はじめに ー 週末研究ノートとは?
個人的に研究的な活動をやるにあたり、オープンにしてみたら面白いかもと思い、自分が興味を持っている ざっくりテーマについて、これから、ゆるい週末研究を公開していこうと思います。(有識者の方のアドバイスも、ちょっとというかかなり期待してます!笑)
どこかの権威的な学会やジャーナルなどで発表する予定はないため、万が一、私の記事を利用する際には自己責任でお願いします。そんな人はいないと思いますが、念のため。
今回のサマリ (TL; DR)
- Semantic Kernelを使って、シンプルな(ナイーブな?)メモリ検索機能を追加してみました
- 「LLMについて教えて?」と質問して結果を比較
- メモリなしだと、『LLMは「Master of Laws」の略称』として回答しました
- 記事:日の丸LLMへ産官学連携、「汎用スパコン」富岳で挑む富士通の勝算の内容をメモリに入れてから、同じ質問をすると、『LLM(Large Language Model)』として回答しました
- 会話履歴も検索するようにしているため、関連ある履歴メモリを踏まえて回答してくれました(元々の狙い)
- チャンク単位でサマリ(LLM実行)をしている関係もあり、応答時間が長く感じました
- OpenAI API の応答時間も関係している様子
環境
- CPU: Intel(R) Core(TM) i7-7700K CPU @ 4.20GHz
- cpu cores: 4
- processors: 8
- Memory: 47GiB available
- OS: Ubuntu 22.04.2 LTS
- Docker:
- Docker version 24.0.2
- Docker Compose version v2.18.1
- Python: 3.10.6
- openai: 0.27.7 (GPT-4 を使える状態にしておく必要があります)
コードは、こちら (llm-tools ブランチ)
今回の週末研究ノート
実験
環境構築(コンテナ作成等)
make
実行方法
今回の Semantic Memory のデモサーバは、以下のように起動します。
$ make bash
docker compose exec app bash
devuser@e981653b56c1:~/workspace$ cd backend/
devuser@e981653b56c1:~/workspace/backend$ make demo-semantic-memory
python -m app.semantic_kernel.executable.demo
/usr/local/lib/python3.10/dist-packages/gradio/components/chatbot.py:228: UserWarning: The `style` method is deprecated. Please set these arguments in the constructor instead.
warnings.warn(
/usr/local/lib/python3.10/dist-packages/gradio/components/textbox.py:259: UserWarning: The `style` method is deprecated. Please set these arguments in the constructor instead.
warnings.warn(
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
http://localhost:7860 等にアクセスすると、以下の様な画面が表示されます。
メモリ追加前
まずは、左下のボックス(「LLMについて教えて?」と書いてあるボックス)にフォーカスを当てて、Shift + Enter で実行します。
すると、『LLMは「Master of Laws」の略称で、法学修士の学位を指します。・・・』と説明をしてくれます。
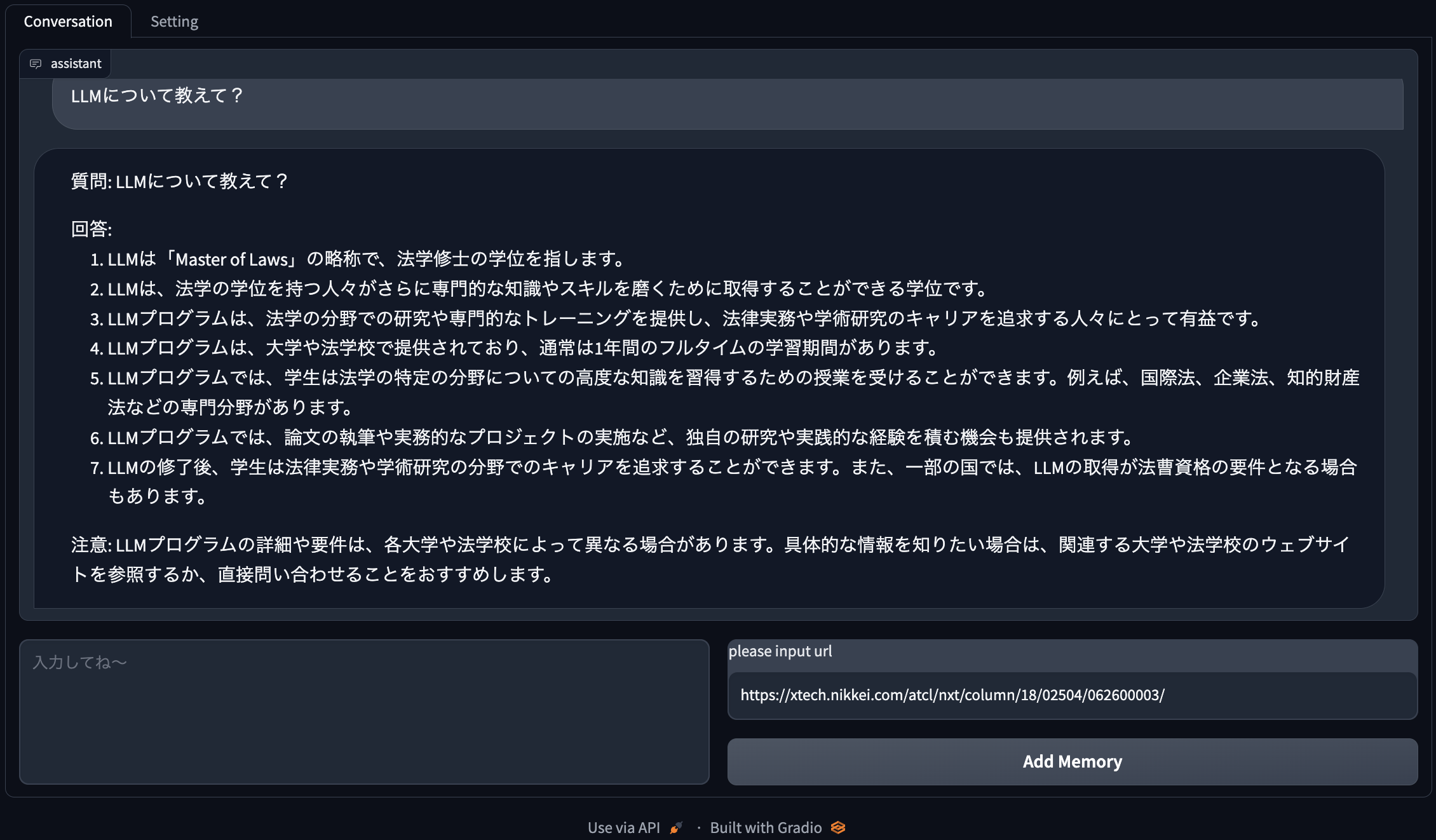
メモリ追加後
では、次にリロードして、一時的なメモリとして、右下にあるURL(https://xtech.nikkei.com/atcl/nxt/column/18/02504/062600003/ )(記事:「日の丸LLMへ産官学連携、「汎用スパコン」富岳で挑む富士通の勝算」)を追加してみましょう。
すでに、URL(https://xtech.nikkei.com/atcl/nxt/column/18/02504/062600003/ )が記載されているので、↓の図のように右下にある「Add Memory」をクリックして実行します。
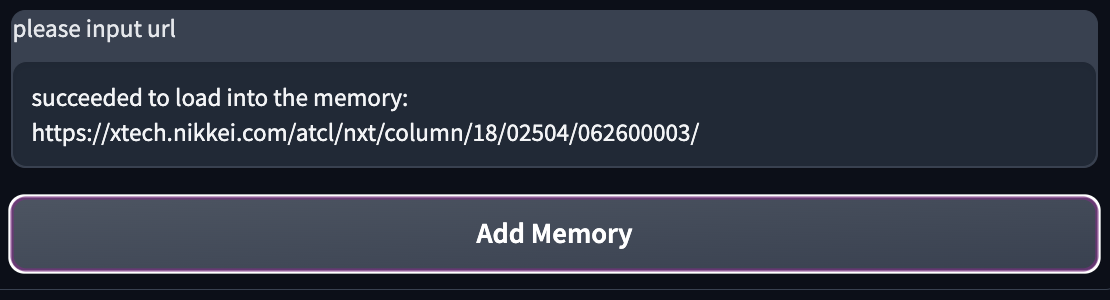
ロードが成功すると、以下のようにテキストが更新されます。
次に、改めて同じ質問(「LLMについて教えて?」と表示されたままShift+Enter)をしてみます。
しばらく待つと、以下のような感じで表示されます。
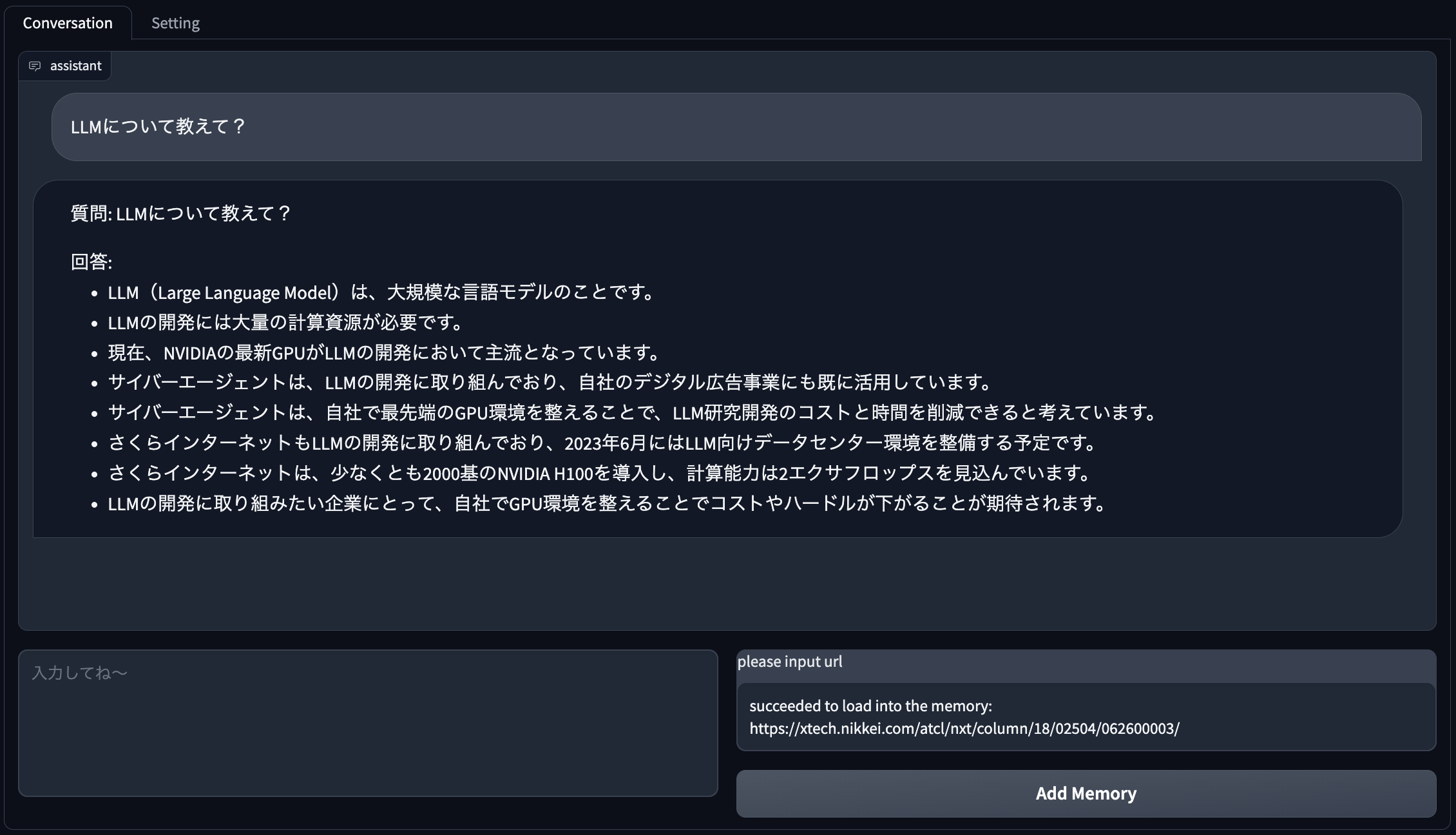
すると、『LLM(Large Language Model)は、大規模な言語モデルのことです。・・・』と先程と異なる回答をしてくれました。
先程の動きと比べると、指定したURLの内容を反映して回答してくれていることがわかります!(計画どおり!笑)
続けてみます
「サイバーエージェントとLLMの関係についてだけ正確に抜き出してくれますか?」と聞いてみます。
同様にしばらく待ちます・・
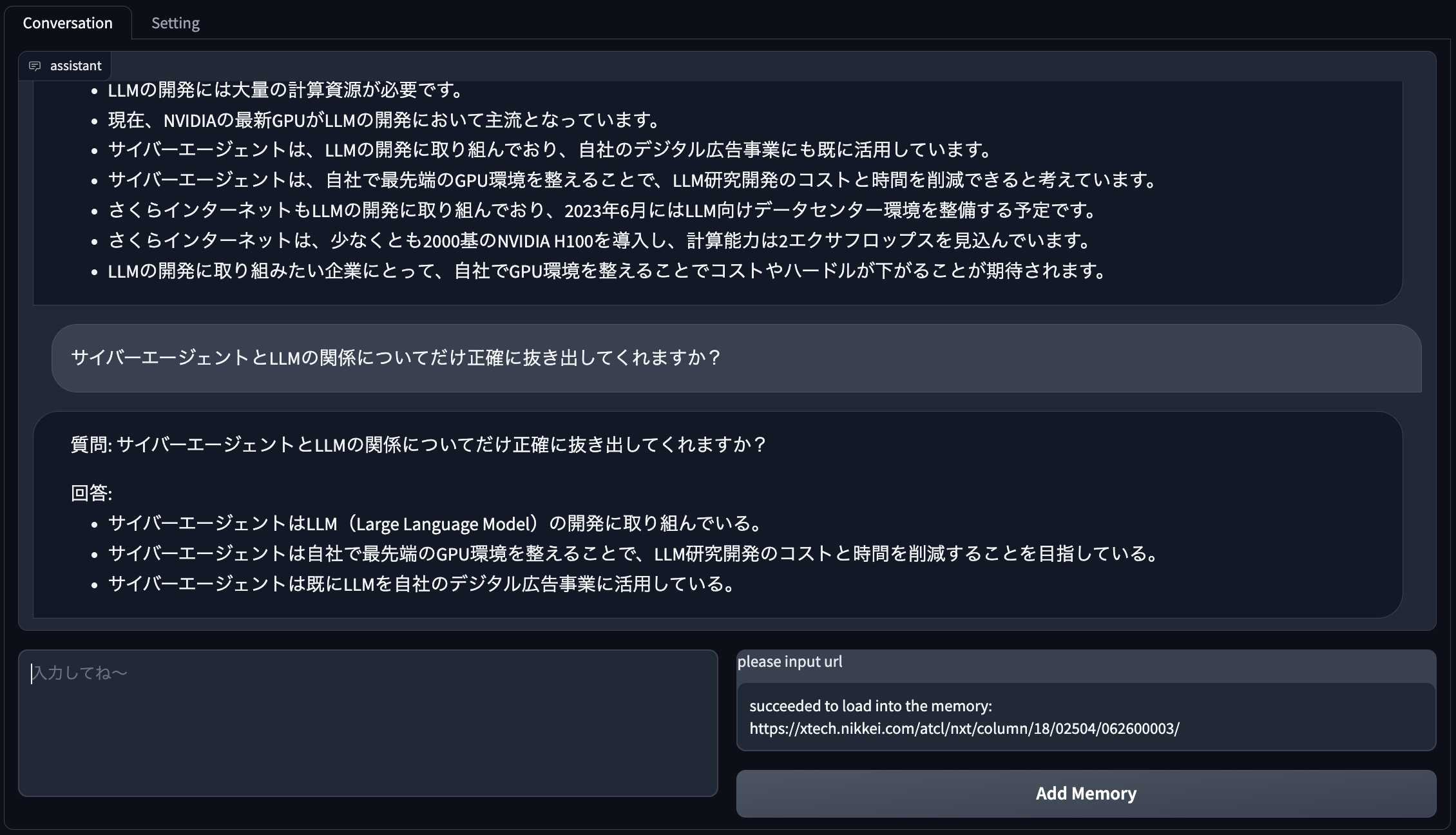
いいですね。
もう少し続けてみます
次は、「さくらインターネットとLLMの関係についてだけ正確に抜き出してくれますか? ただし、サイバーエージェントの情報は除いてください」と違う内容について聞いてみます。
※ サイバーエージェントの情報も織り交ぜてきたりするので、明確に除くように指示するようにしました。
しばらく待ちます・・
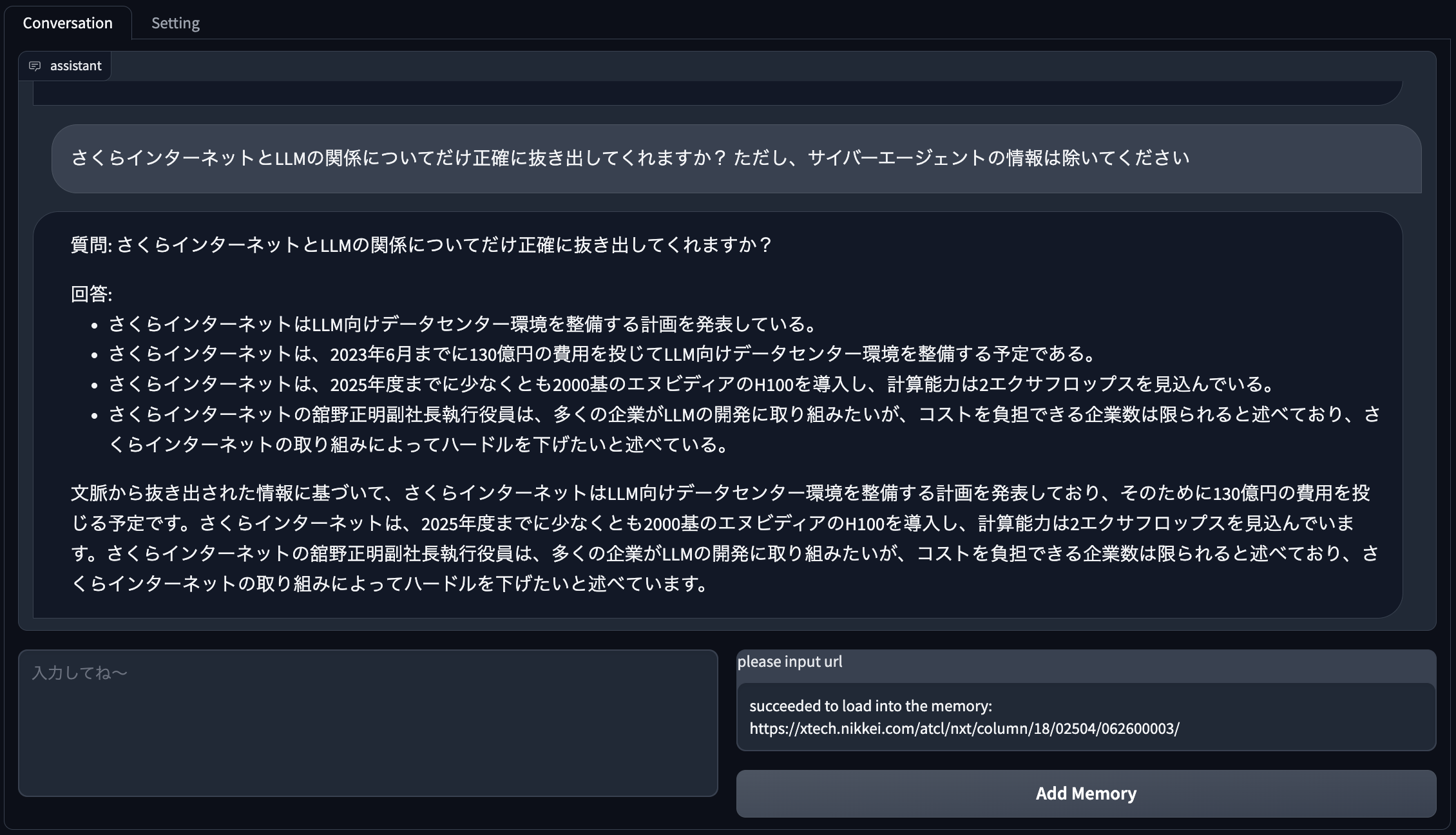
おおむね合ってますね。(「2023年6月まで」と回答してきましたが、正確には「2023年6月に発表」という内容でした。これは最初の要約を作成する際に誤った要約内容を引きずっているようです。ここは今後の課題ですね。)
しかし、思いのほかまともな回答をしてくれている印象です。
正直、半信半疑だったんですが、ChatGPTのように会話の流れを引き継いで回答できるようになりました。
まだ、若干、会話の流れに引きづられすぎる印象もあるので、もう少しいい感じに会話ができるといいな〜、という欲も出てきました笑
コードの紹介
せっかくなので、今回作成した主なコードを紹介しておきます。
SemanticBot クラス
まずは、ボットクラスのコードを紹介します。
class SemanticBot(object):
def __init__(self) -> None:
self.memory = SemanticMemory()
def _llm(self, **params):
response = openai.ChatCompletion.create(**params)["choices"][0]["message"][
"content"
]
return response
async def do_chat(
self,
history: list[tuple[str, str]],
model_name: str,
temperature_percent: int, # in [0, 200]
max_tokens: int = 1024,
) -> list[tuple[str, str]]:
query: str = history[-1][0]
temperature: float = temperature_percent / 100
task = asyncio.create_task(self.memory.search(query=query))
results = await task
previous_context = self.summarize(
query, search_results=results, model_name=model_name
)
prompt = f"""必要に応じて`文脈:`を参考に、以下の`質問:`について正確な回答をするようにステップバイステップでロジックツリー形式で回答してください。
質問:
```
{query}
```
文脈:
```
{previous_context if previous_context else "なし"}
```
"""
answer = self.exec_llm(
query=prompt,
model_name=model_name,
temperature=temperature,
max_tokens=max_tokens,
)
assert answer
history[-1][1] = answer # may be changed url to href
context = f"Q: {query}\nA: {answer}"
await self.memory.append(context)
return history
def summarize(
self, query: str, search_results: list, model_name: str = "gpt-3.5-turbo"
):
template = (
f"以下の文を 質問 `{query}` の意図に正確に答えるように500文字以内になるようにステップバイステップで要点をまとめて洗練させてください。" # noqa
+ """
```
{{$input}}
```
"""
)
summarizer = SemanticMemorySummarizer(template=template, model_name=model_name)
summarized: str = summarizer.summarize_results(search_results)
return summarized
def exec_llm(
self,
query: str,
model_name: str,
temperature: float, # in [0, 2.0]
max_tokens: int = 1024,
):
messages = [{"role": "user", "content": query}]
params = {
"model": model_name,
"max_tokens": max_tokens,
"temperature": temperature,
"messages": messages,
}
answer = self._llm(**params)
return answer
SemanticMemory クラス
class SemanticMemory(object):
def __init__(self, memory_key: str = "memory") -> None:
self.memory_key = memory_key
self.kernel: sk.Kernel = None
self.setup_kernel()
assert self.kernel is not None
def setup_kernel(self, embedding_model: str = "text-embedding-ada-002") -> Self:
kernel = sk.Kernel()
api_key = os.environ.get("OPENAI_API_KEY")
org_id = os.environ.get("OPENAI_ORG_ID")
kernel.add_text_embedding_generation_service(
"ada", OpenAITextEmbedding(embedding_model, api_key, org_id)
)
kernel.register_memory_store(memory_store=sk.memory.VolatileMemoryStore())
self.kernel = kernel
return self
async def append(
self, text: str, memory_id: str = None, additional_metadata: str = None
) -> Self:
if memory_id is None:
memory_id = build_ulid(prefix="INF")
await self.kernel.memory.save_information_async(
self.memory_key,
id=memory_id,
text=text,
additional_metadata=additional_metadata,
)
return self
def clear(self) -> Self:
# recreate the memory store
self.kernel.memory = None
self.kernel.register_memory_store(memory_store=sk.memory.VolatileMemoryStore())
assert self.kernel.memory is not None
return self
async def search(
self, query: str, limit: int = 3, min_relevance: float = 0.8
) -> list[MemoryQueryResult]:
self.query = query
results = await self.kernel.memory.search_async(
self.memory_key, query, limit=limit, min_relevance_score=min_relevance
)
return results
SemanticMemorySummarizer クラス
@dataclass
class SemanticMemorySummarizer(object):
template: str
model_name: str = "gpt-3.5-turbo"
max_tokens: int = 2000
chunk_size: int = 1024
def __post_init__(self) -> None:
self.kernel: sk.Kernel = None
self.setup_kernel(model_name=self.model_name)
assert self.kernel is not None
self.summarizer = self.kernel.create_semantic_function(
self.template, max_tokens=self.max_tokens, temperature=0.0, top_p=0.8
)
def setup_kernel(self, model_name: str = "gpt-3.5-turbo") -> Self:
kernel = sk.Kernel()
api_key = os.environ.get("OPENAI_API_KEY")
org_id = os.environ.get("OPENAI_ORG_ID")
kernel.add_chat_service(
"gpt", OpenAIChatCompletion(model_name, api_key, org_id)
)
self.kernel = kernel
return self
def summarize_results(self, results: list[MemoryQueryResult]) -> str:
summarized: str = ""
for r in results:
g_logger.info(f"{r.additional_metadata=} / {r.relevance}")
text = re.sub(r"\n+", "\n", r.text)
text = re.sub(r"\s\s+", " ", text)
summarized = summarized + "\n" + text
summarized: str = self.summarize(summarized)
g_logger.info(f"{text=}")
g_logger.info(f"{summarized=}")
return summarized
def summarize(self, text: str) -> str:
summarized: str = ""
for idx in range(0, len(text), self.chunk_size):
response = self.summarizer(
summarized + "\n" + text[idx : idx + self.chunk_size]
)
summarized: str = response.result
return summarized
動作確認用サンプルコード
async def _main():
import requests
from bs4 import BeautifulSoup
g_logger.info("Start")
urls = [
"https://xtech.nikkei.com/atcl/nxt/column/18/00001/08164/",
"https://xtech.nikkei.com/atcl/nxt/column/18/00682/062700127/",
"https://xtech.nikkei.com/atcl/nxt/column/18/00001/08158/",
"https://xtech.nikkei.com/atcl/nxt/column/18/02504/062700004/",
"https://xtech.nikkei.com/atcl/nxt/column/18/02498/061500001/",
"https://xtech.nikkei.com/atcl/nxt/column/18/02504/062600003/",
]
smm = SemanticMemory()
g_logger.info("processing to register web page chunks")
for url in urls:
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
memory_chunk_size = 1024
for idx in range(0, len(soup.text), memory_chunk_size):
await smm.append(
text=soup.text[idx : idx + memory_chunk_size], additional_metadata=url
)
query = "LLMについて教えて"
task = asyncio.create_task(smm.search(query=query))
results = await task
g_logger.info("processing to summarize")
template = (
f"以下の文を 質問 `{query}` の意図に正確に答えるように500文字以内になるようにステップバイステップで要点をまとめて洗練させてください。" # noqa
+ """
```
{{$input}}
```
"""
)
summarizer = SemanticMemorySummarizer(template=template)
summarizer.summarize_results(results)
g_logger.info("End")
if __name__ == "__main__":
import asyncio
asyncio.run(_main())
サンプルコードの実行
#動作確認用サンプルコードを実行してみます。
devuser@e981653b56c1:~/workspace/backend$ make summary-semantic-memory [6/1066]
python -m app.semantic_kernel.component.semantic_memory
2023/07/03 00:51:55.432 app INFO Start
2023/07/03 00:51:55.432 app INFO processing to register web page chunks
2023/07/03 00:52:15.683 app INFO processing to summarize
2023/07/03 00:52:15.684 app INFO r.additional_metadata='https://xtech.nikkei.com/atcl/nxt/column/18/02504/062600003/' / 0.8358632573380915
2023/07/03 00:52:34.367 app INFO text='”の変わる業界地図」\n「日の丸LLM」への挑戦\n特集をフォロー\n日の丸LLMへ産官学連携、「汎用スパコン」富岳で挑む富士通の勝算\n玉置 亮太\n日経クロステック/日経コンピュータ\n2023.06.28\n有料会員限定\nコピーしました\n
全2401文字 日本版の大規模言語モデル(LLM)開発に立ちはだかる第3の壁が、大規模な計算資源の確保だ。優れたモデルを構築し十分な質と量の学習データを確保できたとしても、実際にモデルを学習させるには膨大な計算が必要になる。そのためには高性能なコンピューターが
不可欠だ。 生成AI(人工知能)の学習に使う大規模コンピューターの分野で現在、1強ともいえる立場を築いているのが米NVIDIA(エヌビディア)のGPU(グラフィック処理プロセッサー)だ。いま、同社のGPUを大量導入する日本企業が相次いでいる。\n日本初の最新GPU環境が稼
働へ 今夏、エヌビディアの最新GPUをそろえた生成AI向けのコンピューター環境が動き出す。サイバーエージェントが運営するデータセンターに導入される80基の「NVIDIA H100 TensorコアGPU」だ。前世代の「NVIDIA A100 TensorコアGPU」に比べて、モデルの学習を最大9倍に高
速化できるとされている。サイバーエージェントとエヌビディアによれば、H100の導入は日本で初めてだという。投資額は非公表だが、10億円近いとみられる。 サイバーエージェントはH100を使い、国内最大規模のLLMの開発に取り組む。130億パラメーターのLLMを開発し、既に自
社のデジタル広告事業に活用し始めたのに加え、68億パラメーターのLLMを公開している。 同社は最先端のGPU環境を自前でそろえることで、LLM研究開発のコスト面と心理面の両方のハードルを下げられるとみる。LLMの学習には一般に半年単位の時間がかかるとされる。米Amazon rWeb Services(AWS)をはじめ、エヌビディアのGPUをクラウドサービスとして提供する事業者も増えている。 しかし、従量課金制のクラウドサービスを半年以上使った結果、思うような成果を得られなければ時間と料金が無駄になる。サイバーエージェントの石上亮介AI事業本部AIクリエイティブDiv機械学習エンジニアは「ク'
2023/07/03 00:52:34.367 app INFO summarized='日本企業が日本版の大規模言語モデル(LLM)の開発に取り組んでいるが、そのためには大規模な計算資源が必要である。現在、生成AIの学習に使われる大規模コンピューターの分野では、米NVIDIAのGPUが主流となっている。日本
企業もNVIDIAの最新GPUを導入し、LLMの開発に取り組んでいる。サイバーエージェントが運営するデータセンターには80基の「NVIDIA H100 TensorコアGPU」が導入され、これによりモデルの学習が最大9倍に高速化されるとされている。サイバーエージェントはLLMの開発に130億パ
ラメーターのモデルを使用し、既に自社のデジタル広告事業に活用している。また、68億パラメーターのモデルも公開している。サイバーエージェントは自前で最先端のGPU環境を整えることで、LLM研究開発のコストと時間を削減できると考えている。一般的にLLMの学習には半年
以上の時間がかかるため、クラウドサービスを利用する場合でも時間と料金がかかる。しかし、自社でGPU環境を整えることで、効率的な学習が可能となる。'
2023/07/03 00:52:34.368 app INFO r.additional_metadata='https://xtech.nikkei.com/atcl/nxt/column/18/02504/062700004/' / 0.8334322858195052
2023/07/03 00:53:33.303 app INFO text='札“パワー半導体”の変わる業界地図」\n「日の丸LLM」への挑戦\n特集をフォロー\n「情報大航海の二の舞いにはならない」、日本の生成AI安全保障は実現するか\n玉置 亮太\n日経クロステック/日経コンピュータ\n2023.06.29\n有料会
員限定\nコピーしました\n全1816文字 インターネット以来とも言われる技術的転換点を迎えて、基盤技術を海外に握られたままでいいのか――。日本版の大規模言語モデル(LLM)の研究開発を巡る動きは、経済安全保障の意味合いも帯びる。研究開発の体制づくりから人材育成、計
算資源の確保まで。経済界や政界も巻き込んだ議論が芽生えつつある。\n「このままでは国富が流出」との懸念 「生成AI(人工知能)の基盤的な開発能力の醸成に不可欠なインフラである国内の計算能力、計算資源を拡充する。我が国の生成AI分野の研究開発と実装を加速してい
きたい」。2023年6月16日、西村康稔経済産業大臣は、さくらインターネットに最大約68億円の支援を表明した。目的は北海道石狩市にある同社のデータセンターでLLMや生成AIに向けたクラウドサービスを提供するための基盤整備だ。 米NVIDIA(エヌビディア)製のGPU(グラフィ
ック処理プロセッサー)「NVIDIA H100 Tensor コア GPU」を、3年後をめどに2000基導入する。130億円規模の投資額のうち、経産省はおよそ半分を補助する。 さくらインターネットの狙いは生成AI向けの安価なクラウドサービスの提供にとどまらない。LLMの研究開発やサービス
の運用に不可欠な計算資源を、海外に頼らず日本企業が自前で確保する、いわば「生成AI安全保障」の実現だ。 「内燃機関やインターネットと同様に、生成AIには時代を変えるくらいのインパクトがある。現在のインターネットサービスは外資がほとんどを占めており、使うほど
に国富が流出する。生成AIでこの図式を繰り返すことがないようにすべきだ」。同社の舘野正明副社長執行役員は、生成AI安全保障の意義を強調する。 政界や産業界からも、生成AI安全保障を訴える声が上がる。自民党は2023年5月9日、「AI新時代における日本の国家戦略」をう
たった政策提言を岸田文雄首相に手渡した。国内におけるAI開発基盤の育成・強化を訴え、LLMなど'
2023/07/03 00:53:33.304 app INFO summarized='LLM(Large Language Model)は、大規模な言語モデルのことであり、日本企業がその開発に取り組んでいます。LLMの開発には大量の計算資源が必要であり、現在はNVIDIAの最新GPUが主流となっています。日本企業もNVIDIAのGPU
を導入し、LLMの開発に取り組んでいます。\n\n具体的には、サイバーエージェントが運営するデータセンターには80基のNVIDIA H100 TensorコアGPUが導入されており、これによりモデルの学習が最大9倍に高速化されます。サイバーエージェントは130億パラメーターのモデルを使
用してLLMの開発に取り組んでおり、既に自社のデジタル広告事業にも活用しています。また、68億パラメーターのモデルも公開しています。\n\nサイバーエージェントは自社で最先端のGPU環境を整えることで、LLM研究開発のコストと時間を削減することを目指しています。一般
的にLLMの学習には半年以上の時間がかかるため、クラウドサービスを利用する場合でも時間と料金がかかります。しかし、自社でGPU環境を整えることで、効率的な学習が可能となります。\n\n日本版のLLMの研究開発は経済安全保障の意味合いも持っており、経済界や政界も関心
を寄せています。経済産業大臣の西村康稔氏は、計算能力や計算資源の拡充を促進するためにさくらインターネットに最大約68億円の支援を表明しました。これにより、さくらインターネットのデータセンターでLLMや生成AIに向けたクラウドサービスの基盤整備が行われる予定で
す。\n\n日本企業はLLMの研究開発に注力し、国内の計算能力や計算資源の拡充を図ることで、生成AIの基盤的な開発能力を醸成し、国富の流出を防ぐことを目指しています。さくらインターネットも生成AI安全保障の実現を目指し、安価なクラウドサービスの提供だけでなく、計
算資源の自前確保も重要視しています。政界や産業界からも生成AI安全保障を訴える声が上がっており、AI開発基盤の育成・強化が求められています。'
2023/07/03 00:53:33.304 app INFO r.additional_metadata='https://xtech.nikkei.com/atcl/nxt/column/18/02504/062600003/' / 0.819102787175548
2023/07/03 00:54:31.264 app INFO text='ラウドを使って大規模な学習をさせるのには覚悟が必要。心理的にも価格性能比の面でも、試行錯誤が容易なオンプレミスの計算環境は有利だ」と語る。 ただ、大規模なGPU環境を自前でそろえられる企業は限られる。そこでさくらイン
ターネットは生成AIのモデル学習やサービス開発に向けたGPU環境のクラウドサービスを構築する。3年で130億円の費用を投じ、LLM向けデータセンター環境を整備すると2023年6月に発表した。 2025年度時点でエヌビディアのH100を少なくとも2000基導入する。計算能力は2エクサ
フロップスを見込む。まずは2023年度分として32億円を投じ、2023年10月にもH100を500基導入する計画だ。サービス開始は2024年1月以降を予定する。 「LLMの開発に取り組みたい企業は多いが、コストを負担できる企業数は限られる。当社の取り組みで、ハードルをできるだけ下
げたい」。さくらインターネットの舘野正明副社長執行役員は、こう意気込みを語る。\nこの記事は有料会員限定です。次ページでログインまたはお申し込みください。\n次ページ 肝心の料金水準はどうなるのか。舘野副社長は具体的...\n1\n2\n#生成AI\n#富岳\n#LLM\nコピーし
ました\n「日の丸LLM」への挑戦\n前の記事\n日の丸LLMに立ちはだかる壁、データの質と量を確保しつつ早期実用化する鍵は\n次の記事\n「情報大航海の二の舞いにはならない」、日本の生成AI安全保障は実現するか\nあなたにお薦め\n今日のピックアップ\n総務省が富士通に行政
指導、FENICS不正侵入受け再発防止策など求める\n2023.06.30\n総点検完了後に富士通Japan製システムでまたも住民票の誤交付トラブル、宗像市で\n2023.06.30\n河野デジ相が住民票誤交付再発で「申し訳ない」、総点検の負荷試験では発見できず\n2023.06.30\n国内シェア3位、
「らくらくホン」のFCNTが1431億円の巨額負債で経営破綻\n2023.06.30\nブラック・ジャックの新作プロットを生成AIと共創、記者のさじ加減でドラマが激変\n2023.06.30\nChatGPTに絶対にで'
2023/07/03 00:54:31.264 app INFO summarized='LLM(Large Language Model)は、大規模な言語モデルのことであり、日本企業がその開発に取り組んでいます。LLMの開発には大量の計算資源が必要であり、現在はNVIDIAの最新GPUが主流となっています。\n\n具体的には、サイバ
ーエージェントが運営するデータセンターには80基のNVIDIA H100 TensorコアGPUが導入されており、これによりモデルの学習が最大9倍に高速化されます。サイバーエージェントは130億パラメーターのモデルを使用してLLMの開発に取り組んでおり、既に自社のデジタル広告事業に
も活用しています。また、68億パラメーターのモデルも公開しています。\n\nLLMの学習には通常半年以上の時間がかかりますが、サイバーエージェントは自社で最先端のGPU環境を整えることで、効率的な学習を可能にしています。これにより、クラウドサービスを利用する場合に
比べてコストと時間を削減することができます。\n\n日本版のLLMの研究開発は経済安全保障の意味合いも持っており、経済界や政界も関心を寄せています。経済産業大臣の西村康稔氏は、計算能力や計算資源の拡充を促進するためにさくらインターネットに最大約68億円の支援を
表明しました。これにより、さくらインターネットのデータセンターでLLMや生成AIに向けたクラウドサービスの基盤整備が行われる予定です。\n\n日本企業はLLMの研究開発に注力し、国内の計算能力や計算資源の拡充を図ることで、生成AIの基盤的な開発能力を醸成し、国富の流
出を防ぐことを目指しています。さくらインターネットも生成AI安全保障の実現を目指し、安価なクラウドサービスの提供だけでなく、計算資源の自前確保も重要視しています。政界や産業界からも生成AI安全保障を訴える声が上がっており、AI開発基盤の育成・強化が求められて
います。'
2023/07/03 00:54:31.265 app INFO End
devuser@e981653b56c1:~/workspace/backend$
※ python -m app.semantic_kernel.component.semantic_memory と実行しても同じです
まとめ
- 今回は、Semantic Kernelを使ってメモリ検索機能搭載のボットを作ってみました。
- 想像してたよりも、賢いボットになった印象です(Semantic Kernel すごい!)
- 会話の文脈をある程度引き継ぎを自然言語を工夫すればできそうなのは、すごい価値!ですよね?!
- 最初の要約を作成する際に誤った要約内容を引きずって回答する課題が見つかりました
- 例:「2023年6月まで」と回答してきましたが、正確には「2023年6月に発表」という内容でした
- 要約を正確にする、という対応と文献などの情報をより信じて要約するようにメモリキーを区別する等の対応は検討の余地があります
- また、チャットボットとしては、応答時間の長さが課題ですね
- 概ね2〜3分ぐらいで応答が返ってくるイメージです
- しかし、連続で使用していると、10分を超える応答待ちになることもありました
- チャンク単位でサマリ(LLM実行)をしていることが要因のため、chunk_size を大きくして、
gpt-3.5-turbo-16kなどを使うようにする等、チューニングの余地はありそう
- よかったら、みなさんも試してみて〜