DynamoDBには以下の単語が登場します。
- パーティションキー
- ソートキー
- プライマリキー
- ローカルセカンダリインデックス
- グローバルセカンダリインデックス
これらのキー・インデックスについて改めて整理してみました。
キー
まず「パーティション」「データの読み書きを行うAPIの種類」について整理します。その後、キーの種類について整理します。
パーティション
DynamoDBのデータは複数のパーティションに分散して保存されます。このときデータがどのパーティションに保存されるかは パーティションキー を元に決定されます。
また ソートキー が設定されている場合、データはパーティション内でソートキーを元に並べ替えられて物理的に近くに配置されます。
例として、AnimalType(パーティションキー)とName(ソートキー)で構成されるPetsテーブルのデータは以下のように分散して保存されます。
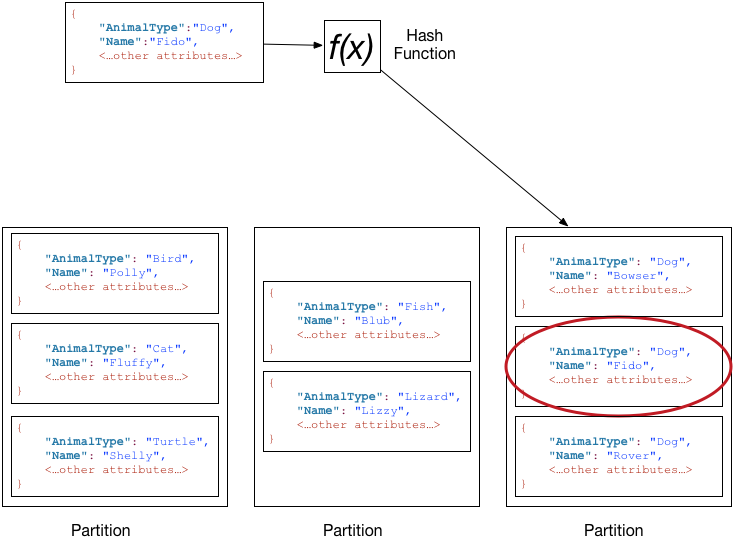
(図はパーティションとデータ分散 - Amazon DynamoDBより引用)
データの読み取りを行うAPIの種類
DynamoDBにはデータの読み書きを行う以下のAPIがあります。
- データの作成
- PutItem
- プライマリキーを指定して単一のデータを書き込む。
- BatchWriteItem
- PutItemのバッチ版。
- PutItem
- データの読み取り
- GetItem
- プライマリキーを指定して単一のデータを取り出す。
- BatchGetItem
- GetItemのバッチ版。
- Query
- パーティションキーを指定して複数のデータを取り出す。ソートキーを指定して取り出すデータの範囲をフィルタすることができる。
- Scan
- テーブルの全てのデータを取り出す。
- GetItem
- データの更新
- UpdateItem
- プライマリキーを指定して単一のデータを更新する。
- UpdateItem
- データの削除
- DeleteItem
- プライマリキーを指定して単一のデータを削除する。
- BatchWriteItem
- DeleteItemのバッチ版。
- DeleteItem
プライマリキー はデータを一意に識別するためのキーで、「パーティションキー」または「パーティションキーとソートキーの複合キー」のことです。
一部のAPIを除き、基本的にデータの読み書きはプライマリキーを指定して行います。データアクセスの特徴にあわせてパーティションキーとソートキーを設計すると良いでしょう。
キーの種類
ここまでの内容をもとに、キーの種類を整理します。
- パーティションキー
- データをどのパーティションに配置するか決定する。
- 各パーティションへのアクセスがなるべく均一になるようパーティションキーを設計すると良い。
- ソートキー
- ソートキーによってデータはパーティション内で並べ替えられて物理的に近くなるように配置される。
-
QueryAPIではソートキーを指定して取り出すデータの範囲をフィルタできる。 - ソートキーの設定は任意。
- プライマリキー
- 「パーティションキー」または「パーティションキーとソートキーの複合キー」のこと。
- プライマリキーによってデータは一意に識別される。
セカンダリインデックス
オリジナルのテーブルのパーティションキー・ソートキーだけでは不十分な場合、別のパーティションキー・ソートキーを設定することができます。それが グローバルセカンダリインデックス(GSI) と ローカルセカンダリインデックス(LSI) です。
グローバルセカンダリインデックスの例
例としてゲームのスコアを格納するGameScoresテーブルを考えます。この例と図はグローバルセカンダリインデックス - Amazon DynamoDBの引用です。
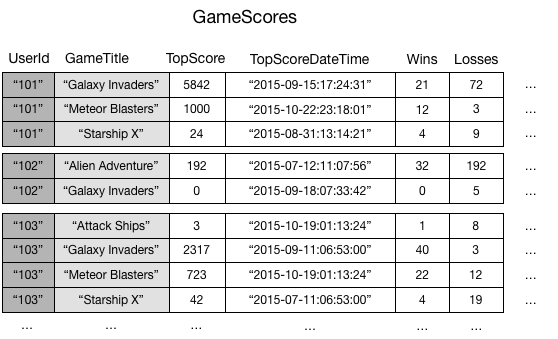
このテーブルのパーティションキーはUserId、ソートキーはGameTitleです。
ここで「各ゲームのトップスコアを持つユーザは誰か?」という問題を考えます。今のパーティションキー・ソートキーの設計では効率よくこの答えを出すことはできません。
そこでGameTitleをパーティションキー、TopScoreをソートキーとする別のテーブルを作成します。また必要なのはユーザ情報のみなので、新しいテーブルはUserIdのみを持つようにします。

これで「各ゲームのトップスコアを持つユーザは誰か?」という問題の答えを効率よく出せるようになりました。
このように、あるテーブルをベースに、異なるパーティションキー・ソートキーのテーブルを作成する仕組みを グローバルセカンダリインデックス(GSI) といいます。
ローカルセカンダリインデックスの例
例としてフォーラムのスレッドのデータを格納するThreadテーブルを考えます。この例と図はローカルセカンダリインデックス - Amazon DynamoDBの引用です。
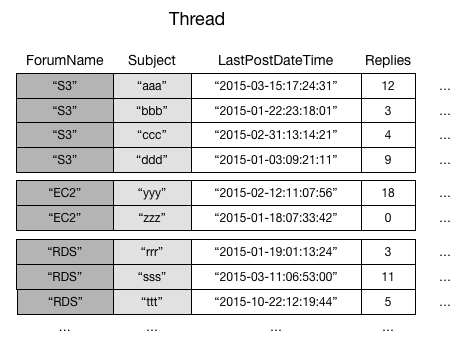
このテーブルのパーティションキーはForumName、ソートキーはSubjectです。
ここで「フォーラム毎に過去nヶ月に更新のあったスレッドのタイトル一覧を表示したい」という問題を考えます。今のパーティションキー・ソートキーの設計では効率よくこの答えを出すことはできません。
そこでパーティションキーはそのままで、LastPostDateTimeをソートキーとする別のテーブルを作成します。また必要なのはタイトルのみなので、新しいテーブルはSubjectのみを持つようにします。
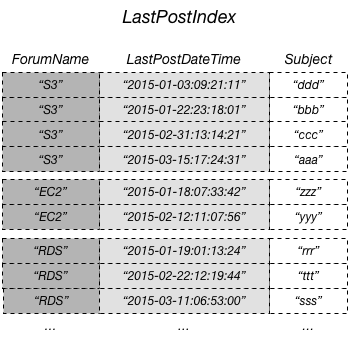
これで「フォーラム毎に過去nヶ月に更新のあったスレッドのタイトル一覧を表示したい」という問題の答えを効率よく出せるようになりました。
このように、あるテーブルをベースに、パーティションキーはそのままに、異なるソートキーのテーブルを作成する仕組みを ローカルセカンダリインデックス(LSI) といいます。
グローバルセカンダリインデックスとローカルセカンダリインデックスの比較
| グローバルセカンダリインデックス | ローカルセカンダリインデックス | |
|---|---|---|
| 新しく設定するキー | パーティションキー、ソートキー(*1) | ソートキーのみ |
| キーの重複(*2) | 可 | 可 |
| インデックス数の上限 | 5 | 5 |
| 項目コレクションのサイズ制限 | なし | 10GB以下 |
| テーブル作成後の追加 | 可 | 不可 |
| 読み込み整合性 | 結果整合性 | 結果整合性、強い整合性 |
| キャパシティユニットの消費 | GSIから消費 | ベーステーブルから消費 |
*1: ソートキーの設定は任意
*2: インデックスにおいては一意制約はありません(参考:DynamoDBでGSIやLSIのキーは重複や値なしが許容されるのか確認してみた | DevelopersIO)
項目コレクションのサイズ制限
ベーステーブルおよびローカルセカンダリインデックスの同じパーティションキーを持つデータの集合を 項目コレクション と言います。以下はThreadテーブルにおける項目コレクションの例です。
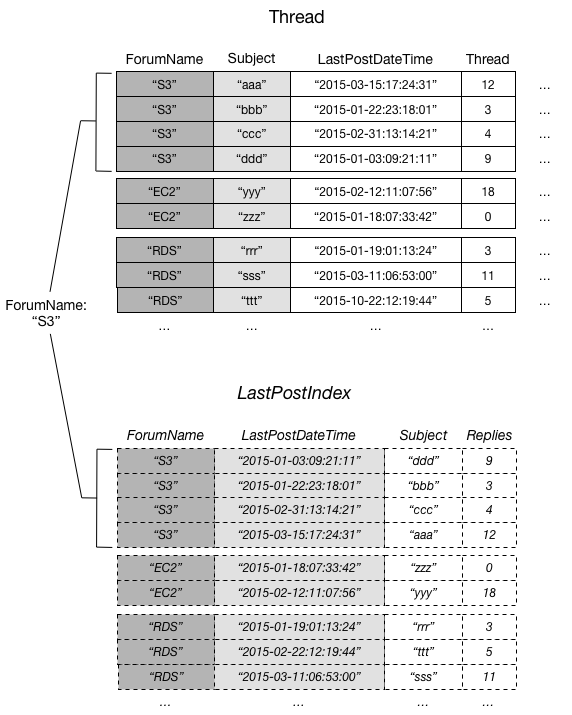
テーブルがローカルセカンダリインデックスをもつ場合、各項目コレクションのサイズは最大10GBです(ローカルセカンダリインデックスのないテーブルであればこの制限はありません)。
テーブル作成後の追加
グローバルセカンダリインデックスはテーブル作成後に作成できます。ローカルセカンダリインデックスはテーブル作成時に作成する必要があります。
読み込み整合性
グローバルセカンダリインデックスは結果整合性のみをサポートします。ローカルセカンダリインデックスは結果整合性と強い整合性をサポートします。強い整合性が必要な場合はローカルセカンダリインデックスの利用を検討します。
キャパシティユニット
セカンダリインデックスの読み込み・書き込みに対してもキャパシティユニットは消費されます。
- セカンダリインデックスに対する読み込みアクセスがあった場合、読み込みキャパシティユニットが消費されます
- ベーステーブルの更新によりセカンダリインデックスが更新された場合、書き込みキャパシティユニットが消費されます
ローカルセカンダリインデックスはベーステーブルとキャパシティユニットを共有します。ローカルセカンダリインデックスへの読み込み・書き込みがあった場合、ベーステーブルのキャパシティユニットが消費されます。
グローバルセカンダリインデックスは独自のキャパシティユニットを持ちます。グローバルセカンダリインデックスへの読み込み・書き込みがあった場合、そのグローバルセカンダリインデックスのキャパシティユニットが消費されます。