はじめに
TensorFlow初心者の私が、"Getting Started with TensorFlow" を勉強していると
- 日本語の記事ほとんどMNISTの話ばっかじゃねーか!
- しかもCNNの内容とコードの話しかまとめられてねぇ!
- 公式のチュートリアルは途中でいろんな機能の話になるから体系的に理解できねぇ!
と感じたので、自分なりにまとめてみようと思います。
本記事のゴールは、様々なページに散らばった情報をまとめ、TensorFlowの大枠を理解するです。
今回はMNISTのコードを追いつつ、そこで使われるTensorFlowの機能などを紹介していきます。
コードについての細かな説明は他の方がされているので、あまりしません。
一応簡単な説明は英語でコードにコメントで入れてあります。
気になる方はこれを読み終わった後に他の記事なり公式のコードなりを追って勉強しましょう。
あと英語が読めるならこんな稚拙な記事を読まずに公式のチュートリアルを読みましょう。
クッソわかりやすいです。
環境
TensorFlow API r1.5です。
TensorFlowのAPIについて
そもそもTensorFlowって何?という方は、「データフローグラフで計算を表現する~」うんぬん説明するより、こちらの記事を読んだ後にこちらの記事を読んだ方が直感的に理解できると思います。
TensorFlowにはAPI layer(以下API)が複数存在します。TensorFlowではAPIの中の様々なclassを呼び出すことで楽をしながらプログラムを書いていきます。TensorFlowには以下のAPIが存在します。
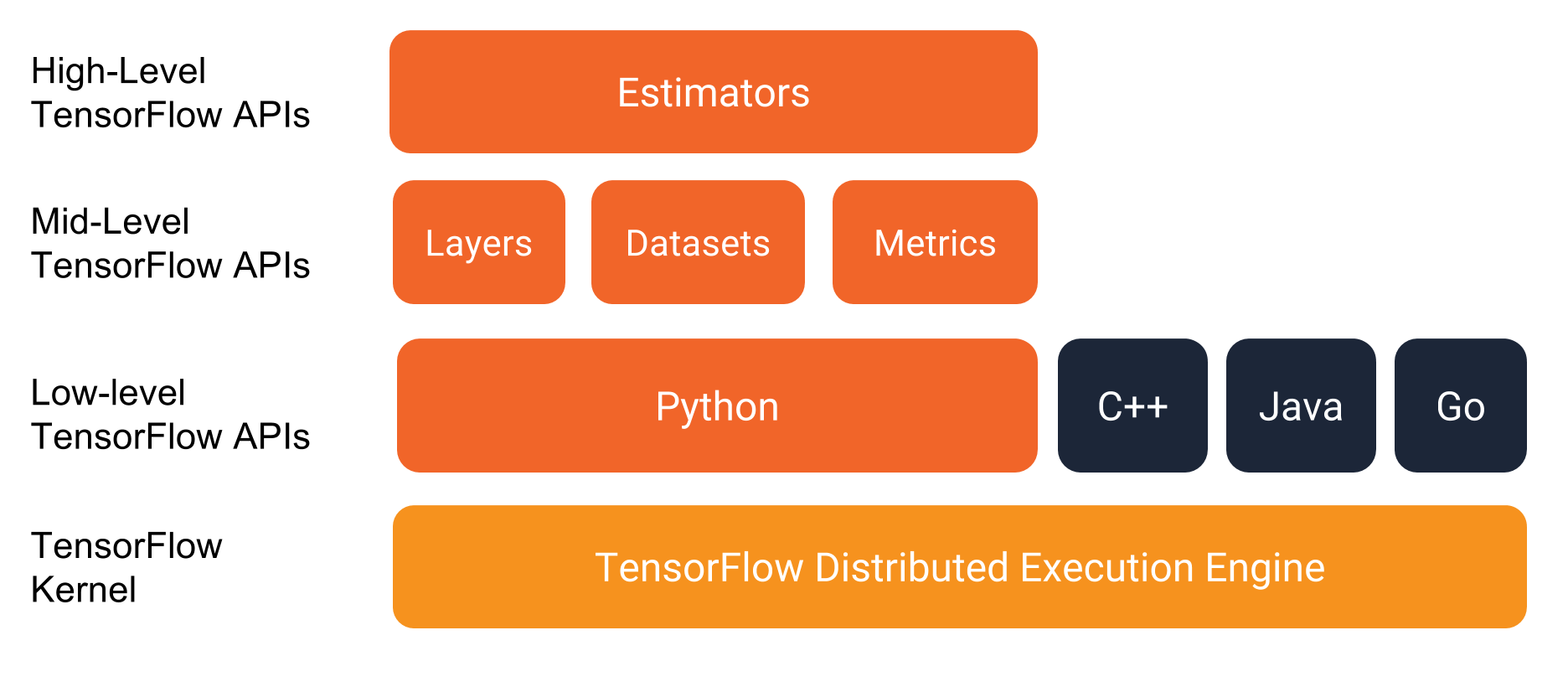
ちなみにGetting Startedでは「EstimatorsとDatasetsを使ってプログラミングを書こうね!!」と書かれていました。
2017年のプレゼンを見た感じだと、TensorFlowはもともとLow-levelなAPIの集まりで、「自由度はめっちゃ高いけど高度なプログラムを実装するのは大変」という状態だったのが、よく使われる手法をHigh-Level APIsとしてTensorFlowに組み込むことで、実装がとても簡単になったそうです。よりLevelの高いAPIsには機械学習でのベストプラクティスとされてきた手法が組み込まれているので、Getting Startedに「EstimatorsとDatasetsを使おう」と書いているのだと思います。
-
Estimators
完成したmodelを表す。modelを訓練したり、accuracyを計算したり、予想したりするときに使います。 -
Datasets
データをinputするときのパイプラインを作るAPI。データを読み込んだり操作したり、扱ってるmodelに組み込むときに使います。
チュートリアルに出てきた内容まとめ
はじめに
先述の通り、公式のコードやQiitaの他の記事を次に読むことを想定し、MNISTを例に説明していきます。
プログラムの流れは大体こんな感じです。
-
cnn_model_fnを定義
-
modelを選択する
-
predictingの設定
-
loss functionの設定
-
trainingの設定
-
evaluatingの設定
-
mainを定義
-
データを読み込む
-
Estimatorの作成
-
Logの作成
-
modelをtrainingする
-
modelをevaluatingして結果をprint
なお、今回使用するコードは公式のGitHubから引っ張ってきています。
CNNってなんだよって方は世界一わかりやすい動画を見るなり他の記事を見るなりしてください。
以下、CNNについて少しは知っているという体で話を進めていきます。
今回扱うモデルの説明
今回扱うモデルは以下のような階層になっています。
-
Convolutional Layer #1:
5x5のフィルターが32枚、activation functionはReLUを使います。 -
Pooling Layer #1:
2x2のフィルターをstride=2でずらしていきます。(フィルターが重ならないようストライドする) -
Convolutional Layer #2:
5x5のフィルターが32枚、activation functionはReLUを使います。 -
Pooling Layer #2:
2x2のフィルターをstride=2でずらしていきます。(フィルターが重ならないようストライドする) -
Dense Layer #1:
ニューロンが1024個、40%をドロップアウトする。 -
Dense Layer #2 (Logits Layer):
ニューロンが10個、それぞれにtarget class (0–9)を持つ。
それでは順に見ていきましょう。
最初に関数ごとのコードを載せ、その後に個々の説明をしていきます。
TensorFlowの概要だけつかみたい人は、コードを飛ばして機能面の説明だけ読んでください。
cnn_model_fnを定義
def cnn_model_fn(features, labels, mode):
"""Model function for CNN."""
# Input Layer
# Reshapes X to 4-D tensor: [batch_size, witdth, height, channels].
# MNIST images are 28x28 pixels, and have one color channel.
# -1 specifies that this dimension should be dynamically computed
# based on the number of input values in features["x"],
# holding the size of all other dimensions constant.
input_layer = tf.reshape(features["x"], [-1, 28, 28, 1])
# Convolutional Layer #1
# Conputes 32 features using a 5x5 filter with ReLU activation.
# Padding is added to preserve width and height.
# Input Tensor Shape: [batch_size, 28, 28, 1]
# Output Tensor Shape: [batch_size, 28, 28, 32]
conv1 = tf.layers.conv2d(
inputs = input_layer,
filters = 32,
kernel_size = [5, 5],
padding = "same",
activation = tf.nn.relu)
# Pooling Layer #1
# First max pooling layer with a 2x2 filter and stride of 2
# Input Tensor Shape: [batch_size, 28, 28, 32]
# Output Tensor Shape: [batch_size, 14, 14, 32]
pool1 = tf.layers.max_pool2d(inputs = conv1, pool_size = [2, 2], strides = 2)
# Convolutional Layer #2
# Conputes 64 features using a 5x5 filter.
# Padding is added to preserve width and height.
# Input Tensor Shape: [batch_size, 14, 14, 32]
# Output Tensor Shape: [batch_size, 14, 14, 64]
conv2 = tf.layers.conv2d(
inputs = pool1,
filters = 64,
kernel_size = [5, 5],
padding = "same",
activation = tf.nn.relu)
# Pooling Layer #2
# Second max pooling layer with a 2x2 filter and stride of 2
# Input Tensor Shape: [batch_size, 14, 14, 64]
# Output Tensor Shape; [batch_size, 7, 7, 64]
pool2 = tf.layers.max_pool2d(inputs = conv2, pool_size = [2, 2], strides = 2)
# Flatten tensor into a batch of vectors
# Input Tensor Shape: [batch_size, 7, 7, 64]
# Output Tensor Shape: [batch_size, 7 * 7 * 64]
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 64])
# Dense Layer
# Densely connected layer with 1024 neurons
# Input Tensor Shape: [batch_size, 7 * 7 * 64]
# Output Tensor Shape: [batch_size, 1024]
dense = tf.layers.dense(inputs = pool2_flat, units = 1024, activation = tf.nn.relu)
# Add dropout operation; 0.6 probability that element will be kept
dropout = tf.layers.dropout(
inputs = dense, rate = 0.4, training = mode == tf.estimator.ModeKeys.TRAIN)
# Logits layer
# Input Tensor Shape: [batch_size, 1024]
# Output Tensor Shape: [batch_size, 10]
logits = tf.layers.dense(inputs = dropout, units = 10)
predictions = {
# Generate predictions (for PREDICT and EVAL mode)
"classes": tf.argmax(input = logits, axis = 1),
# Add softmax_tensor to the graph. It is used for PREDICT and
# by the logging_hook
"probabilities": tf.nn.softmax(logits, name = "softmax_tensor")}
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode = mode, predictions = predictions)
# Calculate Loss (for both TRAIN and EVAL modes)
# First, transfer one-hot
loss = tf.losses.sparse_softmax_cross_entropy(labels = labels, logits = logits)
# Configure the Training Op (for TRAIN mode)
if mode == tf.estimator.ModeKeys.TRAIN:
optimizer = tf.train.GradientDescentOptimizer(learning_rate = 0.001)
train_op = optimizer.minimize(
loss = loss,
global_step = tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode = mode, loss = loss, train_op = train_op)
# Add evaluation metrics (for EVAL mode)
eval_metric_ops = {
"accuracy": tf.metrics.accuracy(
labels = labels, predictions = predictions["classes"])}
return tf.estimator.EstimatorSpec(
mode = mode, loss = loss, eval_metric_ops = eval_metric_ops)
コードを見るとわかる通り、modelのlayerに関してはLayers APIを呼び出して実装しています。tf.layers.****でレイヤーを実装できるので、すごく便利です。
最初は「ああ、APIsにあるモデルやレイヤーを使うとこうやってすぐに実装できるんだな」程度の認識でいいと思います。
Modekeys, EstimatorSpecについて
チュートリアルを追っていてわかりにくかったのはmodeを選択する部分です。
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode = mode, predictions = predictions)
TensorFlowではmodel functionは必ずmodeを受け取らなければなりません。
TRAIN EVAL PREDICTの中から一つを3つから選び、tf.estimator.ModeKeys.*******の形で、modelを実行する際に指定します。
また、どんなmodelでも実行後は実行者が求める結果を返す必要があります。その結果を受け取るのがEstimatorSpecです。2行目ではtf.estimator.EstimatorSpecが返され、実行したmodeをmodeに、modelの実行結果をpredictionsに保持しています。
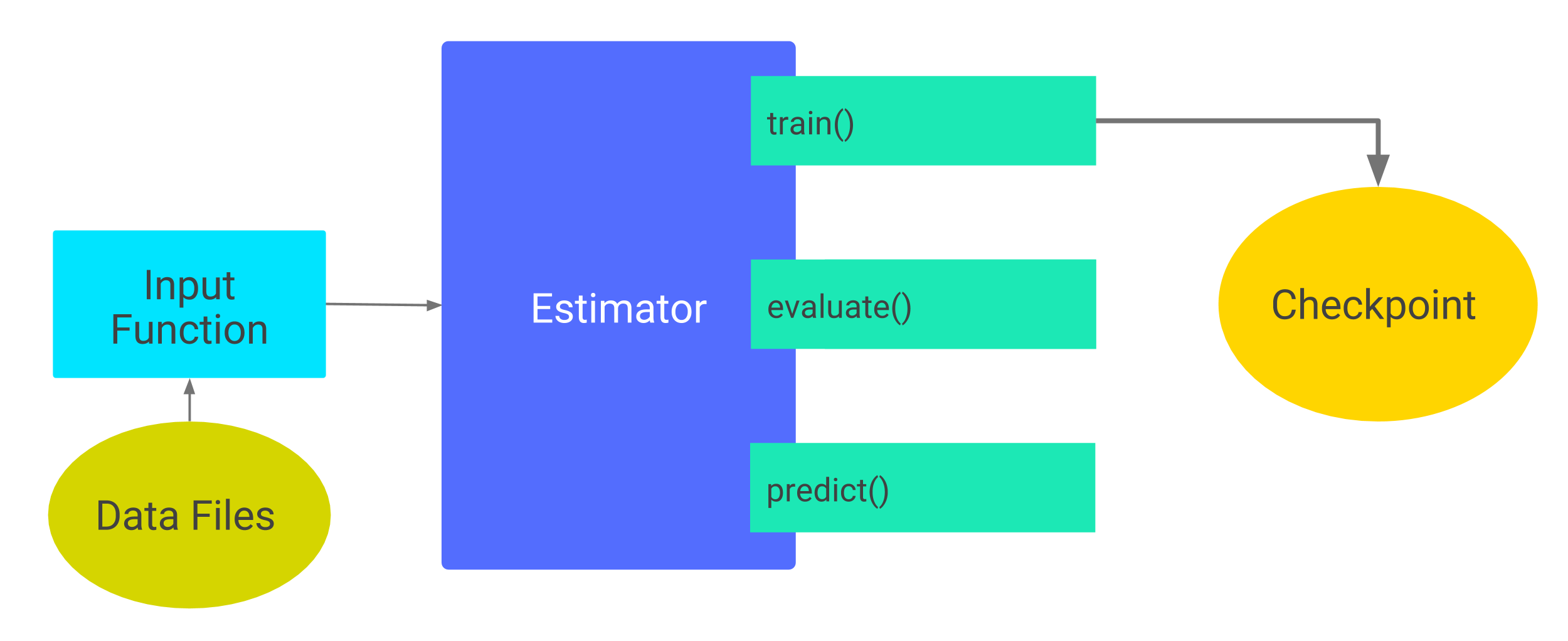
Estimators について
Estimators APIには、Pre-made EstimatorsとCustom Estimatorsがあります。
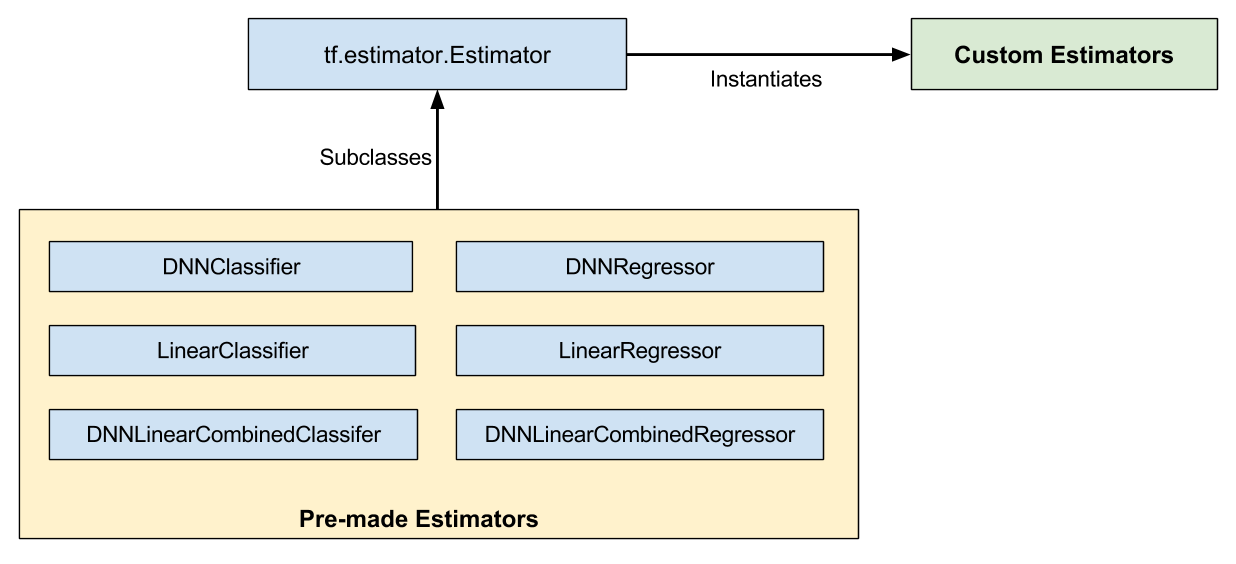
Pre-made Estimatorsには上図のような一般的な機械学習のmodelがプリセットで組み込まれています。また、Pre-made Estimatorsを改良してmodelを作ることもできます。Custom EstimatorsはEstimatorsのインスタンスで、Pre-made Estimatorsでは対応できないようなモデルを使いたいときに、自らCustom Estimatorsを作ります。Custom Estimatorsの作り方はこちらのドキュメント、Estimators API自体の詳しい説明はこちらのProgrammer's Guideをご覧ください。
今回はCNN modelをCustom Estimatorとして実装しています。
Pre-made Estimatorsの場合
Pre-made Estimatorsを使う際は、以下の手順が必要になります。
- 一つ以上のinput functionを作成する
- modelのFeature Columnsを定義する
- Estimatorsのインスタンスを作成し、feature columnsとhyperparametersを設定する
- Estimator objectを呼び出し、dataをinput functionに通す
input function、Feature Columnsについては後で触れます。
詳しく知りたい人はこちらのチュートリアルをご覧ください。
mainを定義
def main(unused_argv):
# Load training and eval data
mnist = tf.contrib.learn.datasets.load_dataset("mnist")
train_data = mnist.train.images # Returns np.array
train_labels = np.asarray(mnist.train.labels, dtype=np.int32)
eval_data = mnist.test.images # Returns np.array
eval_labels = np.asarray(mnist.test.labels, dtype=np.int32)
# Create the Estimator
mnist_classifier = tf.estimator.Estimator(
model_fn=cnn_model_fn, model_dir="/tmp/mnist_convnet_model")
# Set up logging for predictions
# Log the values in the "Softmax" tensor with label "probabilities"
tensors_to_log = {"probabilities": "softmax_tensor"}
logging_hook = tf.train.LoggingTensorHook(
tensors=tensors_to_log, every_n_iter=50)
# Train the model
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": train_data},
y=train_labels,
batch_size=100,
num_epochs=None,
shuffle=True)
mnist_classifier.train(
input_fn=train_input_fn,
steps=20000,
hooks=[logging_hook])
# Evaluate the model and print results
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
x={"x": eval_data},
y=eval_labels,
num_epochs=1,
shuffle=False)
eval_results = mnist_classifier.evaluate(input_fn=eval_input_fn)
print(eval_results)
データについて
便利なことにMNISTの学習データは、すでにTensorFlowの中に組み込まれているので、今回はそれを呼び出します。
仮に自分の手で1からdataをimportする際は、先ほどのAPIsの組織図のところで言及されていた、Datasets APIを使用すると良いでしょう。Importing dataに関する詳しい解説は公式のProgrammer's Guideを読んでください。
読み込んだdataを操作する際もDatasets APIを使うと便利です。
Input Fucnction について
今回は必要ありませんでしたが、本来training, evaluating, predictingをする際にデータを受け取るために、input functionsを作成する必要があります。
input functionsは以下の2つの要素を持つtupleを返します。
-
features
それぞれのkeyがfeatureの名前、valueがfeature's valuesのpython dictionary -
labels
すべてのexampleのlabelの値を持つarray
ごくシンプルなinput funtionの例を示します。
def input_evaluation_set():
features = {'SepalLength': np.array([6.4, 5.0]),
'SepalWidth': np.array([2.8, 2.3]),
'PetalLength': np.array([5.6, 3.3]),
'PetalWidth': np.array([2.2, 1.0])}
labels = np.array([2, 1])
return features, labels
input functionsは先ほど紹介したDatasets APIを使うと、データの処理が楽になります。
def train_input_fn(features, labels, batch_size):
"""An input function for training"""
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# Shuffle, repeat, and batch the examples.
dataset = dataset.shuffle(1000).repeat().batch(batch_size)
# Build the Iterator, and return the read end of the pipeline.
return dataset.make_one_shot_iterator().get_next()
Feature Columns について
こちらも今回は出てきませんでしたが、本来は必要なものです。
Feature Columnsとは読み込まれたraw dataと、Estimatorsをつなぐ仲介役みたいなものです。
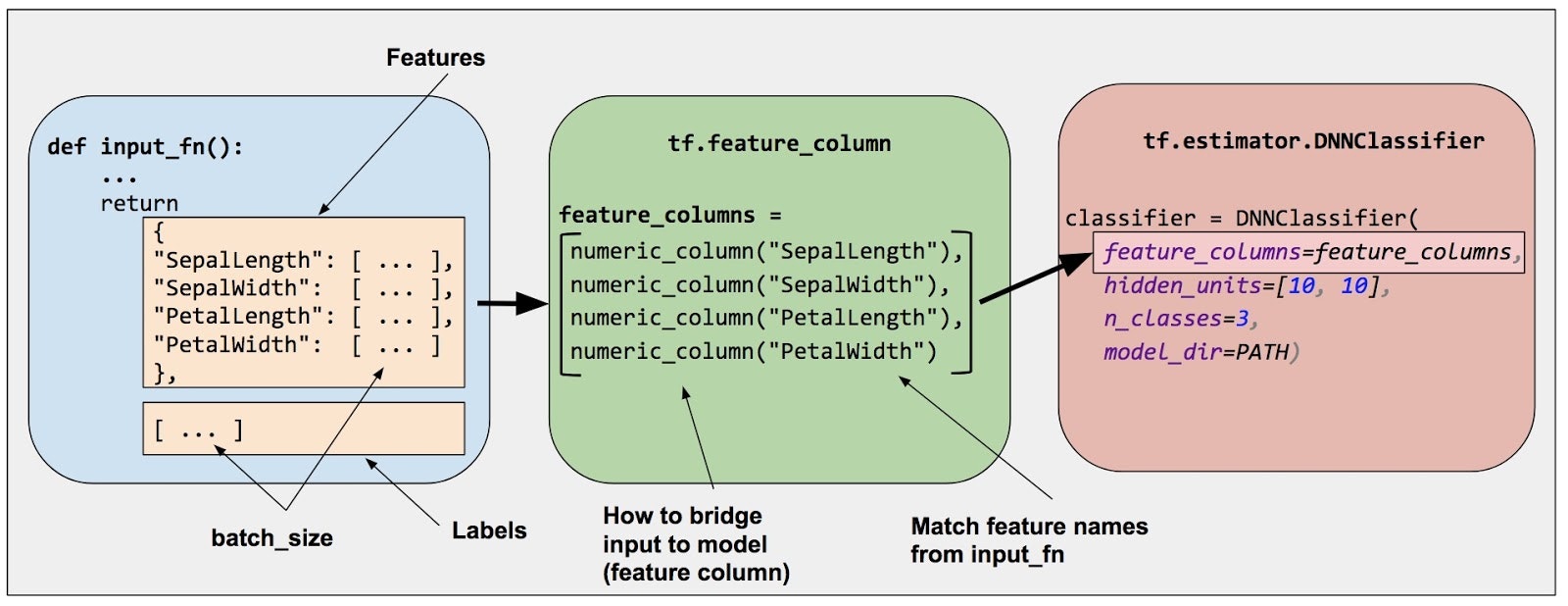
時にはカテゴリー別に、また時には数値として、あるいはその両方として分類したりと、汎用性が高く多様な形でEstimatorsが処理可能なデータに変換できるので、奥が深そうです。
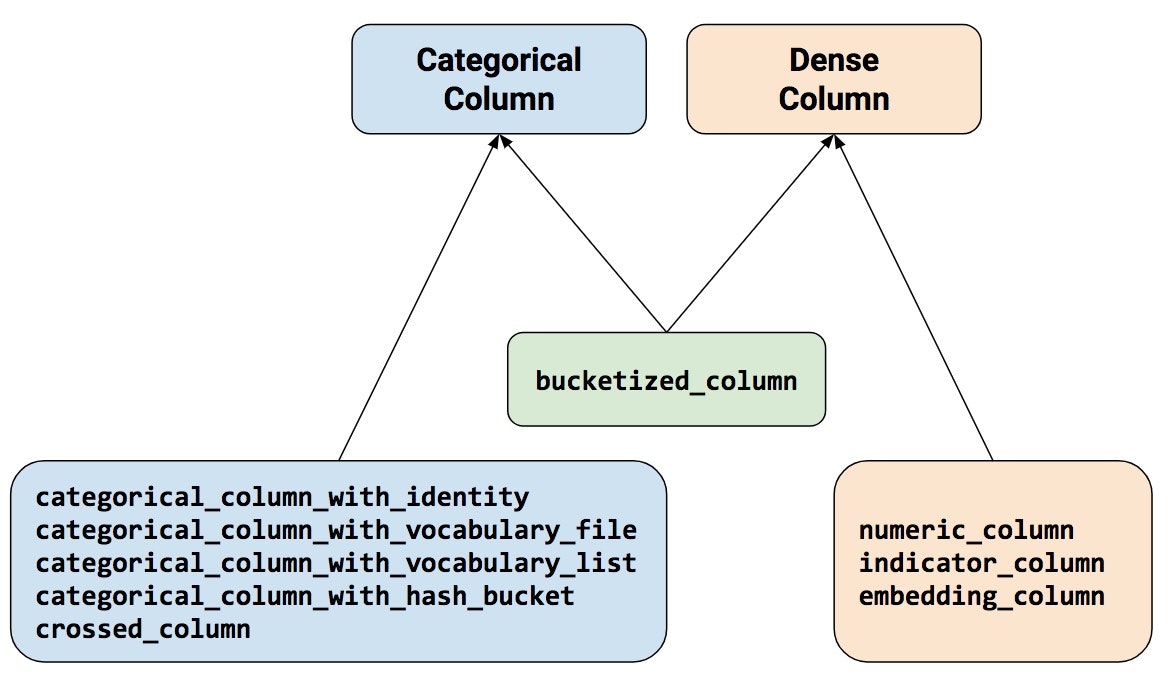
Feature Columnsの詳しい説明はこちらをご覧ください。
Checkpoints, SavedModelについて
TensorFlowには、オートセーブ機能が大きく分けて2つ存在します。
-
Checkpoints
modelのコードに依存したオートセーブフォーマット -
SavedModel
modelのコードに依存しないオートセーブフォーマット
Estimatorsにプリセットされてる機能で簡単なセーブポイントを設定したい!って人はCheckpointsを、もっと自分でカスタマイズしたい!って人はSavedModelを使えばいいと思います。
Checkpointsでは、model_dirという引数を設定し、保存先を指定します。
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
hidden_units=[10, 10],
n_classes=3,
model_dir='models/iris')
そうすると、training中の様々なバージョンのcheckpointsがmodel_dirに保存されます。
また、event filesというものも作成されますが、これは後述するTensorBoardがtrainingの様子を可視化する際に使用する情報です。
Checkpointsについてはこちら、SavedModelについてはこちらをご覧ください。
その他
公式のドキュメントについて
公式には
という3つのドキュメントがあります。
Getting Startedの内容は、この記事であらかたまとめたので、基本的に読まなくてもいいと思います。もし説明中に気になる部分があったなら、リンク先に飛んで読んでください。
この記事を読んだ方は、Tutorialsを読み進めるのがいいと思います。ImagesのA Guide to TF Layers: Building a Convolutional Neural Networkというのが、今回扱ったMNISTのチュートリアルです。それ以降で気になる項目を読み進めましょう。
Programmer's Guideというのは、実際にTensorFlowでコードを実装し始めたプログラマー向けのドキュメントだそうです。内容も具体的なTensorFlowの機能に絞られています。プログラムを書き進める中でAPIsなどで分からないことがあったときは、このドキュメントが役に立ちそうです。
TensorBoardについて
TensorFlowにはTensorBoardというとても便利なツールがあります。
自分の書いたgraph(プログラム)を可視化したり、trainingの過程を可視化したり、とりあえず可視化しまくれるものです。話を聞くのが好きな人はこちらのプレゼン、サクッと使い方を知りたい人はこちらの記事を、じっくり勉強したい人は公式のProgrammer's Guideにあるリファレンスを読んでください。
最後に
TensorFlowの公式ホームページには検索ボックスがあります。
こうやってキーワードを打つと、キーワードとしても、クエリとしても検索してくれます。
TensorFlowではバージョンが変わると今まで使ってたAPIsのインスタンスの階層が変わっていたりします。
なので、コードを参考にする前にしっかりとバージョンを確認し、間違っていないのにエラーを吐かれたら公式でリファレンスを確認するようにしてください。
参照
- TensorFlowのキーコンセプト: Opノード、セッション、変数
- TensorFlowの基礎
- TensorFlow High-Level APIs: Models in a Box (TensorFlow Dev Summit 2017)
- A friendly introduction to Convolutional Neural Networks and Image Recognition
- cnn_mnist.py - GitHub
- Getting Started for ML Beginners
- Getting Started with TensorFlow
- A Guide to TF Layers: Building a Convolutional Neural Network
- Estimators - Programmer's Guide
- Creating Custom Estimators - Getting Started
- Importing data - Programmer's Guide
- Feature Columns - Getting Started
- Checkpoints - Getting Started
- Saving and Restoring - Programmer's Guide
- Hands-on TensorBoard (TensorFlow Dev Summit 2017)
- TensorBoardの最も基本的な使い方
- TensorBoard: Visualizing Learning - Programmer's Guide