はじめに
画像処理はじめ、自然言語処理でも使われているConvolutional Neural Networks (CNN)ですが、Attention機構を組み合わせたらどうか?ということで試してみました。
Attention機構
簡単に言えば、入力(ここでは文)の重要な部分により焦点を当てることができる機能です。
彼女は美人でスタイルも良いんだけど、性格が最悪なんだ。
例えばこの文の評価極性(ポジティブかネガティブか)を決めたい時に、人間なら最悪が含まれる後ろの節まで見てネガティブと判断しますが、
Attention機構も同じように、美人、(スタイルが)良いという部分よりも最悪という部分をより重要視することができます。
元々は機械翻訳で発表されたものです。
Neural Machine Translation by Jointly Learning to Align and Translate[Bahdanauら,ICLR2015]
もっと詳しく知りたい方はこちらの記事が分かりやすいです。
CNNにAttention機構
Attention機構は機械翻訳で発表されて以降、自然言語処理の様々なタスクで使われていきました。
ただ、そのほとんどがLSTMやGRUを適用したRNNの手法です。
なので、今回は評価極性分類タスクでCNNにAttention機構を使ってみました。
評価極性分類というのは、上でも例に挙げたように、入力文が与えられた時にその文がポジティブな意味を持つのかネガティブな意味をもつのかを予測するタスクです。
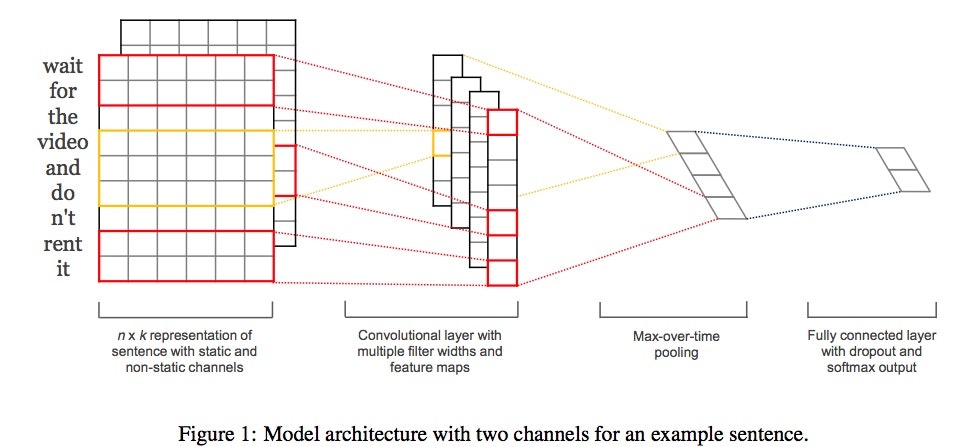
ネットワークモデル
Convolutional Neural Networks for Sentence Classification[Kim,EMNLP2014]が元になっています。
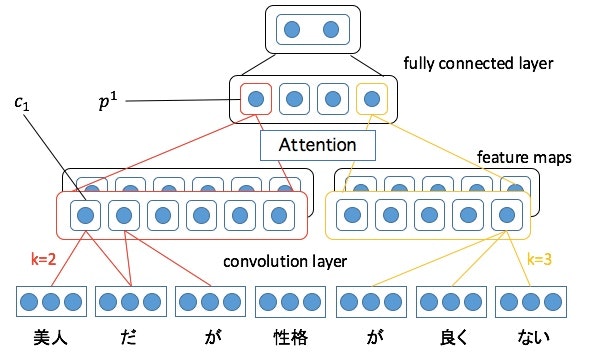
Attention計算
文書分類でGRUを使ったRNNにAttention機構を導入した
[Hierarchical Attention Networks for Document Classification]
(https://www.cs.cmu.edu/~diyiy/docs/naacl16.pdf)[Yangら,NAACL2016]
を参考にしました。
特徴マップ$\boldsymbol{c} \in \mathcal{R}^{l-k+1}$は
\boldsymbol{c} = [c_1, c_2,\cdots,c_{l-k+1}]
$l$は文長、$k$はウィンドウサイズです。
この特徴マップ$\boldsymbol{c}$内の重要度を計算します。この部分がAttention機構です。
\begin{align}
p & = \sum_{i} a_i \odot c_i \\
a_i & = \frac{\exp(W^{(C2)} \tanh(W^{(C1)} c_i))} {\sum_{j} \exp(W^{(C2)} \tanh(W^{(C1)} c_j))}
\end{align}
$\odot$は要素積です。$W^{(C1)} \in \mathcal{R}^{{d}\times 1}$、$W^{(C2)} \in \mathcal{R}^{1\times {d}}$の$d$はハイパーパラメータです。この名称なんなんだろう。。
$a_i$は0から1までの実数値を持つように計算されていて、$a_i$が1に近いほど対応する$c_i$の重要度が高いという意味になります。
1つの特徴マップからはひとつのプーリング結果$p$が出力されます。
ここから先は上で紹介したKimのCNNモデルと同じです。
複数ある$p$を結合し、得られたベクトル$v$を次元圧縮してソフトマックス分類器で分類します。
v = p^1\oplus p^2\oplus \cdots p^m
$m$は特徴マップの数です。ここではKimと同じように100に設定しています。
CNNのpooling層でmax poolingの代わりにAttention使ってみた感じです。図だとこんな感じ。
RNNでAttentionを使う時は、隠れ層のベクトルの重要度を計算しますが、
こっちは畳み込みで得られたスカラー(一応ngramの情報は持っている?)に対して重要度を計算する形なので、果たしてうまくいくかどうか。。。
データ
- ソースコード
- Chainerで実装してます。
- omr001@github
- データセット
- Stanford Sentiment Treebank (SST)を使ってます。
- こちらでダウンロードできます。
- 単語分散表現
- word2vecの学習済みモデル(GoogleNews-vectors-negative300.bin.gz)を使ってます。こちらでダウンロードできます。
コード(ネットワークの部分)
class CNN_attention(Chain):
def __init__(self, vocab_size, embedding_size, input_channel, output_channel_1, output_channel_2, output_channel_3, k1size, k2size, k3size, pooling_units, atten_size=20, output_size=args.classtype, train=True):
super(CNN_attention, self).__init__(
w2e = L.EmbedID(vocab_size, embedding_size),
conv1 = L.Convolution2D(input_channel, output_channel_1, (k1size, embedding_size)),
conv2 = L.Convolution2D(input_channel, output_channel_2, (k2size, embedding_size)),
conv3 = L.Convolution2D(input_channel, output_channel_3, (k3size, embedding_size)),
l1 = L.Linear(pooling_units, output_size),
#Attention
a1 = L.Linear(1, atten_size),
a2 = L.Linear(atten_size, 1),
)
self.output_size = output_size
self.train = train
self.embedding_size = embedding_size
self.ignore_label = 0
self.w2e.W.data[self.ignore_label] = 0
self.w2e.W.data[1] = 0 # 非文字
self.input_channel = input_channel
def initialize_embeddings(self, word2id):
#w_vector = word2vec.Word2Vec.load_word2vec_format('./vector/glove.840B.300d.txt', binary=False) # GloVe
w_vector = word2vec.Word2Vec.load_word2vec_format('./vector/GoogleNews-vectors-negative300.bin', binary=True) # word2vec
for word, id in sorted(word2id.items(), key=lambda x:x[1])[1:]:
if word in w_vector:
self.w2e.W.data[id] = w_vector[word]
else:
self.w2e.W.data[id] = np.reshape(np.random.uniform(-0.25,0.25,self.embedding_size),(self.embedding_size,))
def __call__(self, x):
h_list = list()
ox = copy.copy(x)
if args.gpu != -1:
ox.to_gpu()
x = xp.array(x.data)
x = F.tanh(self.w2e(x))
b, max_len, w = x.shape # batch_size, max_len, embedding_size
x = F.reshape(x, (b, self.input_channel, max_len, w))
c1 = self.conv1(x)
b, outputC, fixed_len, _ = c1.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h1 = self.attention_pooling(F.relu(c1), b, outputC, fixed_len, tf)
h1 = F.reshape(h1, (b, outputC))
h_list.append(h1)
c2 = self.conv2(x)
b, outputC, fixed_len, _ = c2.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h2 = self.attention_pooling(F.relu(c2), b, outputC, fixed_len, tf)
h2 = F.reshape(h2, (b, outputC))
h_list.append(h2)
c3 = self.conv3(x)
b, outputC, fixed_len, _ = c3.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h3 = self.attention_pooling(F.relu(c3), b, outputC, fixed_len, tf)
h3 = F.reshape(h3, (b, outputC))
h_list.append(h3)
h4 = F.concat(h_list)
y = self.l1(F.dropout(h4, train=self.train))
return y
def set_tfs(self, x, b, outputC, fixed_len):
TF = Variable(x[:,:fixed_len].data != 0, volatile='auto')
TF = F.reshape(TF, (b, 1, fixed_len, 1))
TF = F.broadcast_to(TF, (b, outputC, fixed_len, 1))
return TF
def attention_pooling(self, c, b, outputC, fixed_len, tf):
reshaped_c = F.reshape(c, (b*outputC*fixed_len, 1))
scala = self.a2(F.tanh(self.a1(reshaped_c)))
reshaped_scala = F.reshape(scala, (b, outputC, fixed_len, 1))
reshaped_scala = F.where(tf, reshaped_scala, Variable(-10*xp.ones((b, outputC, fixed_len, 1)).astype(xp.float32), volatile='auto'))
rereshaped_scala = F.reshape(reshaped_scala, (b*outputC, fixed_len)) # reshape for F.softmax
softmax_scala = F.softmax(rereshaped_scala)
atten = F.reshape(softmax_scala, (b*outputC*fixed_len, 1))
a_h = F.scale(reshaped_c, atten, axis=0)
reshaped_a_h = F.reshape(a_h, (b, outputC, fixed_len, 1))
p = F.sum(reshaped_a_h, axis=2)
return p
実験内容
SSTを使って、分類の正解率をmax poolingと比較しました。
very negative,negative,neutral,positive,very positiveの5値を分類するSST-5と、neutral除いてポジネガ分類するSST-2の2つのタスクで実験しました。
実験結果
| method | SST-2 | SST-5 |
|---|---|---|
| max | 86.3 (0.27) | 46.5 (1.13) |
| attention | 86.0 (0.20) | 47.2 (0.37) |
値は5回試した平均値、括弧内の値は標準偏差です。
5値分類ではAttention使った方が良いけど、2値ではそんなに変わらないという結果に。
ちなみに5回中の最大値(SST-5)はmax poolingでは48.2%,Attentionでは47.7%とmax poolingの方が良い結果となりました。ただ揺れやすい。。。
考察
特徴マップ内がどうAttentionされているかをすこし詳しくみてみると、
どこか1つを0.9くらい強く重要視していて、それ以外はほぼ0みたいな、結局max poolingと似た感じの学習をしていることが分かりました。
ただ、max poolingと違って、特徴マップ全体の値を考慮しているので、一応間違えにくくはなっているのかな。。。
おわりに
直感的には、最大値だけ使うmax poolingよりも全体の重要度を見るAttentionのほうが良さそうな気がしましたが、、、
2値分類ではともかく5値分類では精度があがっているので、悪くはないですね。。
タスクにもよると思うので、他のタスクでも試してみたいですね。
こちらの記事でもCNNを用いたテキスト分類を分かりやすく紹介しています。