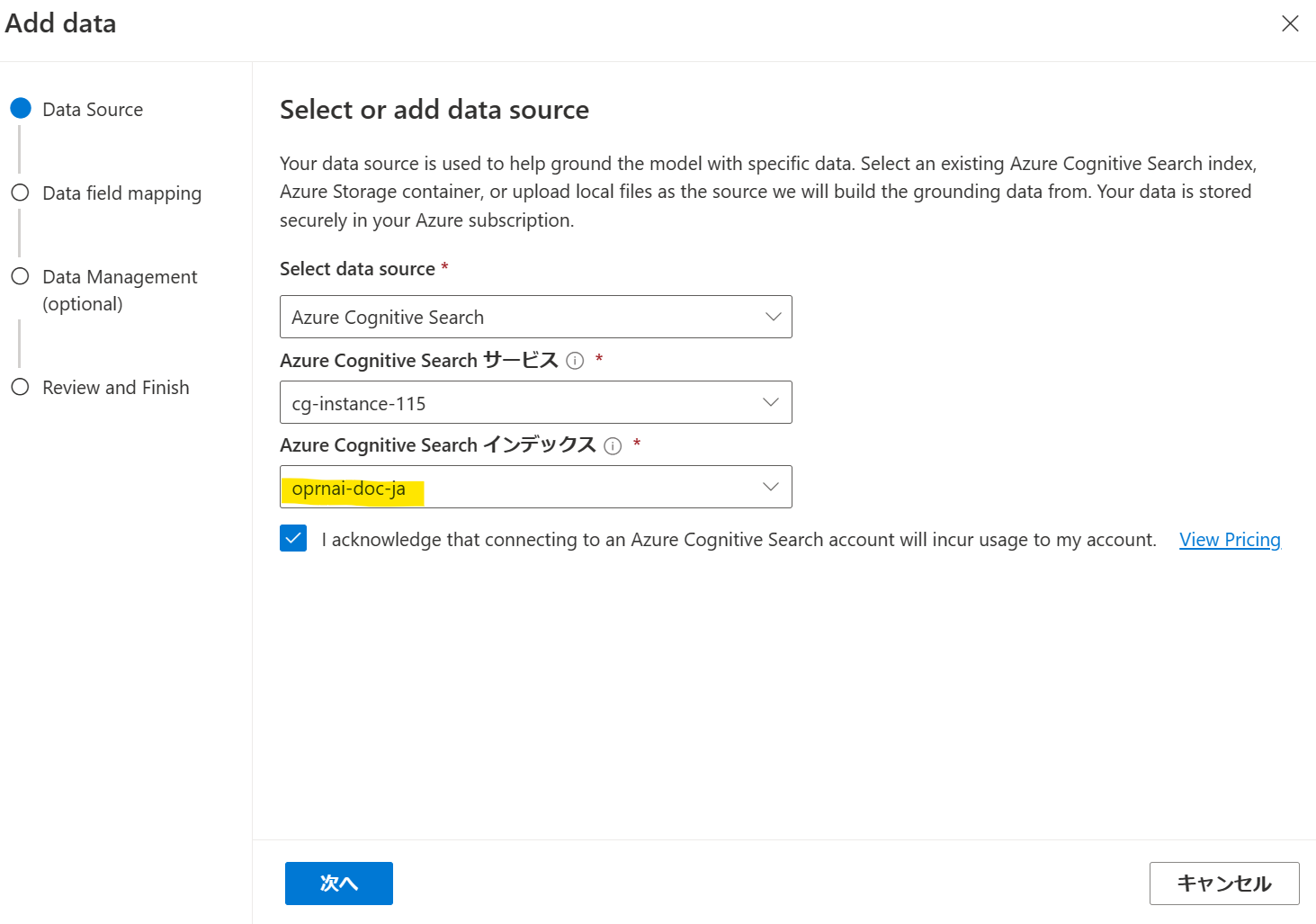
先ほど作成したインデックスを選択します。
Azure OpenAIのAPIが参照するデータ項目とCognitive Searchのインデックスのフィールドのマッピングを行います。データ準備ツールでインデックス化した場合は、データ項目とインデックスが自動で1対1になっています。
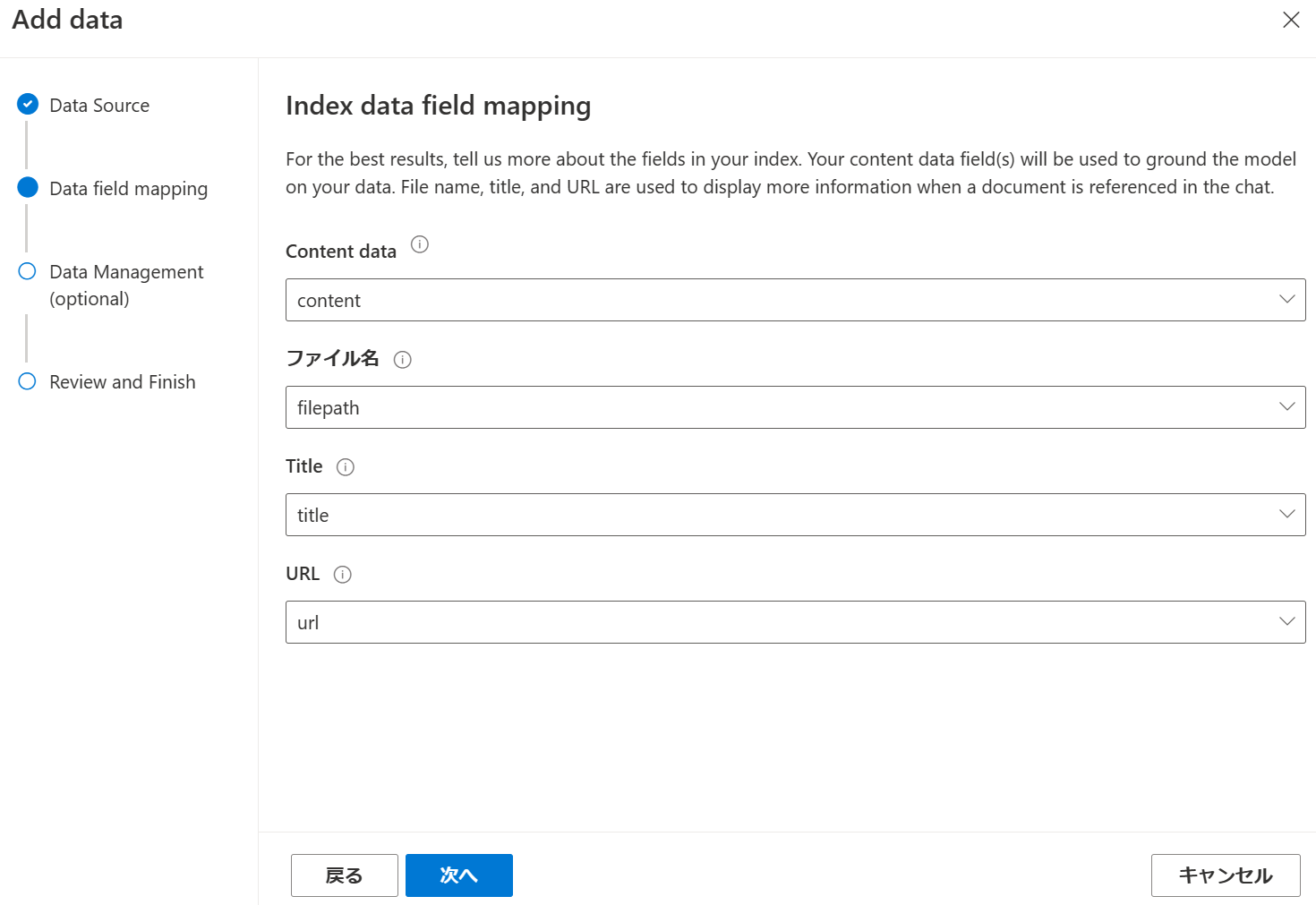
最後に保存して閉じます。

システムメッセージに日本語で考えて答えるように指示します(by公式のベストプラクティス)。
「あなたは人々が情報を見つけるのを助けるAIアシスタントです。日本語の書類を取り出したら、日本語でよく読んで、日本語で答えてください。」

公式の「Multi-lingual support」の項に書かれています。
前回の記事と同じ質問「どんなモデルがある?」をしてみましたが、今回の回答の方がしっくりきますね。GPT-4の情報も含まれています。根拠となるドキュメントも前回は微妙でしたが、今回は良い感じです。
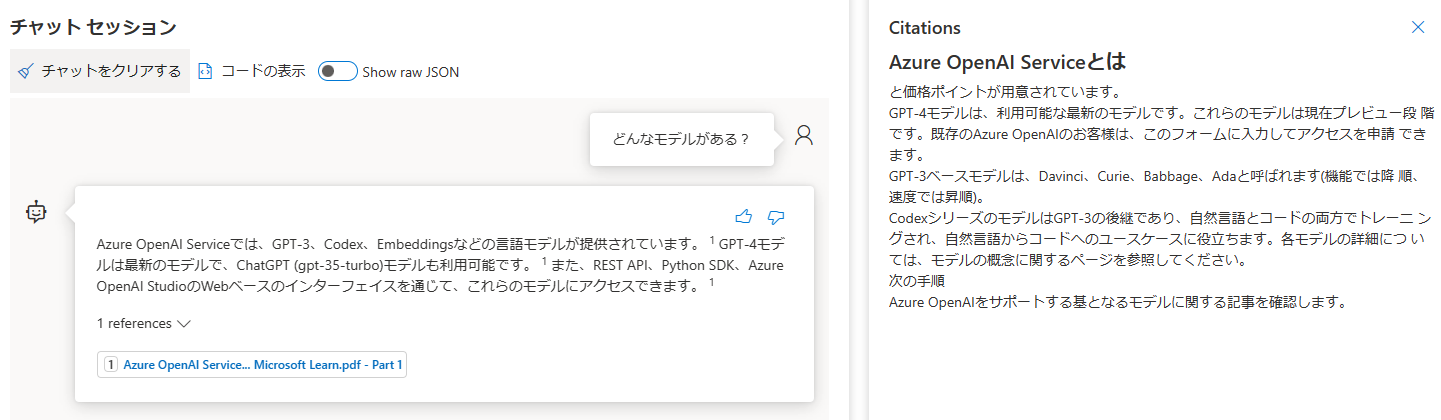
[参考]前回の記事は、言語アナライザーが英語(デフォルト)でシステムプロンプトに何も入力しませんでした。
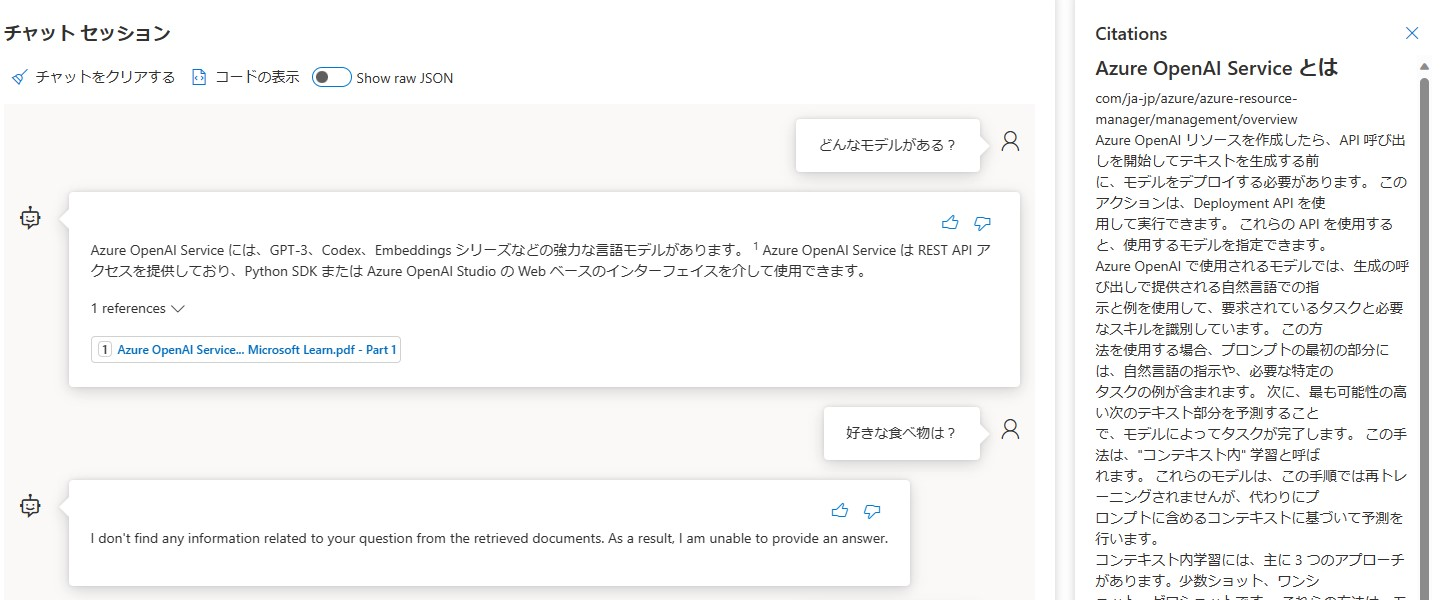
まとめ
今回は生成AI用Cognitive Searchの言語アナライザーを日本語にするために、データ準備ツールを解説しました。このツールを使うとお手軽に日本語ベースのナレッジベースが作成できます。一方で、新しくドキュメントをナレッジベースに追加したい場合は、このツールを手動実行する必要があり、めんどくさいです。検証用途としては十分使えるツールになっていると思うので、是非参考にしていただければと思います。