この記事はLITALICO Advent Calendar 2023のカレンダー2の16日目の記事です。
https://qiita.com/advent-calendar/2023/litalico
はじめに
自己紹介
株式会社LITALICOでWEBエンジニアをやっています。ti-aiutoと申します。
普段は個人向けのWEBサービスの開発を担当していて、特にモノリスなアプリケーションを持続可能な形に保つこと、フロントエンドの開発しやすい環境を整えることに関心があります。
今年度から、新設の基盤グループというところに異動して、セキュリティ面・パフォーマンス面や開発効率向上などの観点から色々と動いていく仕事をしています。
何の話か
タイトルの通り、作業時点で7周年とそれなりに歴史のあるWEBサービスをEC2からFargateに移行するのを頑張りました!という話です。
作業していく中で検討したポイントや大変だったところなど紹介していければと思います。
対象読者
WEBエンジニアの皆さまに読み物としてふ〜んというテンションで読んでいただければうれしいな、と思って書いています。
今回のプロジェクトと同様にEC2->Fargateの移行を担当されるエンジニアの方がいればその参考になったらいいなと思います。
前置き
この記事は社内で知見を共有するために行った発表のスライドをベースにしています。説明の力点の置き方が独特かもしれませんがそのあたりはご容赦ください。
前提知識
移行対象のアプリケーションについて
移行対象のアプリケーションはRails製で、一般ユーザ向けと法人向けのそれぞれに向けた様々な機能が同居しています。機能によってはVue.jsを取り入れてほぼSPAのように作っているものもあります。
関連するAWSのサービスの雑な紹介
本文の中でも適宜説明していきます。
- EC2
- 仮想的なコンピュータを間借りして色々好きなものを入れて自由に使えるというサービスです
- 仮想的なコンピュータ1つのことを「EC2インスタンス」と呼びます
- ECS
- 「コンテナ」を稼働するために必要なリソースを確保して立ち上げて管理して…をよしなにやってくれるサービスです
- Fargate(ECS on Fargate)
- ECSでコンテナを動かすときに、そのために必要なマシンの調達やOSの設定なども含めてすべてよしなにやってくれるサービスです
- Fargateを使わずに、自力で調達したEC2インスタンスとECSを組み合わせて使うこともできます(ECS on EC2)
- ECR
- 「コンテナ」を動かすときに必要な「イメージ」を入れておけるサービスです
- ELB
- 複数あるサーバの各サーバに対してリクエストを振り分けて負荷分散をしてくれるのが「ロードバランサ」ですが、それがAWSのサービスとして提供されているやつです
- EventBridge
- 各種「イベント」をトリガーとしてAWSの各種サービスを発動させることで色々と連携ができるというサービスです
コンテナ化とは
「Dockerを使っていないなんて古い!あり得ない!」とバッシングを受けそうなこのご時世なので、「コンテナ」についての丁寧な説明は省略します。
逆にEC2を使ったWEBサーバ構築というのがあまりピンと来ないかもしれないので、そこの説明をしていければと思います。
「コンテナ化」を簡単に言えば、
- アプリケーションが稼働するために必要なものは色々ある
- 各種ライブラリ、設定ファイル、アプリケーションコード等々
- その必要なもの色々をまとめて「イメージ」というカタマリの中に入れておく
- その「イメージ」から起動した「コンテナ」さえあれば、アプリケーションを動かすことができる状態を作る
というところになると思います。今回はAWSのEC2というサービスを使って構築していたサーバを、AWSのFargateというサービスでコンテナを動かす形に変えていく話をします。
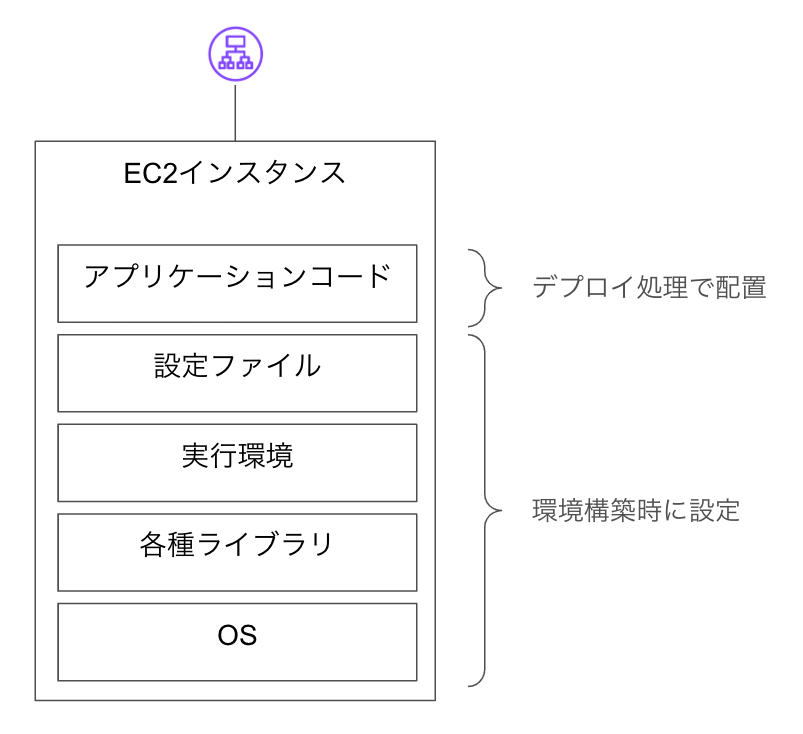
EC2を使う場合のサーバ構築
先ほど説明したように、EC2というのは「仮想的なコンピュータを間借りできる」というサービスですが、そのコンピュータがサーバとして稼働できるようにするために色々と設定をしないといけません。
- 各種ライブラリのインストール
- Cの標準ライブラリ、暗号化関連のライブラリ、画像処理ライブラリ等
- 監視やログ記録のためのツール等々
- rubyなど言語の実行環境のインストール
- OSや諸々のライブラリのための設定ファイル
- デプロイのための設定
- 新しく建てたサーバへデプロイするための設定
- そのサーバへリクエストが振り分けられるようロードバランサを設定
- OSや各種ライブラリは一度入れたら終わりではなく、稼働している間は継続的なアップデートが必要
- 基本的には一度立ち上げたEC2インスタンスは数週間・数ヶ月・数年と運用していくことが多い
- しかも複数台あるので、「このマシンは上げたけどこのマシンはまだ…」のような管理が必要な場合もある
見ての通り、まっさらなコンピュータに環境構築を行って必要なものをどんどん入れていくという作業になります。
Fargateを使う場合のサーバ構築
先ほどの「コンテナ化」の説明の通り、「イメージ」の中に必要なものをすべて入れておきます。
実行に必要なマシンの調達やOSの設定などはFargateがよしなにやってくれます。
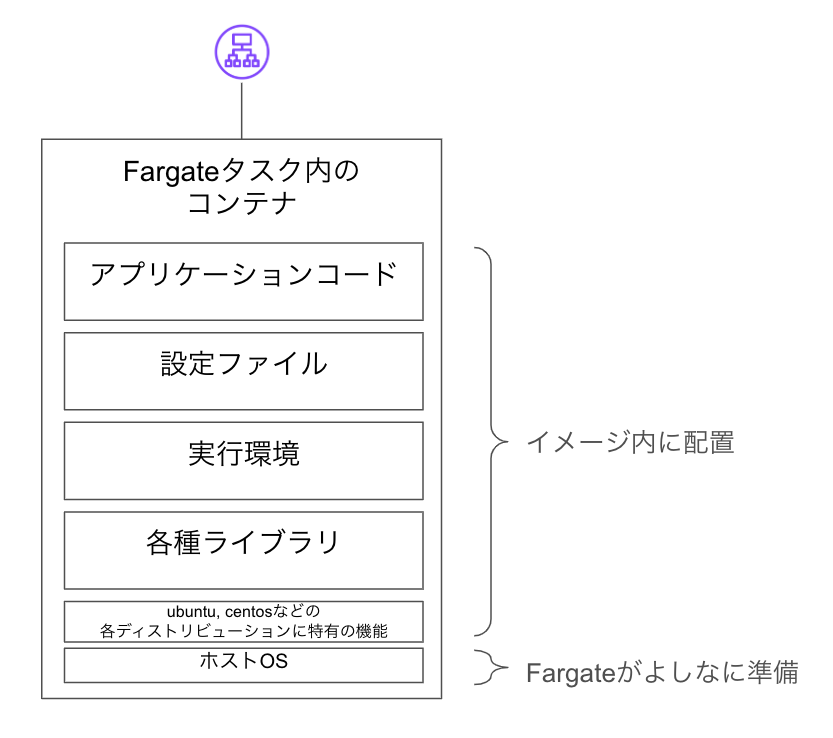
コンテナは数時間・数日など短いサイクルで入れ替わったり増減したりすることが多いので、次のような点に注意が必要です。
- ログファイルなど消えて困るものをコンテナ内に置かない
- 長時間かかる処理の実行中にコンテナが入れ替わると強制終了されてしまう場合がある
「責任共有モデル」の話
「EC2ではOSの設定やバージョンアップも含めて自力でやらないといけない」や「FargateだとOSの設定の部分も含めてよしなにやってくれる」という話をしましたが、「ここまではAWSがやってくれる」「ここまでは自分たちで責任を持ってやらないといけない」といった境界は「責任共有モデル」という概念の中で表現されています。
セキュリティとコンプライアンスは AWS とお客様の間で共有される責任です。この共有モデルは、AWS がホストオペレーティングシステムと仮想化レイヤーから、サービスが運用されている施設の物理的なセキュリティに至るまでの要素を AWS が運用、管理、および制御することから、お客様の運用上の負担を軽減するために役立ちます。お客様には、ゲストオペレーティングシステム (更新とセキュリティパッチを含む)、その他の関連アプリケーションソフトウェア、および AWS が提供するセキュリティグループファイアウォールの設定に対する責任と管理を担っていただきます。使用するサービス、それらのサービスの IT 環境への統合、および適用される法律と規制によって責任が異なるため、お客様は選択したサービスを慎重に検討する必要があります。
https://aws.amazon.com/jp/compliance/shared-responsibility-model/
詳細は次の記事などを読むとわかります。
プロジェクトについて
経緯
EC2は自由に柔軟にカスタマイズできる一方で、次のような課題がありました。
- どんどんライブラリや設定を追加していたが、まっさらな状態から環境構築する手順がわからない闇鍋のような状態だった
- 追加したライブラリのセキュリティアップデートの追随が遅れがちだった
- 水平スケールも垂直スケールも手順が多く対応しづらい状態だった
(1)に関しては、2020年12月のAmazonLinux(EC2で使っていたOS)のEoL対応時に、Ansibleを導入することで環境構築手順とライブラリアップデート手順のコードによる管理を達成できました。当時の状況は以下の記事にまとまっています。
ただ(2)や(3)の根本的な解決には至らず、中でもrubyのメジャーバージョンアップデートや画像処理ライブラリの脆弱性対応などの中で負担感が大きい状態が続いていました。そうした課題の大部分を解消できるということで、コンテナ化をいよいよ進めていくことになりました。
AmazonLinuxのEoL対応のときにコンテナ化まで踏み切れなかった理由としては、「定期実行処理の移行方法がどれもパッとしない」「EC2を使ってCapistranoを使ってデプロイすれば最速で1分20秒ほどで済むが、コンテナ化すると数倍〜十数倍かかる可能性が高い」といった点がありましたが、今回は「そのあたりはどうとでもできるでしょう」ということでコンテナ化のメリットを享受することを最優先に動くことになりました。
遠回りになった部分もあるかもしれませんが、Ansibleを導入して環境構築手順がコード管理されていたことにより、結果的にはコンテナ化をスムーズにつなげられることにもつながったと思います。
進め方
今回のコンテナ化のプロジェクトは、移行方法全体の設計やインフラのIaC化を含めた設計を @inomoto さんが行い、アプリケーション固有の事情を踏まえたデプロイ方法や運用方法の改善と、具体的なアプリケーションの修正対応を自分が行っていくという2人体制で進めていきました。
やることとしては大きく以下の4つに分かれました。作業順も単純なものから複雑なものへと進めたかったため、基本的には以下の通りで進めることになりました。
- 単発で実行するrakeタスクの移行
- 定期実行処理の移行
- Sidekiq(非同期処理)の移行
- WEBサーバの移行
スケジュール
最終的には以下のような流れで移行を完了しました。
- 2022年9月
- 他事業部事例や他社事例も参照しつつ設計をはじめる
- 2022年10月
- rakeタスクの移行に向けた作業を開始
- アプリケーションコンテナの準備
- FluentdやDatadogなどのサイドカーコンテナの準備
- 定期実行処理の実現方法の検討・作業開始
- rakeタスクの移行に向けた作業を開始
- 2022年11月〜12月
- WEBサーバ移行に向けた設計開始
- 定期実行処理の実現方法の変更
- 既存の定期実行処理のテストコードの追加作業
- Sidekiq移行に向けた作業開始
- 2023年1月
- 全定期実行処理の移行完了(1/19)
- 2023年2月
- Sidekiqの移行完了(2/8)
- WEBサーバの移行完了により、当初予定していた範囲のコンテナ化が完了(2/10)
なおコンテナ化自体は以上で終わりですが、そこからパフォーマンスチューニングの日々が始まることになります。
移行上の重要なポイント
共通してやったこと
基本的には必要な対応は、「コンテナ化での注意点」と対応します。
- サーバ内にファイルを配置する・ファイルを読み出す処理を直す
- ログはCloudWatchやDatadogに送る
- RSSやサイトマップ等、サーバ内にファイルを書き出す&読み出して返却していた処理は、S3経由に変更する
- 長時間かかる処理を直す
- WEBサーバ内の処理については非同期処理に切り出す
- Sidekiq内の処理については適切な粒度に処理の単位を分割する
定期実行処理
今回のコンテナ化の中で一番労力を使ったのは定期実行処理の移行でした。
定期実行処理というのは文字通り、時間をトリガーとして「定期」的に実行される処理のことです。広義の「バッチ処理」ですが、「バッチ処理」だと「時間がトリガー」感が薄いのでこういう「定期実行処理」と呼んでいます。
そもそも定期実行処理って要るの?
場合によっては「データの更新があったタイミングで、Sidekiqのキューに入れて非同期処理をする」といった方法をとることで、定期実行処理を使わなくてもやりたいことが実現できる場合があります。
冒頭でも紹介したように、今回移行対象のアプリケーションは2Bと2Cそれぞれに向けた様々な機能を持つため、定期実行処理もそれぞれの機能で必要なものが定義されています。全部数えると70種類で、一日に複数回実行されるものもあるので回数でいれば数百回になってきます。
そうした背景もあり、「本当に定期実行処理って全部残す必要あるんだっけ?」という話題も出てきたため、「なぜ必要なのか?」という観点でみていくことにしました。
結果的にはほぼ全てが残ることになったのですが、必要と判断した根拠は以下です。
- 時間がかかる・リソース消費が多いなどの理由で、時間帯や環境を分離したい処理
- サイトマップや各種RSSの生成、ランキングスコア計算など
- 時間指定で発動する処理
- レコードで指定した公開時刻や投稿時刻、送信予約時刻との比較で発動する処理など
- トリガーの条件が複雑な処理
- 関連レコードが何十個もあって、「その中でのどれか一つでも更新されたら発動したい」のような処理は、更新があろうがなかろうが一括で発動したほうが単純なこともある
- 親子関係(has_manyなど)のレコードが多い場合もあれば、兄弟関係(特定ユーザに対する他ユーザ)のレコードが多い場合もあれば
- 処理の成否を個別に追うのがつらい処理
- 「基本的には成功しているが、このレコードのときだけ失敗した」のように一件一件の成否を見ていくよりも、冪等な処理を一定間隔で一括で回したほうが単純なこともある
移行方法の選択肢
移行前には、サーバのうち一台にcronを設定して定期実行処理を実現していました。移行後の方法としては、次の3つの選択肢が主な選択肢として残りました。
- sidekiq-scheduler
- 指定時間にWorker(ActiveJob)を実行してくれるSidekiqの非公式gem
- 他事業部での採用実績あり
- Sidekiqコンテナのデプロイ時に長時間かかる処理が実行されているとまずいので、あまり長い処理は実行できない
- Sidekiqのキュー処理は「少なくとも1回」なので複数回実行される可能性もある
- EventBrigeのスケジュール機能 + ECS(Fargate)
- 時間をトリガーにECSタスクを起動する
- EventBridgeのイベント通知も「少なくとも1回」なので複数回実行される可能性もある
- 何かしらのcronぽい仕組みをEC2か何かで作る
- 上記の問題が出ないような仕組みを考えて作る
- cronの役割を果たすマシンのメンテナンスはしたくない
採用した方法
最終的にはEventBridge + ECS(Fargate)を使う方法が一番便利だろうということで残りました。
- 多重起動の問題さえ解決できれば一番便利そう
- 定期実行処理の実行中はSidekiqコンテナをデプロイできないor処理を中断しなければならない、は面倒
- 多重起動の問題は他社事例も調べていくと「イベントID」のチェックにより回避できる方法がある
上記のような記事も参考にしつつ、重複実行を判定する処理を実装しました。ちなみに「重複実行がありうるというインフラ側の事情をアプリケーションができるだけ知らなくて良いようにしたい」ということで、実現方法は何回か変遷しています。
- 実行するrakeタスク内に重複実行判定処理の呼び出しを追加する
- 実行するrakeタスクとは別に重複実行判定処理のrakeタスクを実装して、そのrakeタスクへの依存関係を設定する
- 「事前タスク」を初めて自分で実装しました
- 実行するアプリケーションとは別に重複実行判定処理のコンテナを準備して、そのコンテナへの依存関係を設定する
- これによりアプリケーションは重複実行検知の事情を全く知らない形になります
まだ詳細には確認していませんが、先月に入ってから冪等な実行が公式機能でサポートされたようなので、今後はこちらを活用できるといいかもしれません。
事前タスクについての説明も貼っておきます。Railsと組み合わせるときの :environment の正体もようやくわかりました。
あるタスクが事前タスクを持っている場合、そのタスクが呼び出され(実行され)る前に事前タスクを呼び出します。
タスクの定義は
task タスク名 => 事前タスク(の配列)do
アクション
end
のようになります。
ただ、定期実行処理の起動回数がとても多いことから、NATゲートウェイの通信量課金の問題が発覚したのと、数秒で終わる処理のためにわざわざ時間をかけて新しいタスクを起動するのも微妙かもしれないということで、短時間で終わるかつ処理失敗時のリスクが小さいものについては、sidekiq-schedulerも併用して実行することになしました。
NATゲートウェイの課金量の問題は、コンテナのイメージサイズの削減と、「ゲートウェイエンドポイント」の設定により後日ほぼ解消できました。
AWS BatchやStep Functionsなどを組み合わせるのも検討にはあがりましたが、当時の時点では次のような理由により、また必要に応じて随時検討していくことになりました。
(2024/4/11追記)その後、ある時期から特定の時間帯だけFargateのリソース確保に失敗して定期実行が失敗する現象が見られたため、Step Functionsを使って一定回数リトライするよう構成を変更しました。
- ただシンプルにrakeタスクを起動したいだけなので、アプリケーション側の実装を少し工夫して直せる部分はそれで回避してしまいAWS側の構成をできるだけ複雑にしないという方針だった
- リソースの割当に失敗してFargateタスクが立ち上がらないなどの問題も見られなかった
「冪等かつアトミック」な実装への修正対応
重複実行の排除については工夫により対応できた部分もありますが、「そもそも重複実行されても大丈夫なように作ったほうが安心だよね」という観点もあったため、アプリケーションの実装をどんどん修正していくということも行いました。
(関連して、rakeタスクのテストコードがほとんどなかったので、ビジネスロジックをServiceクラスに移動した上でテストコードも追加していく作業も行いました。)
最初は「冪等にする」という言い方をしていたのですが、「同時に処理が走る」という観点も重要だったので、途中から「冪等かつアトミック」という言い方をするようになりました。
考え方としては以下のようなイメージです。
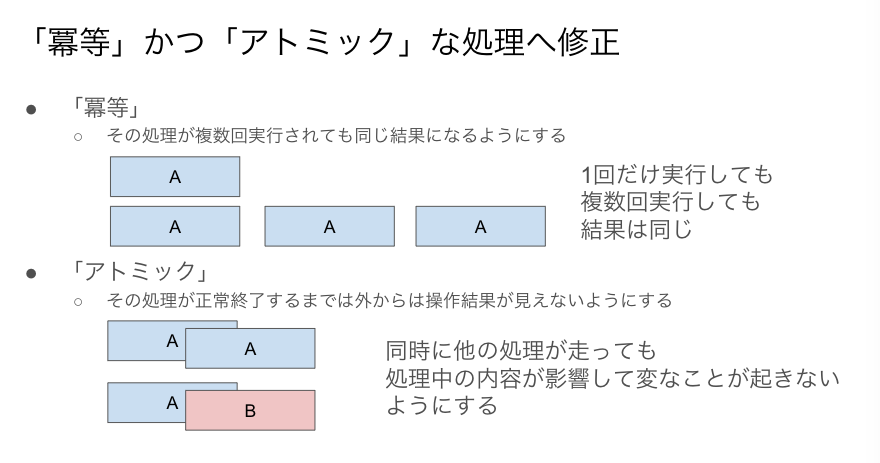
そのために、次のような修正対応を行っていきました。
- 何もしなくても問題ない処理もある
- 特定条件のレコードを一括更新や一括削除するような処理
- 上書きしても問題ないファイルを一括生成していくような処理
- RDBの機能を活用して回避できるものはそうする
- 実行の状態を記録するように変更して、「特定の状態のときだけ実行する」ようにする
- 粒度に気をつけつつロックしてしまう
- 悪影響があっても許容できるものもある
- 社内向けのメールで二重送信されても困らないものなどは修正対象から外したものもあります
その他
他にも振り返って思えば重要だった分岐点はいくつかあったので、簡単にご紹介します。
- デプロイ方法
- 移行前は自前で運用しているJenkinsサーバからデプロイしていましたが、Jenkinsサーバのメンテナンスをせずに済むならその方がいいということで、GitHubActionsを活用してデプロイする形に変更しました
- そこそこ障害があるので、GitHubActionsを使わずにデプロイできるフローも用意しています
- フロントエンドのビルド方法とビルド結果の参照方法
- 次のような条件を満たす方法に至るまで色々と右往左往しました
- Dockerの利点を活かす意味ではimageのビルド方法やリポジトリは各環境共通にしたい
- 同じソースコードからビルド済みの場合は2度目以降はスキップしたい
- Railsからwebpackのビルド結果を参照する必要がある
- フロントエンドのビルド結果は同じソースコードからでも違う結果になることがあり得る
- 次のような条件を満たす方法に至るまで色々と右往左往しました
- 「baseイメージ」を作るかどうか
- gemのインストールなどを高速化したいだけならDockerのレイヤーキャッシュでも実現はできる
- ライブラリのバージョンがビルドのタイミングにより変わると、事前に検証していないライブラリが突然本番環境のイメージに紛れ込む恐れがある
- 「その日にビルドした分は同じbaseイメージからビルドする」のような形を採用することに
- WEBサーバとSidekiqのECSタスクを同居にするか分離するか
- SidekiqのCPU使用率はあまり高くないので、無駄を減らすという観点では同居もなくはない
- 無駄はあるが片方のリソース消費が急増したときにもう片方に影響するおそれもあるので、安全のためには分離したい
- 必要なリソース量を見ていく観点でも分離したほうが計画しやすい
移行後のパフォーマンス問題
無事にコンテナ化を終えたと思いきや、WEBサーバのLatencyが想定以上に悪化していることが後から判明しました。WEBサーバの移行にあたっては、ピークのリクエスト数を踏まえて移行後の環境でその数が捌けることは確認していたのですが、Latencyの変化までは手が回っていませんでした。
以下の画像でわかるように、途中から全体的に倍近く悪化している形です。
ちなみに一瞬上がって下がっている箇所があるのは、すぐに対応できる未知の不具合が一箇所みつかったので切り戻したしたタイミングです。これに関しては切り戻しの手順もstaging環境で確認していたことが功を奏しました。
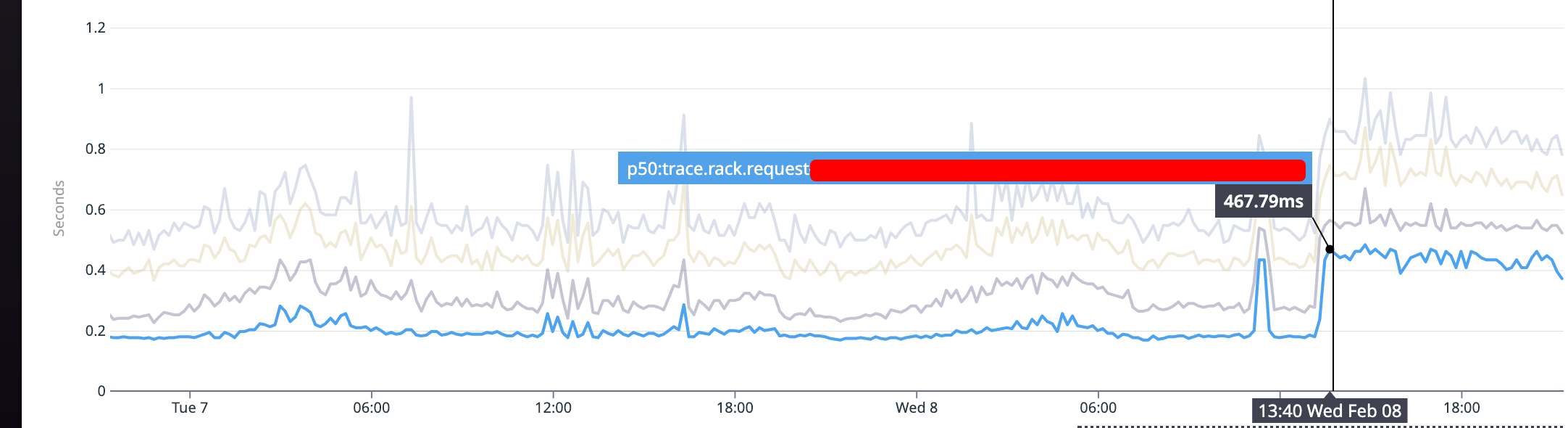
当時の時点ではググるとFargateのほうがCPUやネットワークIOの部分で不利という情報もあったため、一定は仕方のない部分もありつつ、遅いのは困るので無駄なクエリ発行やredis, S3のアクセスを減らしてチューニングを重ねていくことで、移行前と同水準(ページによっては移行前を上回るほど)改善できました。単純なn+1なども案外放置されていることがあるので、何はともあれ見てみることが大事という学びでもありました。
ただ、先日の記事でもご紹介しましたが、最近はFargateの性能問題もかなり改善されてきているようなので、ますます便利なサービスになってきてるなという印象です。
当該サービスでパフォーマンスが重要という話は昨年のアドベントカレンダー記事を参照いただくと雰囲気がつかめるかもしれません。
また、これを機にBOTの大量アクセス(攻撃ではないが、頻度が高過ぎて攻撃と同じくらい厄介なもの)はWAFで弾けたほうが良いよねということで、WAFやアプリケーションでのrate limitの設定を抜本的に見直していくきっかけにもなりました。
おわりに
コンテナ化により、メンテナンス面・セキュリティ面ともに、圧倒的な改善ができたと思います。具体的には、
- マシンを増やすのも減らすのも手軽で簡単
- インスタンスタイプ選定や世代交代の対応なども不要
- これは「CPUガチャ」と裏表ではあるが、コスパ問題も改善されてきている
- ホストOSのアップデートはAWSにお任せできるようになった
- AmazonLinuxのEoL対応みたいなことはもうしなくていい!
- アプリケーションの稼働環境という点では、必要最小限のものだけをコンテナ内に配置する(闇鍋時代とは雲泥の差です)、さらにその必要最小限の中身についてもイメージスキャンやコンテナ向けEDRでチェックしていくことでセキュリティを強化できた
といったところです。特に自分の所属する事業部のサービス・組織の規模からすると、メンテナンスが楽になることのメリットは圧倒的に大きいと思います。
重要なことは、「アプリケーションの開発者がアプリケーションに集中できる環境づくり」だと思っているので、その観点からいっても、EC2インスタンスを自分たちでメンテナンスしていたときよりも大きく改善されていると思います。
この記事に出てきた用語も含めて、ECSとFargateは独特な用語が出てきてそれはそれでとっつきづらい部分はありますが、触ってみればわかることもかなり多いので、敷居が下がった分積極的に多くのエンジニアが触れると良いのかなと思います。
※以下の記事もあわせて読むとよりイメージがつかめるかもしれません(12/18追記)
明日は自分も業務の中で幾度となくお世話になっているスーパー編集長の @akikomuta さんが担当します。お楽しみに!