tkatoです。エッジデバイスでのDeepLearningに興味があります。
近年DeepLearningで学習したモデルをスマートフォンなどのエッジデバイスで動作させる需要が高まっています。
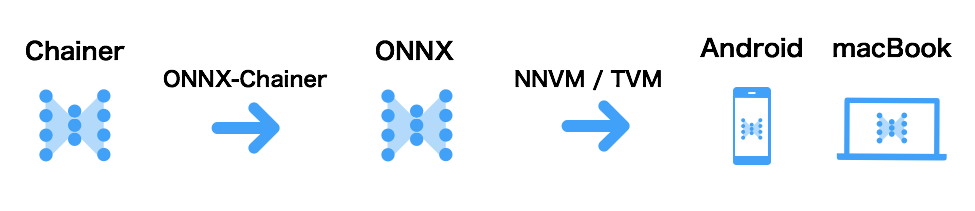
そこで今回は、Chainerの学習済みモデルをAndroidスマートフォンで動かして行きたいと思います。
具体的には、上図のようにChainerのモデルをONNX-ChainerでONNXフォーマットに変換し、NNVM/TVMを使ってAndroidへデプロイします。
結論から言うと、Chainerの学習済みYOLOv2(tiny)をSnapdragon搭載のAndroidスマートフォンのCPU/GPUで動作させることができました。
また、ChainerをONNXフォーマットに変換してNNVM/TVMを使うことで、「Chainerでモデルをつくる → Androidでの動作確認」が全てPythonからできました。
モデルを改良して実機で確認するサイクルを高速化でき、開発効率を上げることができそうです。
動作確認用のソースコードと環境構築方法は、tkat0/chainer-nnvm-exampleで公開しています。
本記事では詳細な手順は省略しているので、詳細を知りたい方は御覧ください。
ONNXとONNX-Chainerは、昨日の@mitmulさんのONNX-Chainer紹介、
NNVM/TVMは、@ashitaniさんのはじめてのNNVMがわかりやすいです。
環境構築
Chainer, ONNX-Chainer, ONNX, NNVM, TVMの環境構築を行います。
私の開発環境は以下の通りです。
- MacBook Pro (13-inch, 2017)
- macOS Sierra 10.12.6
- Xiaomi Mi 5
- Android 7.0
- Snapdragon 820
- Adreno 530 (GPU)
今回動作確認するパッケージのバージョンを記載します。
- Chainer 3.2.0
- ONNX-Chainer 1.0.0a1
- ONNX 1.0.0
- NNVM/TVM cb54478a
環境構築の詳細なコマンド等はtkat0/chainer-nnvm-example/INSTALL.mdを参照してください。
ChainerモデルをONNXに変換する
ONNX-Chainerを使えば、簡単にChainerからONNXへ変換できます。
以下のように、Chainerのモデル(Chain)と入力データを与えるだけです。
# モデル定義と、学習結果の読み込み
model = YOLOv2_tiny()
load_npz('./YOLOtiny_v2.model', model)
# ダミー入力データ作成
# ONNX-Chainerでは計算グラフ構築のために、forward実行する
x = np.ones((1, 3, 352, 352), dtype=np.float32)
# ONNXへのエクスポート
onnx_chainer.export(model, x, filename='YOLOtiny_v2.onnx')
今回は、オブジェクト検出モデルであるYOLOv2 tinyを変換しました。
モデルの定義と学習済みモデルは、 leetenki/YOLOtiny_v2_chainerを利用させていただきました。
モデル定義は以下です。
class YOLOv2_tiny(chainer.Chain):
def __init__(self, n_classes=20, n_boxes=5):
super(YOLOv2_tiny, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(None, 16, 3, stride=1, pad=1, nobias=True)
self.bn1 = L.BatchNormalization(16)
self.conv2 = L.Convolution2D(None, 32, 3, stride=1, pad=1, nobias=True)
self.bn2 = L.BatchNormalization(32)
self.conv3 = L.Convolution2D(None, 64, 3, stride=1, pad=1, nobias=True)
self.bn3 = L.BatchNormalization(64)
self.conv4 = L.Convolution2D(None, 128, 3, stride=1, pad=1, nobias=True)
self.bn4 = L.BatchNormalization(128)
self.conv5 = L.Convolution2D(None, 256, 3, stride=1, pad=1, nobias=True)
self.bn5 = L.BatchNormalization(256)
self.conv6 = L.Convolution2D(None, 512, 3, stride=1, pad=1, nobias=True)
self.bn6 = L.BatchNormalization(512)
self.conv7 = L.Convolution2D(None, 1024, 3, stride=1, pad=1, nobias=True)
self.bn7 = L.BatchNormalization(1024)
self.conv8 = L.Convolution2D(None, 1024, 3, stride=1, pad=1, nobias=True)
self.bn8 = L.BatchNormalization(1024)
self.conv9 = L.Convolution2D(None, 125, 1, stride=1, pad=0, nobias=True)
def __call__(self, x):
h = F.leaky_relu(self.bn1(self.conv1(x)),slope=0.1)
h = F.max_pooling_2d(h, ksize=2, stride=2, pad=0)
h = F.leaky_relu(self.bn2(self.conv2(h)),slope=0.1)
h = F.max_pooling_2d(h, ksize=2, stride=2, pad=0)
h = F.leaky_relu(self.bn3(self.conv3(h)),slope=0.1)
h = F.max_pooling_2d(h, ksize=2, stride=2, pad=0)
h = F.leaky_relu(self.bn4(self.conv4(h)),slope=0.1)
h = F.max_pooling_2d(h, ksize=2, stride=2, pad=0)
h = F.leaky_relu(self.bn5(self.conv5(h)),slope=0.1)
h = F.max_pooling_2d(h, ksize=2, stride=2, pad=0)
h = F.leaky_relu(self.bn6(self.conv6(h)),slope=0.1)
h = F.leaky_relu(self.bn7(self.conv7(h)),slope=0.1)
h = F.leaky_relu(self.bn8(self.conv8(h)),slope=0.1)
h = self.conv9(h)
return h
エクスポートしたONNXファイルは、lutzroeder/Netronを使って可視化できます。かっこいい!
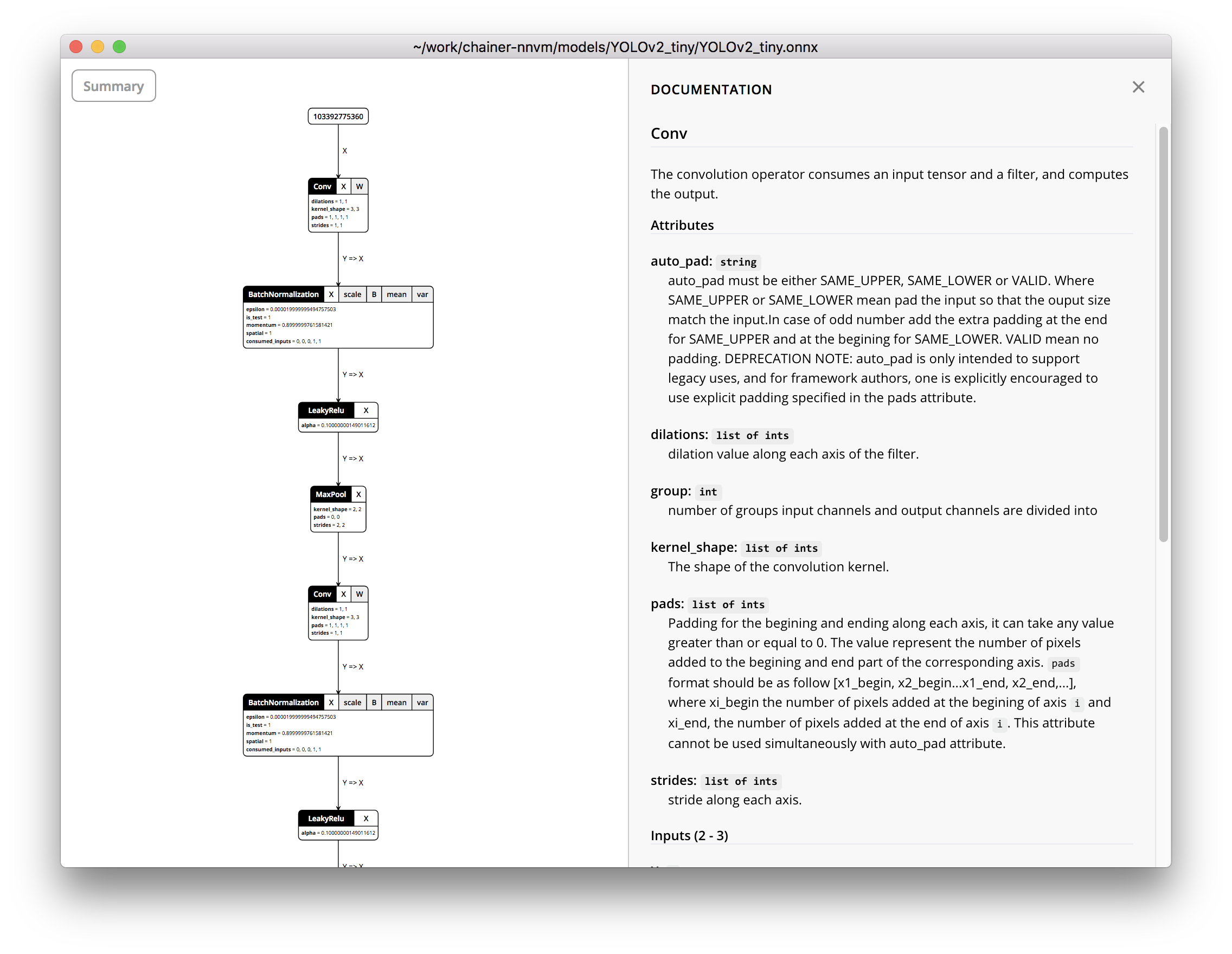
ONNXに変換したモデルをNNVM/TVMで実行する(macBook)
次は、ONNXへ変換したモデルがNNVM/TVMでうまく動くか確認するため、まずはPCで動かしてみましょう。
NNVMでONNXからモデルをインポートし、どのコンテキスト(CPU,GPUなどの計算資源)を使って計算するかを指定し実行します。
まずは、macBookのCPUでの実行例。
# (1) ONNXファイルのロード
onnx_graph = onnx.load('./models/YOLOv2_tiny/YOLOv2_tiny.onnx')
# (2) 入力画像の前処理
input_name = 'input_0'
org_img = Image.open('dog.jpg')
org_img = org_img.resize((352, 352))
img = np.asarray(org_img).astype(np.float32).copy()
img = img.transpose(2,0,1)
img /= 255.
img = img[np.newaxis,:]
# (3) NNVMでONNXをロード
sym, params = nnvm.frontend.from_onnx(onnx_graph)
# (4) CPU向けにビルド
target = "llvm"
with nnvm.compiler.build_config(opt_level=opt_level, add_pass=None):
graph, lib, params = nnvm.compiler.build(sym, target, {input_name: img.shape}, params=params)
# (5) CPUで実行する
module = graph_runtime.create(graph, lib, tvm.cpu(0))
module.set_input('input_0', tvm.nd.array(img.astype(dtype)))
module.set_input(**params)
module.run()
# (6) 結果の取得
out_shape = (1,125,352//32,352//32) # 出力テンソルのサイズ定義
output = tvm.nd.empty(out_shape, ctx=tvm.cpu(0))
output = module.get_output(0, output).asnumpy()
続いて、macBookのGPUでの実行例。OpenCLを指定してビルドします。(4),(5)以外はCPUと同じです。
# (4) GPU向けにビルド
target = "opencl"
with nnvm.compiler.build_config(opt_level=opt_level, add_pass=None):
graph, lib, params = nnvm.compiler.build(sym, target, {input_name: data_shape}, params=params)
# (5) GPUで実行する
ctx = tvm.context(target, 0)
module = graph_runtime.create(graph, lib, ctx)
module.set_input('input_0', tvm.nd.array(data_array.astype(dtype)))
module.set_input(**params)
module.run()
macBookでの計算速度は以下となりました。比較のためにChainerでも測定しています。
それぞれ1000回forward実行した平均時間(sec)です。
| Chainer(macBook CPU) | NNVM(macBook CPU) | NNVM(macBook GPU) |
|---|---|---|
| 0.17 | 1.27 | 0.08 |
TVMはベンチマーク用にtime_evaluatorというAPIを提供しているのでこれを使いました。
# ベンチマーク
num_iter = 100
ftimer = module.module.time_evaluator("run", tvm.cpu(0), num_iter) # module.run()を100回実行
prof_res = ftimer()
print(prof_res)
また、モデルの出力はnumpy.ndarrayとして得られるので、Chainer版と同じ後処理を行い、Chainerと同じ検出結果であることも確認できました。

NNVM/TVMのAndroid向けサンプルアプリを動かす
続いて、ONNXに変換したモデルをNNVM/TVMでAndroidにデプロイしていきます。
まずは、サンプルアプリを使ってTVMによるAndroidへのデプロイを試してましょう。
TVMのリポジトリには、Android用のサンプルアプリ tvm/apps/android_rpcを提供しています。
これは、TVMのコンテキストとしてリモート接続したAndroidを使うことができます。
PythonからmacBookのCPUやGPUを扱うのと同様に、リモートのAndroidで計算を行い、結果を得ることができます。
なお、RPCによるリモート開発は、TVM公式のBlog記事(2017/11/08)が図解されていて詳しいです。
まずは、このandroid_rpcを試してみましょう。
Androidアプリケーションのビルド方法は、tkat0/chainer-nnvm-example/INSTALL.mdに記載しています(Android StudioとAndroid NDKが必要)。
Androidにアプリをインストールできたら、PCでRPCプロキシーサーバーを利用します。
このプロキシサーバーを経由して、Androidと通信します。
$ python -m tvm.exec.rpc_proxy
INFO:root:RPCProxy: client port bind to 0.0.0.0:9090
INFO:root:RPCProxy: Websock port bind to 9190
次にAndroidアプリ側で、プロキシサーバーに接続します。
以下のように、上記サーバーのIPアドレスとポートを指定します。
RPCに以下の表示があり、Androidと接続できたことがわかります。
INFO:root:Handler ready TCPSocket: ('192.168.0.20', 35911):server:android
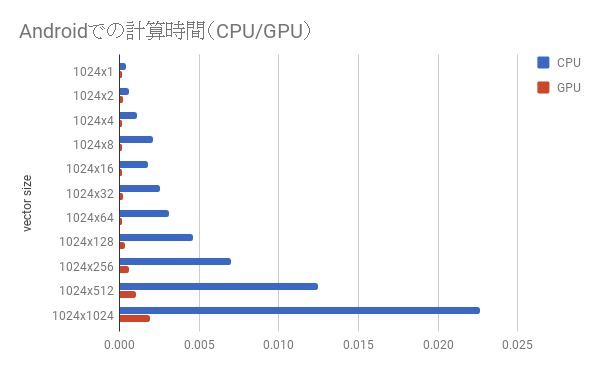
最後に、別の端末を開いて、Androidへ計算をオフロードするサンプルスクリプト(tvm/apps/android_rpc/tests/android_rpc_test.py)を実行してみましょう。
ここでは簡単な行列演算を実行するサンプルです。それぞれのベクトルはデフォルトで1024次元です。
$ cd tvm/apps/android_rpc/tests
$ python android_rpc_test.py
TVM: Initializing cython mode...
[20:40:45] src/runtime/opencl/opencl_device_api.cc:195: Initialize OpenCL platform 'Apple'
[20:40:45] src/runtime/opencl/opencl_device_api.cc:220: opencl(0)='Intel(R) Iris(TM) Graphics 650' cl_device_id=0x1024500
Run GPU test ...
0.000140703 secs/op
Run CPU test ...
0.000337068 secs/op
AndroidスマートフォンのCPU,GPUでTVMの計算を実行することができました。
1024次元のベクトルでは、CPUとGPUの差は2倍程度でしたが、ベクトルの次元を大きくしていくと、CPUとGPUの性能差が顕著にでます。
ちなみに、サイズを大きくしすぎるとCL_INVALID_BUFFER_SIZEエラーとなりました。
(※以下、1回しか測定していないので参考程度)
ONNXに変換したモデルをNNVM/TVMで実行する(Android)
いよいよ、ChainerのモデルをAndroidへデプロイします。
以下のコードで、Chainerから出力したONNXファイルをNNVMで読み込み、TVMでAndroidにデプロイします。
# (3) NNVMでONNXをロード
sym, params = nnvm.frontend.from_onnx(onnx_graph)
# print(sym.debug_str()
# (3') RPCサーバーに接続
proxy_host = os.environ["TVM_ANDROID_RPC_PROXY_HOST"]
proxy_port = 9090
key = "android"
print('RPC Connecting...')
remote = rpc.connect(proxy_host, proxy_port, key=key)
print('RPC Connected')
# (4) Androidの CPU or GPU 向けにビルド
arch = "arm64"
if exec_gpu:
# Mobile GPU
target = 'opencl'
target_host = "llvm -target=%s-linux-android" % arch # OpenCLのホストはARM 64bit Android
ctx = remote.cl(0) # コンテキストはremoteのOpenCLデバイスを指定
else:
# Mobile CPU
target = "llvm -target=%s-linux-android" % arch
target_host = None
ctx = remote.cpu(0)
with nnvm.compiler.build_config(opt_level=opt_level, add_pass=None):
graph, lib, params = nnvm.compiler.build(sym, target, {input_name: data_shape}, params=params, target_host=target_host)
print("-------compute graph-------")
print(graph.ir())
# (4') ビルド結果からライブラリを生成し、Androidに転送する
temp = util.tempdir()
path_so = temp.relpath("YOLOv2_tiny-aarch64.so")
# print('show opencl kernel') # 生成されたOpenCLカーネルを確認できる
# print(lib.imported_modules[0].get_source())
lib.export_library(path_so, ndk.create_shared)
remote.upload(path_so)
rlib = remote.load_module(so_name)
# (5) Androidの CPU or GPU で実行する
img = tvm.nd.array(data_array.astype(dtype), ctx)
rmodule = graph_runtime.create(graph, rlib, ctx)
rmodule.set_input('input_0', img)
rmodule.set_input(**params)
rmodule.run()
output = tvm.nd.empty(out_shape, ctx=ctx)
output = rmodule.get_output(0, output).asnumpy()
ChainerのモデルをONNXフォーマット経由でNNVM/TVMにロードし、AndroidのCPU/GPUで実行できることが確認できました!
計算速度[sec]は以下となりました。
| Android(CPU) | Android(GPU) |
|---|---|
| 2.07 | 0.63 |
あとは期待する性能を目指して、Chainer(モデルアーキテクチャ),NNVM(グラフ最適化),TVM(ハードウェアアーキテクチャへの最適化)の各ドメインで最適化を行っていき、Androidアプリに組み込んでいきます。
Androidアプリとしてデプロイする
今回はRPCサーバーを利用してPCからAndroidを計算先として利用しましたが、今回使ったandroid-rpcにも組み込まれているTVMのランタイムライブラリTVM4Jを使えば、TVMがビルドしたライブラリをAndroidアプリに組み込むことができるようです。
終わりに
今回は、ONNX-ChainerとNNVM/TVMを使ってChainerの学習済みモデルをAndroidへデプロイしました。
ChainerとNNVM/TVMの組み合わせは、ChainerでプロトタイピングしたモデルをPythonだけ書いて手軽に実機で性能検証ができるため、「製品がターゲットとするデバイスでどの程度のモデルなら動かせるかを早期に検証する」目的などで使えるのではないでしょうか。
android-rpcのiOS版もあるので、同様にしてiPhoneへもデプロイができそうです。
最後まで記事を読んでいただきありがとうございました。
おまけ
おまけとして、この記事を書くにあたって私がハマったところや、本筋に関係ないけど試したことを紹介します。
NNVMでグラフの最適化
NNVMは計算グラフの無駄な処理をまとめたり、事前に計算できるものを計算したり、計算グラフの最適化をしてくれます。
これは、nnvm.compiler.buildに対するopt_levelを変えるだけでも簡単に確認ができるので、試してみましょう。
# (4) CPU向けにビルド
target = "llvm"
with nnvm.compiler.build_config(opt_level=opt_level, add_pass=None): # opt_level >= 0 を設定できる
graph, lib, params = nnvm.compiler.build(sym, target, {input_name: img.shape}, params=params)
YOLOv2_tinyのグラフで、opt_levelを変えてビルドしてみましょう。
まずはopt_level=0の場合。
-------compute graph-------
Graph(%input_0,
%param_8,
%param_40,
%param_13,
%param_39,
%param_12,
%param_16,
%param_38,
%param_15,
%param_37,
%param_14,
%param_11,
%param_36,
%param_1,
%param_35,
%param_0,
%param_7,
%param_34,
%param_10,
%param_33,
%param_9,
%param_24,
%param_32,
%param_18,
%param_31,
%param_17,
%param_19,
%param_30,
%param_22,
%param_29,
%param_21,
%param_20,
%param_28,
%param_6,
%param_27,
%param_5,
%param_2,
%param_26,
%param_4,
%param_25,
%param_3,
%param_23) {
%2 = tvm_op(%input_0, %param_8, num_outputs='1', num_inputs='2', func_name='fuse_conv2d', flatten_data='0')
%4 = tvm_op(%param_40, num_outputs='1', num_inputs='1', func_name='fuse___add_scalar__', flatten_data='1')
%5 = tvm_op(%4, num_outputs='1', num_inputs='1', func_name='fuse_sqrt', flatten_data='1')
%6 = tvm_op(%5, num_outputs='1', num_inputs='1', func_name='fuse___rdiv_scalar__', flatten_data='1')
%8 = tvm_op(%6, %param_13, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul', flatten_data='1')
%9 = tvm_op(%8, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims', flatten_data='0')
%10 = tvm_op(%2, %9, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_mul', flatten_data='0')
%12 = tvm_op(%param_39, num_outputs='1', num_inputs='1', func_name='fuse_negative', flatten_data='1')
%13 = tvm_op(%12, %8, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul', flatten_data='1')
%15 = tvm_op(%13, %param_12, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_add', flatten_data='1')
%16 = tvm_op(%15, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims', flatten_data='0')
%17 = tvm_op(%10, %16, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_add', flatten_data='0')
%18 = tvm_op(%17, num_outputs='1', num_inputs='1', func_name='fuse_leaky_relu', flatten_data='1')
%19 = tvm_op(%18, num_outputs='1', num_inputs='1', func_name='fuse_max_pool2d', flatten_data='0')
%21 = tvm_op(%19, %param_16, num_outputs='1', num_inputs='2', func_name='fuse_conv2d_1', flatten_data='0')
%23 = tvm_op(%param_38, num_outputs='1', num_inputs='1', func_name='fuse___add_scalar___1', flatten_data='1')
%24 = tvm_op(%23, num_outputs='1', num_inputs='1', func_name='fuse_sqrt_1', flatten_data='1')
%25 = tvm_op(%24, num_outputs='1', num_inputs='1', func_name='fuse___rdiv_scalar___1', flatten_data='1')
%27 = tvm_op(%25, %param_15, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_1', flatten_data='1')
%28 = tvm_op(%27, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_1', flatten_data='0')
%29 = tvm_op(%21, %28, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_mul_1', flatten_data='0')
%31 = tvm_op(%param_37, num_outputs='1', num_inputs='1', func_name='fuse_negative_1', flatten_data='1')
%32 = tvm_op(%31, %27, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_1', flatten_data='1')
%34 = tvm_op(%32, %param_14, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_add_1', flatten_data='1')
%35 = tvm_op(%34, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_1', flatten_data='0')
%36 = tvm_op(%29, %35, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_add_1', flatten_data='0')
%37 = tvm_op(%36, num_outputs='1', num_inputs='1', func_name='fuse_leaky_relu_1', flatten_data='1')
%38 = tvm_op(%37, num_outputs='1', num_inputs='1', func_name='fuse_max_pool2d_1', flatten_data='0')
%40 = tvm_op(%38, %param_11, num_outputs='1', num_inputs='2', func_name='fuse_conv2d_2', flatten_data='0')
%42 = tvm_op(%param_36, num_outputs='1', num_inputs='1', func_name='fuse___add_scalar___2', flatten_data='1')
%43 = tvm_op(%42, num_outputs='1', num_inputs='1', func_name='fuse_sqrt_2', flatten_data='1')
%44 = tvm_op(%43, num_outputs='1', num_inputs='1', func_name='fuse___rdiv_scalar___2', flatten_data='1')
%46 = tvm_op(%44, %param_1, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_2', flatten_data='1')
%47 = tvm_op(%46, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_2', flatten_data='0')
%48 = tvm_op(%40, %47, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_mul_2', flatten_data='0')
%50 = tvm_op(%param_35, num_outputs='1', num_inputs='1', func_name='fuse_negative_2', flatten_data='1')
%51 = tvm_op(%50, %46, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_2', flatten_data='1')
%53 = tvm_op(%51, %param_0, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_add_2', flatten_data='1')
%54 = tvm_op(%53, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_2', flatten_data='0')
%55 = tvm_op(%48, %54, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_add_2', flatten_data='0')
%56 = tvm_op(%55, num_outputs='1', num_inputs='1', func_name='fuse_leaky_relu_2', flatten_data='1')
%57 = tvm_op(%56, num_outputs='1', num_inputs='1', func_name='fuse_max_pool2d_2', flatten_data='0')
%59 = tvm_op(%57, %param_7, num_outputs='1', num_inputs='2', func_name='fuse_conv2d_3', flatten_data='0')
%61 = tvm_op(%param_34, num_outputs='1', num_inputs='1', func_name='fuse___add_scalar___3', flatten_data='1')
%62 = tvm_op(%61, num_outputs='1', num_inputs='1', func_name='fuse_sqrt_3', flatten_data='1')
%63 = tvm_op(%62, num_outputs='1', num_inputs='1', func_name='fuse___rdiv_scalar___3', flatten_data='1')
%65 = tvm_op(%63, %param_10, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_3', flatten_data='1')
%66 = tvm_op(%65, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_3', flatten_data='0')
%67 = tvm_op(%59, %66, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_mul_3', flatten_data='0')
%69 = tvm_op(%param_33, num_outputs='1', num_inputs='1', func_name='fuse_negative_3', flatten_data='1')
%70 = tvm_op(%69, %65, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_3', flatten_data='1')
%72 = tvm_op(%70, %param_9, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_add_3', flatten_data='1')
%73 = tvm_op(%72, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_3', flatten_data='0')
%74 = tvm_op(%67, %73, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_add_3', flatten_data='0')
%75 = tvm_op(%74, num_outputs='1', num_inputs='1', func_name='fuse_leaky_relu_3', flatten_data='1')
%76 = tvm_op(%75, num_outputs='1', num_inputs='1', func_name='fuse_max_pool2d_3', flatten_data='0')
%78 = tvm_op(%76, %param_24, num_outputs='1', num_inputs='2', func_name='fuse_conv2d_4', flatten_data='0')
%80 = tvm_op(%param_32, num_outputs='1', num_inputs='1', func_name='fuse___add_scalar___4', flatten_data='1')
%81 = tvm_op(%80, num_outputs='1', num_inputs='1', func_name='fuse_sqrt_4', flatten_data='1')
%82 = tvm_op(%81, num_outputs='1', num_inputs='1', func_name='fuse___rdiv_scalar___4', flatten_data='1')
%84 = tvm_op(%82, %param_18, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_4', flatten_data='1')
%85 = tvm_op(%84, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_4', flatten_data='0')
%86 = tvm_op(%78, %85, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_mul_4', flatten_data='0')
%88 = tvm_op(%param_31, num_outputs='1', num_inputs='1', func_name='fuse_negative_4', flatten_data='1')
%89 = tvm_op(%88, %84, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_4', flatten_data='1')
%91 = tvm_op(%89, %param_17, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_add_4', flatten_data='1')
%92 = tvm_op(%91, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_4', flatten_data='0')
%93 = tvm_op(%86, %92, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_add_4', flatten_data='0')
%94 = tvm_op(%93, num_outputs='1', num_inputs='1', func_name='fuse_leaky_relu_4', flatten_data='1')
%95 = tvm_op(%94, num_outputs='1', num_inputs='1', func_name='fuse_max_pool2d_4', flatten_data='0')
%97 = tvm_op(%95, %param_19, num_outputs='1', num_inputs='2', func_name='fuse_conv2d_5', flatten_data='0')
%99 = tvm_op(%param_30, num_outputs='1', num_inputs='1', func_name='fuse___add_scalar___5', flatten_data='1')
%100 = tvm_op(%99, num_outputs='1', num_inputs='1', func_name='fuse_sqrt_5', flatten_data='1')
%101 = tvm_op(%100, num_outputs='1', num_inputs='1', func_name='fuse___rdiv_scalar___5', flatten_data='1')
%103 = tvm_op(%101, %param_22, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_5', flatten_data='1')
%104 = tvm_op(%103, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_5', flatten_data='0')
%105 = tvm_op(%97, %104, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_mul_5', flatten_data='0')
%107 = tvm_op(%param_29, num_outputs='1', num_inputs='1', func_name='fuse_negative_5', flatten_data='1')
%108 = tvm_op(%107, %103, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_5', flatten_data='1')
%110 = tvm_op(%108, %param_21, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_add_5', flatten_data='1')
%111 = tvm_op(%110, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_5', flatten_data='0')
%112 = tvm_op(%105, %111, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_add_5', flatten_data='0')
%113 = tvm_op(%112, num_outputs='1', num_inputs='1', func_name='fuse_leaky_relu_5', flatten_data='1')
%115 = tvm_op(%113, %param_20, num_outputs='1', num_inputs='2', func_name='fuse_conv2d_6', flatten_data='0')
%117 = tvm_op(%param_28, num_outputs='1', num_inputs='1', func_name='fuse___add_scalar___6', flatten_data='1')
%118 = tvm_op(%117, num_outputs='1', num_inputs='1', func_name='fuse_sqrt_6', flatten_data='1')
%119 = tvm_op(%118, num_outputs='1', num_inputs='1', func_name='fuse___rdiv_scalar___6', flatten_data='1')
%121 = tvm_op(%119, %param_6, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_6', flatten_data='1')
%122 = tvm_op(%121, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_6', flatten_data='0')
%123 = tvm_op(%115, %122, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_mul_6', flatten_data='0')
%125 = tvm_op(%param_27, num_outputs='1', num_inputs='1', func_name='fuse_negative_6', flatten_data='1')
%126 = tvm_op(%125, %121, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_6', flatten_data='1')
%128 = tvm_op(%126, %param_5, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_add_6', flatten_data='1')
%129 = tvm_op(%128, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_6', flatten_data='0')
%130 = tvm_op(%123, %129, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_add_6', flatten_data='0')
%131 = tvm_op(%130, num_outputs='1', num_inputs='1', func_name='fuse_leaky_relu_4', flatten_data='1')
%133 = tvm_op(%131, %param_2, num_outputs='1', num_inputs='2', func_name='fuse_conv2d_7', flatten_data='0')
%135 = tvm_op(%param_26, num_outputs='1', num_inputs='1', func_name='fuse___add_scalar___6', flatten_data='1')
%136 = tvm_op(%135, num_outputs='1', num_inputs='1', func_name='fuse_sqrt_6', flatten_data='1')
%137 = tvm_op(%136, num_outputs='1', num_inputs='1', func_name='fuse___rdiv_scalar___6', flatten_data='1')
%139 = tvm_op(%137, %param_4, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_6', flatten_data='1')
%140 = tvm_op(%139, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_6', flatten_data='0')
%141 = tvm_op(%133, %140, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_mul_6', flatten_data='0')
%143 = tvm_op(%param_25, num_outputs='1', num_inputs='1', func_name='fuse_negative_6', flatten_data='1')
%144 = tvm_op(%143, %139, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_mul_6', flatten_data='1')
%146 = tvm_op(%144, %param_3, num_outputs='1', num_inputs='2', func_name='fuse_elemwise_add_6', flatten_data='1')
%147 = tvm_op(%146, num_outputs='1', num_inputs='1', func_name='fuse_expand_dims_6', flatten_data='0')
%148 = tvm_op(%141, %147, num_outputs='1', num_inputs='2', func_name='fuse_broadcast_add_6', flatten_data='0')
%149 = tvm_op(%148, num_outputs='1', num_inputs='1', func_name='fuse_leaky_relu_4', flatten_data='1')
%151 = tvm_op(%149, %param_23, num_outputs='1', num_inputs='2', func_name='fuse_conv2d_8', flatten_data='0')
ret %151
}
graph_attr_keys = [storage_allocated_bytes, dltype, storage_num_not_allocated, dtype, storage_id, storage_inplace_index, shape]
続いて、opt_level=3の場合。
-------compute graph-------
Graph(%input_0,
%param_8_sc,
%batch_norm0_add_beta_expand,
%param_16_sc,
%batch_norm1_add_beta_expand,
%param_11_sc,
%batch_norm2_add_beta_expand,
%param_7_sc,
%batch_norm3_add_beta_expand,
%param_24_sc,
%batch_norm4_add_beta_expand,
%param_19_sc,
%batch_norm5_add_beta_expand,
%param_20_sc,
%batch_norm6_add_beta_expand,
%param_2_sc,
%batch_norm7_add_beta_expand,
%param_23) {
%3 = tvm_op(%input_0, %param_8_sc, %batch_norm0_add_beta_expand, num_outputs='1', num_inputs='3', func_name='fuse_conv2d_broadcast_add_leaky_relu', flatten_data='0')
%4 = tvm_op(%3, num_outputs='1', num_inputs='1', func_name='fuse_max_pool2d', flatten_data='0')
%7 = tvm_op(%4, %param_16_sc, %batch_norm1_add_beta_expand, num_outputs='1', num_inputs='3', func_name='fuse_conv2d_broadcast_add_leaky_relu_1', flatten_data='0')
%8 = tvm_op(%7, num_outputs='1', num_inputs='1', func_name='fuse_max_pool2d_1', flatten_data='0')
%11 = tvm_op(%8, %param_11_sc, %batch_norm2_add_beta_expand, num_outputs='1', num_inputs='3', func_name='fuse_conv2d_broadcast_add_leaky_relu_2', flatten_data='0')
%12 = tvm_op(%11, num_outputs='1', num_inputs='1', func_name='fuse_max_pool2d_2', flatten_data='0')
%15 = tvm_op(%12, %param_7_sc, %batch_norm3_add_beta_expand, num_outputs='1', num_inputs='3', func_name='fuse_conv2d_broadcast_add_leaky_relu_3', flatten_data='0')
%16 = tvm_op(%15, num_outputs='1', num_inputs='1', func_name='fuse_max_pool2d_3', flatten_data='0')
%19 = tvm_op(%16, %param_24_sc, %batch_norm4_add_beta_expand, num_outputs='1', num_inputs='3', func_name='fuse_conv2d_broadcast_add_leaky_relu_4', flatten_data='0')
%20 = tvm_op(%19, num_outputs='1', num_inputs='1', func_name='fuse_max_pool2d_4', flatten_data='0')
%23 = tvm_op(%20, %param_19_sc, %batch_norm5_add_beta_expand, num_outputs='1', num_inputs='3', func_name='fuse_conv2d_broadcast_add_leaky_relu_5', flatten_data='0')
%26 = tvm_op(%23, %param_20_sc, %batch_norm6_add_beta_expand, num_outputs='1', num_inputs='3', func_name='fuse_conv2d_broadcast_add_leaky_relu_6', flatten_data='0')
%29 = tvm_op(%26, %param_2_sc, %batch_norm7_add_beta_expand, num_outputs='1', num_inputs='3', func_name='fuse_conv2d_broadcast_add_leaky_relu_7', flatten_data='0')
%31 = tvm_op(%29, %param_23, num_outputs='1', num_inputs='2', func_name='fuse_conv2d', flatten_data='0')
ret %31
}
graph_attr_keys = [storage_allocated_bytes, dltype, storage_num_not_allocated, dtype, storage_id, storage_inplace_index, shape]
だいぶすっきりしました!func_nameを見ても、複数のレイヤーが1つのオペレーションにまとまっているのがわかりますね。
気になるのは速度ですが、私の環境ではopt_level=0,3で、Androidでは速度の違いはほとんどありませんでした。
Android GPU
0.6464753716299999(opt0) → 0.63244619299(opt3)
Android CPU
2.07656547421(opt0) → 2.0714290007700003(opt3)
rpc_androidのサンプルが動かない
プロキシサーバーを立ち上げる際の凡ミス…
NG
python -m tvm.exec.rpc_server
OK
python -m tvm.exec.rpc_proxy
Androidにリモートで接続してるつもりが、macBook自身に接続し、Android用のバイナリを実行しようとしていたんですね…
TVMがmacOSでビルドできない
tvm直下でmake -j8すると以下のようなエラーがでた。
c++ -std=c++11 -Wall -O2 -Iinclude -I/Users/tkato/work/chainer-nnvm/nnvm/tvm/dlpack/include -I/Users/tkato/work/chainer-nnvm/nnvm/tvm/dmlc-core/include -IHalideIR/src -Itopi/include -fPIC -DTVM_CUDA_RUNTIME=0 -DTVM_ROCM_RUNTIME=0 -DTVM_OPENCL_RUNTIME=1 -DTVM_METAL_RUNTIME=0 -framework OpenCL -shared -o lib/libtvm_runtime.dylib build/runtime/c_dsl_api.o build/runtime/c_runtime_api.o build/runtime/cpu_device_api.o build/runtime/dso_module.o build/runtime/file_util.o build/runtime/module.o build/runtime/module_util.o build/runtime/registry.o build/runtime/system_lib_module.o build/runtime/thread_pool.o build/runtime/workspace_pool.o build/runtime/opencl/opencl_device_api.o build/runtime/opencl/opencl_module.o build/runtime/rpc/rpc_device_api.o build/runtime/rpc/rpc_event_impl.o build/runtime/rpc/rpc_module.o build/runtime/rpc/rpc_server_env.o build/runtime/rpc/rpc_session.o build/runtime/rpc/rpc_socket_impl.o build/runtime/graph/graph_runtime.o -pthread -lm -ldl -L/usr/local/Cellar/llvm/HEAD-8b47f7b/lib -Wl,-search_paths_first -Wl,-headerpad_max_install_names -lLLVMLTO -lLLVMPasses -lLLVMObjCARCOpts -lLLVMMIRParser -lLLVMSymbolize -lLLVMDebugInfoPDB -lLLVMDebugInfoDWARF -lLLVMCoverage -lLLVMTableGen -lLLVMDlltoolDriver -lLLVMOrcJIT -lLLVMXCoreDisassembler -lLLVMXCoreCodeGen -lLLVMXCoreDesc -lLLVMXCoreInfo -lLLVMXCoreAsmPrinter -lLLVMSystemZDisassembler -lLLVMSystemZCodeGen -lLLVMSystemZAsmParser -lLLVMSystemZDesc -lLLVMSystemZInfo -lLLVMSystemZAsmPrinter -lLLVMSparcDisassembler -lLLVMSparcCodeGen -lLLVMSparcAsmParser -lLLVMSparcDesc -lLLVMSparcInfo -lLLVMSparcAsmPrinter -lLLVMPowerPCDisassembler -lLLVMPowerPCCodeGen -lLLVMPowerPCAsmParser -lLLVMPowerPCDesc -lLLVMPowerPCInfo -lLLVMPowerPCAsmPrinter -lLLVMNVPTXCodeGen -lLLVMNVPTXDesc -lLLVMNVPTXInfo -lLLVMNVPTXAsmPrinter -lLLVMMSP430CodeGen -lLLVMMSP430Desc -lLLVMMSP430Info -lLLVMMSP430AsmPrinter -lLLVMMipsDisassembler -lLLVMMipsCodeGen -lLLVMMipsAsmParser -lLLVMMipsDesc -lLLVMMipsInfo -lLLVMMipsAsmPrinter -lLLVMLanaiDisassembler -lLLVMLanaiCodeGen -lLLVMLanaiAsmParser -lLLVMLanaiDesc -lLLVMLanaiAsmPrinter -lLLVMLanaiInfo -lLLVMHexagonDisassembler -lLLVMHexagonCodeGen -lLLVMHexagonAsmParser -lLLVMHexagonDesc -lLLVMHexagonInfo -lLLVMBPFDisassembler -lLLVMBPFCodeGen -lLLVMBPFAsmParser -lLLVMBPFDesc -lLLVMBPFInfo -lLLVMBPFAsmPrinter -lLLVMARMDisassembler -lLLVMARMCodeGen -lLLVMARMAsmParser -lLLVMARMDesc -lLLVMARMInfo -lLLVMARMAsmPrinter -lLLVMARMUtils -lLLVMAMDGPUDisassembler -lLLVMAMDGPUCodeGen -lLLVMAMDGPUAsmParser -lLLVMAMDGPUDesc -lLLVMAMDGPUInfo -lLLVMAMDGPUAsmPrinter -lLLVMAMDGPUUtils -lLLVMAArch64Disassembler -lLLVMAArch64CodeGen -lLLVMAArch64AsmParser -lLLVMAArch64Desc -lLLVMAArch64Info -lLLVMAArch64AsmPrinter -lLLVMAArch64Utils -lLLVMObjectYAML -lLLVMLibDriver -lLLVMOption -lLLVMWindowsManifest -lLLVMFuzzMutate -lLLVMX86Disassembler -lLLVMX86AsmParser -lLLVMX86CodeGen -lLLVMGlobalISel -lLLVMSelectionDAG -lLLVMAsmPrinter -lLLVMDebugInfoCodeView -lLLVMDebugInfoMSF -lLLVMX86Desc -lLLVMMCDisassembler -lLLVMX86Info -lLLVMX86AsmPrinter -lLLVMX86Utils -lLLVMMCJIT -lLLVMLineEditor -lLLVMInterpreter -lLLVMExecutionEngine -lLLVMRuntimeDyld -lLLVMCodeGen -lLLVMTarget -lLLVMCoroutines -lLLVMipo -lLLVMInstrumentation -lLLVMVectorize -lLLVMScalarOpts -lLLVMLinker -lLLVMIRReader -lLLVMAsmParser -lLLVMInstCombine -lLLVMTransformUtils -lLLVMBitWriter -lLLVMAnalysis -lLLVMProfileData -lLLVMObject -lLLVMMCParser -lLLVMMC -lLLVMBitReader -lLLVMCore -lLLVMBinaryFormat -lLLVMSupport -lLLVMDemangle -l/usr/lib/libz.dylib -lcurses -lm
clang: warning: argument unused during compilation: '-pthread' [-Wunused-command-line-argument]
ld: library not found for -l/usr/lib/libz.dylib
clang: error: linker command failed with exit code 1 (use -v to see invocation)
make: *** [lib/libtvm_runtime.dylib] Error 1
-l/usr/lib/libz.dylibを-lzとして、コマンドを再実行することでビルドできました。
c++ -std=c++11 -Wall -O2 -Iinclude -I/Users/tkato/work/chainer-nnvm/nnvm/tvm/dlpack/include -I/Users/tkato/work/chainer-nnvm/nnvm/tvm/dmlc-core/include -IHalideIR/src -Itopi/include -fPIC -DTVM_CUDA_RUNTIME=0 -DTVM_ROCM_RUNTIME=0 -DTVM_OPENCL_RUNTIME=1 -DTVM_METAL_RUNTIME=0 -framework OpenCL -shared -o lib/libtvm_runtime.dylib build/runtime/c_dsl_api.o build/runtime/c_runtime_api.o build/runtime/cpu_device_api.o build/runtime/dso_module.o build/runtime/file_util.o build/runtime/module.o build/runtime/module_util.o build/runtime/registry.o build/runtime/system_lib_module.o build/runtime/thread_pool.o build/runtime/workspace_pool.o build/runtime/opencl/opencl_device_api.o build/runtime/opencl/opencl_module.o build/runtime/rpc/rpc_device_api.o build/runtime/rpc/rpc_event_impl.o build/runtime/rpc/rpc_module.o build/runtime/rpc/rpc_server_env.o build/runtime/rpc/rpc_session.o build/runtime/rpc/rpc_socket_impl.o build/runtime/graph/graph_runtime.o -pthread -lm -ldl -L/usr/local/Cellar/llvm/HEAD-8b47f7b/lib -Wl,-search_paths_first -Wl,-headerpad_max_install_names -lLLVMLTO -lLLVMPasses -lLLVMObjCARCOpts -lLLVMMIRParser -lLLVMSymbolize -lLLVMDebugInfoPDB -lLLVMDebugInfoDWARF -lLLVMCoverage -lLLVMTableGen -lLLVMDlltoolDriver -lLLVMOrcJIT -lLLVMXCoreDisassembler -lLLVMXCoreCodeGen -lLLVMXCoreDesc -lLLVMXCoreInfo -lLLVMXCoreAsmPrinter -lLLVMSystemZDisassembler -lLLVMSystemZCodeGen -lLLVMSystemZAsmParser -lLLVMSystemZDesc -lLLVMSystemZInfo -lLLVMSystemZAsmPrinter -lLLVMSparcDisassembler -lLLVMSparcCodeGen -lLLVMSparcAsmParser -lLLVMSparcDesc -lLLVMSparcInfo -lLLVMSparcAsmPrinter -lLLVMPowerPCDisassembler -lLLVMPowerPCCodeGen -lLLVMPowerPCAsmParser -lLLVMPowerPCDesc -lLLVMPowerPCInfo -lLLVMPowerPCAsmPrinter -lLLVMNVPTXCodeGen -lLLVMNVPTXDesc -lLLVMNVPTXInfo -lLLVMNVPTXAsmPrinter -lLLVMMSP430CodeGen -lLLVMMSP430Desc -lLLVMMSP430Info -lLLVMMSP430AsmPrinter -lLLVMMipsDisassembler -lLLVMMipsCodeGen -lLLVMMipsAsmParser -lLLVMMipsDesc -lLLVMMipsInfo -lLLVMMipsAsmPrinter -lLLVMLanaiDisassembler -lLLVMLanaiCodeGen -lLLVMLanaiAsmParser -lLLVMLanaiDesc -lLLVMLanaiAsmPrinter -lLLVMLanaiInfo -lLLVMHexagonDisassembler -lLLVMHexagonCodeGen -lLLVMHexagonAsmParser -lLLVMHexagonDesc -lLLVMHexagonInfo -lLLVMBPFDisassembler -lLLVMBPFCodeGen -lLLVMBPFAsmParser -lLLVMBPFDesc -lLLVMBPFInfo -lLLVMBPFAsmPrinter -lLLVMARMDisassembler -lLLVMARMCodeGen -lLLVMARMAsmParser -lLLVMARMDesc -lLLVMARMInfo -lLLVMARMAsmPrinter -lLLVMARMUtils -lLLVMAMDGPUDisassembler -lLLVMAMDGPUCodeGen -lLLVMAMDGPUAsmParser -lLLVMAMDGPUDesc -lLLVMAMDGPUInfo -lLLVMAMDGPUAsmPrinter -lLLVMAMDGPUUtils -lLLVMAArch64Disassembler -lLLVMAArch64CodeGen -lLLVMAArch64AsmParser -lLLVMAArch64Desc -lLLVMAArch64Info -lLLVMAArch64AsmPrinter -lLLVMAArch64Utils -lLLVMObjectYAML -lLLVMLibDriver -lLLVMOption -lLLVMWindowsManifest -lLLVMFuzzMutate -lLLVMX86Disassembler -lLLVMX86AsmParser -lLLVMX86CodeGen -lLLVMGlobalISel -lLLVMSelectionDAG -lLLVMAsmPrinter -lLLVMDebugInfoCodeView -lLLVMDebugInfoMSF -lLLVMX86Desc -lLLVMMCDisassembler -lLLVMX86Info -lLLVMX86AsmPrinter -lLLVMX86Utils -lLLVMMCJIT -lLLVMLineEditor -lLLVMInterpreter -lLLVMExecutionEngine -lLLVMRuntimeDyld -lLLVMCodeGen -lLLVMTarget -lLLVMCoroutines -lLLVMipo -lLLVMInstrumentation -lLLVMVectorize -lLLVMScalarOpts -lLLVMLinker -lLLVMIRReader -lLLVMAsmParser -lLLVMInstCombine -lLLVMTransformUtils -lLLVMBitWriter -lLLVMAnalysis -lLLVMProfileData -lLLVMObject -lLLVMMCParser -lLLVMMC -lLLVMBitReader -lLLVMCore -lLLVMBinaryFormat -lLLVMSupport -lLLVMDemangle -lz -lcurses -lm
AndroidのGPUで実行すると、CL_INVALID_WORK_GROUP_SIZE エラーとなる
最初、YOLOv2_tinyの入力を416x416で試していたのですが、以下のエラーが出ました。
tvm._ffi.base.TVMError: Except caught from RPC call: [01:49:31] /Users/tkato/work/chainer-nnvm/nnvm/tvm/apps/android_rpc/app/src/main/jni/../../../../../../include/../src/runtime/module_util.cc:46: Check failed: ret == 0 (-1 vs. 0) [01:49:31] /Users/tkato/work/chainer-nnvm/nnvm/tvm/apps/android_rpc/app/src/main/jni/../../../../../../include/../src/runtime/opencl/opencl_module.cc:223: Check failed: e == CL_SUCCESS OpenCL Error, code=-54: CL_INVALID_WORK_GROUP_SIZE
根本的な解決ではありませんが、入力画像サイズを小さくしたところ、このエラーは生じなくなりました。
入力画像サイズを変えながら、各OpenCLカーネル実行時のgrobal_work_sizeとlocal_work_sizeをログ出力して確認したところ、画像サイズが大きくなるほどwork_sizeが大きくなることがわかりました。しかしそれ以上深入りするのは、やめた。
ONNX-Chainerでうまくモデルを変換できない
onnx_chainer.export()で生成したONNXファイルを見ると、以下のようにバラバラになってることがありました。
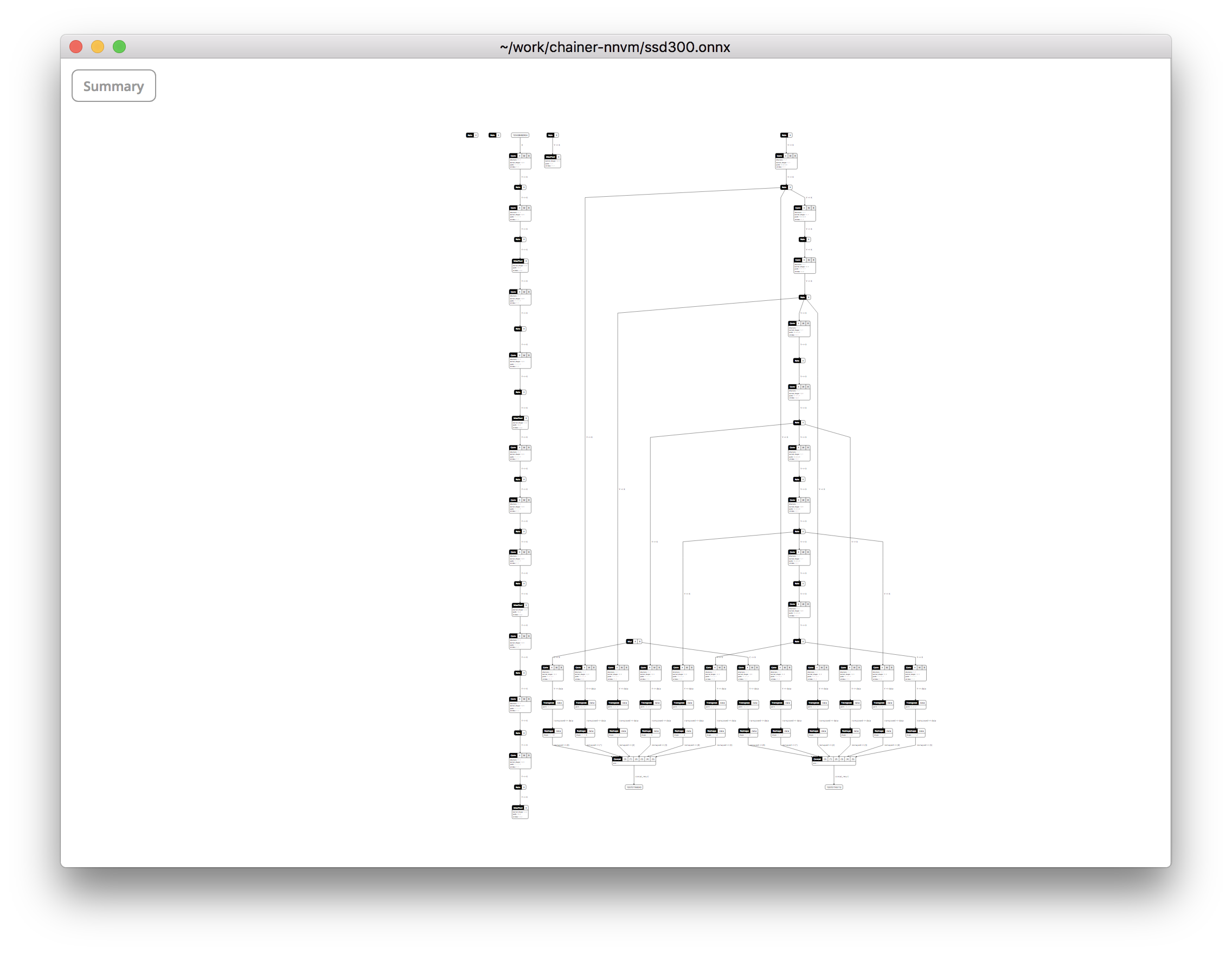
ONNX-Chainerのサポート外のレイヤーを含むモデルを変換したときにこうなりました。
ONNX-ChainerがサポートするレイヤーはSupported Functionsにちゃんと記載がありますのでよく読みましょう。むしろサポートするレイヤーを増やすために積極的にContributeしていきたい気持ち。
ちなみにONNXがサポートしているレイヤーはOperator Schemasに記載があります。今今は、各フレームワークでどのレイヤーがサポートしているかを把握してモデルの設計をするのが大切です。
NNVMでONNXをインポート時にエラー
NNVMでONNXからインポートする際に以下のエラーが出た。
nnvm._base.NNVMError: [22:09:11] src/core/symbolic.cc:290: Check failed: args.size() <= n_req (3 vs. 2) Incorrect number of arguments, requires 2, provided 3
エラーが生じたのは、ONNXの定義ではConvレイヤーの入力が、X, W, bの3つ使っているモデルだった。
NNVMのONNXインポート部分のコードを読むと、convレイヤーはextras={'use_bias': False}となっている。
つまり、NNVMはX,Wの2入力のConvしか対応していない。
def _conv():
def _impl(inputs, attr, params):
# get number of channels
channels = _infer_channels(inputs[1], params)
attr['channels'] = channels
return AttrCvt(
op_name=_dimension_picker('conv'),
transforms={
'kernel_shape': 'kernel_size',
'dilations': ('dilation', (0, 0)),
'pads': ('padding', (0, 0), _revert_caffe2_pad),
'group': ('groups', 1)},
extras={'use_bias': False},
custom_check=_dimension_constraint())(inputs, attr)
return _impl
バイアスがないConvレイヤーは、Chainerでは以下のように定義できますね。
self.conv1 = L.Convolution2D(None, 16, 3, stride=1, pad=1, nobias=True)
他にもFCレイヤーが変換できない問題もありました。同様の原因かな。NNVM/TVMとONNXのバージョンが合っていないかも…
そんなこんなで、ようやく動くモデルがYOLOv2_tinyだったわけです。
別のモデルとして、yusuketomoto/chainer-fast-neuralstyleも試してみました。リアルタイムにAndroidのGPUで画風変換ができたら面白い!
NNVMがELUを非サポートなのはとりあえずReLUで代用し、bias付きConvが非対応問題は強引に無視したりしてなんとかTVMでビルドができたものの、32x32より大きい画像ではCL_INVALID_WORK_GROUP_SIZEのエラーが出た。32x32で画風変換しても面白くないので中断した。
以上、最後の最後まで読んでいただきありがとうございました。