アテンション機構についてのメモ。
シンプルに試す
シンプルに試すには、softmaxによりアテンション層を計算して、入力層と要素積をとって、
merge([inputs, a_probs], name='attention_mul', mode='mul')
Denseにより活性化関数を掛けて、1として教師信号と比較、
という形で学習をする。
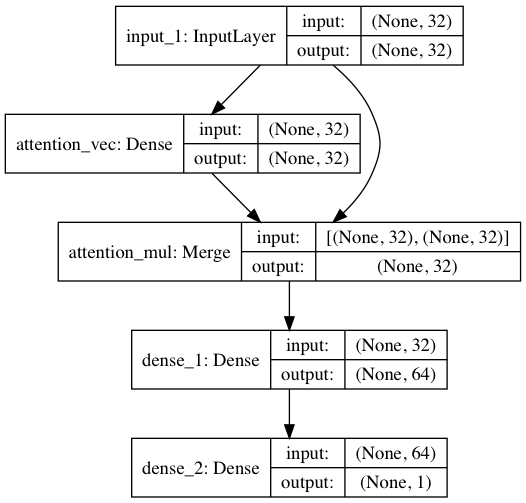
アテンション層の出力は
outputs = [layer.output for layer in model.layers if layer.name == layer_name]
という形で、層の名前で取れる。
kerasの作法
Denseについて
例)
model.add(Dense(20, input_dim=5))
次は活性化関数を入れてみよう。20個のノードそれぞれに対して5つの数値が入ってくるが、
その5つの数値の重み付け和(+バイアス)を適当にとって最後に関数をかける。そのときの関数が活性化関数である。
参考:https://qiita.com/Ishotihadus/items/c2f864c0cde3d17b7efb
Permuteについて
keras.layers.Permute(dims)
与えられたパターンにより入力の次元を入れ替える.
参考
▼参考:Keras : Luong Attentionは実装できたのか?(Teacher Forcingの話も少し)
https://qiita.com/HotAllure/items/50cf80cb1caf9c4d11fa
▼参考:【 self attention 】簡単に予測理由を可視化できる文書分類モデルを実装する
https://qiita.com/itok_msi/items/ad95425b6773985ef959
https://github.com/nn116003/self-attention-classification
▼【テキスト分類】Convolutional Neural NetworksにAttention機構を使ってみた。
https://qiita.com/omr001/items/bda375fa1938ff7c2596
https://github.com/omr001/cnn-sentiment-classification/tree/master