はじめに
ゲームサーバを建てるために、自宅にサーバ用のPCを1台設置しています。
昨今のAIブームに影響を受けてローカルLLMを触ってみたくなり、ちょうどPCIeのスロットも余っているので触ってみることにしました。
環境
- 箱:Asrock DeskMeet X600
- OS:Proxmox 9.1
- CPU:AMD Ryzen 5 9600
- GPU:AMD Radeon RX 9060 XT 16GB
- LLMを触るために新しく購入
- もちろんGeforceでも良い (CUDA使えますし)
- 玄人志向のこれが箱にギリギリ収まるライン (200mm) かも
- LLMを触るために新しく購入
- メモリ:Micron MTC20C2085S1EC56BD1R (DDR5-5600 ECC U-DIMM 32GB) 2枚
- ストレージ:KIOXIA EXCERIA PLUS G3 (1TB) 2枚
- ProxmoxのbtrfsでRAID1運用
やること
ProxmoxのPCIeパススルー機能を使って、仮想マシンからRadeonにアクセスできるようし、そこでOllamaを動作させます。
Ryzen+Radeon+Proxmoxとかいう環境向けの参考になれば幸いです。
1. BIOSでIOMMUを有効化
BIOSの設定から IOMMU を有効化します。
Advanced → AMD CBS → NBIO Common Options → IOMMU を Enabled にします
2. Proxmoxのカーネルの起動オプションを変更
amd_iommu=on と iommu=pt を追記します。(前者はなくてもいいかもしれない)
設定が終わったら一度Proxmoxを再起動します。
> nano /etc/kernel/cmdline
# 元々↓のようになっているので
# root=UUID=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
# ↓のように変更
# root=UUID=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx amd_iommu=on iommu=pt
> reboot
3. 仮想マシンのセットアップ
適当にセットアップします。
今回はUbuntu 24.04をインストールします。
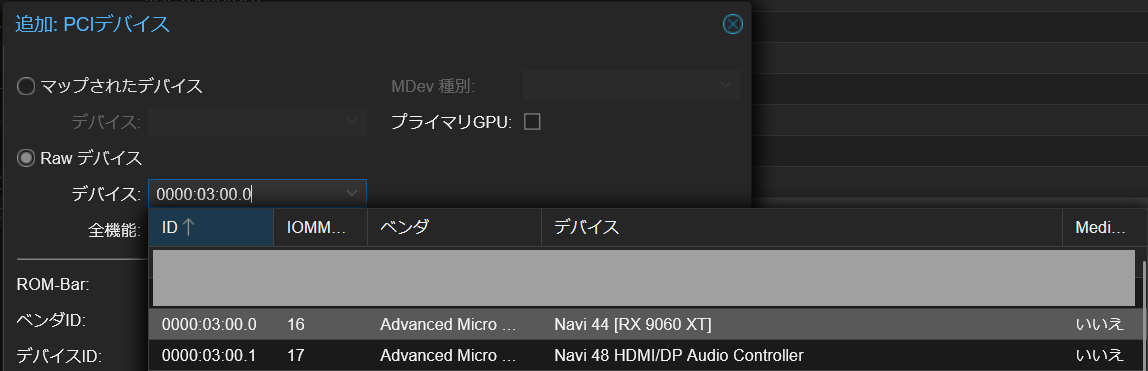
4. 対象の仮想マシンのPCIデバイスでRadeon RX 9060 XTを追加
対象の仮想マシンについて、 ハードウェア → 追加 → PCIデバイス から、 Rawデバイス で RX 9060 XT を選択します。
5. 仮想マシンを起動して、ドライバとROCmのインストール
Quick start installation guide を元に、 ROCm と AMDGPU driver をインストールします。
インストールが終わったら仮想マシンを再起動します。
サポート環境とかは System requirements (Linux) で確認できます。
6. amd-smiでGPUを認識しているか確認
amd-smi コマンドで確認します。
> amd-smi
+------------------------------------------------------------------------------+
| AMD-SMI 26.1.0+5df6c765 amdgpu version: 6.16.6 ROCm version: 7.1.0 |
| VBIOS version: 00144809 |
| Platform: Linux Guest (Passthrough) |
|-------------------------------------+----------------------------------------|
| BDF GPU-Name | Mem-Uti Temp UEC Power-Usage |
| GPU HIP-ID OAM-ID Partition-Mode | GFX-Uti Fan Mem-Usage |
|=====================================+========================================|
| 0000:00:10.0 AMD Radeon RX 9060 XT | 0 % 44 °C 0 3/160 W |
| 0 0 N/A N/A | 0 % 0.0 % 57/16304 MB |
+-------------------------------------+----------------------------------------+
+------------------------------------------------------------------------------+
| Processes: |
| GPU PID Process Name GTT_MEM VRAM_MEM MEM_USAGE CU % |
|==============================================================================|
| No running processes found |
+------------------------------------------------------------------------------+
↓のように認識していない場合は一度Proxmoxを再起動して再度確認します。
> amd-smi
ERROR:root:Unable to get devices, driver not initialized (amdgpu not found in modules)
ERROR:root:Unable to detect any GPU devices, check amdgpu version and module status (sudo modprobe amdgpu)
ERROR:root:Unable to detect any CPU devices, check amd_hsmp version and module status (sudo modprobe amd_hsmp)
AMDSMI Tool: 26.1.0+5df6c765 | AMDSMI Library version: 26.1.0 | ROCm version: 7.1.0
7. Ollamaをインストール
Download Ollama を参考にして、Ollamaをインストールします。
8. gpt-oss-20bを動かしてみる
試しにOpenAIが公開している gpt-oss-20b をダウンロードして動かしてみます。以下のコマンドでモデルのダウンロードが行われ、チャットインターフェースが起動します。
> ollama run gpt-oss:20b
# ↓のようなプロンプトが表示される
# >>> Send a message (/? for help)
適当にコンテキストウィンドウを広げてみます。モデル自体は12GB程度で、残り4GBほど余裕があるので32kぐらいまで拡張してみます。
また、思考レベルも high にしてみます。
>>> /set parameters num_ctx 32768
>>> /set think high
設定したらモデルを保存しておきます。次からこの名称でモデルを指定すると、↑の設定通りに動作してくれます。
>>> /save gpt-oss-20b-32k-high
設定はこの辺にしてメッセージを送ってみます。ちゃんと動いてそうですね。
>>> 自己紹介をしてください
Thinking...
The user asks: "自己紹介をしてください" meaning "Introduce yourself." They want an introduction. Should respond in Japanese. So write a friendly introduction,
mention that I'm ChatGPT, large language model, can help with many tasks, etc. Perhaps mention capabilities and limitations. Ok.
...done thinking.
はじめまして!
私はChatGPT(Chat Generative Pre‑trained Transformer)と呼ばれる、大規模言語モデルです。OpenAIが開発したもので、膨大なテキストデータを学習して、自然言語での対話や文
章生成、情報検索、翻訳、プログラミングサポートなど、さまざまなタスクをこなすことができます。
### 主な特徴
- **日本語・英語をはじめ、多くの言語に対応**
- **質問に対して分かりやすく回答**
- **アイデア出し・文章校正・創作・プログラミングコードの提案**
- **会話を楽しみながら学びや作業の手助け**
### 使い方のヒント
- **具体的な質問**をすると、より的確な回答が得られます。
- **例文やコードの修正**を依頼する際は、元のテキストを添えてください。
- **創作やアイデア**を求めるときは、テーマや用途を教えていただけると、より適した提案ができます。
### 注意点
- 私は最新情報(2025年12月以降)は持っていません。
- 法的・医学的・安全に関わる判断は、専門家の意見を優先してください。
- 個人情報や機密情報を入力しないようご注意ください。
何かお手伝いできることがあれば、遠慮なく聞いてくださいね!
--verbose オプションをつけると、トークンの生成速度など色々見れるようです。
> ollama run gpt-oss-20b-32k-high --verbose
>>> こんにちは
Thinking...
The user says "こんにちは" meaning "Hello". Probably respond politely. Since user wrote in Japanese, respond in Japanese. Probably a simple greeting like "こんにちは
!今日はどんなご用件でしょうか?" Or just greet back. Let's do that.
...done thinking.
こんにちは!今日はどんなご用件でしょうか?何かお手伝いできることがあれば、どうぞ教えてくださいね。
total duration: 1.812626798s
load duration: 93.525108ms
prompt eval count: 68 token(s)
prompt eval duration: 136.716771ms
prompt eval rate: 497.38 tokens/s
eval count: 92 token(s)
eval duration: 1.539113758s
eval rate: 59.77 tokens/s
9. ollama.serviceの調整
リソースが割とかつかつなので、 ollama.service の設定を調整しておきます。設定が終わったらデーモンの再起動をします。
> sudo vim /etc/systemd/system/ollama.service
# ↓のように環境変数を追加
# Environment="OLLAMA_MAX_LOADED_MODELS=1" # ロードするモデルの最大数
# Environment="OLLAMA_NUM_PARALLEL=1" # 同時に処理するリクエスト数
# Environment="OLLAMA_SCHED_SPREAD=0" # モデルを複数GPUへ分割配置するか
# Environment="OLLAMA_FLASH_ATTENTION=1" # Flash Attentionの有効化
# Environment="OLLAMA_KV_CACHE_TYPE=q8_0" # KVキャッシュの量子化タイプ
> sudo systemctl daemon-reload
> sudo systemctl restart ollama.service
せっかくなのでAIエディタのCursorから呼び出してみる
OllamaはOpenAI互換のAPIサーバとして動作するので、OpenAIのAPIサーバのふりをして叩かせることができます。
CursorにはOpenAIの接続情報を設定する部分がありますので、ここにサーバのアドレスを設定すればローカルLLMが使えるというわけです。(もっと良いやり方があると思いますが)
ただ一つだけ注意点があり、Cursorから送信したリクエストは、一旦Cursorのサーバに渡され、そこから各LLMのプロバイダーに送信されるという設計になっているようです。そのため、プライベートIPを設定してもCursorのサーバからアクセスできないため動作しません。というわけでグローバルIPでアクセスできるようにします。
1. ルータの設定
外からサーバにアクセスできるようにポート変換などの設定をします。
2. 証明書の発行
ドメインは既に存在するものとして、先にLet's encryptで証明書を発行します。
# クライアントのインストール
> sudo apt install letsencrypt
# 証明書の発行
> sudo letsencrypt certonly --standalone -d <ドメイン>
Saving debug log to /var/log/letsencrypt/letsencrypt.log
Enter email address (used for urgent renewal and security notices)
(Enter 'c' to cancel): <メールアドレス>
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Please read the Terms of Service at
https://letsencrypt.org/documents/LE-SA-v1.6-August-18-2025.pdf. You must agree
in order to register with the ACME server. Do you agree?
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
(Y)es/(N)o: Y
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Would you be willing, once your first certificate is successfully issued, to
share your email address with the Electronic Frontier Foundation, a founding
partner of the Let's Encrypt project and the non-profit organization that
develops Certbot? We'd like to send you email about our work encrypting the web,
EFF news, campaigns, and ways to support digital freedom.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
(Y)es/(N)o: <好きな方を選ぶ>
Account registered.
Requesting a certificate for <ドメイン>
Successfully received certificate.
Certificate is saved at: /etc/letsencrypt/live/<ドメイン>/fullchain.pem
Key is saved at: /etc/letsencrypt/live/<ドメイン>/privkey.pem
This certificate expires on 2026-03-08.
These files will be updated when the certificate renews.
Certbot has set up a scheduled task to automatically renew this certificate in the background.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
If you like Certbot, please consider supporting our work by:
* Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate
* Donating to EFF: https://eff.org/donate-le
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
3. nginxの設定
nginxをフロント用サーバとして設置してOllamaにproxyさせます。わざわざproxyする理由としては、1つはSSL通信のため、もう1つはOllamaにはAPI Keyによる認証機能がないので、認証レイヤーを挟むためです。
( tcp/11434 が外部に公開されてしまっていると意味がないので、 tcp/11434 のフィルタは別途行ってください)
> sudo apt install nginx
> sudo vim /etc/nginx/conf.d/ollama.conf
nginxのコンフィグは下のような感じで設定しました。
# ollama.serviceの設定に合わせる
upstream ollama {
server 127.0.0.1:11434;
keepalive 32;
}
# httpでアクセスされたらhttpsへリダイレクトする
server {
listen 80;
server_name <ドメイン>;
location / {
return 301 https://$host$request_uri;
}
}
server {
# めちゃくちゃ雑なAPI Key認証
if ($http_authorization != 'Bearer <API Key>') { return 401; }
# ssl関係
listen 443 ssl;
server_name <ドメイン>;
ssl_certificate /etc/letsencrypt/live/<ドメイン>/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/<ドメイン>/privkey.pem;
ssl_trusted_certificate /etc/letsencrypt/live/<ドメイン>/chain.pem;
ssl_protocols TLSv1.2 TLSv1.3;
# proxy関係
proxy_connect_timeout 60s;
proxy_send_timeout 3600s;
proxy_read_timeout 3600s;
client_max_body_size 50m;
location / {
proxy_pass http://ollama;
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering off;
proxy_request_buffering off;
}
}
4. 外から叩けるか確認
Curlでシンプルなリクエストを投げてみます。 Ollama is running と表示されればOKです。
> curl https://<ドメイン>
Ollama is running
5. API情報をCursorに設定
ドメインとAPI Keyを設定します。
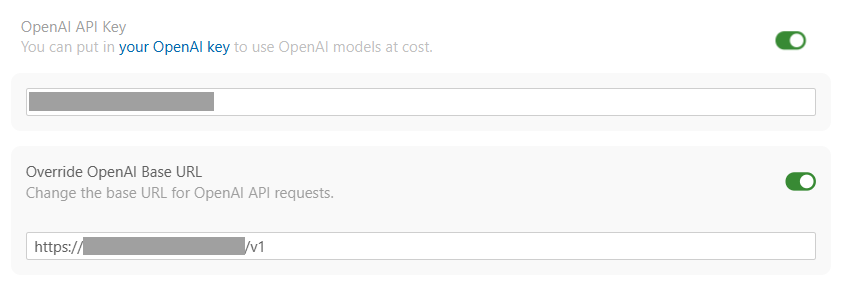
Cursorにカスタムモデルを追加します。モデル名は先程作成した gpt-oss-20b-32k-high にします。

6. リクエストを送信
モデルに先程設定した gpt-oss-20b-32k-high を選択し、チャット欄に文章を入力して送信します。
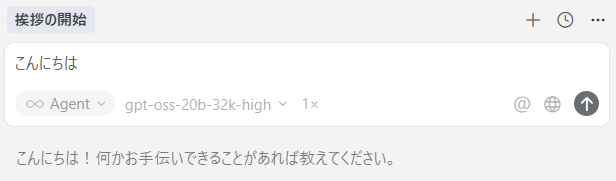
問題なく応答が返ってきてますね。アクセスログも確認できました。
> tail -f /var/log/nginx/access.log
xx.xx.xx.xx - - [08/Dec/2025:15:29:03 +0000] "POST /v1/chat/completions HTTP/1.1" 200 12210 "-" "axios/1.13.2"
おわりに
というわけで、軽めのモデルを軽めの設定で動かす分には、意外と動くなという感想でした。ただ、リソースが結構カツカツなので、ローカルLLMをバリバリ使うには、Ryzen AI搭載機とかNVIDIAのDGX Sparkとかを使う必要が出てくるのでしょう。多分。