はじめに
huggingfaceではさまざまなデータセット,モデル,メトリックを扱うことができます.また,Trainerを用いることで学習や評価も簡単に記述することができます.huggingfaceでいろんなタスクを試してみました.
NLP
テキスト分類
- データセット:imdb
- モデル:bert
- メトリック:accuracy
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer, TrainingArguments, Trainer
import evaluate
import numpy as np
import os
# tokenizer の dead lock warning を回避
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# データの読み込み
imdb = load_dataset('imdb')
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", max_length=512, truncation=True)
# トークナイザの読み込み
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
# バッチ単位で高速にトークナイズする
imdb = imdb.map(tokenize_function, batched=True)
# モデルの読み込み
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=2)
# 訓練の設定
# lr schedule: https://dev.classmethod.jp/articles/huggingface-usage-scheluder-type/
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
)
# trainerで識別できるように label から labels に名前を変更
# imdb = imdb.rename_column("label", "labels")
# label または labels で受け取ってくれるようになった
# メトリックの読み込み
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=imdb["train"],
eval_dataset=imdb["test"],
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
# trainer.predict()
なお,Trainerを用いずに記述すると以下のようになります.early stoppingや結果の保存を行う場合はさらに追加の実装が必要となります.一方で,込み入った操作が必要な場合は以下の記述を用いた方がむしろわかりやすい場合もあります.
import torch
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
from transformers import get_scheduler
from torch.optim import AdamW
import evaluate
# データの読み込み
imdb_raw = load_dataset('imdb')
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", max_length=512, truncation=True)
# トークナイザの読み込み
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
# バッチ単位で高速にトークナイズする
imdb = imdb.map(tokenize_function, batched=True, remove_columns=['text'])
# モデルの読み込み
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=2).to('cuda:0')
# データをtorch型に変換
imdb.set_format("torch")
# 指定したカラムだけ変換する場合
# imdb.set_format(type="torch", columns=["input_ids", "token_type_ids", "attention_mask", "labels"])
# 不要なカラムを削除する場合
# imdb = imdb.remove_columns([不要なカラム])
# dataloaderに格納してバッチ単位で取り出せるようにする
train_dataloader = DataLoader(imdb['train'], shuffle=True, batch_size=8)
# collator を用いる場合
# train_dataloader = DataLoader(imdb['train'], shuffle=True, batch_size=8, collate_fn=data_collator)
eval_dataloader = DataLoader(imdb['test'], shuffle=False, batch_size=8)
# オプティマイザの設定
optimizer = AdamW(model.parameters(), lr=5e-5)
# エポック数の設定
num_epochs = 3
# 総イテレーション数の取得
num_training_steps = num_epochs * len(train_dataloader)
# 学習率をどのように変化させていくかの設定
lr_scheduler = get_scheduler(
name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
)
# 二重ループで tqdm を行うための設定
progress_bar = tqdm(range(num_training_steps))
# 学習
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to('cuda:0') for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# 評価
metric = evaluate.load("accuracy")
model.eval()
for batch in tqdm(eval_dataloader):
batch = {k: v.to('cuda:0') for k, v in batch.items()}
with torch.no_grad():
outputs = model(**batch)
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions=predictions, references=batch["labels"])
metric.compute()
zero shot テキスト分類
文ベクトルのコサイン類似度をとったときの予測精度は次のようになります.
Sentence BERT > GloVe > BERT > Doc2Vec
そのため,訓練時に存在しないラベルを予測する zero shot テキスト分類では Sentence BERT を応用すると良いです.
from transformers import AutoTokenizer, AutoModel
from torch.nn import functional as F
tokenizer = AutoTokenizer.from_pretrained('deepset/sentence_bert')
model = AutoModel.from_pretrained('deepset/sentence_bert')
sentence = 'Who are you voting for in 2020?'
labels = ['business', 'art & culture', 'politics']
# run inputs through model and mean-pool over the sequence
# dimension to get sequence-level representations
inputs = tokenizer.batch_encode_plus([sentence] + labels,
return_tensors='pt',
pad_to_max_length=True)
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
output = model(input_ids, attention_mask=attention_mask)[0]
sentence_rep = output[:1].mean(dim=1)
label_reps = output[1:].mean(dim=1)
# now find the labels with the highest cosine similarities to
# the sentence
similarities = F.cosine_similarity(sentence_rep, label_reps)
closest = similarities.argsort(descending=True)
for ind in closest:
print(f'label: {labels[ind]} \t similarity: {similarities[ind]}')
一方で,Sentence BERTは文ベクトルの手法であるため1単語に弱かったりします.
そこで,Gloveと組み合わせることで精度が向上します.[参考]
また,mnliを用いる手法もあります.mnliは前提と仮説の内容上の関係に応じて「含意(entailment)」「矛盾(contradiction)」「どちらとも言えない(neutral)」といったラベルが付けられています.
mnli-BARTが一番精度が高いそうです. (BARTやT5は事前学習を頑張ったtransformer)
# pose sequence as a NLI premise and label as a hypothesis
from transformers import AutoModelForSequenceClassification, AutoTokenizer
sentence = 'Who are you voting for in 2020?'
labels = ['business', 'art & culture', 'politics']
nli_model = AutoModelForSequenceClassification.from_pretrained('facebook/bart-large-mnli')
tokenizer = AutoTokenizer.from_pretrained('facebook/bart-large-mnli')
premise = sentence
hypothesis = f'This example is {labels[2]}.'
# run through model pre-trained on MNLI
x = tokenizer.encode(premise, hypothesis, return_tensors='pt', truncation_strategy='only_first')
logits = nli_model(x)[0]
# we throw away "neutral" (dim 1) and take the probability of
# "entailment" (2) as the probability of the label being true
entail_contradiction_logits = logits[:,[0,2]]
probs = entail_contradiction_logits.softmax(dim=1)
prob_label_is_true = probs[:,1] # 0.9721
翻訳
英仏翻訳を行います.
テキスト分類ではlabelとlabelsのどちらでも損失計算時に読み込んでくれますが,seq2seqのタスクにおいては tokenizer でtext_targetをlabelsに変換して扱うからか,損失計算時にlabelsだけを受け取ります.
from transformers import AutoTokenizer
from datasets import load_dataset
books = load_dataset('opus_books', 'en-fr')
books = books['train'].train_test_split(test_size=0.2)
tokenizer = AutoTokenizer.from_pretrained("t5-small")
source_lang = "en"
target_lang = "fr"
prefix = "translate English to French: "
def preprocess_function(examples):
inputs = [prefix + example[source_lang] for example in examples["translation"]]
targets = [example[target_lang] for example in examples["translation"]]
# text_targetに入力したテキストはtokenized_booksでlabelsとして扱われる
model_inputs = tokenizer(inputs, text_target=targets, max_length=128, truncation=True)
return model_inputs
tokenized_books = books.map(preprocess_function, batched=True)
print(books['train'][0].keys())
print(tokenized_books['train'][0].keys())
print("input_ids ", tokenizer.decode(tokenized_books['train'][0]['input_ids']))
print("labels ", tokenizer.decode(tokenized_books['train'][0]['labels']))
# dict_keys(['id', 'translation'])
# dict_keys(['id', 'translation', 'input_ids', 'attention_mask', 'labels'])
# input_ids translate English to French: What a stroke was this for poor Jane! who would willingly have gone through the world without believing that so much wickedness existed in the whole race of mankind, as was here collected in one individual.</s>
# labels Quel coup pour la pauvre Jane qui aurait parcouru le monde entier sans s’imaginer qu’il existât dans toute l’humanité autant de noirceur qu’elle en découvrait en ce moment dans un seul homme!</s>
モデルの読み込みと学習は次のように行います.
from transformers import AutoModelForSeq2SeqLM, DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer
model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
# バッチ単位で処理するときにバッチの中で最大長のテキストに合わせてpaddingしてくれるので,固定長でデータセット全体をパディングするより計算が早くなる
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model)
training_args = Seq2SeqTrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=1,
fp16=True,
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=tokenized_books["train"],
eval_dataset=tokenized_books["test"],
tokenizer=tokenizer,
data_collator=data_collator,
)
trainer.train()
BERTに2文を入力
2文の等価性判定 (MRPC)タスクを行います.
こちらでMRPCタスクが詳しく説明されています.
まず,データを読み込んで中身を確認してみます.
from datasets import load_dataset
# データの読み込み
dataset = load_dataset("glue", "mrpc")
print(dataset['train'].features)
print(dataset)
# {'sentence1': Value(dtype='string', id=None), 'sentence2': Value(dtype='string', id=None), 'label': ClassLabel(names=['not_equivalent', 'equivalent'], id=None), 'idx': Value(dtype='int32', id=None)}
# DatasetDict({
# train: Dataset({
# features: ['sentence1', 'sentence2', 'label', 'idx'],
# num_rows: 3668
# })
# validation: Dataset({
# features: ['sentence1', 'sentence2', 'label', 'idx'],
# num_rows: 408
# })
# test: Dataset({
# features: ['sentence1', 'sentence2', 'label', 'idx'],
# num_rows: 1725
# })
# })
2文の等価性判定タスクなので,sentence1とsentence2の2文が与えられていることがわかりました.BERTのtokenizerは2文をまとめて1つのinput_idsに変換します.
from transformers import AutoTokenizer
def tokenize_function(examples):
return tokenizer(text=examples["sentence1"], text_pair=examples["sentence2"], padding="max_length", max_length=512, truncation=True)
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
dataset = dataset.map(tokenize_function, batched=True)
print(tokenizer.decode(dataset['train'][0]['input_ids']))
# [SEP]で2文が結合されている
# [CLS] Amrozi accused his brother, whom he called " the witness ", of deliberately distorting his evidence. [SEP]
# Referring to him as only " the witness ", Amrozi accused his brother of deliberately distorting his evidence. [SEP] [PAD] [PAD]
# [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
imdbのときと同様のコードで学習します.
from transformers import AutoModelForSequenceClassification, AutoTokenizer, TrainingArguments, Trainer
import evaluate
import numpy as np
import os
# tokenizer の dead lock warning を回避
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# モデルの読み込み
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=2)
# 訓練の設定
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
)
# メトリックの読み込み
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
トークン分類 (固有表現抽出)
from datasets import load_dataset
from transformers import AutoTokenizer
wnut = load_dataset('wnut_17')
example = wnut['train'][0]
print(example) # {'id': '0', 'tokens': ['@paulwalk', 'It', "'s", 'the', 'view', 'from', 'where', 'I', "'m", 'living', 'for', 'two', 'weeks', '.', 'Empire', 'State', 'Building', '=', 'ESB', '.', 'Pretty', 'bad', 'storm', 'here', 'last', 'evening', '.'], 'ner_tags': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 7, 8, 8, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0]}
label_list = wnut["train"].features[f"ner_tags"].feature.names
print(label_list) # ['O', 'B-corporation', 'I-corporation', 'B-creative-work', 'I-creative-work', 'B-group', 'I-group', 'B-location', 'I-location', 'B-person', 'I-person', 'B-product', 'I-product']
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
# is_split_into_words=Trueで,テキストではなく,単語のリストを入力としてトークン列を返す.defaultはFalse
tokenized_input = tokenizer(example["tokens"], is_split_into_words=True)
tokens = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
print(tokens) # ['[CLS]', '@', 'paul', '##walk', 'it', "'", 's', 'the', 'view', 'from', 'where', 'i', "'", 'm', 'living', 'for', 'two', 'weeks', '.', 'empire', 'state', 'building', '=', 'es', '##b', '.', 'pretty', 'bad', 'storm', 'here', 'last', 'evening', '.', '[SEP]']
wnutデータセットはトークン列で分割されておらず,より大きな単語の単位で分割されています.モデルはトークンで事前学習されているため,単語をサブワードに分割する必要があります.そこで,単語をトークンに分解した最初のトークンをner番号,後に続くトークンは-100と予測するようにすることで対処します.
例: To ##kyo To ##wer -> 7(B-location) -100 8(I-location) -100
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
labels = []
for i, label in enumerate(examples[f"ner_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i) # Map tokens to their respective word.
previous_word_idx = None
label_ids = []
for word_idx in word_ids: # Set the special tokens to -100.
if word_idx is None:
label_ids.append(-100)
elif word_idx != previous_word_idx: # Only label the first token of a given word.
label_ids.append(label[word_idx])
else:
label_ids.append(-100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
tokenized_wnut = wnut.map(tokenize_and_align_labels, batched=True)
TokenClassificationモデルを用いることで,各トークンに対応するラベルを学習させることができます.
from transformers import DataCollatorForTokenClassification, AutoModelForTokenClassification, TrainingArguments, Trainer
# datacollatorを用いる場合は torch型に変換しないように気を付ける
tokenized_wnut.set_format(columns=["input_ids", "attention_mask", "labels"])
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
model = AutoModelForTokenClassification.from_pretrained("distilbert-base-uncased", num_labels=14)
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_wnut["train"],
eval_dataset=tokenized_wnut["test"],
tokenizer=tokenizer,
data_collator=data_collator,
)
trainer.train()
GPTやBERTの事前学習 (Language modeling)
まずはGPTの事前学習を行なってみます.
from datasets import load_dataset
from transformers import AutoTokenizer
eli5_raw = load_dataset('eli5', split='train_asks[:5000]')
eli5 = eli5_raw.train_test_split(test_size=0.2)
print(eli5)
# DatasetDict({
# train: Dataset({
# features: ['q_id', 'title', 'selftext', 'document', 'subreddit', 'answers', 'title_urls', 'selftext_urls', 'answers_urls'],
# num_rows: 4000
# })
# test: Dataset({
# features: ['q_id', 'title', 'selftext', 'document', 'subreddit', 'answers', 'title_urls', 'selftext_urls', 'answers_urls'],
# num_rows: 1000
# })
# })
# このtokenizerはデフォルトで[CLS]や[SEP]がつかない
tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
# Extract the text subfield from its nested structure with the flatten method:
eli5 = eli5.flatten()
def preprocess_function(examples):
return tokenizer([" ".join(x) for x in examples["answers.text"]], truncation=True)
tokenized_eli5 = eli5.map(
preprocess_function,
batched=True,
num_proc=4,
remove_columns=eli5["train"].column_names,
)
print(tokenized_eli5)
# DatasetDict({
# train: Dataset({
# features: ['input_ids', 'attention_mask'],
# num_rows: 4000
# })
# test: Dataset({
# features: ['input_ids', 'attention_mask'],
# num_rows: 1000
# })
# })
block_size = 128
# 長い文を128トークンずつに区切る
def group_texts(examples):
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
total_length = (total_length // block_size) * block_size
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
lm_dataset = tokenized_eli5.map(group_texts, batched=True, num_proc=4)
print(lm_dataset)
# num_rows が増えている
# DatasetDict({
# train: Dataset({
# features: ['input_ids', 'attention_mask', 'labels'],
# num_rows: 8506
# })
# test: Dataset({
# features: ['input_ids', 'attention_mask', 'labels'],
# num_rows: 2106
# })
# })
print(lm_dataset['train'][0])
# {'input_ids': [2437, 857, 262, 2910, 3632, 13054, 286, 257, 8234, 6129, 670, 11, 290, 703, 857, 340, 13238, 422, 326, 286, 257, 1692, 30, 4162, 318, 612, 257, 1517, 884, 355, 10038, 30, 314, 1101, 9648, 284, 1064, 663, 10361, 319, 281, 16673, 5046, 13, 10347, 340, 307, 284, 1254, 517, 6776, 26, 307, 517, 4075, 11, 22919, 517, 30, 357, 31426, 34119, 11, 2440, 28227, 737, 198, 198, 11980, 356, 6515, 884, 9172, 287, 18599, 4695, 30, 1081, 287, 422, 26697, 284, 27842, 13, 2141, 11916, 588, 43699, 290, 347, 49133, 423, 597, 16673, 11135, 422, 262, 1613, 326, 714, 4727, 428, 4069, 30, 2080, 262, 46275, 278, 1245, 286, 3660, 9007, 11, 703, 481, 428, 1245, 1204, 29098, 3965, 290, 635, 3265, 30, 3633, 314, 460, 470], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'labels': [2437, 857, 262, 2910, 3632, 13054, 286, 257, 8234, 6129, 670, 11, 290, 703, 857, 340, 13238, 422, 326, 286, 257, 1692, 30, 4162, 318, 612, 257, 1517, 884, 355, 10038, 30, 314, 1101, 9648, 284, 1064, 663, 10361, 319, 281, 16673, 5046, 13, 10347, 340, 307, 284, 1254, 517, 6776, 26, 307, 517, 4075, 11, 22919, 517, 30, 357, 31426, 34119, 11, 2440, 28227, 737, 198, 198, 11980, 356, 6515, 884, 9172, 287, 18599, 4695, 30, 1081, 287, 422, 26697, 284, 27842, 13, 2141, 11916, 588, 43699, 290, 347, 49133, 423, 597, 16673, 11135, 422, 262, 1613, 326, 714, 4727, 428, 4069, 30, 2080, 262, 46275, 278, 1245, 286, 3660, 9007, 11, 703, 481, 428, 1245, 1204, 29098, 3965, 290, 635, 3265, 30, 3633, 314, 460, 470]}
# Tips
# jupyterは 0 を2回押すとRestart, i を2回押すと KeyboardInterrupt
input_idsとlabelsが同じものになっていますが,モデルで学習するときは input_ids[0:i-1] から labels[i] を自己回帰的に学習します.
from transformers import DataCollatorForLanguageModeling
from transformers import AutoModelForCausalLM, TrainingArguments, Trainer
tokenizer.pad_token = tokenizer.eos_token
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
weight_decay=0.01,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_dataset["train"],
eval_dataset=lm_dataset["test"],
data_collator=data_collator,
)
trainer.train()
BERTの事前学習は,上記コードのtokenizerとmodelをdistilgpt2をdistilroberta-baseに変更し,datacollatorをdata_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)と変更するだけでOKです.
テキスト要約
まず,データを読み込みます.テキスト要約はtextからsummaryを生成するタスクです.
from datasets import load_dataset
billsum = load_dataset('billsum', split='ca_test')
billsum = billsum.train_test_split(test_size=0.2)
print(billsum['train'][0])
# {'text': 'The people of the State of California do enact as follows ~略',
# 'summary': 'Existing law, the Swimming Pool Safety Act, ~略',
# 'title': 'An act to amend Section 7195 of the Business and Professions Code, and to amend Sections 115922 and 115925 of the Health and Safety Code, relating to public health.'}
T5を読み込んでseq2seqを行います.T5は事前学習済みseq2seq transformersモデルで,prefixを設定してさまざまなfinetuningを行えるため,汎用性が高いです.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('t5-small')
prefix = 'summarize: '
def preprocess_function(examples):
inputs = [prefix + doc for doc in examples["text"]]
model_inputs = tokenizer(inputs, max_length=1024, truncation=True)
labels = tokenizer(text_target=examples["summary"], max_length=128, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
tokenized_billsum = billsum.map(preprocess_function, batched=True)
print(tokenized_billsum)
# このうち使われる(モデルが認識して読み込む)featuresは input_ids, attention_mask, labelsであり,
# labelsは summaryのトークンID列である
# DatasetDict({
# train: Dataset({
# features: ['text', 'summary', 'title', 'input_ids', 'attention_mask', 'labels'],
# num_rows: 989
# })
# test: Dataset({
# features: ['text', 'summary', 'title', 'input_ids', 'attention_mask', 'labels'],
# num_rows: 248
# })
# })
from transformers import DataCollatorForSeq2Seq, AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
# tokenizeはエポックごとに行うよりもpreprocessで1回だけ行うべきだが,
# datacollatorはエポックごとにshuffleされた状態で行うべきなのでこのような実装になっている.
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=model)
training_args = Seq2SeqTrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=1,
fp16=True,
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=tokenized_billsum["train"],
eval_dataset=tokenized_billsum["test"],
tokenizer=tokenizer,
data_collator=data_collator,
)
trainer.train()
文選択 (Multiple choice)
広くはcontextにあう文を複数文の中から選択するタスクです.次に紹介するswagは,1文とそれに続く1文の名詞句が与えられ,複数の動詞句の中から正しいものを選択するタスクです.
例:
context
Members of the procession walk down the street holding small horn brass instruments.
A drum line [ここに入る文を選択する]
選択肢
- passes by walking down the street playing their instruments.
- has heard approaching them.
- arrives and they're outside dancing and asleep.
- turns the lead singer watches the performance.
答え
1番
実際にswagの学習まで行うために,まずはデータセットを読み込みます.
from datasets import load_dataset
swag = load_dataset("swag", "regular")
swag['train'][0]
# {'video-id': 'anetv_jkn6uvmqwh4',
# 'fold-ind': '3416',
# 'startphrase': 'Members of the procession walk down the street holding small horn brass instruments. A drum line',
# 'sent1': 'Members of the procession walk down the street holding small horn brass instruments.',
# 'sent2': 'A drum line',
# 'gold-source': 'gold',
# 'ending0': 'passes by walking down the street playing their instruments.',
# 'ending1': 'has heard approaching them.',
# 'ending2': "arrives and they're outside dancing and asleep.",
# 'ending3': 'turns the lead singer watches the performance.',
# 'label': 0}
次にtokenizeを行います.与えられたデータからBERTに入力する形に変換します.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
ending_names = ["ending0", "ending1", "ending2", "ending3"]
def preprocess_function(examples):
first_sentences = [[context] * 4 for context in examples["sent1"]]
question_headers = examples["sent2"]
second_sentences = [
[f"{header} {examples[end][i]}" for end in ending_names] for i, header in enumerate(question_headers)
]
first_sentences = sum(first_sentences, [])
second_sentences = sum(second_sentences, [])
tokenized_examples = tokenizer(first_sentences, second_sentences, truncation=True)
return {k: [v[i : i + 4] for i in range(0, len(v), 4)] for k, v in tokenized_examples.items()}
tokenized_swag = swag.map(preprocess_function, batched=True)
どういう処理をしているかpreprocess_functionの中を確認したり,新たに実装するためにはjupyter notebook上で適当なバッチを取り出して試すと楽です.
# 8つのデータが含まれるバッチを作成.preprocess_functionで入力するexamplesと同様.
# このように取得するとDataset型からdict型になる
# 厳密にはmap関数ではdatasets.arrow_dataset.Batch型でexamplesが取り出される
examples = swag['train'][:8]
first_sentences = [[context] * 4 for context in examples["sent1"]]
question_headers = examples["sent2"]
second_sentences = [
[f"{header} {examples[end][i]}" for end in ending_names] for i, header in enumerate(question_headers)
]
first_sentences = sum(first_sentences, [])
second_sentences = sum(second_sentences, [])
print(first_sentences)
# ['Members of the procession walk down the street holding small horn brass instruments.',
# 'Members of the procession walk down the street holding small horn brass instruments.',
# 'Members of the procession walk down the street holding small horn brass instruments.',
# 'Members of the procession walk down the street holding small horn brass instruments.',
# 'A drum line passes by walking down the street playing their instruments.',
# 'A drum line passes by walking down the street playing their instruments.',
# 'A drum line passes by walking down the street playing their instruments.',
# 'A drum line passes by walking down the street playing their instruments.',
# 'A group of members in green uniforms walks waving flags.',
# 'A group of members in green uniforms walks waving flags.',
# 'A group of members in green uniforms walks waving flags.',
# 'A group of members in green uniforms walks waving flags.',
# 'A drum line passes by walking down the street playing their instruments.',
# 'A drum line passes by walking down the street playing their instruments.',
# 'A drum line passes by walking down the street playing their instruments.',
# 'A drum line passes by walking down the street playing their instruments.',
# 'The person plays a song on the violin.',
# 'The person plays a song on the violin.',
# 'The person plays a song on the violin.',
# 'The person plays a song on the violin.',
# 'The person holds up the violin to his chin and gets ready.',
# 'The person holds up the violin to his chin and gets ready.',
# 'The person holds up the violin to his chin and gets ready.',
# 'The person holds up the violin to his chin and gets ready.',
# 'A person retrieves an instrument from a closet.',
# 'A person retrieves an instrument from a closet.',
# 'A person retrieves an instrument from a closet.',
# 'A person retrieves an instrument from a closet.',
# 'The man examines the instrument in his hand.',
# 'The man examines the instrument in his hand.',
# 'The man examines the instrument in his hand.',
# 'The man examines the instrument in his hand.']
print(second_sentences)
# ['A drum line passes by walking down the street playing their instruments.',
# 'A drum line has heard approaching them.',
# "A drum line arrives and they're outside dancing and asleep.",
# 'A drum line turns the lead singer watches the performance.',
# 'Members of the procession are playing ping pong and celebrating one left each in quick.',
# 'Members of the procession wait slowly towards the cadets.',
# 'Members of the procession continues to play as well along the crowd along with the band being interviewed.',
# 'Members of the procession continue to play marching, interspersed.',
# 'Members of the procession pay the other coaches to cheer as people this chatter dips in lawn sheets.',
# 'Members of the procession walk down the street holding small horn brass instruments.',
# 'Members of the procession is seen in the background.',
# 'Members of the procession are talking a couple of people playing a game of tug of war.',
# 'Members of the procession are playing ping pong and celebrating one left each in quick.',
# 'Members of the procession wait slowly towards the cadets.',
# 'Members of the procession makes a square call and ends by jumping down into snowy streets where fans begin to take their positions.',
# 'Members of the procession play and go back and forth hitting the drums while the audience claps for them.',
# 'The man finishes the song and lowers the instrument.',
# 'The man hits the saxophone and demonstrates how to properly use the racquet.',
# 'The man finishes massage the instrument again and continues.',
# 'The man continues dancing while the man gore the music outside while drums.',
# 'The person finishes playing then marches their tenderly.',
# 'The person walks in frame and rubs on his hands, and then walks into a room.',
# 'The person continues playing guitar while moving from the camera.',
# 'The person plays a song on the violin.',
# 'The man examines the instrument in his hand.',
# 'The man stops playing the drums and waves over the other boys.',
# 'The man lights the cigarette and sticks his head in.',
# 'The man drags off the vacuum.',
# 'The person studies a picture of the man playing the violin.',
# 'The person holds up the violin to his chin and gets ready.',
# 'The person stops to speak to the camera again.',
# 'The person puts his arm around the man and backs away.']
tokenized_examples = tokenizer(first_sentences, second_sentences, truncation=True)
print({k: [v[i : i + 4] for i in range(0, len(v), 4)] for k, v in tokenized_examples.items()}['input_ids'][0])
# [[101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102], [101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 2038, 2657, 8455, 2068, 1012, 102], [101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 8480, 1998, 2027, 1005, 2128, 2648, 5613, 1998, 6680, 1012, 102], [101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 4332, 1996, 2599, 3220, 12197, 1996, 2836, 1012, 102]]
# Tips
# print(first_sentences) ではリストがコンマ+スペースで表示
# jupyter で first_sentences とするとリストがコンマ+改行で表示
選択問題のcollatorは少し工夫が必要です.
from dataclasses import dataclass
from transformers.tokenization_utils_base import PreTrainedTokenizerBase, PaddingStrategy
from typing import Optional, Union
import torch
@dataclass
class DataCollatorForMultipleChoice:
"""
Data collator that will dynamically pad the inputs for multiple choice received.
"""
tokenizer: PreTrainedTokenizerBase
padding: Union[bool, str, PaddingStrategy] = True
max_length: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
def __call__(self, features):
label_name = "label" if "label" in features[0].keys() else "labels"
labels = [feature.pop(label_name) for feature in features]
batch_size = len(features)
num_choices = len(features[0]["input_ids"])
flattened_features = [
[{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
]
flattened_features = sum(flattened_features, [])
batch = self.tokenizer.pad(
flattened_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt",
)
batch = {k: v.view(batch_size, num_choices, -1) for k, v in batch.items()}
batch["labels"] = torch.tensor(labels, dtype=torch.int64)
return batch
collatorの挙動も確認してみます.
preprocess_functionのときとは異なり,collatorで読み込まれるfeaturesはlist(tokenized_swag['train'].select(range(8)))のようにバッチに対してlistがつくことに注意が必要です.以下の3種類が異なるものとして別の場面で用いられます.
# datasets.dataset_dict.DatasetDict型のまま扱う場合はこちら. 単にいくつかサンプルを取り出すときなどに用いる.
print(tokenized_swag['train'].select(range(4)))
# Dataset({
# features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
# num_rows: 4
# })
# dict型に変換される. preprocess_functionではこのように扱う.
print(tokenized_swag['train'][:4]) # == tokenized_swag['train'].select(range(4)).to_dict()
# {'label': [0, 3, 1, 3], 'input_ids': [[[101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102], [101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 2038, 2657, 8455, 2068, 1012, 102], [101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 8480, 1998, 2027, 1005, 2128, 2648, 5613, 1998, 6680, 1012, 102], [101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 4332, 1996, 2599, 3220, 12197, 1996, 2836, 1012, 102]], [[101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 2024, 2652, 17852, 13433, 3070, 1998, 12964, 2028, 2187, 2169, 1999, 4248, 1012, 102], [101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 3524, 3254, 2875, 1996, 15724, 1012, 102], [101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 4247, 2000, 2377, 2004, 2092, 2247, 1996, 4306, 2247, 2007, 1996, 2316, 2108, 10263, 1012, 102], [101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 3613, 2000, 2377, 10998, 1010, 25338, 1012, 102]], [[101, 1037, 2177, 1997, 2372, 1999, 2665, 11408, 7365, 12015, 9245, 1012, 102, 2372, 1997, 1996, 14385, 3477, 1996, 2060, 7850, 2000, 15138, 2004, 2111, 2023, 24691, 16510, 2015, 1999, 10168, 8697, 1012, 102], [101, 1037, 2177, 1997, 2372, 1999, 2665, 11408, 7365, 12015, 9245, 1012, 102, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102], [101, 1037, 2177, 1997, 2372, 1999, 2665, 11408, 7365, 12015, 9245, 1012, 102, 2372, 1997, 1996, 14385, 2003, 2464, 1999, 1996, 4281, 1012, 102], [101, 1037, 2177, 1997, 2372, 1999, 2665, 11408, 7365, 12015, 9245, 1012, 102, 2372, 1997, 1996, 14385, 2024, 3331, 1037, 3232, 1997, 2111, 2652, 1037, 2208, 1997, 12888, 1997, 2162, 1012, 102]], [[101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 2024, 2652, 17852, 13433, 3070, 1998, 12964, 2028, 2187, 2169, 1999, 4248, 1012, 102], [101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 3524, 3254, 2875, 1996, 15724, 1012, 102], [101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 3084, 1037, 2675, 2655, 1998, 4515, 2011, 8660, 2091, 2046, 20981, 4534, 2073, 4599, 4088, 2000, 2202, 2037, 4460, 1012, 102], [101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 2377, 1998, 2175, 2067, 1998, 5743, 7294, 1996, 3846, 2096, 1996, 4378, 28618, 2015, 2005, 2068, 1012, 102]]], 'token_type_ids': [[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]], 'attention_mask': [[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]]}
# list型に変換される. Trainer や torch.utils.data.generator において collator を使用する場合, バッチは list として扱われるため, datasets.dataset_dict.DatasetDict型のままだとエラーが生じる場合がある.
print(list(tokenized_swag['train'].select(range(4))))
# [{'label': 0, 'input_ids': [[101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102], [101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 2038, 2657, 8455, 2068, 1012, 102], [101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 8480, 1998, 2027, 1005, 2128, 2648, 5613, 1998, 6680, 1012, 102], [101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 4332, 1996, 2599, 3220, 12197, 1996, 2836, 1012, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}, {'label': 3, 'input_ids': [[101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 2024, 2652, 17852, 13433, 3070, 1998, 12964, 2028, 2187, 2169, 1999, 4248, 1012, 102], [101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 3524, 3254, 2875, 1996, 15724, 1012, 102], [101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 4247, 2000, 2377, 2004, 2092, 2247, 1996, 4306, 2247, 2007, 1996, 2316, 2108, 10263, 1012, 102], [101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 3613, 2000, 2377, 10998, 1010, 25338, 1012, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}, {'label': 1, 'input_ids': [[101, 1037, 2177, 1997, 2372, 1999, 2665, 11408, 7365, 12015, 9245, 1012, 102, 2372, 1997, 1996, 14385, 3477, 1996, 2060, 7850, 2000, 15138, 2004, 2111, 2023, 24691, 16510, 2015, 1999, 10168, 8697, 1012, 102], [101, 1037, 2177, 1997, 2372, 1999, 2665, 11408, 7365, 12015, 9245, 1012, 102, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102], [101, 1037, 2177, 1997, 2372, 1999, 2665, 11408, 7365, 12015, 9245, 1012, 102, 2372, 1997, 1996, 14385, 2003, 2464, 1999, 1996, 4281, 1012, 102], [101, 1037, 2177, 1997, 2372, 1999, 2665, 11408, 7365, 12015, 9245, 1012, 102, 2372, 1997, 1996, 14385, 2024, 3331, 1037, 3232, 1997, 2111, 2652, 1037, 2208, 1997, 12888, 1997, 2162, 1012, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}, {'label': 3, 'input_ids': [[101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 2024, 2652, 17852, 13433, 3070, 1998, 12964, 2028, 2187, 2169, 1999, 4248, 1012, 102], [101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 3524, 3254, 2875, 1996, 15724, 1012, 102], [101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 3084, 1037, 2675, 2655, 1998, 4515, 2011, 8660, 2091, 2046, 20981, 4534, 2073, 4599, 4088, 2000, 2202, 2037, 4460, 1012, 102], [101, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102, 2372, 1997, 1996, 14385, 2377, 1998, 2175, 2067, 1998, 5743, 7294, 1996, 3846, 2096, 1996, 4378, 28618, 2015, 2005, 2068, 1012, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}]
collatorの主要部分の出力は次のようになります.
features = list(tokenized_swag['train'].select(range(8)))
print(features[0]) # {'label': 0, 'input_ids': [[101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102], [101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 2038, 2657, 8455, 2068, 1012, 102], [101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 8480, 1998, 2027, 1005, 2128, 2648, 5613, 1998, 6680, 1012, 102], [101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 4332, 1996, 2599, 3220, 12197, 1996, 2836, 1012, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
label_name = "label" if "label" in features[0].keys() else "labels"
labels = [feature.pop(label_name) for feature in features]
batch_size = len(features)
num_choices = len(features[0]["input_ids"])
flattened_features = [
[{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
]
flattened_features = sum(flattened_features, [])
print(len(flattened_features)) # 32 (バッチサイズが4倍になる)
print(flattened_features[0]) # {'input_ids': [101, 2372, 1997, 1996, 14385, 3328, 2091, 1996, 2395, 3173, 2235, 7109, 8782, 5693, 1012, 102, 1037, 6943, 2240, 5235, 2011, 3788, 2091, 1996, 2395, 2652, 2037, 5693, 1012, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
学習のコードは他のタスクと同様です.
from transformers import AutoModelForMultipleChoice, TrainingArguments, Trainer
model = AutoModelForMultipleChoice.from_pretrained("bert-base-uncased")
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=5e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_swag["train"],
eval_dataset=tokenized_swag["validation"],
tokenizer=tokenizer,
data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer),
)
trainer.train()
質問応答 (QA)
- データセット:squad
- モデル:distilbert
- メトリック:exact_match, f1
与えられたcontextとquestionについて,questionの答えとなる部分をcontextから抜き出すタスクです.以下画像のようにcontextの中のstart, endの各トークンの位置を予測します.[参照]

from transformers import AutoTokenizer, AutoModelForQuestionAnswering, TrainingArguments, Trainer, DefaultDataCollator
from datasets import load_dataset
from tqdm.auto import tqdm
import evaluate
def preprocess_function(examples):
questions = [q.strip() for q in examples["question"]]
inputs = tokenizer(
questions,
examples["context"],
max_length=384,
truncation="only_second",
return_offsets_mapping=True,
padding="max_length",
)
offset_mapping = inputs.pop("offset_mapping")
answers = examples["answers"]
start_positions = []
end_positions = []
for i, offset in enumerate(offset_mapping):
answer = answers[i]
start_char = answer["answer_start"][0]
end_char = answer["answer_start"][0] + len(answer["text"][0])
sequence_ids = inputs.sequence_ids(i)
# Find the start and end of the context
idx = 0
while sequence_ids[idx] != 1:
idx += 1
context_start = idx
while sequence_ids[idx] == 1:
idx += 1
context_end = idx - 1
# If the answer is not fully inside the context, label it (0, 0)
if offset[context_start][0] > end_char or offset[context_end][1] < start_char:
start_positions.append(0)
end_positions.append(0)
else:
# Otherwise it's the start and end token positions
idx = context_start
while idx <= context_end and offset[idx][0] <= start_char:
idx += 1
start_positions.append(idx - 1)
idx = context_end
while idx >= context_start and offset[idx][1] >= end_char:
idx -= 1
end_positions.append(idx + 1)
inputs["start_positions"] = start_positions
inputs["end_positions"] = end_positions
return inputs
squad = load_dataset('squad')
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
tokenized_squad = squad.map(preprocess_function, batched=True, remove_columns=squad["train"].column_names)
model = AutoModelForQuestionAnswering.from_pretrained("distilbert-base-uncased")
data_collator = DefaultDataCollator()
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
)
squad_metric = evaluate.load("squad")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_squad["train"],
eval_dataset=tokenized_squad["validation"],
tokenizer=tokenizer,
data_collator=data_collator,
)
trainer.train()
また,pipelineを用いることで,postprocessも含めた出力をシンプルな記述で得ることができます.
from transformers import pipeline
nlp = pipeline('question-answering', model=model, tokenizer=tokenizer, device='cuda:0')
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# res の出力
# {'score': 0.21171393990516663,
# 'start': 59,
# 'end': 84,
# 'answer': 'gives freedom to the user'}
exact_match, f1 で質問応答の精度を評価します.
# 評価の一例
from evaluate import load
squad_metric = load("squad")
predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22'}]
references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}]
results = squad_metric.compute(predictions=predictions, references=references)
# {'exact_match': 100.0, 'f1': 100.0}
CV (mmlab含む)
Computer Vision分野のディープラーニングにおいては, huggingfaceの他にも,さまざまなタスクやモデルをまとめたライブラリとしてmmlabが使われることが多いため,それも含めて調べました.
CLIP
CLIPは,2021年1月にOpenAIが公開した,画像と画像を説明するテキストのペア4億組を学習させたモデルです.[論文]
rinna社が日本語対応のモデルを公開しています.[1][2]
モデルへの入力と出力例は次のようになります.
入力:

playing music
playing sports
出力:
playing musicのスコア:0.998
playing sportsのスコア:0.002
学習の仕組みとしては,画像とテキストをそれぞれベクトル化し,正しいペアの内積を大きく,それ以外を小さくするように学習します.
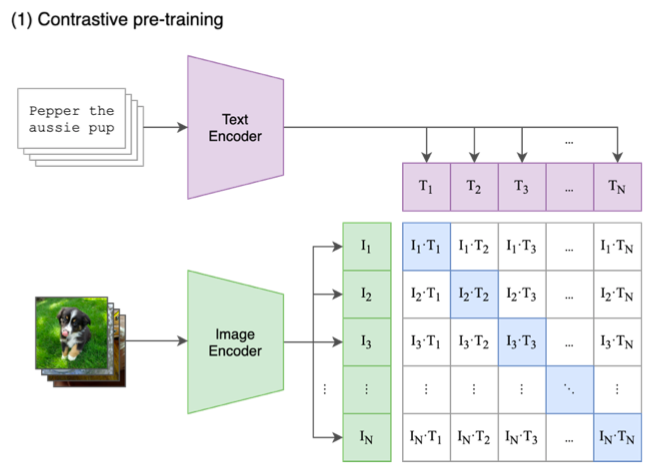
CLIPは画像検索に応用できます.あらかじめたくさんの画像をベクトルに変換しておき,クエリとなるテキストが入力されたら,それぞれの内積をとって内積が最大となる画像から順に選んでいけば良いです.
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
# stream=Trueだと、イテレータで結果を取得できるようになるので、レスポンスをすべて取得し終わる前から読み取りを開始できる
image = Image.open(requests.get(url, stream=True).raw)
display(image)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
print(inputs.keys()) # dict_keys(['input_ids', 'attention_mask', 'pixel_values'])
print(inputs['input_ids'].shape) # torch.Size([2, 7])
print(inputs['pixel_values'].shape) # torch.Size([1, 3, 224, 224])
outputs = model(**inputs)
print(outputs.keys()) # odict_keys(['logits_per_image', 'logits_per_text', 'text_embeds', 'image_embeds', 'text_model_output', 'vision_model_output'])
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
print(logits_per_image) # tensor([[18.9041, 11.7159]], grad_fn=<TBackward0>)
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
print(probs) # tensor([[9.9925e-01, 7.5487e-04]], grad_fn=<SoftmaxBackward0>)

正しく "a photo of a cat" の方を99%で予測できています.
MOT (Multiplt Object Tracking)
複数の物体を検知してトラッキングするタスクです.ここでは人の追跡をおこなってみます.mmtrackingをインストールするためにダウンロードしてきたリポジトリの中に mmtracking/demo/MMTracking_Tutorial.ipynbがあるので,それに沿って行うと推論から学習まで簡単に行えます.
# 1. mmtrackingのインストール
# https://github.com/open-mmlab/mmtracking/blob/master/docs/en/install.md
# 2. 事前にyoutube動画をダウンロード (個人の責任で行ってください)
# !pip install pytube
# pytube <URL>
import mmcv
from mmtrack.apis import inference_mot, init_model
input_video = 'scramble.mp4'
output = input_video.split('.')[0] + '_tracking.' + input_video.split('.')[1]
out_imgs_path = "output_imgs"
mot_config = './configs/mot/deepsort/deepsort_faster-rcnn_fpn_4e_mot17-private-half.py'
imgs = mmcv.VideoReader(input_video)
fps = imgs.fps
print(fps, 'fps')
print(len(imgs))
# 動画の位置からimgsの範囲を決める
# imgs = imgs[100: 200]
# print(len(imgs))
# build the model from a config file
mot_model = init_model(mot_config, device='cuda:0')
prog_bar = mmcv.ProgressBar(len(imgs))
# test and show/save the images
for i, img in enumerate(imgs):
# 推論
result = inference_mot(mot_model, img, frame_id=i)
# 画像保存
mot_model.show_result(
img,
result,
show=False,
wait_time=int(1000. / fps),
out_file=f'{out_imgs_path}/{i:06d}.jpg')
prog_bar.update()
# 動画に結合
print(f'\n making the output video at {output} with a FPS of {fps}')
mmcv.frames2video(out_imgs_path, output, fps=fps)
gifに出力して結果を確認してみます.
from PIL import Image
import glob
# imgs を out.gifに出力
imgs = [Image.open(path) for path in sorted(glob.glob('output_imgs/*'))]
imgs[0].save('out.gif', save_all=True, append_images=imgs[1:], duration=100, loop=0)

Audio
Transcribe (音声書き起こし)
あまり詳しくありませんが,Audio系のDeepLearningモデルも試してみます.
まず,common_voiceという音声とテキストのペアが含まれるデータセットを取得します.
音声や画像のデータセットはデータ容量が大きいため,データ分析や本学習を除いては,データの一部分だけダウンロードしてくるのが望ましいと思います.split引数を用いてデータの一部分だけを簡単にダウンロードできます.
from datasets import load_dataset, load_metric, Audio
# split='train[:10%]' : 学習分割の最初の10%のみをロード。
# split='train[:100]+validation[:100]' : 学習分割の最初の100例と検証分割の最初の100例から分割を作成。
# https://huggingface.co/docs/datasets/loading#slice-splits
common_voice = load_dataset("common_voice", "tr", split="train[:10]")
音声データを再生してみます.
データはホームディレクトリ下の.cache/huggingface/datasets/common_voice/tr/...に保存されており,以下のコードでパスを取得できます.
import IPython.display
mp3_path = common_voice[0]['path']
IPython.display.Audio(mp3_path)

transcript (音声文字起こし) を試してみます.openaiが出した,680k時間を超えるデータで学習したtransformersベースのモデルであるwhisperを使います.多言語対応であり,日本語も含まれます.
デモはこちらです.
from transformers import WhisperProcessor, WhisperForConditionalGeneration
import torch
# load model and processor
processor = WhisperProcessor.from_pretrained("openai/whisper-large")
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-large")
# サンプリングレートを16kにする
ds = common_voice.cast_column("audio", Audio(sampling_rate=16_000))
input_speech = ds[0]["audio"]["array"]
# transcribe から translateに変えると英語に翻訳する.
# 生成に5秒ほどかかるものの, audio -> en-text のように fr-text を介さずに翻訳できる.
model.config.forced_decoder_ids = processor.get_decoder_prompt_ids(language = "fr", task = "transcribe")
input_features = processor(input_speech, return_tensors="pt").input_features
# モデルの予測
predicted_ids = model.generate(input_features)
# 生成
transcription1 = processor.batch_decode(predicted_ids)
transcription2 = processor.batch_decode(predicted_ids, skip_special_tokens = True)
print(transcription1)
print(transcription2)
# ['<|startoftranscript|><|fr|><|transcribe|><|notimestamps|> Leur maquillage de la hirvathie veut la différence.<|endoftext|>']
# [' Leur maquillage de la hirvathie veut la différence.']
macのボイスメモからは次のように読み込みます。
# !pip install -q git+https://github.com/openai/whisper.git
import whisper
model = whisper.load_model("large")
result = model.transcribe("test.m4a", language='en') # task='translate'
print(result["text"])
論文の図を眺めてみましたが,Tokens in Multitask Training Format部分を頑張ってそうです.


Datasets
GLUE Benchmark
NLPの学習,評価,分析のためのデータセットを集めたものです.[参考]
dataset = load_dataset('glue', 'cola')のように読み込みます.
どんな感じで学習評価するかはこちらのcolabにまとまっています.
タスクの説明
・CoLA : 文が英語文法として正しいかどうかを判定。ラベル数2
・SST-2 : 映画レビューの感情解析(ポジティブ、ネガティブ)を判定。ラベル数2
・MRPC : 2つの文が同じ意味かどうかを判定。ラベル数2
・STS-B : ニュースの見出し文の類似度を5段階で評価。回帰
・QQP : 2つの質問が同じ意味かどうかを判定。ラベル数2
・MNLI-m / MNLI-mm : 2つの文の含意関係(含意、矛盾、中立)を判定。ラベル数3
・SQuAD : コンテキストから質問の回答を抽出。
・QNLI : 質問と文は、正しい回答を含んでいるかどうかを判定。ラベル数2
・RTE : 2つの文の含意関係(含意、含意でない)を判定。ラベル数2
・WNLI : 代名詞が置換された文が元の文に含まれているかどうかを判定。ラベル数2
メトリックとLeaderboard総合1位の各点数
for CoLA: Matthews Correlation Coefficient (73.8)
for SST-2: Accuracy (97.9)
for MRPC: Accuracy and F1 score (94.5/92.6)
for STS-B: Pearson Correlation Coefficient and Spearman's_Rank_Correlation_Coefficient (93.5/93.1)
for QQP: Accuracy and F1 score (76.7/91.1)
for MNLI (matched or mismatched): Accuracy (92.1)
for QNLI: Accuracy (96.7)
for RTE: Accuracy (92.4)
for WNLI: Accuracy (97.9)
SuperGLUE Benchmark
SuperGLUEには8つのサブタスクが含まれている。
BoolQ (Boolean Questions) — 質問応答タスク。短い質問に対して、"はい"または"いいえ"で回答する。
CB (CommitmentBank) — 埋め込まれた句から仮説を抽出する形式のテキスト含意タスク。
COPA (Choice of Plausible Alternatives) — 因果推論タスク。前提と、2つの考えられる原因ないし結果の回答が与えられる。
MultiRC (Multi-Sentence Reading Comprehension) — 質問応答タスク。ひとつのコンテキストの文章に関する質問に答えることが求められる。
ReCoRD (Reading Comprehension with Commonsense Reasoning Dataset) — 質問応答タスク。新たな記事と、それに関する質問が穴埋め形式(Cloze-style)で与えられる。マスクされた部分の適切な置き換えをリストから選択しなければならない。
RTE (Recognizing Textual Entailment) — テキスト含意タスク。ひとつのテキストがもうひとつのテキストと相反しているかどうかを判断する。
WiC (Word-in-Context) — 語義曖昧性解消タスク。2つのパッセージの中で、ひとつの単語が同じ意味で使用されているかどうかを判断する。
WSC (Winograd Schema Challenge) — 共参照解決タスク。代名詞の先行詞を決定する必要がある。
[参考]
例えば因果推論タスクのCOPAはこのようなデータです.
dataset = load_dataset('super_glue', 'copa')
dataset['train'][0]
# {'premise': 'My body cast a shadow over the grass.',
# 'choice1': 'The sun was rising.',
# 'choice2': 'The grass was cut.',
# 'question': 'cause',
# 'idx': 0,
# 'label': 0}
dataset['train'].features
# {'premise': Value(dtype='string', id=None),
# 'choice1': Value(dtype='string', id=None),
# 'choice2': Value(dtype='string', id=None),
# 'question': Value(dtype='string', id=None),
# 'idx': Value(dtype='int32', id=None),
# 'label': ClassLabel(names=['choice1', 'choice2'], id=None)}
[premise] My body cast a shadow over the grass
because
[choice1] The sun was rising
という因果関係となるため,答えはchoice1です.
Models
以下の画像はNLPにおけるモデルの推移です.Self-attention構造を持つTransformerが出て以降はほぼ全てのモデルがTransformerをベースとするようになりました.また,CV分野のVision TransformerやAudio分野のWhisperなど,他の分野にもTransformerが広がっています.
[参考]
個人的にはタスクにもよりますが,モデルの予測性能は飽和してきている気がする (パラメータの増加に対して精度の向上が少ない) ので,GPTや翻訳モデルの力を借りつつ,効率よく新しいデータセットを作る手法が大切になってくる気がします,というか実際にそうなってきています.
GoogleのチャットbotであるLaMDAはボットと人間の会話等から新しいデータセットを作って,GPTが苦手とする,事実に即した応答や面白みのある応答を実現しています.
Evaluate
huggingfaceではこれまでdatasetsというライブラリにメトリックも含まれていましたが,現在はevaluateというライブラリに移行しつつあります.
ModelsやDatasetsと同様に,Spacesでメトリックを検索できます.
import evaluate
accuracy = evaluate.load("accuracy")
print(accuracy.description)
print(accuracy.features)
# Accuracy is the proportion of correct predictions among the total number of cases processed. It can be computed with:
# Accuracy = (TP + TN) / (TP + TN + FP + FN)
# Where:
# TP: True positive
# TN: True negative
# FP: False positive
# FN: False negative
# {'predictions': Value(dtype='int32', id=None), 'references': Value(dtype='int32', id=None)}
計算は次のように行います.
# まとめて
accuracy.compute(references=[0,1,0,1], predictions=[1,0,0,1])
# 一個ずつ追加して
for ref, pred in zip([0,1,0,1], [1,0,0,1]):
accuracy.add(references=ref, predictions=pred)
accuracy.compute()
# バッチごとに追加して
for refs, preds in zip([[0,1],[0,1]], [[1,0],[0,1]]):
accuracy.add_batch(references=refs, predictions=preds)
accuracy.compute()
# 機械学習における適用例
# for model_inputs, gold_standards in evaluation_dataset:
# predictions = model(model_inputs)
# metric.add_batch(references=gold_standards, predictions=predictions)
# metric.compute()
また,metricsをまとめて計算したり,結果をjson形式で保存する場合は次のように書きます.
# metricsをまとめて計算
clf_metrics = evaluate.combine(["accuracy", "f1", "precision", "recall"])
clf_metrics.compute(references=[0,1,0,1], predictions=[1,0,0,1])
# {'accuracy': 0.5, 'f1': 0.5, 'precision': 0.5, 'recall': 0.5}
# モデル情報とともに保存
result = accuracy.compute(references=[0,1,0,1], predictions=[1,0,0,1])
hyperparams = {"model": "bert-base-uncased"}
evaluate.save("./results/", experiment="run 42", **result, **hyperparams)
pipelineの活用
pipelineを用いるとさまざまなタスクを簡単に試すことができます.
翻訳
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-ja-en")
model = AutoModelForSeq2SeqLM.from_pretrained("Helsinki-NLP/opus-mt-ja-en")
input_text = "昨日は本を読みました"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
outputs = model.generate(input_ids)
decoded_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded_text)
# I read a book yesterday.
日本語はまだありませんが,translation_xx_to_xx で簡単に翻訳できます.
from transformers import pipeline
en_fr_translator = pipeline("translation_en_to_fr")
en_fr_translator("How old are you?")
## [{'translation_text': ' quel âge êtes-vous?'}]
テキスト生成
from transformers import pipeline, T5Tokenizer, AutoModelForCausalLM
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-medium")
tokenizer.do_lower_case = True # due to some bug of tokenizer config loading
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt2-medium")
generator = pipeline('text-generation', model=model, tokenizer=tokenizer, device='cuda:0')
generator("昨日発表された")
# 昨日発表された新型iphoneの発表会場で手に入れた新型デバイスについて、今回はご紹介したいと思います。
# 個人的には、ディスプレイのデザインには非常に関心を寄せています! iphone6発表当時から、ディスプレイの
# 見た目に興味があったので、この
会話 (conversational)
ボットと会話できます.ボットは過去の会話の履歴を全て入力して応答を生成します.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-medium")
model = AutoModelForCausalLM.from_pretrained("microsoft/DialoGPT-medium")
# Let's chat for 5 lines
for step in range(5):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)
# pretty print last ouput tokens from bot
print("DialoGPT: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
# User Does money buy happiness?
# Bot Depends how much money you spend on it .
# User What is the best way to buy happiness ?
# Bot You just have to be a millionaire by your early 20s, then you can be happy .
# User This is so difficult !
# Bot You have no idea how hard it is to be a millionaire and happy . There is a reason the rich have a lot of money
テキストから画像生成 (stable diffusion)
# 事前準備
# 1. https://huggingface.co/settings/tokens でトークンを取得して huggingface-cli login でホームディレクトリ下にトークンを保存
# 2. https://huggingface.co/CompVis/stable-diffusion-v1-4 ここの利用規約に同意する必要がある
from diffusers import StableDiffusionPipeline
import torch
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4",
torch_type=torch.float16, revision="fp16")
pipe = pipe.to("cuda")
prompt = "Tokyo Tower painted by Katsuhika Hokusai"
image = pipe(prompt).images
image[0]

固有表現抽出 (token-classification or ner)
from transformers import pipeline, AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-base-NER")
model = AutoModelForTokenClassification.from_pretrained("dslim/bert-base-NER")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "My name is Wolfgang and I live in Berlin"
ner_results = nlp(example)
print(ner_results)
# [{'entity': 'B-PER', 'score': 0.99901396, 'index': 4, 'word': 'Wolfgang', 'start': 11,
# 'end': 19}, {'entity': 'B-LOC', 'score': 0.999645, 'index': 9, 'word': 'Berlin',
# 'start': 34, 'end': 40}]
画像分類 (image-classification)
from transformers import pipeline
clf = pipeline("image-classification")
clf("cat.jpeg")
# [{'score': 0.6696406602859497, 'label': 'tabby, tabby cat'},
# {'score': 0.17107301950454712, 'label': 'tiger cat'},
# {'score': 0.14145831763744354, 'label': 'Egyptian cat'},
# {'score': 0.00964306853711605, 'label': 'lynx, catamount'},
# {'score': 0.0012223547091707587, 'label': 'Persian cat'}]
feature-extraction
BARTによるテキストの特徴抽出はこちらです.
from transformers import BartTokenizer, BartModel
tokenizer = BartTokenizer.from_pretrained('facebook/bart-base')
model = BartModel.from_pretrained('facebook/bart-base')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
VITによる画像の特徴抽出はこちらです.
from transformers import ViTFeatureExtractor, ViTModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
model = ViTModel.from_pretrained('google/vit-base-patch16-224-in21k')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
fill-mask
from transformers import pipeline
classifier = pipeline("fill-mask")
classifier("Paris is the <mask> of France.")
# [{'score': 0.7, 'sequence': 'Paris is the capital of France.'},
# {'score': 0.2, 'sequence': 'Paris is the birthplace of France.'},
# {'score': 0.1, 'sequence': 'Paris is the heart of France.'}]
question-answering
再掲ですが,questionの答えをcontextから抜き出すタスクです.
from transformers import pipeline
qa_model = pipeline("question-answering")
question = "Where do I live?"
context = "My name is Merve and I live in İstanbul."
qa_model(question = question, context = context)
## {'answer': 'İstanbul', 'end': 39, 'score': 0.953, 'start': 31}
summarization
from transformers import pipeline
classifier = pipeline("summarization")
classifier("Paris is the capital and most populous city of France, with an estimated population of 2,175,601 residents as of 2018, in an area of more than 105 square kilometres (41 square miles). The City of Paris is the centre and seat of government of the region and province of Île-de-France, or Paris Region, which has an estimated population of 12,174,880, or about 18 percent of the population of France as of 2017.”)
## [{ "summary_text": " Paris is the capital and most populous city of France..." }]
text-classification
テキスト分類系のいろんなモデルを試せます.
QNLIは質問と文が与えられ,質問に対する回答が文に含まれているか判定するタスクです.
from transformers import pipeline
classifier = pipeline("text-classification", model = "cross-encoder/qnli-electra-base")
classifier("Where is the capital of France?, Paris is the capital of France.")
## [{'label': 'entailment', 'score': 0.997}]
text2text-generation
雑多なseq2seqタスクがあるようです.
context と question から answer を生成するのではなく,
context と answer から question を生成しています.
# Tip: By now, install transformers from source
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-base-finetuned-question-generation-ap")
model = AutoModelWithLMHead.from_pretrained("mrm8488/t5-base-finetuned-question-generation-ap")
def get_question(answer, context, max_length=64):
input_text = "answer: %s context: %s </s>" % (answer, context)
features = tokenizer([input_text], return_tensors='pt')
output = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'],
max_length=max_length)
return tokenizer.decode(output[0])
context = "Manuel has created RuPERTa-base with the support of HF-Transformers and Google"
answer = "Manuel"
get_question(answer, context)
# output: question: Who created the RuPERTa-base?
table-question-answering
表データと質問が与えられたとき,質問に対する答えを表から抜き出します.
# nvcc -V で cudaのバージョン確認 https://zenn.dev/takeshita/articles/a02402e59d72a7
# pip install torch==1.12.0+cu116 torchvision==0.13.0+cu116 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu116
# pip install torch-scatter -f https://data.pyg.org/whl/torch-1.12.0+cu116.html
from transformers import pipeline
import pandas as pd
# prepare table + question
data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
table = pd.DataFrame.from_dict(data)
question = "how many movies does Leonardo Di Caprio have?"
# pipeline model
# Note: you must to install torch-scatter first.
tqa = pipeline(task="table-question-answering", model="google/tapas-large-finetuned-wtq")
print(tqa(table=table, query=question)['cells'][0])
#53
audio-classification
speechbrain をインストールする必要があります.
from speechbrain.pretrained import EncoderClassifier
model = EncoderClassifier.from_hparams(
"speechbrain/google_speech_command_xvector"
)
model.classify_file("file.wav")
automatic-speech-recognition
from transformers import pipeline
with open("sample.flac", "rb") as f:
data = f.read()
pipe = pipeline("automatic-speech-recognition", "facebook/wav2vec2-base-960h")
pipe("sample.flac")
# {'text': "GOING ALONG SLUSHY COUNTRY ROADS AND SPEAKING TO DAMP AUDIENCES IN DRAUGHTY SCHOOL ROOMS DAY AFTER DAY FOR A FORTNIGHT HE'LL HAVE TO PUT IN AN APPEARANCE AT SOME PLACE OF WORSHIP ON SUNDAY MORNING AND HE CAN COME TO US IMMEDIATELY AFTERWARDS"}