はじめに
AWSのマネージドNoSQLであるDynamoDBについて調べたことをまとめてみました。
RDBMS暦が長いと、なかなかに難しいですね。
理論
キーの考え方
DynamoDBでレコード(Item)を一意に決定するプライマリキーには以下の2通りがあります。
-
パーティションキー
-
パーティションキー+ソートキー
パーティションキーはハッシュキー、ソートキーはレンジキーと呼ばれていたりします。
パーティションキーといった方がしっくりきますね。
パーティションキーはその名の通り、パーティションを分割して保存されます。パーティションキーが異なるItemは独立性が高く、パーティションキーを横断した処理はDynamoDBは苦手とします。
一方、ソートキーは同じパーティション内で順序を含めて保存されます。
同一パーティションキー内のデータをユニークに決定する属性です。
例として某アイドルのテーブルを考えてみます。
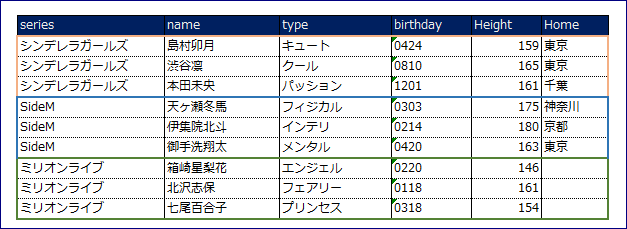
独立性の高いパーティションキー。
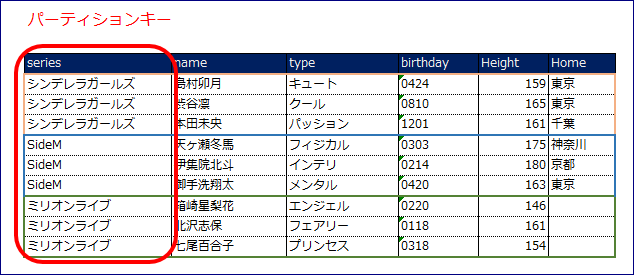
ソートキーを組み合わせてItemを一意になります。
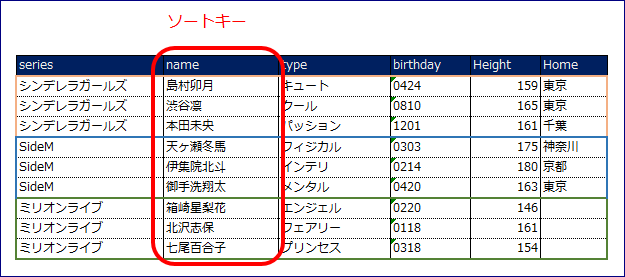
属性と型
DynamoDBは基本的にスキーマレスなのでキー以外の属性については定義する必要はありません。
使用できる型は以下の通りです。
- 文字列
- 数値
- バイナリ
- Boolean
- null
- リスト
- マップ
- セット
ScanとQuery
DynamoDBのテーブルからデータを取得(Select)する操作にはScanとQueryがあります。
Scanは全件取得、Queryはキーで絞り込んで取得する処理です。
Scanはコストがかかる(料金的な意味も含めて)ので、避けてQueryを使用するようにテーブル設計したほうが良いようです。
インデックス
非キー属性で絞り込む場合、インデックス(セカンダリインデックス)を事前に設定しておく必要があります。
セカンダリインデックスには以下の2つがあります
-
ローカルセカンダリインデックス(LSI)
-
グローバルセカンダリインデックス(GSI)
LSIは同一パーティション内の属性を絞り込みます。そのため、代替ソートキーということになります。
GSIはパーティションをまたがって属性を絞り込むことができます。
どちらも1つのテーブルに5つまで作成できますが、LSIはテーブルの作成時にしか設定できません。
※ 今後のアップデートでLSIも後から変更可能になるとのことです。
インデックスとは別にフィルタリングの機能があります。
ただし、これはScanまたはQueryで取得した結果に対するフィルタリングのため、コストは下がりません。
また、Limitと併用した場合、Limitで制限して取得した後にフィルタリングされます。
インデックステーブルに保存される属性は元のテーブルの属性のサブセットとなります(射影と呼びます)。
インデックス作成時に指定できますが、インデックスの属性に含めるのか、インデックスからはキーのみを取得し、基のテーブルからキーで引き直すのかは、設計時のポイントになりそうです。
LSI
実質的に元のテーブルとソートキーが異なる、トリガーで管理されたテーブルを作成することと同意です。
パーティションキーは同じでなくてはなりません。
そのため、必ずパーティションキーとソートキーの複合キーのテーブルとなります。
元のテーブルのItemが変更されると、自動でインデックスのテーブルも更新されます。
1つのテーブルに5つのインデックスが作成できますが、それぞれのインデックスは独立しているため、複数のインデックスを組み合わせた絞り込みはできません。
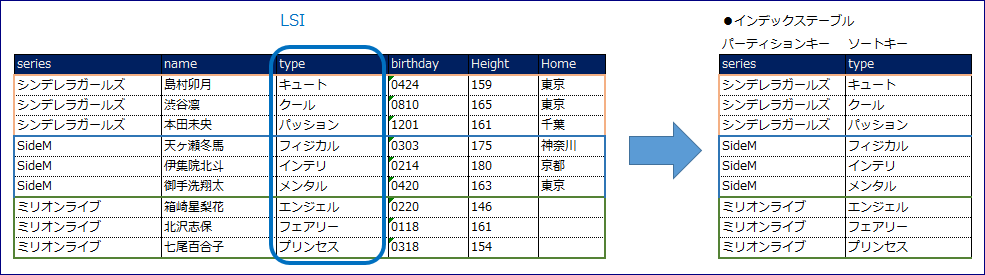
スループットはベーステーブルと共用です。
GSI
グローバルセカンダリインデックスはLSIのようなパーティションキーに依存することはありません。
指定した属性をプライマリキーとするインデックスのテーブルが作成されます。
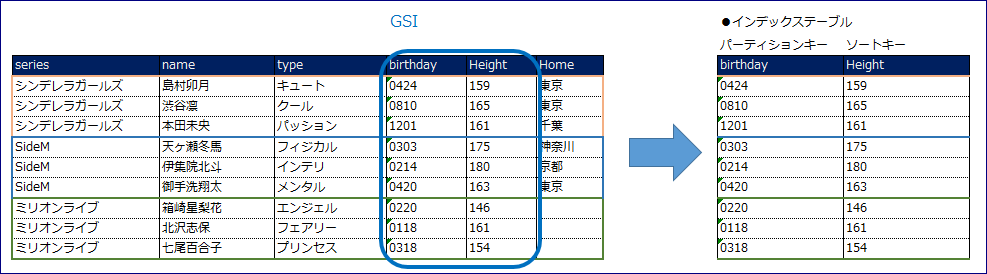
その他の制限は LSI と同様です。
スループットは LSI と違い、独立しています。
実践
実際に触って確認してみます。
環境はPython3.6とboto3を使用し、Cloud9から実行しています。
テーブルの作成
create_tableで行います。
def create_table(resource):
"""
テーブルの作成
"""
resource.create_table(
TableName = 'idolmaster',
KeySchema = [
{
'AttributeName': 'series',
'KeyType': 'HASH'
},
{
'AttributeName': 'name',
'KeyType': 'RANGE'
},
],
AttributeDefinitions = [
{
'AttributeName': 'series',
'AttributeType': 'S'
},
{
'AttributeName': 'name',
'AttributeType': 'S'
},
{
'AttributeName': 'type',
'AttributeType': 'S'
},
{
'AttributeName': 'birthday',
'AttributeType': 'S'
},
{
'AttributeName': 'height',
'AttributeType': 'N'
},
],
ProvisionedThroughput = {
'ReadCapacityUnits': 1,
'WriteCapacityUnits': 1
},
LocalSecondaryIndexes=[
{
'IndexName': 'typeLSIndex',
'KeySchema': [
{
'AttributeName': 'series',
'KeyType': 'HASH'
},
{
'AttributeName': 'type',
'KeyType': 'RANGE'
}
],
'Projection': {
'ProjectionType': 'INCLUDE',
'NonKeyAttributes': [
'name',
]
}
},
],
GlobalSecondaryIndexes=[
{
'IndexName': 'birthHeightGSIndex',
'KeySchema': [
{
'AttributeName': 'birthday',
'KeyType': 'HASH'
},
{
'AttributeName': 'height',
'KeyType': 'RANGE'
},
],
'Projection': {
'ProjectionType': 'KEYS_ONLY',
},
'ProvisionedThroughput': {
'ReadCapacityUnits': 1,
'WriteCapacityUnits': 1
}
},
],
)
AttributeDefinitions で属性の型定義を行います。キーとなる属性のみを定義すればよいのですが、セカンダリインデックスを作成する場合は、そのキー属性の定義も必要になります。
LocalSecondaryIndexes の KeySchema ではHASHキーは基のテーブルと同じ指定となります。自明ですが、指定しないとエラーとなります。
レコード(Item)の登録
put_itemで行います。
def put(resource):
"""
レコードの登録
"""
table = resource.Table("idolmaster")
with table.batch_writer() as batch:
batch.put_item(
Item={
'series': 'シンデレラガールズ',
'name': '島村卯月',
'type': 'キュート',
'birthday': '0424',
'height': 159,
'home': '東京'
}
)
batch.put_item(
Item={
'series': 'シンデレラガールズ',
'name': '渋谷凛',
'type': 'クール',
'birthday': '0810',
'height': 165,
'home': '東京'
}
)
batch.put_item(
Item={
'series': 'シンデレラガールズ',
'name': '本田未央',
'type': 'パッション',
'birthday': '1201',
'height': 161,
'home': '千葉'
}
)
batch.put_item(
Item={
'series': 'SideM',
'name': '天ヶ瀬冬馬',
'type': 'フィジカル',
'birthday': '0303',
'height': 175,
'home': '神奈川'
}
)
batch.put_item(
Item={
'series': 'SideM',
'name': '伊集院北斗',
'type': 'インテリ',
'birthday': '0214',
'height': 180,
'home': '京都'
}
)
batch.put_item(
Item={
'series': 'SideM',
'name': '御手洗翔太',
'type': 'メンタル',
'birthday': '0420',
'height': 163,
'home': '東京'
}
)
batch.put_item(
Item={
'series': 'ミリオンライブ',
'name': '箱崎星梨花',
'type': 'エンジェル',
'birthday': '0220',
'height': 146
}
)
batch.put_item(
Item={
'series': 'ミリオンライブ',
'name': '北沢志保',
'type': 'フェアリー',
'birthday': '0118',
'height': 161
}
)
batch.put_item(
Item={
'series': 'ミリオンライブ',
'name': '七尾百合子',
'type': 'プリンセス',
'birthday': '0318',
'height': 154
}
)
複数 put_itemしたいときは batch_writer を使います。
レコード(Item)の取得
Scan
いくつかのパターンで実行してみました。
def scan(resource):
"""
Scan
"""
table = resource.Table("idolmaster")
print('-----------------------------------')
print('case1 全件取得')
result = table.scan()
dump(result)
print('-----------------------------------')
print('case2 Filter')
result = table.scan(
FilterExpression=Attr('home').eq('東京')
)
dump(result)
print('-----------------------------------')
print('case3 Filter or ')
result = table.scan(
FilterExpression=Attr('home').eq('東京') | Key('series').eq('シンデレラガールズ')
)
dump(result)
print('-----------------------------------')
print('case4 Filter and ')
result = table.scan(
FilterExpression=Attr('home').eq('東京') & Key('series').eq('シンデレラガールズ')
)
dump(result)
print('-----------------------------------')
print('case5 Filter and 2 ')
result = table.scan(
FilterExpression=Attr('home').eq('東京') & Attr('series').eq('シンデレラガールズ')
)
dump(result)
print('-----------------------------------')
print('case6 Limit')
result = table.scan(
FilterExpression=Attr('series').eq('ミリオンライブ'),
Limit=2
)
dump(result)
print('-----------------------------------')
print('case7 Limit 2')
result = table.scan(
FilterExpression=Attr('series').eq('ミリオンライブ'),
Limit=10
)
dump(result)
Filter の And と Or は Python の and と or ではなく、& と | を使います。
Filter での属性の指定は Attr('属性名')を使います。
実行結果は以下の通りです。
-----------------------------------
case1 全件取得
-----size:9
[
{
"series": "シンデレラガールズ",
"name": "島村卯月",
"height": "159",
"birthday": "0424",
"type": "キュート",
"home": "東京"
},
{
"series": "シンデレラガールズ",
"name": "本田未央",
"height": "161",
"birthday": "1201",
"type": "パッション",
"home": "千葉"
},
{
"series": "シンデレラガールズ",
"name": "渋谷凛",
"height": "165",
"birthday": "0810",
"type": "クール",
"home": "東京"
},
{
"series": "SideM",
"name": "伊集院北斗",
"height": "180",
"birthday": "0214",
"type": "インテリ",
"home": "京都"
},
{
"series": "SideM",
"name": "天ヶ瀬冬馬",
"height": "175",
"birthday": "0303",
"type": "フィジカル",
"home": "神奈川"
},
{
"series": "SideM",
"name": "御手洗翔太",
"height": "163",
"birthday": "0420",
"type": "メンタル",
"home": "東京"
},
{
"series": "ミリオンライブ",
"name": "七尾百合子",
"height": "154",
"birthday": "0318",
"type": "プリンセス"
},
{
"series": "ミリオンライブ",
"name": "北沢志保",
"height": "161",
"birthday": "0118",
"type": "フェアリー"
},
{
"series": "ミリオンライブ",
"name": "箱崎星梨花",
"height": "146",
"birthday": "0220",
"type": "エンジェル"
}
]
-----------------------------------
case2 Filter
-----size:3
[
{
"series": "シンデレラガールズ",
"name": "島村卯月",
"height": "159",
"birthday": "0424",
"type": "キュート",
"home": "東京"
},
{
"series": "シンデレラガールズ",
"name": "渋谷凛",
"height": "165",
"birthday": "0810",
"type": "クール",
"home": "東京"
},
{
"series": "SideM",
"name": "御手洗翔太",
"height": "163",
"birthday": "0420",
"type": "メンタル",
"home": "東京"
}
]
-----------------------------------
case3 Filter or
-----size:4
[
{
"series": "シンデレラガールズ",
"name": "島村卯月",
"height": "159",
"birthday": "0424",
"type": "キュート",
"home": "東京"
},
{
"series": "シンデレラガールズ",
"name": "本田未央",
"height": "161",
"birthday": "1201",
"type": "パッション",
"home": "千葉"
},
{
"series": "シンデレラガールズ",
"name": "渋谷凛",
"height": "165",
"birthday": "0810",
"type": "クール",
"home": "東京"
},
{
"series": "SideM",
"name": "御手洗翔太",
"height": "163",
"birthday": "0420",
"type": "メンタル",
"home": "東京"
}
]
-----------------------------------
case4 Filter and
-----size:2
[
{
"series": "シンデレラガールズ",
"name": "島村卯月",
"height": "159",
"birthday": "0424",
"type": "キュート",
"home": "東京"
},
{
"series": "シンデレラガールズ",
"name": "渋谷凛",
"height": "165",
"birthday": "0810",
"type": "クール",
"home": "東京"
}
]
-----------------------------------
case5 Filter and 2
-----size:2
[
{
"series": "シンデレラガールズ",
"name": "島村卯月",
"height": "159",
"birthday": "0424",
"type": "キュート",
"home": "東京"
},
{
"series": "シンデレラガールズ",
"name": "渋谷凛",
"height": "165",
"birthday": "0810",
"type": "クール",
"home": "東京"
}
]
-----------------------------------
case6 Limit
-----size:0
[]
-----------------------------------
case7 Limit 2
-----size:3
[
{
"series": "ミリオンライブ",
"name": "七尾百合子",
"height": "154",
"birthday": "0318",
"type": "プリンセス"
},
{
"series": "ミリオンライブ",
"name": "北沢志保",
"height": "161",
"birthday": "0118",
"type": "フェアリー"
},
{
"series": "ミリオンライブ",
"name": "箱崎星梨花",
"height": "146",
"birthday": "0220",
"type": "エンジェル"
}
]
Query
queryについても同様です。
コメントアウトしているところは、実行するとエラーとなります。
def query(resource):
"""
Query
"""
table = resource.Table("idolmaster")
print('-----------------------------------')
print('case1 no param -> error')
# result = table.query()
# dump(result)
print('-----------------------------------')
print('case2 Key')
result = table.query(
KeyConditionExpression=Key('series').eq('SideM')
)
dump(result)
print('-----------------------------------')
print('case3 Attr -> error')
#result = table.query(
# KeyConditionExpression=Attr('series').eq('SideM')
#)
#dump(result)
print('-----------------------------------')
print('case4 KeyConditionExpression no key -> error ')
#result = table.query(
# KeyConditionExpression=Key('home').eq('東京')
#)
#dump(result)
print('-----------------------------------')
print('case5 hash no eq -> error')
#result = table.query(
# KeyConditionExpression=Key('series').lt('A')
#)
#dump(result)
print('-----------------------------------')
print('case6 hash and range ')
result = table.query(
KeyConditionExpression=Key('series').eq('シンデレラガールズ') & Key('name').begins_with('島')
)
dump(result)
print('-----------------------------------')
print('case7 hash or range --> erro ')
#result = table.query(
# KeyConditionExpression=Key('series').eq('A') | Key('name').eq('島')
#)
#dump(result)
print('-----------------------------------')
print('case8 onluy range --> error')
#result = table.query(
# KeyConditionExpression=Key('name').eq('島')
#)
#dump(result)
パーティションキーにはeq条件しか使用できません。
また、ソートキーの条件はパーティションキーの条件を指定した上でないと使用できません。
実行結果は以下の通りです。
-----------------------------------
case1 no param -> error
-----------------------------------
case2 Key
-----size:3
[
{
"series": "SideM",
"name": "伊集院北斗",
"height": "180",
"birthday": "0214",
"type": "インテリ",
"home": "京都"
},
{
"series": "SideM",
"name": "天ヶ瀬冬馬",
"height": "175",
"birthday": "0303",
"type": "フィジカル",
"home": "神奈川"
},
{
"series": "SideM",
"name": "御手洗翔太",
"height": "163",
"birthday": "0420",
"type": "メンタル",
"home": "東京"
}
]
-----------------------------------
case3 Attr -> error
-----------------------------------
case4 KeyConditionExpression no key -> error
-----------------------------------
case5 hash no eq -> error
-----------------------------------
case6 hash and range
-----size:1
[
{
"series": "シンデレラガールズ",
"name": "島村卯月",
"height": "159",
"birthday": "0424",
"type": "キュート",
"home": "東京"
}
]
-----------------------------------
case7 hash or range --> erro
-----------------------------------
case8 onluy range --> error
インデックスを利用したレコード(Item)の取得
LSI
インデックステーブルに対してqueryを実行するイメージです。
def local_index(resource):
"""
Local Secondary Index
"""
index = resource.Table('idolmaster')
print('-----------------------------------')
print('case1 scan')
result = index.scan(
IndexName='typeLSIndex'
)
dump(result)
print('-----------------------------------')
print('case2 base key --> error')
#result = index.query(
# IndexName='typeLSIndex',
# KeyConditionExpression=Key('series').eq('シンデレラガールズ') & Key('name').begins_with('島')
#)
#dump(result)
print('-----------------------------------')
print('case3 query')
result = index.query(
IndexName='typeLSIndex',
KeyConditionExpression=Key('series').eq('ミリオンライブ') & Key('type').begins_with('フ')
)
dump(result)
実行結果は以下の通りです。
-----------------------------------
case1 scan
-----size:9
[
{
"series": "シンデレラガールズ",
"name": "島村卯月",
"type": "キュート"
},
{
"series": "シンデレラガールズ",
"name": "渋谷凛",
"type": "クール"
},
{
"series": "シンデレラガールズ",
"name": "本田未央",
"type": "パッション"
},
{
"series": "SideM",
"name": "伊集院北斗",
"type": "インテリ"
},
{
"series": "SideM",
"name": "天ヶ瀬冬馬",
"type": "フィジカル"
},
{
"series": "SideM",
"name": "御手洗翔太",
"type": "メンタル"
},
{
"series": "ミリオンライブ",
"name": "箱崎星梨花",
"type": "エンジェル"
},
{
"series": "ミリオンライブ",
"name": "北沢志保",
"type": "フェアリー"
},
{
"series": "ミリオンライブ",
"name": "七尾百合子",
"type": "プリンセス"
}
]
-----------------------------------
case2 base key --> error
-----------------------------------
case3 query
-----size:1
[
{
"series": "ミリオンライブ",
"name": "北沢志保",
"type": "フェアリー"
}
]
GSI
def global_index(resource):
"""
Global Secondary Index
"""
index = resource.Table('idolmaster')
print('-----------------------------------')
print('case1 scan')
result = index.scan(
IndexName='birthHeightGSIndex'
)
dump(result)
print('-----------------------------------')
print('case2 query')
result = index.query(
IndexName='birthHeightGSIndex',
KeyConditionExpression=Key('birthday').eq('0118')
)
dump(result)
取得できる属性は基のテーブルのキーとパーティションのキーのみとなっています。
実行結果は以下の通りです。
-----------------------------------
case1 scan
-----size:9
[
{
"series": "ミリオンライブ",
"name": "北沢志保",
"height": "161",
"birthday": "0118"
},
{
"series": "シンデレラガールズ",
"name": "渋谷凛",
"height": "165",
"birthday": "0810"
},
{
"series": "SideM",
"name": "御手洗翔太",
"height": "163",
"birthday": "0420"
},
{
"series": "ミリオンライブ",
"name": "箱崎星梨花",
"height": "146",
"birthday": "0220"
},
{
"series": "ミリオンライブ",
"name": "七尾百合子",
"height": "154",
"birthday": "0318"
},
{
"series": "シンデレラガールズ",
"name": "島村卯月",
"height": "159",
"birthday": "0424"
},
{
"series": "SideM",
"name": "天ヶ瀬冬馬",
"height": "175",
"birthday": "0303"
},
{
"series": "SideM",
"name": "伊集院北斗",
"height": "180",
"birthday": "0214"
},
"series": "シンデレラガールズ",
"name": "本田未央",
"height": "161",
"birthday": "1201"
}
]
-----------------------------------
case2 query
-----size:1
[
{
"series": "ミリオンライブ",
"name": "北沢志保",
"height": "161",
"birthday": "0118"
}
]
おわりに
ドキュメントを読み直すたびに新しい発見があります。それだけ理解できていないということだと思います。
制限やスループットの話もまとめたかったのですが、疲れたのでまたの機会にします。