サーバ台数の節約などで、振り分け元と振り分け先を同一サーバでまかないたい場合の設定についてメモします。
結論からいうと、できることはできるのですが、予算が許せば役割を分離して振り分け先と元を別ノードで構成することをおすすめします。
なお、ポート番号でも分かる通り、本来はRedisの冗長化を考えたものです。Redis冗長化については別のエントリで記載するかもしれません。
システム構成
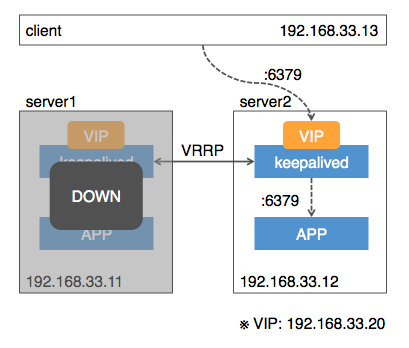
先にシステム構成を示しておきます。
clientから、keepalivedの持つVIP経由でアプリケーションにアクセスします。VIPはload balanceも行い、2台で適切に振り分けます。

また、1台ダウン時はVIPが別ノードに移動して処理を継続します。
各設定
基本的に、server1, server2ともに設定は同じです。どちらのサーバでも設定を行ってください。
keepalivedの設定
! Configuration File for keepalived
vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 51
priority 50
advert_int 1
notify_master "/usr/local/scripts/notify-master.sh"
notify_backup "/usr/local/scripts/notify-backup.sh"
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.33.20
}
unicast_peer {
192.168.33.11
192.168.33.12
}
}
virtual_server 192.168.33.20 26379 {
delay_loop 5
lvs_sched wrr
lvs_method DR
protocol TCP
real_server 192.168.33.11 6379 {
weight 1
inhibit_on_failure
TCP_CHECK {
connect_port 6379
connect_timeout 5
}
}
real_server 192.168.33.12 6379 {
weight 1
inhibit_on_failure
TCP_CHECK {
connect_port 6379
connect_timeout 5
}
}
}
virtual_server のポート設定が26379となっており、本来のポート番号とは異なりますが、わざとこうしています。あとで説明します。
loopbackアドレスの設定
VIPにアクセスされたら自分自身だと認識するように、loopbackアドレスを作成します。
DEVICE=lo:0
IPADDR=192.168.33.20
NETMASK=255.255.255.255
ONBOOT=yes
作成後、反映。
sudo service network restart
kernel parameterの変更
macアドレスを記憶されないようにすることと、ip forwarding設定の追加のためにカーネルパラメータを変更します。
net.ipv4.conf.all.arp_ignore = 0
net.ipv4.conf.all.arp_announce = 0
net.ipv4.conf.lo.arp_ignore = 1
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.eth1.arp_ignore = 1
net.ipv4.conf.eth1.arp_announce = 2
net.ipv4.conf.eth1.rp_filter= 0
net.ipv4.ip_forward = 1
いろいろ検証で試行錯誤した後の設定なので、不要なものが入っているかもしれません。
sysctl.dディレクトリはなければ作成してください。
CentOS6でも読み込んでくれます。 1
設定後、反映。
sudo sysctl -p /etc/sysctl.d/keepalived
keepalivedが発行するスクリプト
keepalivedもMASTER/BACKUP stateを持っており、それぞれのstateになったタイミングでスクリプトを発行できます。
# !/bin/bash -u
### Change vip port in keepalived
sed -i -e "s/virtual_server 192.168.33.20 .* {/virtual_server 192.168.33.20 6379 {/g" /etc/keepalived/keepalived.conf
service keepalived reload
# !/bin/bash -u
### Change vip port in keepalived
RELOAD_FLG=0
grep "virtual_server 192.168.33.29 26379 {" /etc/keepalived/keepalived.conf > /dev/null
if [ $? -ne 0 ] ; then
RELOAD_FLG=1
fi
sed -i -e "s/virtual_server 192.168.33.20 .* {/virtual_server 192.168.33.20 26379 {/g" /etc/keepalived/keepalived.conf
# reloadのタイミングでBACKUP STATEに移行して再度このスクリプトが実行されるため、無限実行を防ぐためにチェックを行う
if [ ${RELOAD_FLG} -eq 1 ] ;then
service keepalived reload
fi
### delete master vip (if exist)
ip addr show eth1 | grep "inet 192.168.33.20/32" > /dev/null
if [ $? -eq 0 ] ; then
sudo ip addr del 192.168.33.20/32 dev eth1
fi
結果
最後にそれぞれのkeepalivedを立ち上げたあと、clientからVIPにアクセスすると、うまく振り分けてくれると思います。
なお、lookbackインターフェースにIPアドレスを記載しているため、server1,server2自身からは振り分けを確認することはできません。(常に自分自身にしかアクセスされません)
ポイント
この設定では、keepalivedのMASTER state側だけ、notify_masterスクリプトによってVIPのポートを正しいものに変更しています。結果、以下のような設定になります。
# MASTER state
virtual_server 192.168.33.20 6379 {
# BACKUP state
virtual_server 192.168.33.20 26379 {
もしMASTER state側のkeepalivedがダウンした場合でも、他ノードのkeepalivedがこれを検知してvirtual_serverのポート番号を正しいものに変更しなおして、リロードしてくれます。
この設定を行わないと、clientから振り分け先(今回でいうserver1,server2)の間で通信を行ったときに、たまにネットワークループを引き起こし、パケットが無限にserver1/server2間で通信し合います。(tcpdumpとかで見るとえらいことになっています)
数回に1回というのが嫌らしいところで、一見1,2回試すとうまくいくのでたちが悪い…。
脚注2にもありますが、vagrant上でやると問題になるのは、おそらくこれが問題だと思われます。なお、私が確認したところでは、別にvagrantだけの問題ではなく、オンプレでも普通に起こりました…。
同様に、BACKUP stateに移ったらダミーのポート番号に変更し直す必要があるため、上記のなかでは設定済みであればreloadを行わないような工夫を行っています。この制御を行わないと、「BACKUP stateになった」→「notify_backupスクリプト実行」→「スクリプト中でkeepalived reload」→「reloadにより改めてBACKUP stateを再認識」→「notify_backupスクリプト実行」→以下続く…の無限ループに陥ります。
まとめ
一応、上記設定によってHA構成にしつつload balanceも行うという構成は取れました。LBノードとLB振り分け先ノードを集約できるので、サーバ台数の節約にはなると思います。
が、そのためにkeepalivedの中でkeepalived.confを書き換えてリロードするという複雑な仕組みを取る必要があり、また振り分け先を自分自身にするため余計に設定が必要など、かなり複雑でセンシティブな構成になっていると思います。
ですので、サーバ台数節約以外の目的では、普通に振り分け元と先のノードは別々に管理したほうが、よっぽど保守性が上がるように思います。