はじめに
InstructGPTは、GPTが人間にとって望ましい出力をするように試みた研究です。
そのためには、人間が対話形式のテキストデータを作ることが有効です(論文内のSFTモデル)。
また、PPOモデルはGPTが生成した文を評価する別のモデルを用意し、強化学習を行うことでさらなる性能を向上させています。
論文には実装がありませんが、ありがたいことに追実装を行っている方がいました。
これを参考にしながら論文でメインとなる目的関数について考えてみます。
目的関数の説明
InstructGPTの論文にはこのような数式で説明されています。
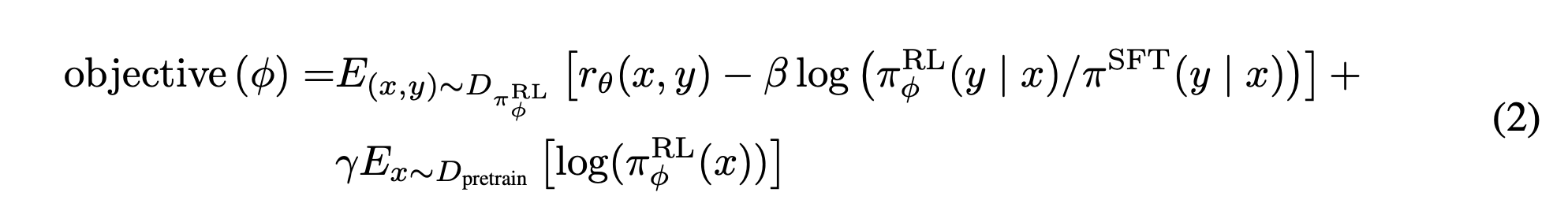
1項目
$r_\theta$ の項は報酬モデルのスコアを表します。
新しく学習するRLモデルについてランダムサンプリングでたくさん文を生成して、報酬モデルのスコアが高いものを学習データに追加するイメージです。
強化学習手法の REINFORCE が、報酬の大きな生成文を優先的に出すよう学習することに相当します。
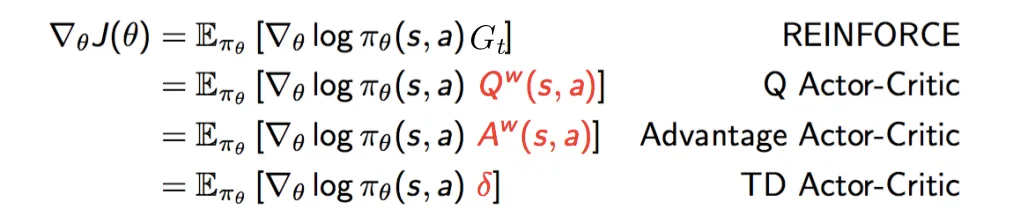
$G_t$ は累積報酬和であり、InstructGPTでは報酬モデルの出力を固定値の報酬として扱っています。
実装では Advantage Actor-Critic を採用しています。
これは、報酬モデルとActor(RLモデル)とは別に、Criticという価値関数を導入する手法です。
実装においては、Criticモデルは、Actorモデルのdeepcopyをとった後、ヘッドにスカラーを出力するための線形層を加えています。
REINFORCEと比較したactor-criticの利点は、以下のようなものがあります。
- actor-criticは、方策勾配を求めるときに、状態価値関数をベースラインとして使うことで、方策の更新を安定させることができます。REINFORCEでは、ベースラインが定数であるため、方策の更新が大きく揺れやすいです。
- actor-criticは、状態価値関数を学習するcriticと方策を学習するactorを分けておくことで、それぞれに適したニューラルネットワークや学習率などを設定することができます。REINFORCEでは、方策関数だけを学習するため、ニューラルネットワークの設計やパラメータ調整が難しい場合があります。
- actor-criticは、非同期的に複数のエージェントが並列に学習することで、データ効率や探索性能を向上させることができます。A3C(Asynchronous Advantage Actor-Critic)はその一例です。REINFORCEでは、一つのエージェントしか使えないため、学習速度や汎化性能に限界があります。
2項目
SFTモデルと新しく学習させるRLモデルの生成文の間でKLダイバージェンスをとったものです。
人間ではなくモデルが評価しているため、報酬を高くするだけの崩壊した文が生成されてしまう恐れがあります。
そこで、生成する各トークンの語彙分布について、SFTモデルの語彙分布と近づけるようにすることで、崩壊した文が生成されないような工夫をしています。
このようにKL項を加えた強化学習手法をPPOとよびます。
3項目
報酬を高くするように学習を続けていると、GPT本来の性能(perplexityや各タスクにおけるFew-shot能力等)が薄れてします現象がありました。
そこで、通常のGPT学習の項を加えることで、精度の低下を防いでいます。
論文中ではPPO-ptxモデルとされています。
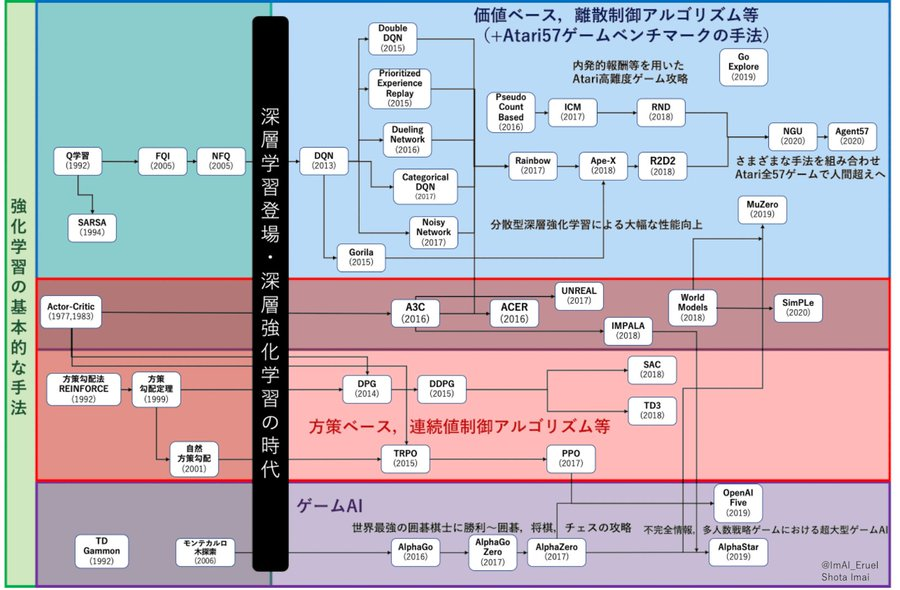
強化学習のロードマップ
強化学習のロードマップは下図でまとめられています。
価値ベースと方策ベースを組み合わせたActor-Criticに端を発してPPOにつながっていることがわかります。
GPT3にPPO学習を取り入れたchatGPTが人気ですが、これからも強化学習を取り入れた研究は増えていきそうです。