AWSでサーバーレスなバッチ
2つのAWSアカウント間(VPC Peering済み)で、一方のデータベースからデータ加工してもう一方のデータベースへ、のようなバッチをつくります。
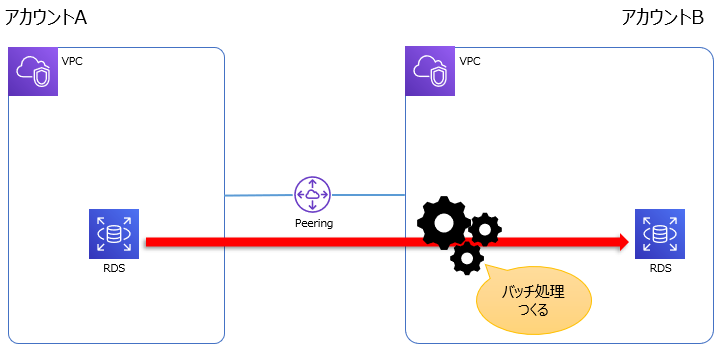
勉強も兼ねてAWSのサービスを積極的に使っていこうということで、
まずは間に DynamoDB を挟み、分割した Lambda function で処理する形にしました。
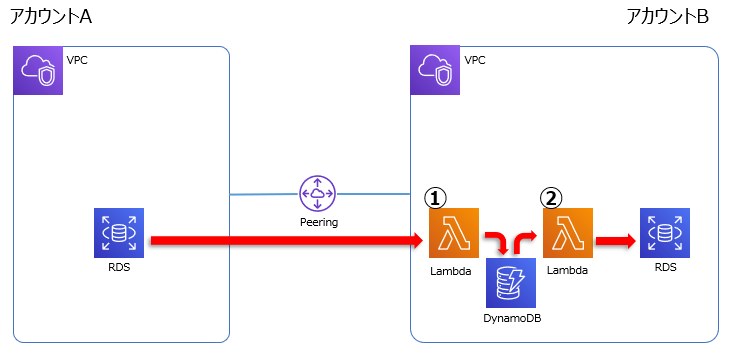
そしてRDSへのアクセス情報は Secrets Manager を使って保管し、一連のフローは Step Functions で組んでみました。
これを ClooudWatch Events でスケジュール実行させます。

では、それぞれ構築していきましょう。
① Lambda [RDS to DynamoDB]
LambdaでRDSにアクセスするのはコネクションプール数の問題1でアンチパターンではありますが、
今回のバッチはスケジュールトリガーなので同時実行数は問題にならないはず。
RDSアクセスのためVPC内に配置します。
必要なIAMポリシーは以下のとおり。
AWSLambdaVPCAccessExecutionRole- SecretsManager読み取り権限(
DescribeSecret,GetSecretValue) - DynamoDB書き込み権限(
DescribeTable,PutItem)
ランタイムはPython3.8にしました。
ライブラリはboto3などの他、RDS(MySQL)アクセスのためpymysqlを使います。
(ローカルでpip installしてzipをアップロード)
Secrets Manager
RDSやDocumentDBなどのシークレット情報を保管し、設定によりパスワードのローテーションも自動で管理してくれるようです。
IDとパスワードだけでなく、任意の項目もシークレットとして保管できます。
例)ホスト、ポート、データベース名など
さて、ここで「RDS」で設定しようとしたとき、該当アカウント以下のRDSインスタンスしか選択できません。
今回はPeering先のRDSのシークレット情報をつくりたかったので、「その他」で任意のシークレットとして作成することに。(ローテーションはしない)
作成後、各言語用のサンプルコードが生成されます。
そのままコピペすればOK。(後からも確認可能)
get_secret_value_response['SecretString']ないしbase64.b64decode(get_secret_value_response['SecretBinary'])を利用するとのことなので、それを返すようにしておきます。
呼び出し側はこんな感じ。
secrets = json.loads(get_secret())
conn = pymysql.connect(
secrets['host'],
user=secrets['username'],
passwd=secrets['password'],
db=secrets['dbname'],
cursorclass=pymysql.cursors.DictCursor
)
DynamoDB
予め必要なテーブルを作成しておきます。
プライマリーキーはパーティションキー(必須)とソートキー(任意)で構成されます。
cf. DynamoDBのキー・インデックスについてまとめてみた
リレーショナルDBにおけるレコードは、DynamoDBでは**項目(Item)**と呼ぶようです。
PutItemでデータを投入します。
サポートしている型はMySQLの型とは異なるので、日付型などをそのまま投入しようとするとエラーになります。
また、空文字も投入できないので明示的にNull型を指定する必要があります。
cf. Boto3を使ったら空文字のままだとDynamoDBにデータが入れられなかった話
※jsではオプションがあるようですが、python(boto3)ではまだないのかな…?
cf. DynamoDB は空の値を登録できないけど DynamoDB document client のコンストラクタにオプションを渡すだけで空の値を NULL 型には変換できるよ?
import boto3
...
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('table-name')
for row in data:
for k,v in row.items():
if isinstance(v, str) and v == '':
#DynamoDBに空文字''を投入しようとするとエラーになるのでNoneを明示的に指定
row[k] = None
elif isinstance(v, (datetime.date, datetime.datetime, datetime.time)):
#DynamoDBは日付・時刻型をサポートしていないので文字列に変換
row[k] = v.isoformat() #もちろんstrftimeでもいいです
#キーが存在すれば上書きされる
res = table.put_item(
Item=row
)
RDBでのUPDATEと同じように更新対象のカラムを指定するUpdateItemもあります。
※今回の例だと、IAMポリシーで追加で許可する必要あり。
今回はすべて洗い替えでよかったのでそのままPutItemにしました。
② Lambda [DynamoDB to RDS]
こちらもVPC内に置き、IAMポリシーは以下のとおりです。
AWSLambdaVPCAccessExecutionRole- SecretsManager読み取り権限(
DescribeSecret,GetSecretValue) - DynamoDB読み取り権限(
DescribeTable,GetItem,Scan,Query)
DynamoDB
プライマリーキー指定のGetItemで項目1件を取得します。
import boto3
...
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('table-name')
#GetItem(ソートキーありの場合)
res = table.get_item(
Key={
'partition-key-name': VALUE1,
'sort-key-name': VALUE2
}
)
res['Item'] #取得した項目。取得できなければ'Item'が存在しない。
さらにQueryとScanがあります。
使い分けのざっくりした理解としては…
- Query
- プライマリーキーorインデックス指定
- 高速
- Scan
- 全走査
- 結果にフィルタをかけることが可能
- 高コスト
基本はQueryを使うのがよさそうです。
cf. DynamoDBをPython(boto3)を使って試してみた
import boto3
from boto3.dynamodb.conditions import Key #これが必要
...
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('table-name')
#Query:キー指定(&ソートキーありの場合)
res = table.query(
KeyConditionExpression=Key('partition-key-name').eq(VALUE1) & Key('sort-key-name').eq(VALUE2)
)
#Query:インデックス指定(&パーティションキーのみの場合)
res = table.query(
IndexName='index-name',
KeyConditionExpression=Key('partition-key-name').eq(VALUE3)
)
res['Count'] #取得件数
res['Items'] #取得した項目のリスト
DynamoDBでインデックスをつくる場合、射影と呼ばれ、コピーテーブルがつくられるイメージのようです。
テーブルのデータサイズによっては全カラム反映するよりキーだけ反映する形にした上で、
インデックスでキー取得 → 改めてキーで項目取得
という処理にした方がいいかも。
③ Step Functions
JSON記法で処理フローを構築できるもの。(組み合わせられるのはLambdaに限りません)
条件分岐とか並行処理も書けるので相当柔軟にフローをつくれます。
定義だけだと正直、読み書きしにくいですが、Syntaxチェックしてくれたり自動でフロー図をつくってくれたりするので助かります。
作成したフローをステートマシンと呼ぶようです。
cf. AWS Step Functions で作る Serverless バッチシステム
Lambdaを呼ぶ場合はIAMポリシーでInvokeFunctionが必要です。
①②のfunctionは実際にはもう少し細分化しているので、ここでフローをつくります。
直列処理と並行処理はそれぞれ大体以下のような形。
{
"Comment": "コメントコメントコメント",
"StartAt": "First Process",
"States": {
"First Process": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT:function:FUNCTION_NAME",
"Next": "Second Process"
},
"Second Process": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT:function:FUNCTION_NAME",
"End": true
}
}
}
{
"Comment": "コメントコメントコメント",
"StartAt": "Main Process",
"States": {
"Main Process": {
"Type": "Parallel",
"End": true,
"Branches": [
{
"StartAt": "Branch Process A",
"States": {
"Branch Process A": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT:function:FUNCTION_NAME",
"End": true
}
}
},
{
"StartAt": "Branch Process B",
"States": {
"Branch Process B": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT:function:FUNCTION_NAME",
"End": true
}
}
}
]
}
}
}
CloudWatch Events
ステートマシンは CloudWatch Events をトリガーにして実行できます。
スケジュール実行する場合、rate式かcron式で指定するわけですが、
cronで地味にハマったので備忘まで。
-
分 時 日 月 曜日 年の6要素 - 日と曜日のワイルドカードはいずれかは
?にする必要がある(両方*や、*と値指定の組み合わせはNG) - リージョンによらず時間はUTCなので日本時間の9時間前を指定
cf. Schedule Expressions for Rules
おわりに
いずれもほぼ初めて触ったサービスですが、非常に面白かったです。
Let's サーバーレス!
そしてやってみると気になる、Lambdaコードの管理とか開発環境とかどうやるものなのかな…?
-
プレビュー版が発表されたRDS Proxyでこの問題は解決すると思われます。 ↩