これまでの記事
- オリジナルKdB(科目検索)を作ってみよう -1- Node.jsセットアップ編
- オリジナルKdB(科目検索)を作ってみよう -2- パース編
- オリジナルKdB(科目検索)を作ってみよう -3- データで遊ぶ編
- オリジナルKdB(科目検索)を作ってみよう -4- Express.jsでWEBアプリことはじめ編
- オリジナルKdB(科目検索)を作ってみよう -5- Express.jsでWEBアプリ整形編
- オリジナルKdB(科目検索)を作ってみよう -6- 本番環境Herokuにデプロイ編
- オリジナルKdB(科目検索)を作ってみよう -番外1- FaaS下準備編

この記事を読む前に
ある特定の人にしかわからない単語が出現する可能性が高いです。あらかじめご了承ください。
この記事での開発環境
- MacOS 10.14.3
- Visual Studio Code 1.31.1
- Node.js LTS 10.15.1 (AWS Lambdaでは8.10)
はじめに
「オリジナルKdB(科目検索)を作ってみよう」の番外編です。これまではExpress.jsは使わず、サーバレスなシステムを作っていきましょう。シリーズでやっていたようにExpress.jsでエンヤコラはやらずに、関数を作るだけで簡単にサービスを作ることができます。
前提条件
- AWSのアカウントを持っていること
- node.jsの開発環境があること
AWS Lambda用の関数を作成
まずはじめにAWS LambdaではNode.jsの他にPython, Ruby, Java, Go, C#(.NET)を使うことができますので、それぞれ得意な言語で書くことをオススメします。
今回は特に複雑な処理は行わないのでAWS-SDKを使わずに作れます。
それではindex.jsを作りましょう。
// exports.handlerに格納された関数がlambdaで実行できる
// AWS Lambdaから引数としてevent, context, callbackの3つが与えられる
// それぞれの説明は後述
exports.handler = (event, context, callback) => {
// 前回作ったdata.jsを読み込む
const json = require("./data")
// requestのクエリ文字列から習得(ここでは ?search=〇〇 )
const str = event.queryStringParameters.search
// 正規表現を作成して検索
const reg = new RegExp(str)
const filterCource = json.subjects.filter( (element) => {
return element.name.match(reg)
})
// データ量削減のために最初の5件のみに限定
const resJson = {
subjects: filterCource.splice(0, 5)
}
// responseを作成
const res = {
statusCode: 200,
headers: {
"Content-Type": "application/json",
"Access-Control-Allow-Origin" : "*"
},
body : JSON.stringify(resJson),
isBase64Encoded: false
}
// responseをクライアントへ
callback(null, res)
};
※AWS Lambdaではデータ転送量が多くなるほど、実行時間が長くなるほどお金がかかります。そのためresponseを5件に絞り、JSON.stringfy()のコストとデータ転送量を削減しています。
引数についての説明
event
基本的にrequestだと考えてもらって大丈夫です。ですが、ブラウザからのHTTPリクエストだけでなく、他のAWSサービスと連携してlambda関数が使われることが多いのでrequestという引数名が使われていません。注意してください。
引数eventに入ってくる情報は呼び出しもとによって様々であり、また細かく設定することができます。今回は別のAWSのサービスであるAPI Gatewayと一緒に使うので、lambda関数のeventに入る情報はある程度の規約に従います。詳しくは AWS Lambda Proxy Integrationを試してみた で説明されています。
今回はGETリクエストなので こちら に従います。特に今回使うのはevent.queryStringParametersのみなので難しくありません。
context
これは 公式のドキュメント が詳しいです。
AWS Lambda で関数を実行した環境についての情報や、ログの書き出し場所、認証情報、クライアントのプラットフォーム・OS・地域情報などなど。多くの基本情報はcontextに格納されます。
lambda関数を実行してアクセスログやエラーログを取りたいときに便利な情報がたくさん入っているところです。今回は特にログは取らないので使っていません。
callback
こちらも公式のドキュメントに詳しく書いてあります。
コールバックの詳細はcallback(Error error, Object result);となっています。
・error – オプションのパラメーターであり、Lambda 関数の失敗した実行結果を提供するために使用できます。Lambda 関数が成功すると、最初のパラメーターとして NULL を渡すことができます。
・result – オプションのパラメーターであり、関数の正常な実行結果を提供するために使用できます。提供される result は、JSON.stringify と互換性がある必要があります。エラーになる場合、このパラメーターは無視されます。
とあるように、lambda関数が成功した時はcallback(null, res)と書き、JSONオブジェクトをcallbackに渡せばいいということになります。逆にlambda関数のどこかでエラーをハンドリングした場合はcallback(error, null)と書けばいいということになります。
つまり、callbackの第2引数に渡されたJSONオブジェクトがクライアントへのレスポンスになります。今回はエラーハンドリングをしていないのでcallback(error, null)は出てきません。
lambda関数のローカル実行テスト
簡単のために Lambda用のプログラムをローカルでテスト実行する方法(簡単編)の作法に従います。次のようにlocal.test.jsを作ります。
const { performance } = require('perf_hooks'); // 実行時間の計測用
const lambda = require('./index.js');
const event = {
"queryStringParameters": {
"search": "生物", // 検索したいワードに書き換える
}
};
const context = "";
const callback = (error, result) => {
if(error){
console.error(error.message);
}else{
console.log(result)
}
}
const check = performance.now() // 実行時間を計測開始
lambda.handler(event, context, callback)
console.log(performance.now() - check) //実行時間の表示
※実際にはcontextやeventにもっと多くの情報が格納されますが、今回のlambda関数内で使っていないので省略しています。他のlambda関数を書く時は先述したこちらの記事を参考に修正する必要があります。
それではテストしてちゃんとコールバックが返ってくるか確認します。
$ node local.test.js
ちゃんと検索結果が表示されたらOKです。
Zipファイルに圧縮してAWS Lambdaにアップロードするための準備をしましょう。
$ zip -r test.zip index.js data.js node_modules
AWS Lambdaの準備
AWSのアカウントを作ったなら、AWS Lambdaのページにいきます。
こちらからどうぞ → AWS Lambda
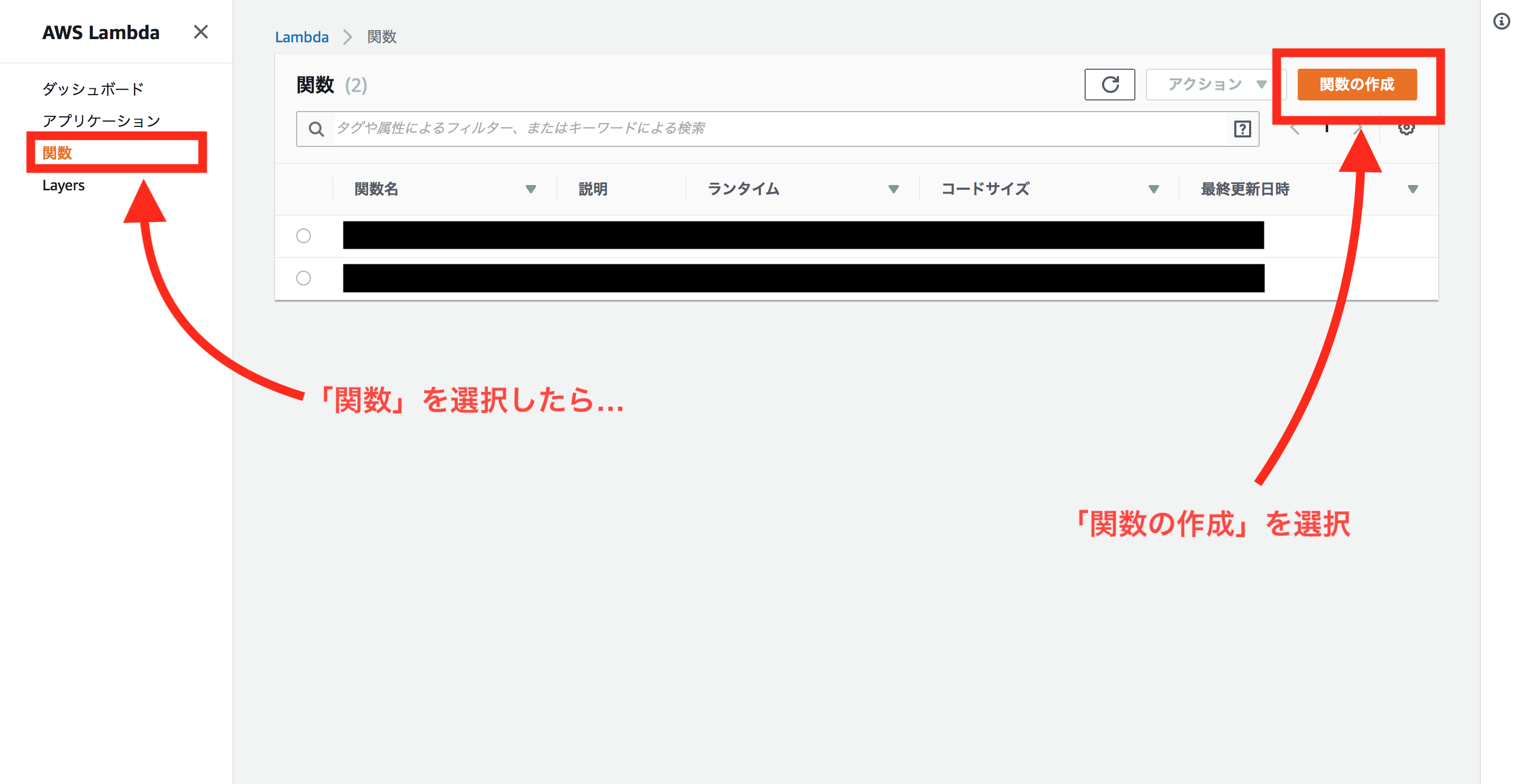
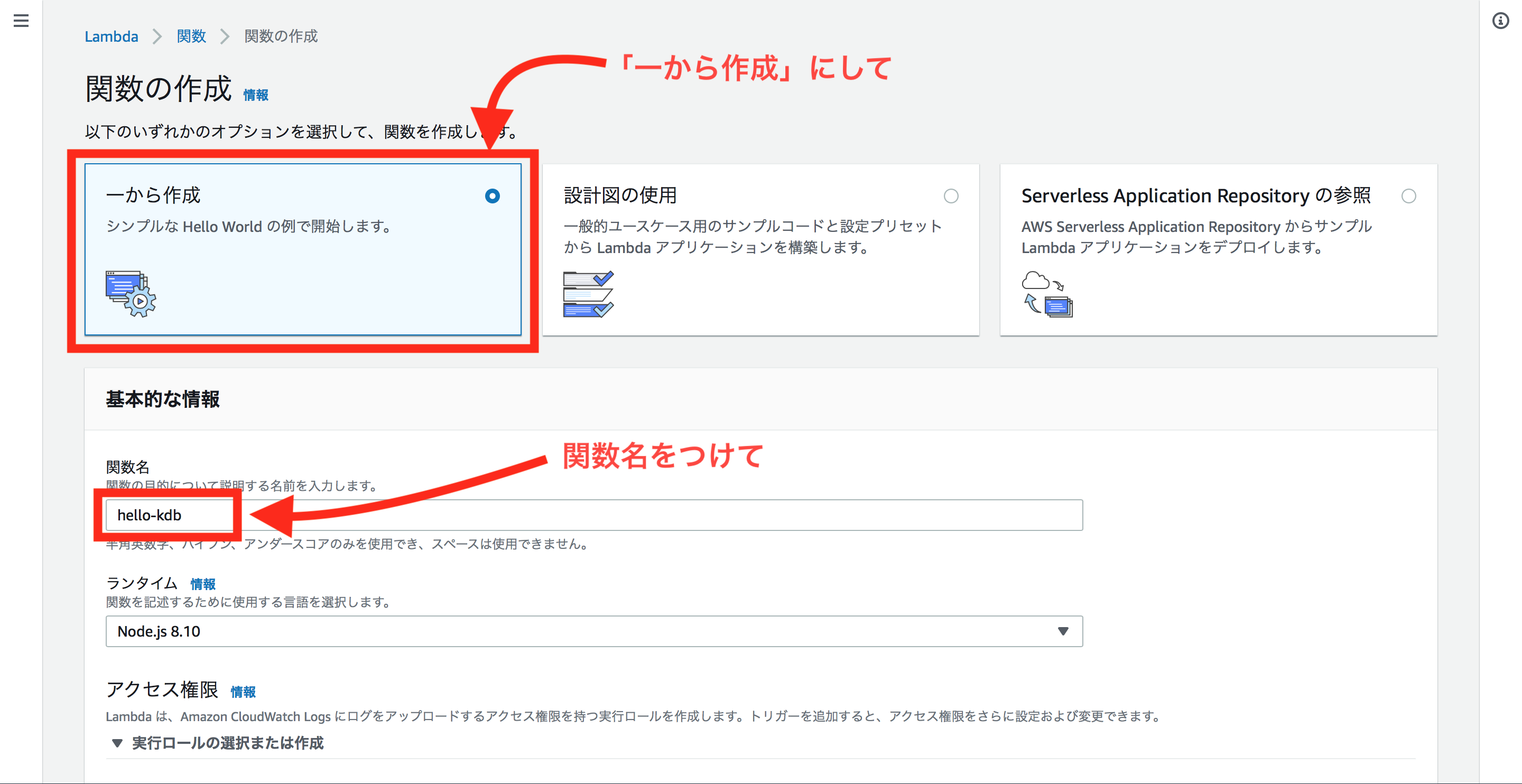
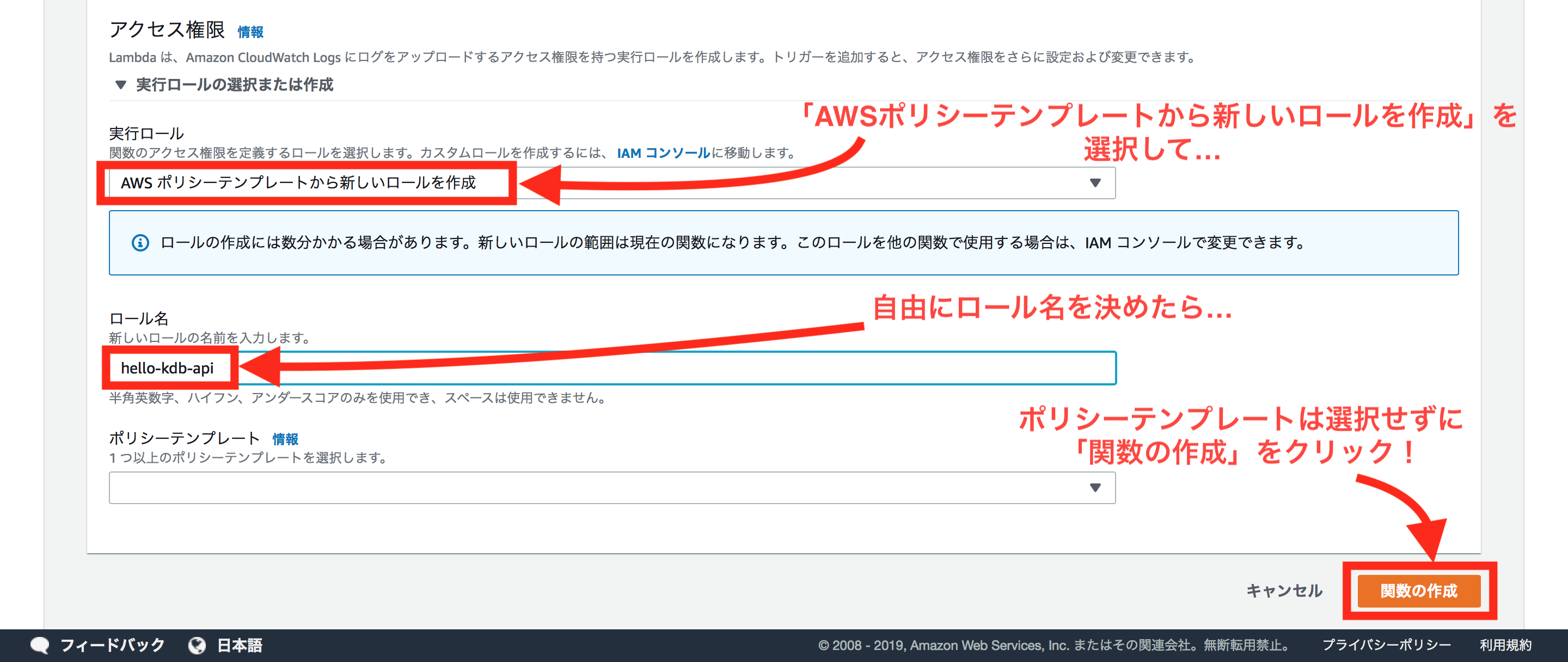

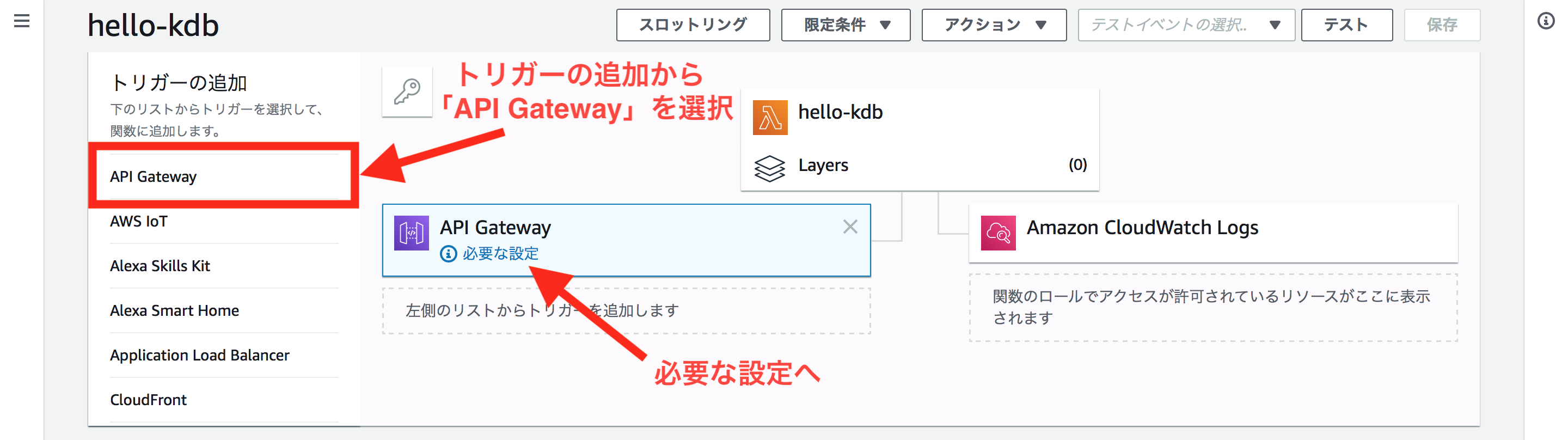


これでサーバレスに関数を実行できるはずです!
ですが今回の処理ではおそらく Internal Server Error が返ると思うので簡易的なトラブルシューティングをします。
トラブルシューティング
本番環境でテストしたか?
右上の「テストイベントの選択」をクリックしてテストイベントを作成する。次のように記述する。
{
"queryStringParameters": {
"search": "生物"
}
}

テストイベントを「作成」したら、実際に「テスト」を押して実行してみる。
ここでエラーが発生したらログをよく確認する。
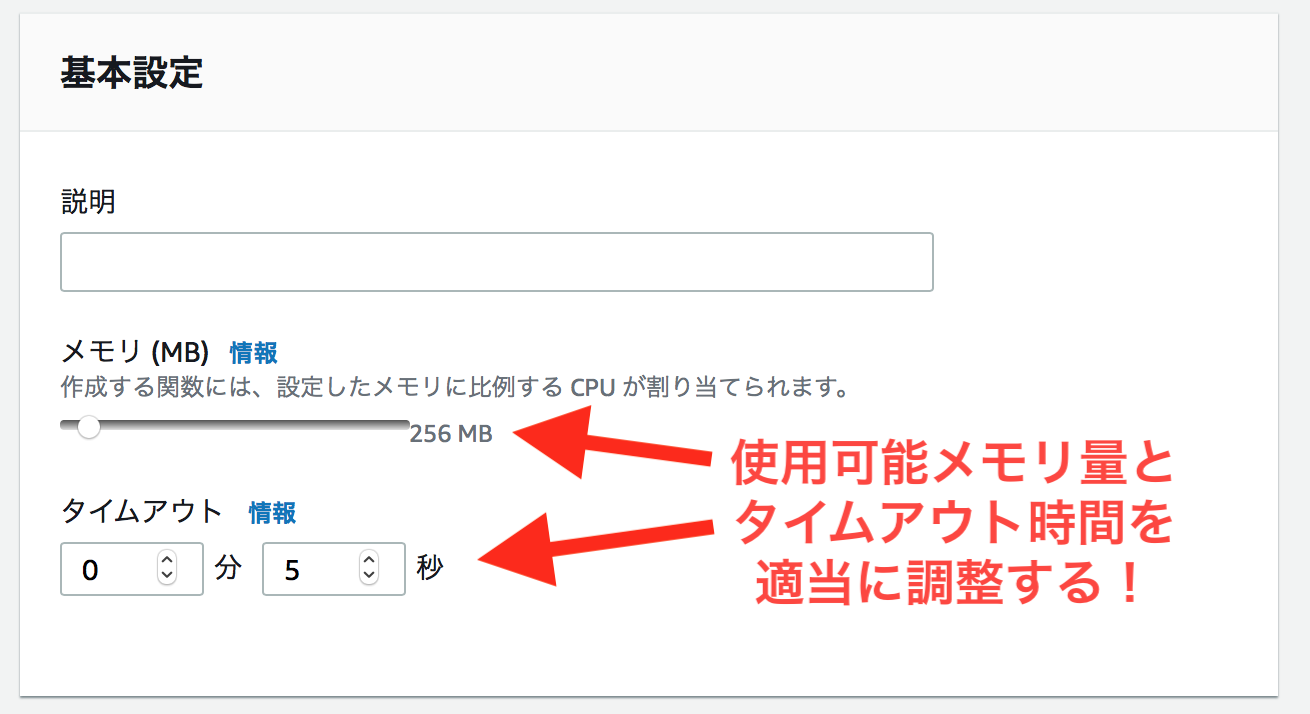
使用可能メモリ量とタイムアウト設定を確認したか?

ログを確認してみると普通にタイムアウトしていることがわかります。なので、設定を変更して使用可能メモリ量とタイムアウト設定を変更しましょう。

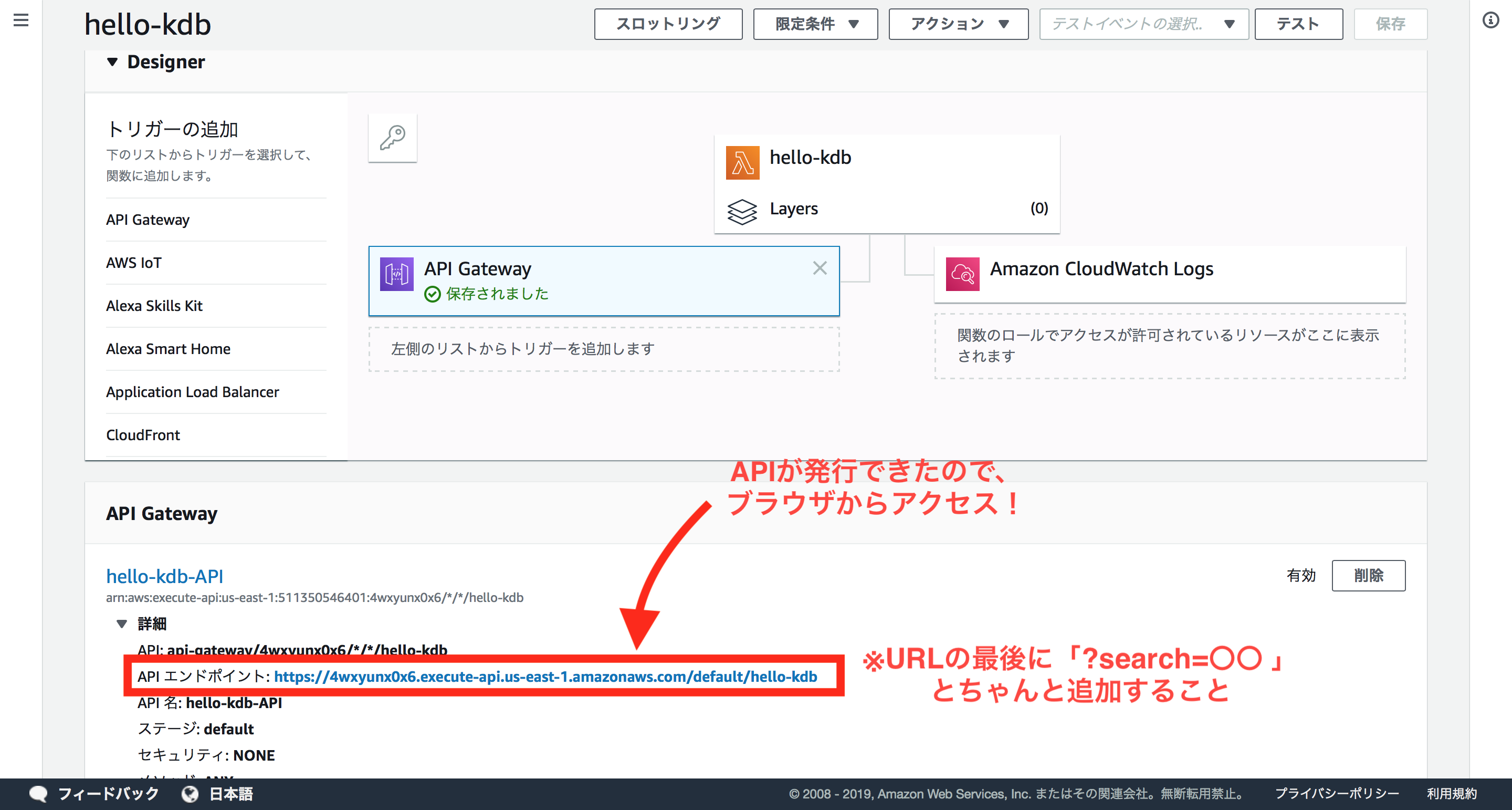
APIが完成した!

APIのURLにクエリ文字列を指定して実行すると実際にレスポンスが返ることがわかります。
サーバがどうだとか、IPアドレスがどうだとか、ルーティングがどうだとか考えることなしに作れるのはものすごい楽です!
最初はどうしていいかわからないと思いますが、慣れると一つの関数を数分でセットアップできるようになりますし、公式ドキュメントに書いてあるようにAWS-CLIを使えばブラウザで操作をしなくてもコマンドラインだけでLambda関数をアップロード・API化・実行することができるので、極めれば一瞬です。
なお、今回はAPIを「オープン」で作成しましたが、やっぱりAPI-Keyを発行するなり、ユーザ認証をするなど、何かしらのセキュリティを設けたほうが確実で安全です。ここでの説明は割愛させていただきますが最低限のマナーなので気をつけたほうがいいです。
参考記事↓
それではAWSLambda編をお送りしました。
質問等はコメントでお願いします!
次回はGCP Cloud Functionsでやっていきます!
ありがとうございました!
次の記事 → オリジナルKdB(科目検索)を作ってみよう -番外3- GCP Cloud Functions編
今回のあとがき
AWSやらGCPやらAzureやら...どのサービスを使うのがベストなのか...結局は好みなんじゃないかなぁと思います。個人的な考えでは、AWSはスケールアウトに優れていて各サービスの粒度が細かいので細かいところに手が届く玄人向け、GCPは他のクラウドサービスよりサービスの粒度がちょっと大きいけれどもGoogleのバックグラウンドを十二分に使えるので簡単で安定感があるため万人向けという印象です。
僕にはAWSが性に合っていたというだけですね。GCPが好きな方はもちろんGCPが性に合っているんだと思いますし、Azureが好きな人はAzureが性に合っているんだと思います。結局は好みです。
ところでクラウドサービスは本当に便利ですね。こんなに便利なサービスがあると「インフラ - バックエンド - フロントエンド」という構造は実際もうすでに古いなぁって思います。
誰でも利用できるクラウドサービスの登場でサーバ実物を管理する必要性がなくなる。これが言わんとすることは、『「バックエンド」と「フロントエンド」が求める機能を満たすためのクラウドサービスを選択するクラウドのマエストロのような存在が今後のキーになる』ということかなと個人的には思っています。
それにしても、オンプレミスに頼り続ける日本は世界から遅れすぎているのでどうにかしたいものですね(巨大な主語)