TL;DR
- 単眼カメラの画像だけを使って自動車の3次元的な検出をやってみた
- 人の姿勢推定(pose estimation)に使われるCenterNetを応用
- 改善点は多々あるもののある程度形になった

きっかけ
業務上、画像認識を専門とする会社との関わりがあるが、その会社がとにかくすごい。画像だけを元にしているにも関わらず、3次元的な物体検出をしている(自動車を例に挙げるとここが自動車の前/後面で、ここが左右側面で、というような感じ)。
これまではYOLOやSSDのような長方形のbounding boxで対象を囲むような物体検出しか触れておらず、どのような手法を使っているのか全く想像ができなかった。この記事は、画像のみを使った3次元の物体検出について色々調べてみて、自動車の3次元的な検出を自分で試してみた記録です。
3次元物体検出について調べてみる
今回目指したのは、画像のみを使って自動車をこんな感じで立体的に認識することです。

ひとまず、画像だけを元にして3次元的な物体検出に使えそうな手法を調べてみました。自分が何も知らなかっただけで色々な手法があるようです。
- 姿勢推定
画像を元に人の姿勢、関節の位置なんかを推定する手法。人間以外でもある程度形の決まっているものであれば、その形を人間の関節の繋がりみたいに置き換えてやれば、いろんなものに使えそう。人の姿勢推定についてはDeNAのブログに最新の動向が分かりやすくまとめられていました。
https://engineer.dena.com/posts/2019.11/cv-papers-19-2d-human-pose-estimation/
- 深度推定
画像を元にカメラから物体への深度を推定する手法。すごい。
https://ai.googleblog.com/2019/05/moving-camera-moving-people-deep.html
ただし物体検出を行うためには、画像を使った既存の手法と組み合わせるか、推定した深度を使ってさらに物体検出を行わなければならない。と思う。まさに後者の手法をとったのがこの論文。
https://arxiv.org/pdf/1812.07179.pdf
- Segmentation
画像のpixelごとに何が写っているのかを分類する手法。自動車の前後、左右の側面でそれぞれ属性を変えてやれば、3次元的な認識もできるはず。
今回は姿勢推定に使われる手法を応用することにしました。
- 他のものに隠れて一部分しか画像に写ってい場合でも、画像に写っている部分から隠れた部分を推測できそう
- 比較的実装が簡単そう
といった理由からです。
実装
正解データの与え方
今回は姿勢推定に使われるCenterNetを使いました。
CenterNetでは、認識対象の中心点と各関節の位置、また各関節間のベクトルを学習させることで姿勢推定を行なっています。(CenterNetでは姿勢推定だけでなく、従来のBounding Boxによる認識や認識対象のxyz座標を認識させたり、いろいろな使い方があるようです。)

https://github.com/xingyizhou/CenterNet
姿勢推定と同様の手法が使えるよう、自動車の直方体を、
自動車の中心点
┣自動車の前面 or 後面
┃┗前後の面をなす四角形の4つの頂点
┗自動車の左側面 or 右側面
┗左右の面をなす四角形の4つの頂点
のような繋がりと見立て、
自動車の中心点、側面の中心点、直方体の頂点の位置、
自動車の中心点から側面の中心点のベクトル、側面の中心点から直方体の頂点へのベクトル
を正解データとして与えました。

学習させたデータを可視化するとこんな感じです。上の図では、
自動車の中心点
┣自動車の前面 or 後面
┃┗前後の面をなす四角形の4つの頂点
┗自動車の左側面 or 右側面
┗前後の面をなす四角形の4つの頂点
という色付けをしています。
ネットワーク構造
U-Netに近い構造にしましたが、計算時間の関係から元の画像サイズまでは戻していません。
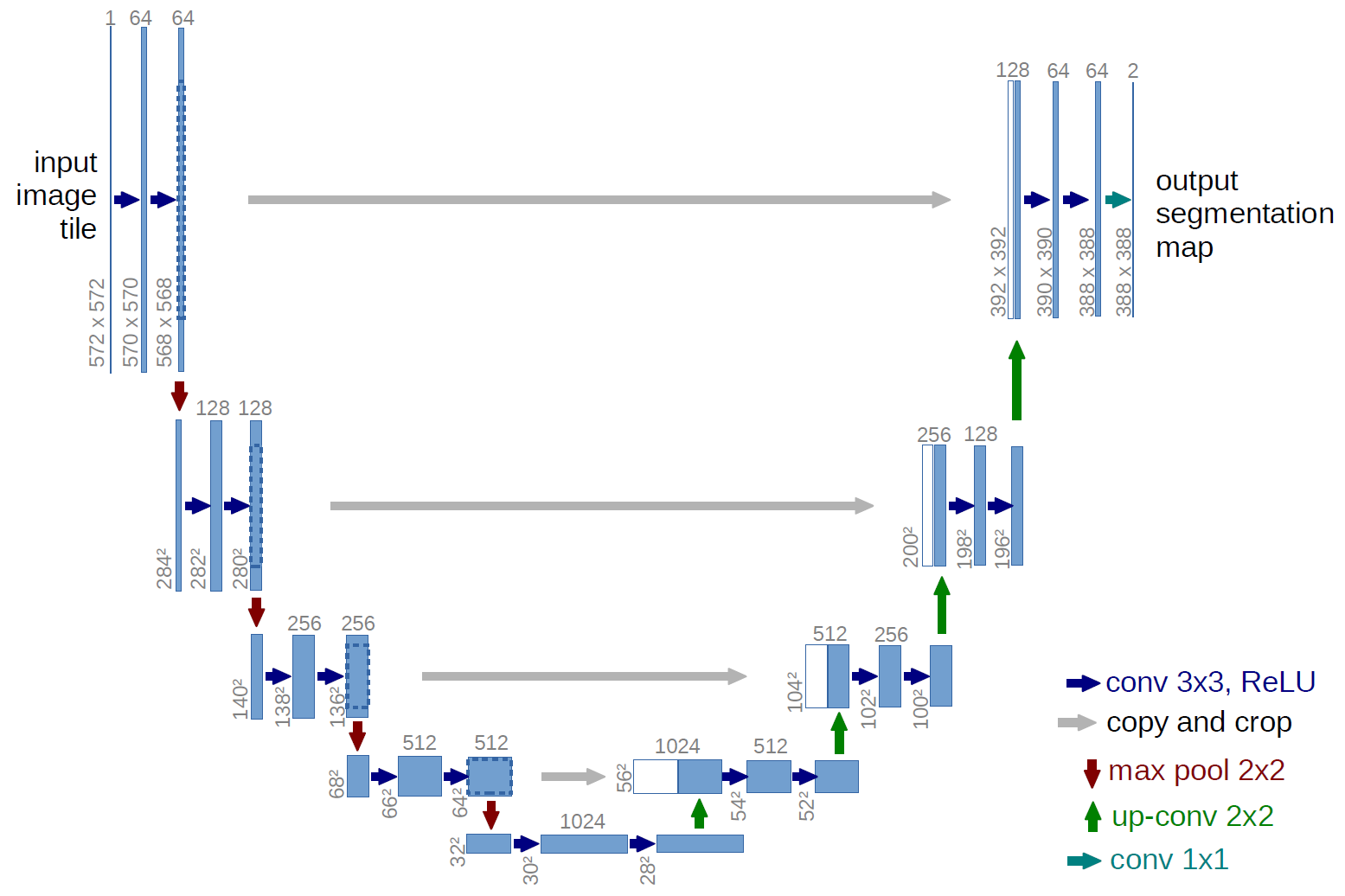
https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
画像サイズを小さくしていく部分にはEfficientNetの学習済みパラメータを使いました。
データセット
KITTIの3D Object Detection Evaluation 2017を使いTrainingデータを19:1でtraining用、validation用に分けました。
http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
学習
EfficientNetの部分の重みを固定して30Epoch分を転移学習、その後EfficientNetの部分の重みの固定を解除して20Epoch分Fine Tuningさせました。
評価関数の最適化のために試行錯誤するのはこれからで、とりあえず学習させてみた、という程度の途中経過です。
結果
KITTIからダウンロードできるテスト用のデータでの推論結果を紹介します。
割とうまく認識できているもの
うまく認識できているものを選んだと言うよりは、他の画像についても大体この程度の精度で認識できていました。


イマイチうまく認識できていないもの
画像中央にある横向きの自動車をうまく認識できていません。Occlusionが発生している場合のロバスト性はまだまだ改善の余地がありそう。

画像左側でいくつか誤検出があります。

やってみて思ったこと
- CenterNetはYoloと比較してもAnker Boxの選択がない分アルゴリズムとしてシンプルですし、初中級者レベルの自分でも意外と簡単に実装できました。それでいてオーソドックスなBounding Boxでの認識も、今回のような3次元での認識もできるし、いろいろ使えそうです。
- 自動車の検出のためのラベル(赤で塗りつぶしている部分)はKITTIのリファレンスデータから独自に作りました。後から思ったのは、自動車のInstance Segmentationの学習済みデータをうまく活用すると大幅に精度が上がるのではないか、ということです。今回の実装はSegmentationによく使われるU-Netに近いものなので、相性もかなり良さそうです。
今後やってみたいこと
- Segmentationと組み合わせて精度をあげる
- Jetsonとかを使ってリアルタイムに動かす
- 自動車の位置、動きを認識(今回のもの+α→カルマンフィルタ)