はじめに
前回、LangChainでCognitive SearchベクトルDBを構築する方法について解説しました。
今回は、作成したベクトルDBとGPTを連携させ、いわゆるRetrieval-Augmented Generation(RAG)を構築していきます。具体的には、LangChainのRetrievalQAを使用して実装していきます。
LangChainでQAを実装するに方法はいくつかあり、公式で分かりやすく整理されています。
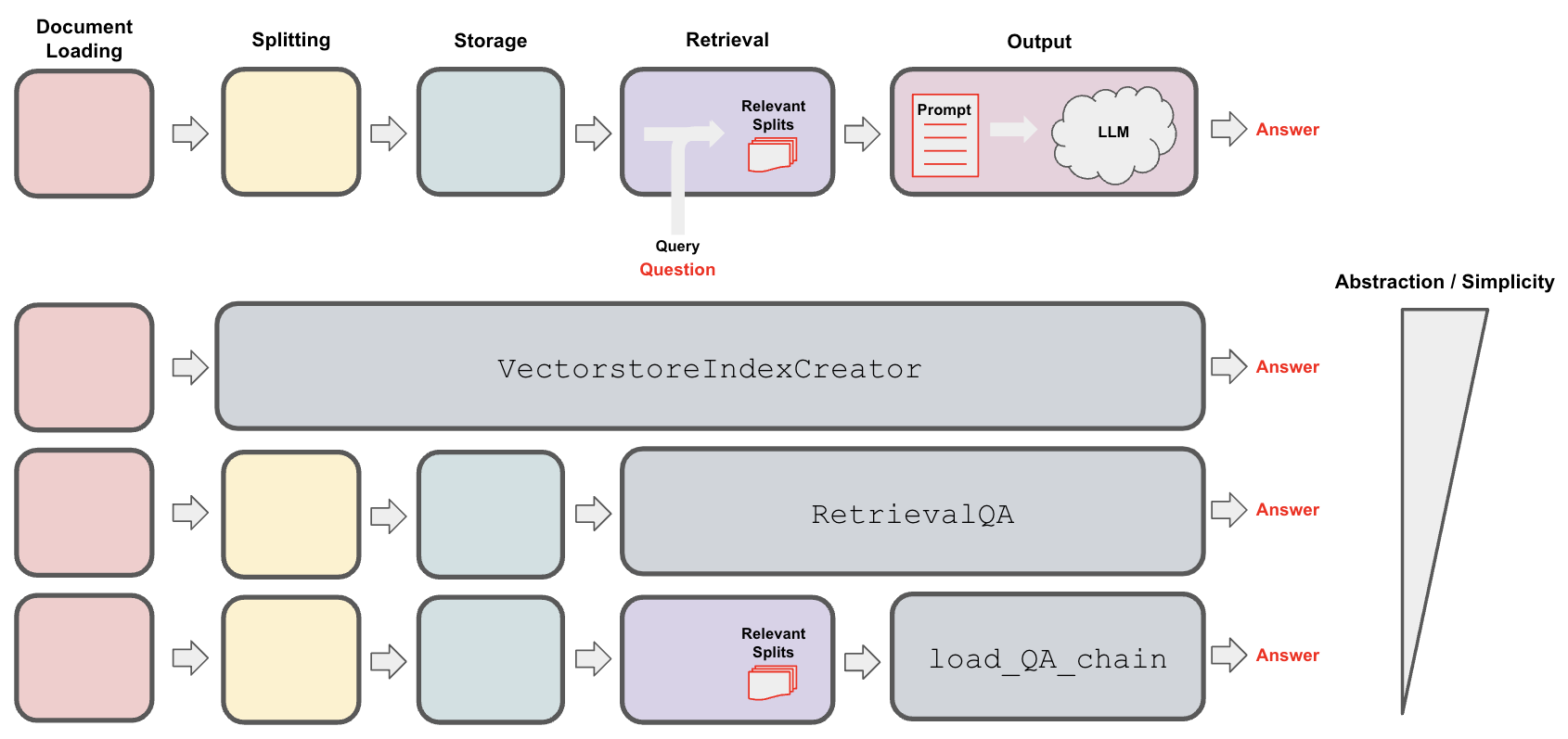
口で説明しても分かりにくい部分があるので、公式のサンプルコードを載せておきます。
VectorestoreIndexCreator
インデックス作成まで自動でやってくれ、クエリを発行するだけで簡単にRAGを構築できます。
from langchain.document_loaders import TextLoader
from langchain.indexes import VectorstoreIndexCreator
loader = TextLoader('../state_of_the_union.txt', encoding='utf8')
index = VectorstoreIndexCreator().from_loaders([loader])
query = "What did the president say about Ketanji Brown Jackson"
index.query(query)
こちらの記事でも解説しています。
RetrievalQA
Retriever(検索システム)は自前で用意し、Retrieverと連携したRAGが作れます。有名な文章検索エンジンやベクトルデータベースは、たいていlangchainのモジュールとして利用できることが多いです。今回はCognitive SearchのベクトルストアをRetrieverとして使いたいので、このRetrievalQAを使います。
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(texts, embeddings)
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
load_QA_chain
こちらはRetriever等で検索されたドキュメントそのものを引数にRAGを構築できることが特徴です。langchainの適切なRetrieverが無い場合にこちらを利用すことが多いです。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
with open("../../state_of_the_union.txt") as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(texts, embeddings, metadatas=[{"source": str(i)} for i in range(len(texts))]).as_retriever()
query = "What did the president say about Justice Breyer"
docs = docsearch.get_relevant_documents(query)
chain = load_qa_chain(OpenAI(temperature=0), chain_type="stuff")
query = "What did the president say about Justice Breyer"
chain.run(input_documents=docs, question=query)
事前準備
コードはこちらのレポジトリに置いています。
Pythonのバージョンは3.10.6で動作確認を行っています。ライブラリは下記の通りです。
ipykernel
python-dotenv
nbmake
pypdf
langchain==0.0.285
openai==0.27.8
tiktoken==0.4.0
azure-search-documents==11.4.0b8
azure-identity==1.13.0b4
LangChainのバージョンは0.0.285です。Cognitive SearchのSDKはazure-search-documents==11.4.0b8のバージョンを確実に固定してください。
環境変数の定義
環境変数を.envに定義しておきます。
AZURE_OPENAI_ENDPOINT="https://<resource-name>.openai.azure.com/"
AZURE_OPENAI_API_KEY="<api-key>"
AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME="<deploy-name>"
AZURE_OPENAI_GPT35_DEPLOYMENT_NAME="<deploy-name>"
AZURE_SEARCH_ENDPOINT="https://<service-name>.search.windows.net"
AZURE_SEARCH_SERVICE_NAME="<service-name>"
AZURE_SEARCH_API_KEY_ADMIN="<api-key-admin>"
import os
from dotenv import load_dotenv
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores.azuresearch import AzureSearch
load_dotenv()
# Azure OpenAIのエンドポイントとAPIキー
AZURE_OPENAI_ENDPOINT=os.getenv("AZURE_OPENAI_ENDPOINT")
AZURE_OPENAI_API_KEY=os.getenv("AZURE_OPENAI_API_KEY")
# Embeddingモデルのデプロイ名
AZURE_OPENAI_GPT35_DEPLOYMENT_NAME=os.getenv("AZURE_OPENAI_GPT35_DEPLOYMENT_NAME")
AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME=os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME")
# Azure SearchのエンドポイントとAPIキー
AZURE_SEARCH_ENDPOINT=os.getenv("AZURE_SEARCH_ENDPOINT")
AZURE_SEARCH_SERVICE_NAME=os.getenv("AZURE_SEARCH_SERVICE_NAME")
AZURE_SEARCH_API_KEY_ADMIN=os.getenv("AZURE_SEARCH_API_KEY_ADMIN")
ベクトル検索
Embeddingモデルを定義し、前回の記事でCognitive Searchのベクトルストアを定義します。試しにベクトル検索を実行してみましょう。
# emmbeddingモデルを定義
embeddings = OpenAIEmbeddings(
openai_api_type="azure",
model='text-embedding-ada-002',
openai_api_base=AZURE_OPENAI_ENDPOINT,
openai_api_key=AZURE_OPENAI_API_KEY,
deployment=AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME)
# インデックス名
index_name = "fixed-sample-index"
# ベクトルストアを作成
vector_store = AzureSearch(
azure_search_endpoint=AZURE_SEARCH_ENDPOINT,
azure_search_key=AZURE_SEARCH_API_KEY_ADMIN,
index_name=index_name,
embedding_function=embeddings.embed_query
)
# ベクトル検索
result_docs = vector_store.similarity_search(
query="Azure OpenAIで使えるモデルを教えて",
k=3,
search_type="similarity"
)
# 結果を表示
for doc in result_docs:
print(doc.json(indent=2, ensure_ascii=False))
ベクトル検索ができていることを確認できました。
{
"page_content": "Azure OpenAI Service とは\n[アーティクル ]•2023/05/01\nAzure OpenAI Service では、 GPT-3 、 Codex 、 Embeddings モデル シリーズなど\nOpenAI の強⼒な⾔語モデルを REST API として使⽤できます。 さらに、新しい GPT-4\nおよび ChatGPT (gpt-35-turbo) モデル シリーズがプレビューで利⽤可能になりまし\nた。 これらのモデルは、特定のタスクに合わせて簡単に調整できます。たとえば、コ\nンテンツの⽣成、まとめ、セマンティック検索、⾃然⾔語からコードへの翻訳などで\nす。 ユーザーは、 REST API 、 Python SDK 、または Azure OpenAI S tudio の Web ベース\nのインターフェイスを介してサービスにアクセスできます。\n機能 Azur e OpenAI\n使⽤できるモデル 新しい GPT-4 シリーズ ( プレビュー )\nGPT-3 ベース シリーズ\n新しい ChatGPT (gpt -35-turbo) ( プレビュー )\nCodex シリーズ\n埋め込みシリーズ\n詳細については、 モデルに関するページを参照してください。\n微調整 Ada\nBabbage\nCurie\nCushman*\nDavinci*\n* 現在は利⽤できません。 ** ⽶国東部と⻄ヨーロッパでは、現在新\n規のお客様は微調整を利⽤できません。 ⽶国ベースのトレーニング\nには、⽶国中南部をご利⽤ください\nPrice こちらで⼊⼿可能\n仮想ネットワークのサポ\nート & プライベート リン\nクのサポートはい\nマネージド ID はい、 Azure Active Directory 経由\nUI エクスペリエンス アカウントとリソースの管理には Azur e Portal、\nモデルの探索と微調整には Azur e OpenAI Ser vice S tudio\nリージョン別の提供状況 ⽶国東部\n⽶国中南部\n⻄ヨーロッパ機能の概要",
"metadata": {
"source": "../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf",
"page": 0
}
}
{
"page_content": "Azure OpenAI を使⽤すると、顧客は OpenAI と同じモデルを実⾏しながら、 Microsoft\nAzure のセキュリティ機能を使⽤できます。 Azure OpenAI では、プライベート ネット\nワーク、リージョンの可⽤性、責任ある AI コンテンツのフィルター処理が提供されま\nす。\n⼊⼒候補エンドポイントは、 API サービスのコア コンポーネントです。 この API は、\nモデルのテキストイン、テキストアウト インターフェイスへのアクセスを提供しま\nす。 ユーザーは、英語のテキスト コマンドを含む⼊⼒ プロンプトを⼊⼒するだけで、\nモデルによってテキスト ⼊⼒候補が⽣成されます。\n単純なプロンプトと⼊⼒候補の例を次に⽰します。\nプロンプト : \"\"\" count to 5 in a for loop \"\"\"\n⼊⼒候補 : for i in range(1, 6): print(i)\nAzure OpenAI では、テキストをトークンに分割して処理します。 トークンには、単語\nまたは⽂字のチャンクのみを指定できます。 たとえば、 \"hamburger\" という単語はト\nークン \"ham\"、 \"bur\" 、 \"ger\" に分割されますが、 \"pear\" のような短くて⼀般的な単語\nは 1 つのトークンです。 多くのトークンは、 \"hello\" や \"bye\" などの空⽩で始まりま\nす。\n所与の要求で処理されるトークンの合計数は、⼊⼒、出⼒、および要求パラメーター\nの⻑さによって異なります。 処理されるトークンの量は、モデルの応答待機時間とス\nループットにも影響します。\nAzure OpenAI は、 Azure の新しい製品オファリングです。 Azure OpenAI は、他の\nAzure 製品と同じように、 Azure サブスクリプションにこのサービス⽤の リソースまた\nはインスタンスを作成 して使⽤を開始できます。 Azure のリソース管理設計 について\n詳しくご覧いただけます。主要な概念\nプロンプトと⼊⼒候補\nトークン\nリソース\nデプロイメント",
"metadata": {
"source": "../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf",
"page": 2
}
}
{
"page_content": "機能 Azur e OpenAI\nコンテンツのフィルター\n処理プロンプトと⼊⼒候補は、⾃動システムを使ってコンテンツ ポリシ\nーに対して評価されます。 重⼤度の⾼いコンテンツはフィルターで\n除外されます。\nMicrosoft は、⼈を第⼀に考える原則に基づいて、 AI の発展に取り組んでいます。\nAzure OpenAI で使⽤できる⽣成モデルには、かなりの潜在的利益がありますが、慎重\nな設計と熟考した軽減策がない場合、そのようなモデルによって、正しくない、また\nは有害なコンテンツが⽣成される可能性があります。 Microsoft は、悪⽤や意図しない\n損害から保護するために多⼤な投資を⾏っています。たとえば、明確に定義したユー\nス ケースを⽰すことを申請者の要件とする、 責任ある AI 使⽤に関する Microsoft の原\n則を取り⼊れる、顧客をサポートするコンテンツ フィルターを構築する、オンボー\nドされた顧客に対して責任ある AI 実装のガイダンスを提供するなどです。\nAzure OpenAI にアクセスするにはどうすればよいですか ?\n⾼い需要、今後の製品の機能強化、 Microsoft の責任ある AI へのコミットメント を\n考慮し、現在、アクセスは制限されています。 現在のところ、 Microsoft と既存のパー\nトナーシップ関係があるお客様、リスクの低いユース ケース、軽減策の取り⼊れに取\nり組んでいるお客様を対象としています。\nより具体的な情報は、申請フォームに記載されています。 Azure OpenAI に対するアク\nセスを拡⼤できるよう、責任を持って取り組んでいますので、しばらくお待ちくださ\nい。\nアクセスはこちらからお申し込みください。\n[今すぐ適⽤する ]\nAzure OpenAI Service では、 OpenAI GPT-4 、 GPT-3 、 Codex 、 DALL-E モデルを使⽤し\nた⾼度な⾔語 AI を顧客に提供し、 Azure のセキュリティとエンタープライズの約束を\n実現します。 Azure OpenAI は OpenAI と共に API を共同開発し、互換性を確保し、⼀\n⽅から他⽅へのスムーズな移⾏を保証します。責任ある AI\nAzure OpenAI にアクセスするにはどうすれば\nよいですか ?\nAzure OpenAI と OpenAI の⽐較",
"metadata": {
"source": "../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf",
"page": 1
}
}
RetrievalQA
Azure OpenAIのチャットモデルを定義し、RetrievalQAチェーンを定義します。RetrievalQAでベクトルストアを利用したい場合は、as_retriever()のメソッドを呼び出してRetrievalクラスに変換する必要があります。それではQAチェーンを実行してみましょう。
from langchain.chains import RetrievalQA
from langchain.chat_models import AzureChatOpenAI
# チャットモデルを定義
chat = AzureChatOpenAI(
openai_api_type="azure",
model_name="gpt-3.5-turbo",
openai_api_version="2023-07-01-preview",
openai_api_base=AZURE_OPENAI_ENDPOINT,
deployment_name=AZURE_OPENAI_GPT35_DEPLOYMENT_NAME,
openai_api_key=AZURE_OPENAI_API_KEY,
temperature=0
)
# RetrievalQAチェーンを定義
qa_chain = RetrievalQA.from_chain_type(
llm=chat,
retriever=vector_store.as_retriever(), # 指定しなければ k=4/serarch_type=simirality
return_source_documents=True
)
# QAを実行
result = qa_chain({"query": "Azure OpenAIで使えるモデルを教えて"})
display(result)
結果はresultフィールドに格納されています。回答の根拠はsource_documentsに格納されています。
{'query': 'Azure OpenAIで使えるモデルを教えて',
'result': 'Azure OpenAIで利用できるモデルは以下の通りです:\n\n- GPT-4シリーズ(プレビュー)\n- GPT-3ベースシリーズ(Davinci、Curie、Babbage、Ada)\n- ChatGPT(gpt-35-turbo)シリーズ(プレビュー)\n- Codexシリーズ\n- Embeddingsシリーズ\n\nただし、一部のモデル(Cushman、Davinci)は現在利用できません。また、新規のお客様は一部の地域(米国東部、西ヨーロッパ)では微調整を利用できません。詳細については、Azure OpenAIのモデルに関するページを参照してください。',
'source_documents': [Document(page_content='Azure OpenAI Service とは\n[アーティクル ]•2023/05/01\nAzure OpenAI Service では、 GPT-3 、 Codex 、 Embeddings モデル シリーズなど\nOpenAI の強⼒な⾔語モデルを REST API として使⽤できます。 さらに、新しい GPT-4\nおよび ChatGPT (gpt-35-turbo) モデル シリーズがプレビューで利⽤可能になりまし\nた。 これらのモデルは、特定のタスクに合わせて簡単に調整できます。たとえば、コ\nンテンツの⽣成、まとめ、セマンティック検索、⾃然⾔語からコードへの翻訳などで\nす。 ユーザーは、 REST API 、 Python SDK 、または Azure OpenAI S tudio の Web ベース\nのインターフェイスを介してサービスにアクセスできます。\n機能 Azur e OpenAI\n使⽤できるモデル 新しい GPT-4 シリーズ ( プレビュー )\nGPT-3 ベース シリーズ\n新しい ChatGPT (gpt -35-turbo) ( プレビュー )\nCodex シリーズ\n埋め込みシリーズ\n詳細については、 モデルに関するページを参照してください。\n微調整 Ada\nBabbage\nCurie\nCushman*\nDavinci*\n* 現在は利⽤できません。 ** ⽶国東部と⻄ヨーロッパでは、現在新\n規のお客様は微調整を利⽤できません。 ⽶国ベースのトレーニング\nには、⽶国中南部をご利⽤ください\nPrice こちらで⼊⼿可能\n仮想ネットワークのサポ\nート & プライベート リン\nクのサポートはい\nマネージド ID はい、 Azure Active Directory 経由\nUI エクスペリエンス アカウントとリソースの管理には Azur e Portal、\nモデルの探索と微調整には Azur e OpenAI Ser vice S tudio\nリージョン別の提供状況 ⽶国東部\n⽶国中南部\n⻄ヨーロッパ機能の概要', metadata={'source': '../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf', 'page': 0}),
Document(page_content='機能 Azur e OpenAI\nコンテンツのフィルター\n処理プロンプトと⼊⼒候補は、⾃動システムを使ってコンテンツ ポリシ\nーに対して評価されます。 重⼤度の⾼いコンテンツはフィルターで\n除外されます。\nMicrosoft は、⼈を第⼀に考える原則に基づいて、 AI の発展に取り組んでいます。\nAzure OpenAI で使⽤できる⽣成モデルには、かなりの潜在的利益がありますが、慎重\nな設計と熟考した軽減策がない場合、そのようなモデルによって、正しくない、また\nは有害なコンテンツが⽣成される可能性があります。 Microsoft は、悪⽤や意図しない\n損害から保護するために多⼤な投資を⾏っています。たとえば、明確に定義したユー\nス ケースを⽰すことを申請者の要件とする、 責任ある AI 使⽤に関する Microsoft の原\n則を取り⼊れる、顧客をサポートするコンテンツ フィルターを構築する、オンボー\nドされた顧客に対して責任ある AI 実装のガイダンスを提供するなどです。\nAzure OpenAI にアクセスするにはどうすればよいですか ?\n⾼い需要、今後の製品の機能強化、 Microsoft の責任ある AI へのコミットメント を\n考慮し、現在、アクセスは制限されています。 現在のところ、 Microsoft と既存のパー\nトナーシップ関係があるお客様、リスクの低いユース ケース、軽減策の取り⼊れに取\nり組んでいるお客様を対象としています。\nより具体的な情報は、申請フォームに記載されています。 Azure OpenAI に対するアク\nセスを拡⼤できるよう、責任を持って取り組んでいますので、しばらくお待ちくださ\nい。\nアクセスはこちらからお申し込みください。\n[今すぐ適⽤する ]\nAzure OpenAI Service では、 OpenAI GPT-4 、 GPT-3 、 Codex 、 DALL-E モデルを使⽤し\nた⾼度な⾔語 AI を顧客に提供し、 Azure のセキュリティとエンタープライズの約束を\n実現します。 Azure OpenAI は OpenAI と共に API を共同開発し、互換性を確保し、⼀\n⽅から他⽅へのスムーズな移⾏を保証します。責任ある AI\nAzure OpenAI にアクセスするにはどうすれば\nよいですか ?\nAzure OpenAI と OpenAI の⽐較', metadata={'source': '../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf', 'page': 1}),
Document(page_content='Azure OpenAI を使⽤すると、顧客は OpenAI と同じモデルを実⾏しながら、 Microsoft\nAzure のセキュリティ機能を使⽤できます。 Azure OpenAI では、プライベート ネット\nワーク、リージョンの可⽤性、責任ある AI コンテンツのフィルター処理が提供されま\nす。\n⼊⼒候補エンドポイントは、 API サービスのコア コンポーネントです。 この API は、\nモデルのテキストイン、テキストアウト インターフェイスへのアクセスを提供しま\nす。 ユーザーは、英語のテキスト コマンドを含む⼊⼒ プロンプトを⼊⼒するだけで、\nモデルによってテキスト ⼊⼒候補が⽣成されます。\n単純なプロンプトと⼊⼒候補の例を次に⽰します。\nプロンプト : """ count to 5 in a for loop """\n⼊⼒候補 : for i in range(1, 6): print(i)\nAzure OpenAI では、テキストをトークンに分割して処理します。 トークンには、単語\nまたは⽂字のチャンクのみを指定できます。 たとえば、 "hamburger" という単語はト\nークン "ham"、 "bur" 、 "ger" に分割されますが、 "pear" のような短くて⼀般的な単語\nは 1 つのトークンです。 多くのトークンは、 "hello" や "bye" などの空⽩で始まりま\nす。\n所与の要求で処理されるトークンの合計数は、⼊⼒、出⼒、および要求パラメーター\nの⻑さによって異なります。 処理されるトークンの量は、モデルの応答待機時間とス\nループットにも影響します。\nAzure OpenAI は、 Azure の新しい製品オファリングです。 Azure OpenAI は、他の\nAzure 製品と同じように、 Azure サブスクリプションにこのサービス⽤の リソースまた\nはインスタンスを作成 して使⽤を開始できます。 Azure のリソース管理設計 について\n詳しくご覧いただけます。主要な概念\nプロンプトと⼊⼒候補\nトークン\nリソース\nデプロイメント', metadata={'source': '../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf', 'page': 2}),
Document(page_content='通常、 1 つのプロンプトの最⼤⼊⼒⻑に収まる数に応じて、例の数は 0 から 100 の範\n囲です。 最⼤⼊⼒⻑は、使⽤する特定のモデルによって異なる場合があります。 少数\nショット学習を使⽤すると、正確な予測に必要なタスク固有のデータの量を⼤幅に削\n減できます。 このアプローチは、通常、微調整されたモデルよりもパフォーマンスは\n正確ではありません。\nワンショット : この場合は、 1 つの例のみが提供されることを除き、少数ショットの⽅\n法と同じです。\nゼロショット : この場合、モデルに例は提供されず、タスク要求のみが提供されます。\nこのサービスでは、ユーザーはいくつかのモデルにアクセスできます。 各モデルに\nは、異なる機能と価格ポイントが⽤意されています。\nGPT-4 モデルは、利⽤可能な最新のモデルです。 これらのモデルは現在プレビュー段\n階です。 既存の Azure OpenAI のお客様は、このフォームに⼊⼒してアクセスを申請\nできます。\nGPT-3 ベース モデルは、 Davinci 、 Curie 、 Babbage 、 Ada と呼ばれます ( 機能では降\n順、速度では昇順 ) 。\nCodex シリーズのモデルは GPT-3 の後継であり、⾃然⾔語とコードの両⽅でトレーニ\nングされ、⾃然⾔語からコードへのユース ケースに役⽴ちます。 各モデルの詳細につ\nいては、モデルの概念に関するページ を参照してください。\nAzure OpenAI をサポートする基となるモデル に関する記事を確認します。モデル\n次の⼿順', metadata={'source': '../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf', 'page': 4})]}
Azure OpenAIで利用できるモデルは以下の通りです:
- GPT-4シリーズ(プレビュー)
- GPT-3ベースシリーズ(Davinci、Curie、Babbage、Ada)
- ChatGPT(gpt-35-turbo)シリーズ(プレビュー)
- Codexシリーズ
- Embeddingsシリーズ
ただし、一部のモデル(Cushman、Davinci)は現在利用できません。また、新規のお客様は一部の地域(米国東部、西ヨーロッパ)では微調整を利用できません。詳細については、Azure OpenAIのモデルに関するページを参照してください。
ベクトル検索のパラメータ変更
as_retriever()の引数を指定することで、Cognitive Searchのハイブリッド検索やセマンティック・ハイブリッド検索に切り替えることができます。どのように指定するかは、ソースコードを読み解くしかないのですが、必要な部分を引用しておきます。
def similarity_search(
self, query: str, k: int = 4, **kwargs: Any
) -> List[Document]:
search_type = kwargs.get("search_type", self.search_type)
if search_type == "similarity":
docs = self.vector_search(query, k=k, **kwargs)
elif search_type == "hybrid":
docs = self.hybrid_search(query, k=k, **kwargs)
elif search_type == "semantic_hybrid":
docs = self.semantic_hybrid_search(query, k=k, **kwargs)
else:
raise ValueError(f"search_type of {search_type} not allowed.")
return docs
実際にas_retriever()の引数でハイブリッド検索、k=1を指定してQAチェーンを実行してみます。
# ベクトル検索のパラメータを変更
qa_chain = RetrievalQA.from_chain_type(
llm=chat,
retriever=vector_store.as_retriever(search_kwargs={'k': 1, 'search_type': 'hybrid'}),
return_source_documents=True
)
result = qa_chain({"query": "Azure OpenAIで使えるモデルを教えて"})
display(result)
{'query': 'Azure OpenAIで使えるモデルを教えて',
'result': 'Azure OpenAI Serviceでは、以下のモデルが利用可能です。\n\n- GPT-4シリーズ(プレビュー)\n- GPT-3ベースシリーズ\n- ChatGPT(gpt-35-turbo)(プレビュー)\n- Codexシリーズ\n- 埋め込みシリーズ\n\nただし、一部のモデル(Cushman、Davinci)は現在利用できません。また、一部の地域(米国東部、西ヨーロッパ)では新規のお客様は微調整を利用できません。詳細な情報は、Azure OpenAI Serviceのモデルに関するページを参照してください。',
'source_documents': [Document(page_content='Azure OpenAI Service とは\n[アーティクル ]•2023/05/01\nAzure OpenAI Service では、 GPT-3 、 Codex 、 Embeddings モデル シリーズなど\nOpenAI の強⼒な⾔語モデルを REST API として使⽤できます。 さらに、新しい GPT-4\nおよび ChatGPT (gpt-35-turbo) モデル シリーズがプレビューで利⽤可能になりまし\nた。 これらのモデルは、特定のタスクに合わせて簡単に調整できます。たとえば、コ\nンテンツの⽣成、まとめ、セマンティック検索、⾃然⾔語からコードへの翻訳などで\nす。 ユーザーは、 REST API 、 Python SDK 、または Azure OpenAI S tudio の Web ベース\nのインターフェイスを介してサービスにアクセスできます。\n機能 Azur e OpenAI\n使⽤できるモデル 新しい GPT-4 シリーズ ( プレビュー )\nGPT-3 ベース シリーズ\n新しい ChatGPT (gpt -35-turbo) ( プレビュー )\nCodex シリーズ\n埋め込みシリーズ\n詳細については、 モデルに関するページを参照してください。\n微調整 Ada\nBabbage\nCurie\nCushman*\nDavinci*\n* 現在は利⽤できません。 ** ⽶国東部と⻄ヨーロッパでは、現在新\n規のお客様は微調整を利⽤できません。 ⽶国ベースのトレーニング\nには、⽶国中南部をご利⽤ください\nPrice こちらで⼊⼿可能\n仮想ネットワークのサポ\nート & プライベート リン\nクのサポートはい\nマネージド ID はい、 Azure Active Directory 経由\nUI エクスペリエンス アカウントとリソースの管理には Azur e Portal、\nモデルの探索と微調整には Azur e OpenAI Ser vice S tudio\nリージョン別の提供状況 ⽶国東部\n⽶国中南部\n⻄ヨーロッパ機能の概要', metadata={'source': '../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf', 'page': 0})]}
カスタムRetriever
ここまでベクトルストアをRetrievalに変換して、QAチェーンを作ってきましたが、ソースドキュメントに検索スコアがついていません。このあたりをカスタマイズするために、BaseRetrieverクラスを継承してカスタムのRetrieverを作成します。BaseRetrieverクラスに関しては、公式に記載されていますが、get_relevant_documents()メソッドをオバーライドすることで、自由にRetrieverをカスタマイズできます。
AzureSearchのvector_search_with_score()メソッドを実行すると、検索スコアを取得できるのですが、Documentクラスの中に含まれていないので、取り回しが悪いです。Documentのメタデータに検索スコアを格納するようにコードを書いています。
from langchain.schema.retriever import BaseRetriever, Document
class CustomRetriever(BaseRetriever):
from langchain.vectorstores import VectorStore
from typing import List
vectorstore: VectorStore
search_type: str = "vector"
top_k: int = 3
def get_relevant_documents(self, query: str) -> List[Document]:
if self.search_type == "vector":
_docs = self.vectorstore.vector_search_with_score(query=query, k=self.top_k)
elif self.search_type == "hybrid":
_docs = self.vectorstore.hybrid_search_with_score(query=query, k=self.top_k)
else:
raise ValueError(f"search_type of {self.search_type} not allowed.")
# Documentのメタデータにスコアを追加
docs = []
for _doc in _docs:
doc: Document = _doc[0]
score: float = _doc[1]
doc.metadata["@search.score"] = score
docs.append(doc)
return docs
custom_retriever = CustomRetriever(vectorstore=vector_store, search_type="hybrid", top_k=3)
qa_chain = RetrievalQA.from_chain_type(
llm=chat,
retriever=custom_retriever,
return_source_documents=True
)
result = qa_chain({"query": "Azure OpenAIで使えるモデルを教えて"})
display(result)
{'query': 'Azure OpenAIで使えるモデルを教えて',
'result': 'Azure OpenAI Serviceでは、以下のモデルが利用可能です。\n\n- GPT-3ベースシリーズ\n- 新しいGPT-4シリーズ(プレビュー)\n- 新しいChatGPT(gpt-35-turbo)(プレビュー)\n- Codexシリーズ\n- 埋め込みシリーズ\n\nただし、一部のモデル(Cushman、Davinci)は現在利用できません。また、一部の地域(米国東部、西ヨーロッパ)では新規のお客様は微調整を利用できません。詳細については、モデルに関するページを参照してください。',
'source_documents': [Document(page_content='Azure OpenAI Service とは\n[アーティクル ]•2023/05/01\nAzure OpenAI Service では、 GPT-3 、 Codex 、 Embeddings モデル シリーズなど\nOpenAI の強⼒な⾔語モデルを REST API として使⽤できます。 さらに、新しい GPT-4\nおよび ChatGPT (gpt-35-turbo) モデル シリーズがプレビューで利⽤可能になりまし\nた。 これらのモデルは、特定のタスクに合わせて簡単に調整できます。たとえば、コ\nンテンツの⽣成、まとめ、セマンティック検索、⾃然⾔語からコードへの翻訳などで\nす。 ユーザーは、 REST API 、 Python SDK 、または Azure OpenAI S tudio の Web ベース\nのインターフェイスを介してサービスにアクセスできます。\n機能 Azur e OpenAI\n使⽤できるモデル 新しい GPT-4 シリーズ ( プレビュー )\nGPT-3 ベース シリーズ\n新しい ChatGPT (gpt -35-turbo) ( プレビュー )\nCodex シリーズ\n埋め込みシリーズ\n詳細については、 モデルに関するページを参照してください。\n微調整 Ada\nBabbage\nCurie\nCushman*\nDavinci*\n* 現在は利⽤できません。 ** ⽶国東部と⻄ヨーロッパでは、現在新\n規のお客様は微調整を利⽤できません。 ⽶国ベースのトレーニング\nには、⽶国中南部をご利⽤ください\nPrice こちらで⼊⼿可能\n仮想ネットワークのサポ\nート & プライベート リン\nクのサポートはい\nマネージド ID はい、 Azure Active Directory 経由\nUI エクスペリエンス アカウントとリソースの管理には Azur e Portal、\nモデルの探索と微調整には Azur e OpenAI Ser vice S tudio\nリージョン別の提供状況 ⽶国東部\n⽶国中南部\n⻄ヨーロッパ機能の概要', metadata={'source': '../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf', 'page': 0, '@search.score': 0.03279569745063782}),
Document(page_content='機能 Azur e OpenAI\nコンテンツのフィルター\n処理プロンプトと⼊⼒候補は、⾃動システムを使ってコンテンツ ポリシ\nーに対して評価されます。 重⼤度の⾼いコンテンツはフィルターで\n除外されます。\nMicrosoft は、⼈を第⼀に考える原則に基づいて、 AI の発展に取り組んでいます。\nAzure OpenAI で使⽤できる⽣成モデルには、かなりの潜在的利益がありますが、慎重\nな設計と熟考した軽減策がない場合、そのようなモデルによって、正しくない、また\nは有害なコンテンツが⽣成される可能性があります。 Microsoft は、悪⽤や意図しない\n損害から保護するために多⼤な投資を⾏っています。たとえば、明確に定義したユー\nス ケースを⽰すことを申請者の要件とする、 責任ある AI 使⽤に関する Microsoft の原\n則を取り⼊れる、顧客をサポートするコンテンツ フィルターを構築する、オンボー\nドされた顧客に対して責任ある AI 実装のガイダンスを提供するなどです。\nAzure OpenAI にアクセスするにはどうすればよいですか ?\n⾼い需要、今後の製品の機能強化、 Microsoft の責任ある AI へのコミットメント を\n考慮し、現在、アクセスは制限されています。 現在のところ、 Microsoft と既存のパー\nトナーシップ関係があるお客様、リスクの低いユース ケース、軽減策の取り⼊れに取\nり組んでいるお客様を対象としています。\nより具体的な情報は、申請フォームに記載されています。 Azure OpenAI に対するアク\nセスを拡⼤できるよう、責任を持って取り組んでいますので、しばらくお待ちくださ\nい。\nアクセスはこちらからお申し込みください。\n[今すぐ適⽤する ]\nAzure OpenAI Service では、 OpenAI GPT-4 、 GPT-3 、 Codex 、 DALL-E モデルを使⽤し\nた⾼度な⾔語 AI を顧客に提供し、 Azure のセキュリティとエンタープライズの約束を\n実現します。 Azure OpenAI は OpenAI と共に API を共同開発し、互換性を確保し、⼀\n⽅から他⽅へのスムーズな移⾏を保証します。責任ある AI\nAzure OpenAI にアクセスするにはどうすれば\nよいですか ?\nAzure OpenAI と OpenAI の⽐較', metadata={'source': '../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf', 'page': 1, '@search.score': 0.03279569745063782}),
Document(page_content='Azure OpenAI を使⽤すると、顧客は OpenAI と同じモデルを実⾏しながら、 Microsoft\nAzure のセキュリティ機能を使⽤できます。 Azure OpenAI では、プライベート ネット\nワーク、リージョンの可⽤性、責任ある AI コンテンツのフィルター処理が提供されま\nす。\n⼊⼒候補エンドポイントは、 API サービスのコア コンポーネントです。 この API は、\nモデルのテキストイン、テキストアウト インターフェイスへのアクセスを提供しま\nす。 ユーザーは、英語のテキスト コマンドを含む⼊⼒ プロンプトを⼊⼒するだけで、\nモデルによってテキスト ⼊⼒候補が⽣成されます。\n単純なプロンプトと⼊⼒候補の例を次に⽰します。\nプロンプト : """ count to 5 in a for loop """\n⼊⼒候補 : for i in range(1, 6): print(i)\nAzure OpenAI では、テキストをトークンに分割して処理します。 トークンには、単語\nまたは⽂字のチャンクのみを指定できます。 たとえば、 "hamburger" という単語はト\nークン "ham"、 "bur" 、 "ger" に分割されますが、 "pear" のような短くて⼀般的な単語\nは 1 つのトークンです。 多くのトークンは、 "hello" や "bye" などの空⽩で始まりま\nす。\n所与の要求で処理されるトークンの合計数は、⼊⼒、出⼒、および要求パラメーター\nの⻑さによって異なります。 処理されるトークンの量は、モデルの応答待機時間とス\nループットにも影響します。\nAzure OpenAI は、 Azure の新しい製品オファリングです。 Azure OpenAI は、他の\nAzure 製品と同じように、 Azure サブスクリプションにこのサービス⽤の リソースまた\nはインスタンスを作成 して使⽤を開始できます。 Azure のリソース管理設計 について\n詳しくご覧いただけます。主要な概念\nプロンプトと⼊⼒候補\nトークン\nリソース\nデプロイメント', metadata={'source': '../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf', 'page': 2, '@search.score': 0.032786883413791656})]}
カスタムPrompt
QAのプロンプトを変更したい場合はPromptTemplateで指定します。こちらの公式に詳しく書かれています。
from langchain.prompts import PromptTemplate
PROMPT_TEMPLATE ="""
## 命令
以下のコンテキストに基づいて、質問に対する回答を正確に生成してください。
## 制約
- コンテキスト以外からは回答しないでください。
- 質問で聞かれた内容以外を回答しないでください。
- 回答に改行は使用せず、文章で回答してください。
## コンテキスト
{context}
## 質問
{question}
## 回答
"""
PROMPT = PromptTemplate(
template=PROMPT_TEMPLATE, input_variables=["context", "question"]
)
qa_chain = RetrievalQA.from_chain_type(
llm=chat,
retriever=custom_retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": PROMPT}
)
result = qa_chain({"query": "Azure OpenAIで使えるモデルを教えて"})
display(result)
{'query': 'Azure OpenAIで使えるモデルを教えて',
'result': 'Azure OpenAIで使えるモデルは、GPT-4シリーズ、GPT-3シリーズ、ChatGPT (gpt-35-turbo)、Codexシリーズ、Embeddingsシリーズ、Ada、Babbage、Curie、Cushmanのモデルが利用可能です。ただし、現在はDavinciモデルは利用できません。また、一部の地域では新規のお客様は微調整を利用できませんので、利用可能なモデルについては詳細なページを参照してください。',
'source_documents': [Document(page_content='Azure OpenAI Service とは\n[アーティクル ]•2023/05/01\nAzure OpenAI Service では、 GPT-3 、 Codex 、 Embeddings モデル シリーズなど\nOpenAI の強⼒な⾔語モデルを REST API として使⽤できます。 さらに、新しい GPT-4\nおよび ChatGPT (gpt-35-turbo) モデル シリーズがプレビューで利⽤可能になりまし\nた。 これらのモデルは、特定のタスクに合わせて簡単に調整できます。たとえば、コ\nンテンツの⽣成、まとめ、セマンティック検索、⾃然⾔語からコードへの翻訳などで\nす。 ユーザーは、 REST API 、 Python SDK 、または Azure OpenAI S tudio の Web ベース\nのインターフェイスを介してサービスにアクセスできます。\n機能 Azur e OpenAI\n使⽤できるモデル 新しい GPT-4 シリーズ ( プレビュー )\nGPT-3 ベース シリーズ\n新しい ChatGPT (gpt -35-turbo) ( プレビュー )\nCodex シリーズ\n埋め込みシリーズ\n詳細については、 モデルに関するページを参照してください。\n微調整 Ada\nBabbage\nCurie\nCushman*\nDavinci*\n* 現在は利⽤できません。 ** ⽶国東部と⻄ヨーロッパでは、現在新\n規のお客様は微調整を利⽤できません。 ⽶国ベースのトレーニング\nには、⽶国中南部をご利⽤ください\nPrice こちらで⼊⼿可能\n仮想ネットワークのサポ\nート & プライベート リン\nクのサポートはい\nマネージド ID はい、 Azure Active Directory 経由\nUI エクスペリエンス アカウントとリソースの管理には Azur e Portal、\nモデルの探索と微調整には Azur e OpenAI Ser vice S tudio\nリージョン別の提供状況 ⽶国東部\n⽶国中南部\n⻄ヨーロッパ機能の概要', metadata={'source': '../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf', 'page': 0, '@search.score': 0.03279569745063782}),
Document(page_content='機能 Azur e OpenAI\nコンテンツのフィルター\n処理プロンプトと⼊⼒候補は、⾃動システムを使ってコンテンツ ポリシ\nーに対して評価されます。 重⼤度の⾼いコンテンツはフィルターで\n除外されます。\nMicrosoft は、⼈を第⼀に考える原則に基づいて、 AI の発展に取り組んでいます。\nAzure OpenAI で使⽤できる⽣成モデルには、かなりの潜在的利益がありますが、慎重\nな設計と熟考した軽減策がない場合、そのようなモデルによって、正しくない、また\nは有害なコンテンツが⽣成される可能性があります。 Microsoft は、悪⽤や意図しない\n損害から保護するために多⼤な投資を⾏っています。たとえば、明確に定義したユー\nス ケースを⽰すことを申請者の要件とする、 責任ある AI 使⽤に関する Microsoft の原\n則を取り⼊れる、顧客をサポートするコンテンツ フィルターを構築する、オンボー\nドされた顧客に対して責任ある AI 実装のガイダンスを提供するなどです。\nAzure OpenAI にアクセスするにはどうすればよいですか ?\n⾼い需要、今後の製品の機能強化、 Microsoft の責任ある AI へのコミットメント を\n考慮し、現在、アクセスは制限されています。 現在のところ、 Microsoft と既存のパー\nトナーシップ関係があるお客様、リスクの低いユース ケース、軽減策の取り⼊れに取\nり組んでいるお客様を対象としています。\nより具体的な情報は、申請フォームに記載されています。 Azure OpenAI に対するアク\nセスを拡⼤できるよう、責任を持って取り組んでいますので、しばらくお待ちくださ\nい。\nアクセスはこちらからお申し込みください。\n[今すぐ適⽤する ]\nAzure OpenAI Service では、 OpenAI GPT-4 、 GPT-3 、 Codex 、 DALL-E モデルを使⽤し\nた⾼度な⾔語 AI を顧客に提供し、 Azure のセキュリティとエンタープライズの約束を\n実現します。 Azure OpenAI は OpenAI と共に API を共同開発し、互換性を確保し、⼀\n⽅から他⽅へのスムーズな移⾏を保証します。責任ある AI\nAzure OpenAI にアクセスするにはどうすれば\nよいですか ?\nAzure OpenAI と OpenAI の⽐較', metadata={'source': '../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf', 'page': 1, '@search.score': 0.03279569745063782}),
Document(page_content='Azure OpenAI を使⽤すると、顧客は OpenAI と同じモデルを実⾏しながら、 Microsoft\nAzure のセキュリティ機能を使⽤できます。 Azure OpenAI では、プライベート ネット\nワーク、リージョンの可⽤性、責任ある AI コンテンツのフィルター処理が提供されま\nす。\n⼊⼒候補エンドポイントは、 API サービスのコア コンポーネントです。 この API は、\nモデルのテキストイン、テキストアウト インターフェイスへのアクセスを提供しま\nす。 ユーザーは、英語のテキスト コマンドを含む⼊⼒ プロンプトを⼊⼒するだけで、\nモデルによってテキスト ⼊⼒候補が⽣成されます。\n単純なプロンプトと⼊⼒候補の例を次に⽰します。\nプロンプト : """ count to 5 in a for loop """\n⼊⼒候補 : for i in range(1, 6): print(i)\nAzure OpenAI では、テキストをトークンに分割して処理します。 トークンには、単語\nまたは⽂字のチャンクのみを指定できます。 たとえば、 "hamburger" という単語はト\nークン "ham"、 "bur" 、 "ger" に分割されますが、 "pear" のような短くて⼀般的な単語\nは 1 つのトークンです。 多くのトークンは、 "hello" や "bye" などの空⽩で始まりま\nす。\n所与の要求で処理されるトークンの合計数は、⼊⼒、出⼒、および要求パラメーター\nの⻑さによって異なります。 処理されるトークンの量は、モデルの応答待機時間とス\nループットにも影響します。\nAzure OpenAI は、 Azure の新しい製品オファリングです。 Azure OpenAI は、他の\nAzure 製品と同じように、 Azure サブスクリプションにこのサービス⽤の リソースまた\nはインスタンスを作成 して使⽤を開始できます。 Azure のリソース管理設計 について\n詳しくご覧いただけます。主要な概念\nプロンプトと⼊⼒候補\nトークン\nリソース\nデプロイメント', metadata={'source': '../data/Azure OpenAI Service とは - Azure Cognitive Services _ Microsoft Learn.pdf', 'page': 2, '@search.score': 0.032786883413791656})]}
トークン数の取得
これはRetrievalQAに限った話ではないですが、コールバック関数経由で実行に使ったすべてのトークンの合計を取得することができます(※おそらくEmbeddingのトークン数はカウントされていないと思います)。
from langchain.callbacks import get_openai_callback
with get_openai_callback() as cb:
result = qa_chain({"query": "Azure OpenAIで使えるモデルを教えて"})
usage = {
"completion_tokens": cb.completion_tokens,
"prompt_tokens": cb.prompt_tokens,
"total_tokens": cb.total_tokens,
}
print(cb)
print(usage)
Tokens Used: 2720
Prompt Tokens: 2618
Completion Tokens: 102
Successful Requests: 1
Total Cost (USD): $0.004131
{'completion_tokens': 102, 'prompt_tokens': 2618, 'total_tokens': 2720}
まとめ
今回はRetrievalQAについて解説しました。次回は会話履歴を考慮したRAGアーキテクチャを解説予定です。