はじめに
データ分析や機械学習において、モデルの精度を向上するためにはデータを理解する探索的なデータ分析とデータの前処理や特徴量エンジニアリングが重要です。
一方で、そのような作業はデータ分析を生業とするプロフェッショナルの高度な技能とPythonのような言語に対する理解も必要だったりします。
Amazon SageMaker AI Data Wranglerとは
Amazon SageMaker AI(以下、SageMaker)はAWSが提供するデータ分析、機械学習のプラットフォームです。
SageMakerはJupyterLabのようなNotebook形式で分析やモデル訓練が行えるツールを提供していますが、できるだけコードを書かない、所謂ノーコード・ローコードでの分析ツールも提供しています。
SageMaker Data Wranglerはノーコード・ローコードで探索的データ分析やデータの前処理、特徴量エンジニアリングを行えるツールです。
本記事ではSageMaker Data Wranglerを使用してデータ分析や前処理、特徴量エンジニアリングを行ってみます。
SageMaker Data Wranglerでできるデータ変換の種類
SageMaker Data Wranglerでできる変換を確認しておきます。これらの組み込みデータ変換を使用すると内部的にPySparkコードが生成されます。
各変換の簡単な説明とドキュメントリンクを記載します。変換名はSageMaker Data Wranglerを使用するときの変換UIに表示されます。使い方を調べるときにご活用ください。
| カテゴリ | 変換名 | 説明 |
|---|---|---|
| Custom | Custom formula | Spark SQLを使用してデータフレーム内のデータをクエリして新しい列を定義する |
| Custom | Custom transform | PySpark、Pandas、PySpark(SQL)を使用してカスタム変換を定義する |
| Custom | Balance data | ランダムオーバーサンプリング、ランダムアンダーサンプリング、SMOTEを使用してバイナリ分類におけるデータバランスをとる |
| Standard | Dimensionality Reduction | 上位K個の主成分について、ベクトルを低次元空間に射影するようにモデルをトレーニングする |
| Standard | Encode categorical | カテゴリ変数を数値またはベクトル表現に変換する |
| Standard | Featurize date/time | 日付/時刻を数値およびベクトル表現にエンコードする 年、日、週などの日付から特徴を抽出する |
| Standard | Featurize text | 自然言語テキストからベクトル表現を生成する |
| Standard | Filter or drop rows | 指定したパターンに一致しない行をフィルターまたは削除する |
| Standard | Format string | 標準の文字列フォーマット操作を使用して、文字列をクリーンアップする |
| Standard | Group by ※ドキュメントなし |
グループ化された新しい列として集計列を追加する |
| Standard | Handle missing | 欠損値を置換、削除したりインジケータを追加する |
| Standard | Handle outliers | 外れ値の数値およびカテゴリ値を削除または置換する |
| Standard | Handle structured column | JSONをフラット化し、構造化データに対して操作を実行する |
| Standard | Manage columns | データセット内の列を移動、削除、複製、名前変更する |
| Standard | Manage rows | 行の並べ替え、順序のシャッフル、重複排除、空行の削除、指定パターンに一致しない行を削除する |
| Standard | Manage vectors | ベクトル列を展開または作成する |
| Standard | Parse column as type | 列を新しいデータ型にキャストする |
| Standard | Process numeric | 数値を変換して機械学習モデルのパフォーマンスを向上させる |
| Standard | Sampling | データセットのサンプルを作成する |
| Standard | Search and edit | 文字列の検索、置換、分割などの変換を行う |
| Standard | Split data | データフレームを複数のデータフレームに分割する |
| Standard | Time Series | 時系列を前処理および操作する |
| Standard | Validate string | 標準の文字列関数を使用して文字列の形式を検証する |
| Amazon AI services | Transforms for Amazon Personalize | Amazon Personalizeのユースケースに合わせてデータセットを変換する |
やってみた
SageMakerドメインおよびプロファイルはあらかじめ作成しておきます。
QuickSetupを使用すると迷うことなくドメインを作成できます。
事前準備
SageMaker Studioの起動
SageMaker Studioを起動します。以下のような画面が立ち上がります。
SageMaker Canvasの起動
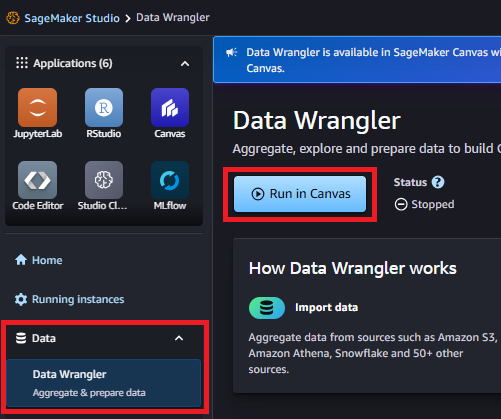
SageMaker Data WranglerはSageMaker Canvasと統合されました。
左ペインの「Data」ー「Data Wrangler」を選択して、「Run in Canvas」を押下することでインスタンスを起動します。
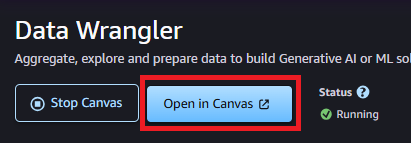
起動したら「Open in Canvas」でSageMaker Canvasを起動します。
実践!特徴量エンジニアリング
Kaggleの「Titanic - Machine Learning from Disaster」のサンプルデータを使用して特徴量エンジニアリングを実施してみます。
データのインポート
データはS3やローカルファイルの他に、PostgreSQLやMySQL、DocumentDB、Redshiftなど多種多様なデータソースからインポートできます。今回はS3からインポートします。
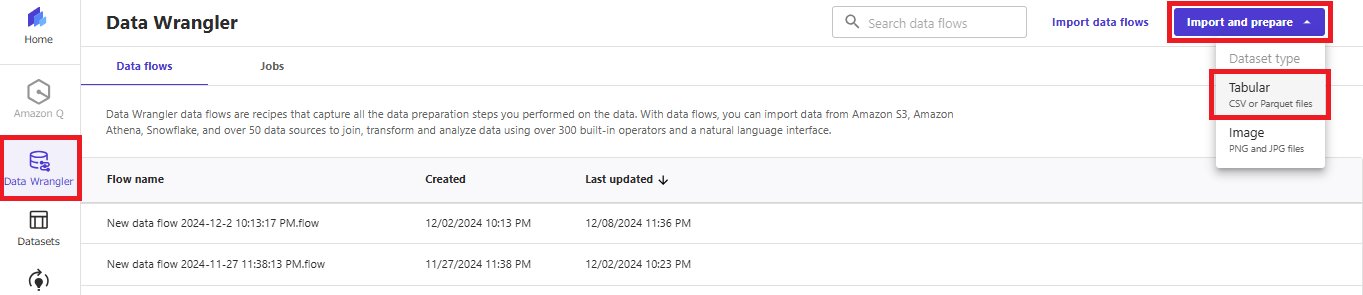
左ペインで「Data Wrangler」を選択し、「Import and prepare」を押下します。
CSVファイルを扱うので「Tabuler」としましょう。
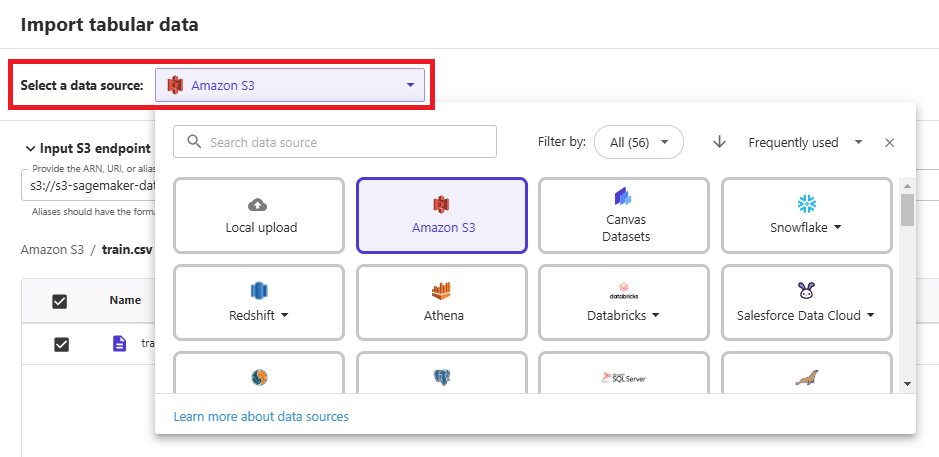
「Select a data source:」からさまざまなデータソースを選択できます。
S3にファイルをアップロードしておき、CSVファイルを選択します。
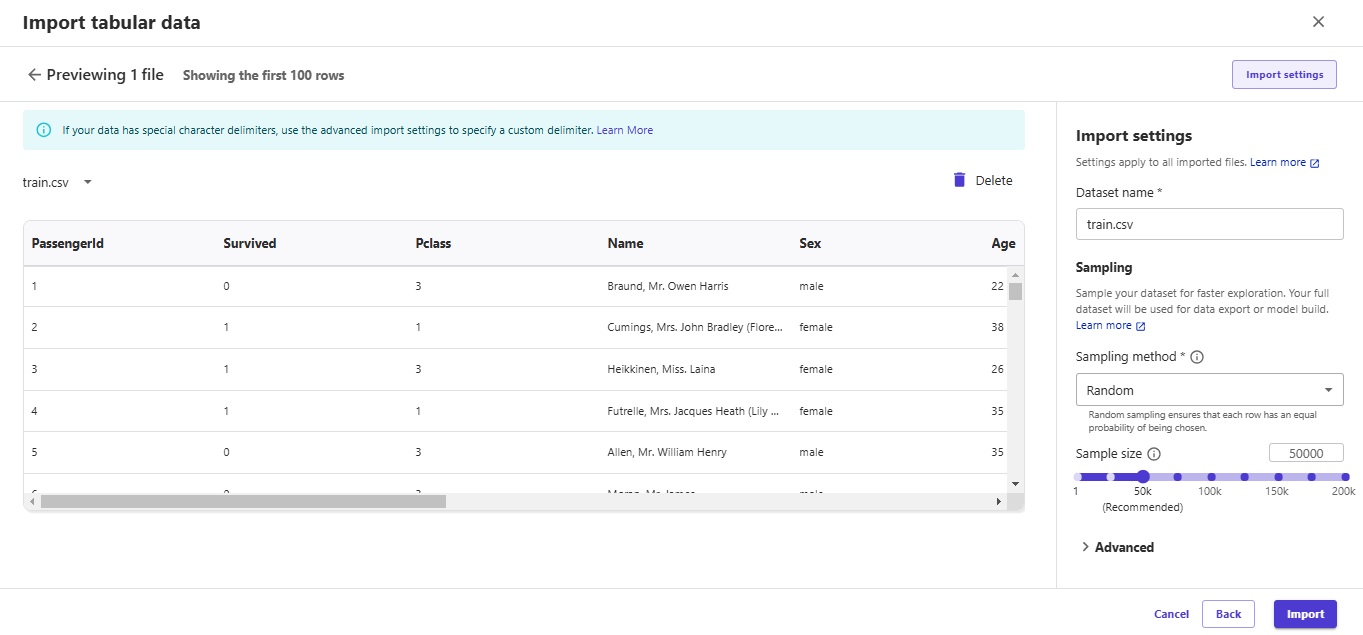
ファイルの内容がプレビューされますので、データセット名やサンプリングを設定してインポートします。
データ型の変換
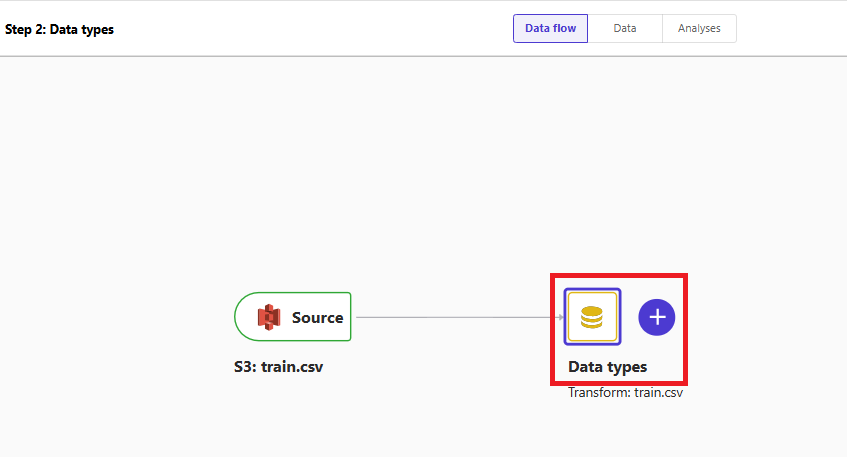
CSVファイルを取り込んだばかりのシンプルなデータフローが作成されます。
「Data types」をダブルクリックするとデータ型を変更できます。
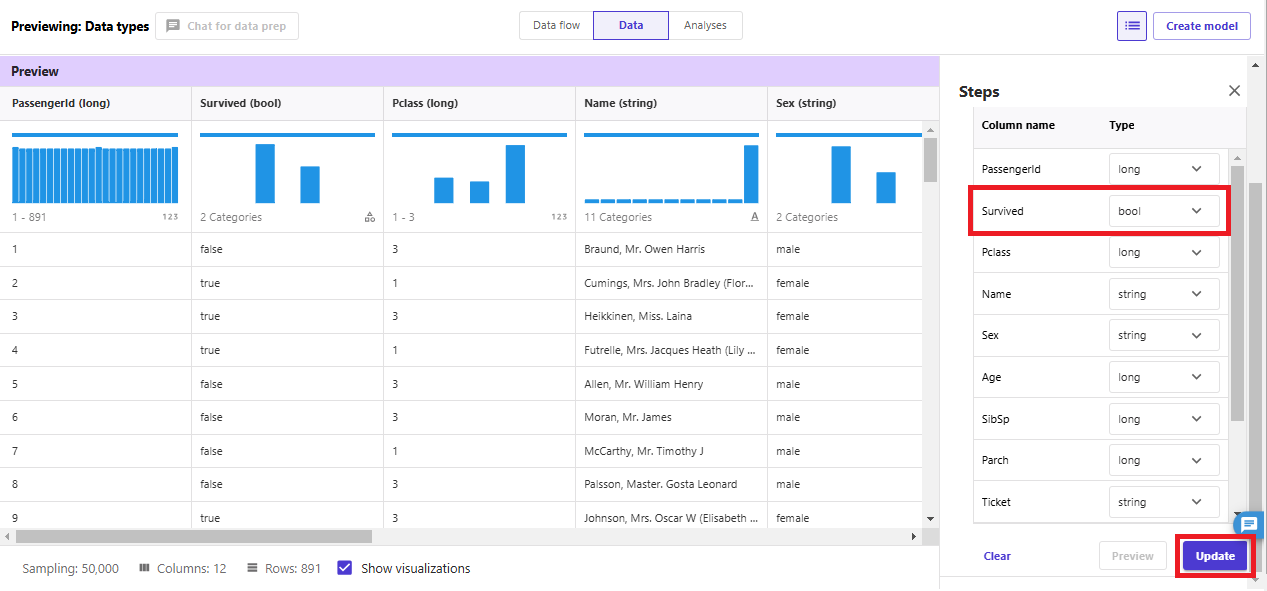
「Survived」を「Boolean」に変更してみました。「Preview」を確認したら「Update」で反映します。
探索的データ分析
「Data flow」タブに戻り、「Data types」の横の「+」ボタンから「Get data insights」を選択します。
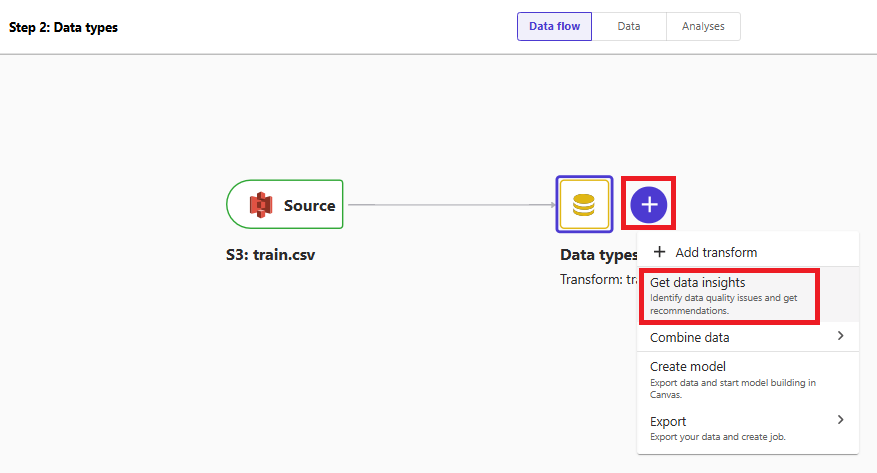
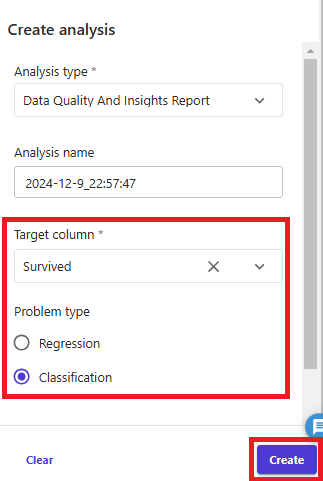
生存有無を分類するため「Target column」は「Survived」、「Problem type」は「Classification」として「Create」を押下すると、たった数秒でデータセットの概要レポートを出力してくれます。
データセットの統計情報
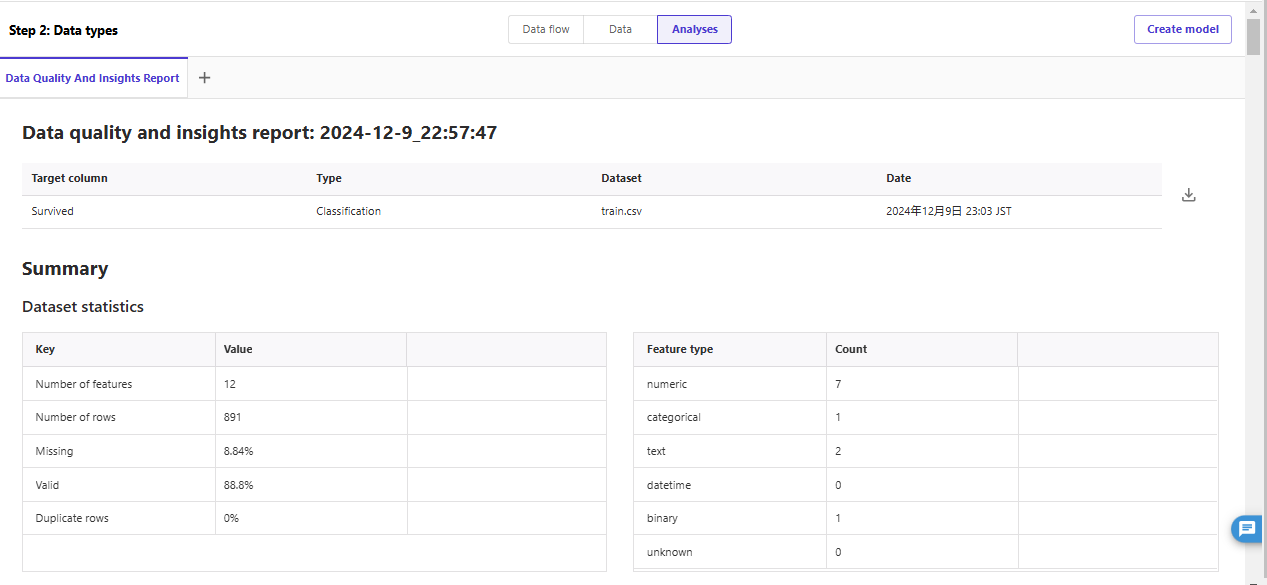
特徴のサマリ
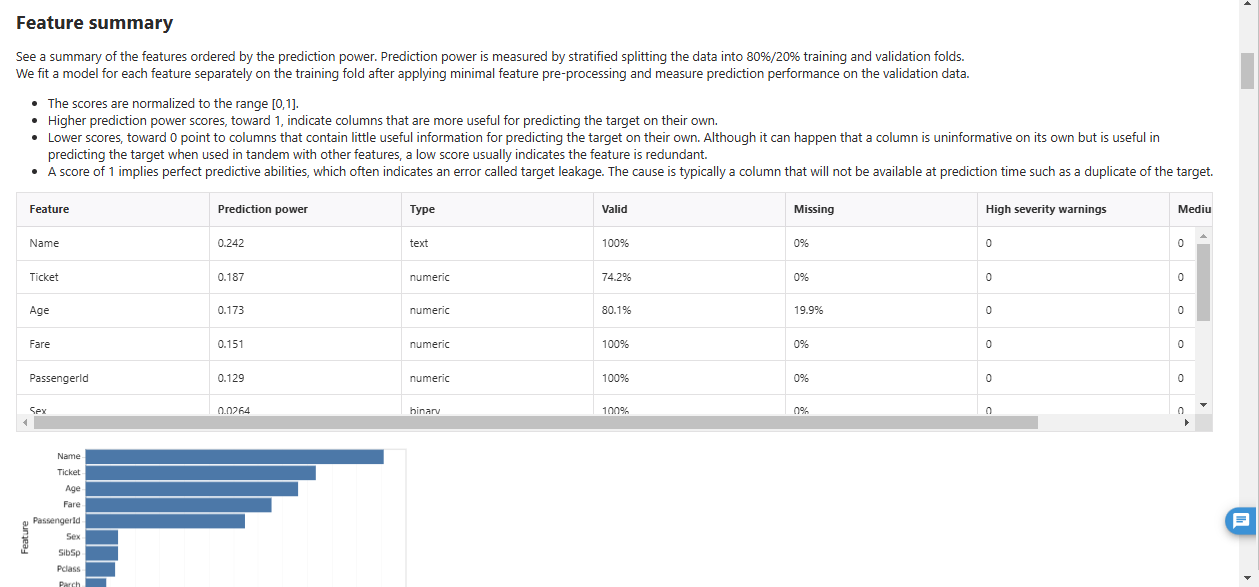
Quick Model
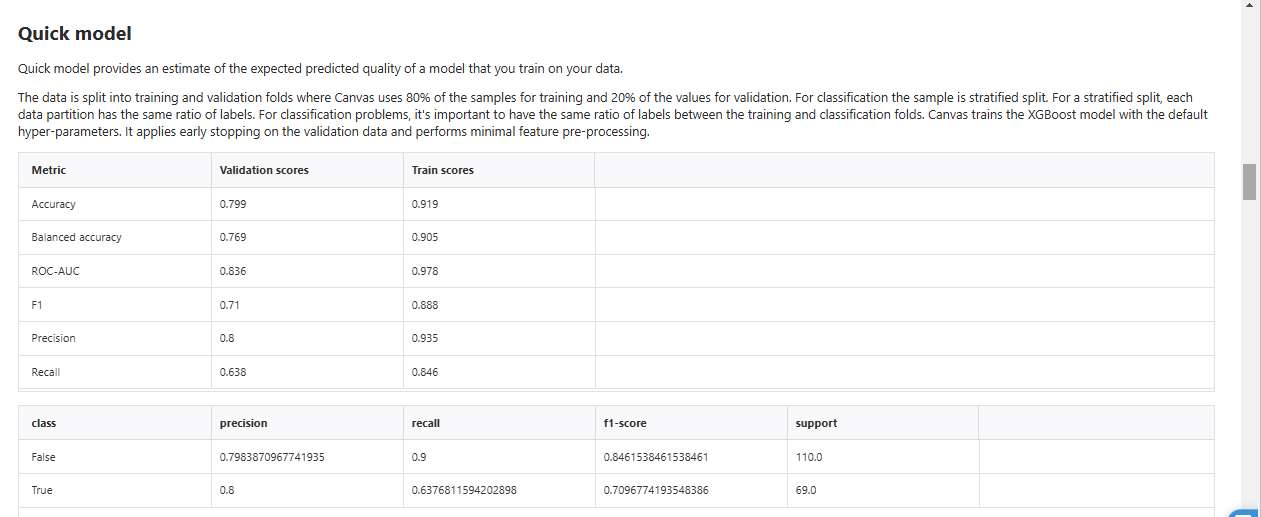
各特徴の統計量
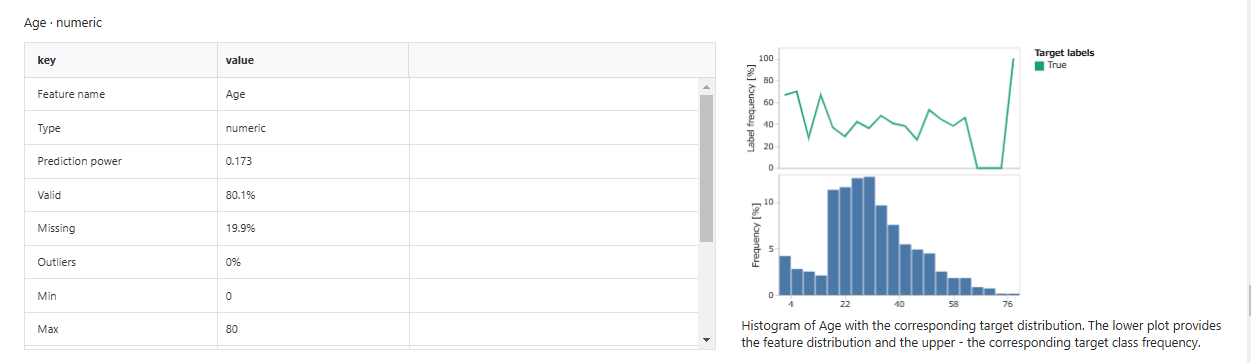
その他に、重複行の有無や異常値などを可視化してくれます。
データセットの変換
「Titanic competition w/ TensorFlow Decision Forests」のコードを参考に訓練用データセットを変換してみます。
「Data flow」タブに戻り、「Data types」の「+」を選択して「+Add transform」を選択します。
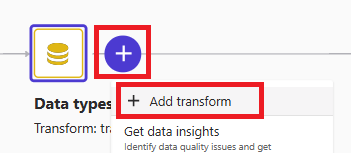
「Data」タブに遷移したら「+Add transform」を押下して変換ステップを追加していきます。
「Titanic competition w/ TensorFlow Decision Forests」で実装されているデータ変換をSageMaker Data Wranglerで処理してみます。
1.Tokenize the names. For example, "Braund, Mr. Owen Harris" will become ["Braund", "Mr.", "Owen", "Harris"].
def normalize_name(x):
return " ".join([v.strip(",()[].\"'") for v in x.split(" ")])
df["Name"] = df["Name"].apply(normalize_name)
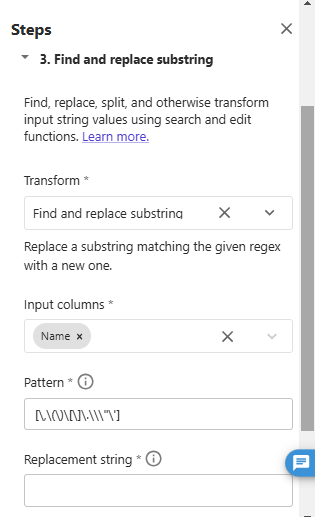
「Search and edit」からTransform「Find and replace substring」を選択して、以下の通りInput columnsにName、Patternに[\,\(\)\[\]\.\\\"\']、Replacement stringに半角スペースを入力します。
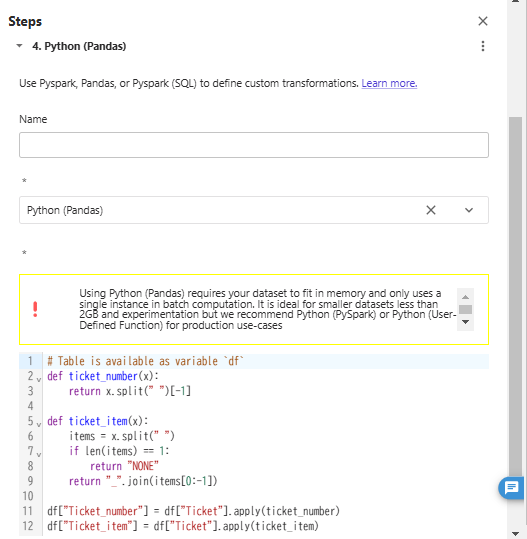
2.Extract any prefix in the ticket. For example ticket "STON/O2. 3101282" will become "STON/O2." and 3101282.
def ticket_number(x):
return x.split(" ")[-1]
def ticket_item(x):
items = x.split(" ")
if len(items) == 1:
return "NONE"
return "_".join(items[0:-1])
df["Ticket_number"] = df["Ticket"].apply(ticket_number)
df["Ticket_item"] = df["Ticket"].apply(ticket_item)
この変換は用意された部品だけでの実装が難しかったため「Custom transform」から「Python (Pandas)」を選択してカスタムコード(上と同じコード)を入力しました。
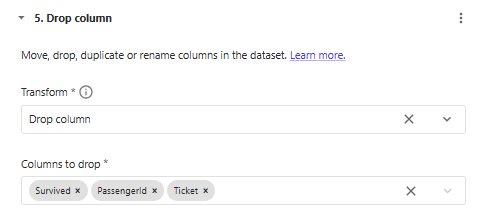
Let's keep the list of the input features of the model. Notably, we don't want to train our model on the "PassengerId" and "Ticket" features.
input_features.remove("Ticket")
input_features.remove("PassengerId")
input_features.remove("Survived")
「Manage columns」の「Drop column」で削除する特徴を選択します。
※ PassengerIdはこの後のデータエクスポートで使用するため戻しておきます。
データのエクスポート
変換したデータはS3やSageMaker Canvas Datasets、SageMaker Feature Storeなどへエクスポートできます。特徴量をSageMaker Feature Storeへエクスポートしてみます。
SageMaker Feature Storeへエクスポートする際、以下の列が必要になります。
- Record identifier:レコードを一意に識別できるID
- Event time feature:レコードのイベントが発生したときのタイムスタンプ
「Record identifier」にはPassengerIdを使用し、「Event time feature」は以下のようなCustom transformを追加してevent_timeという名前の特徴を作成します。
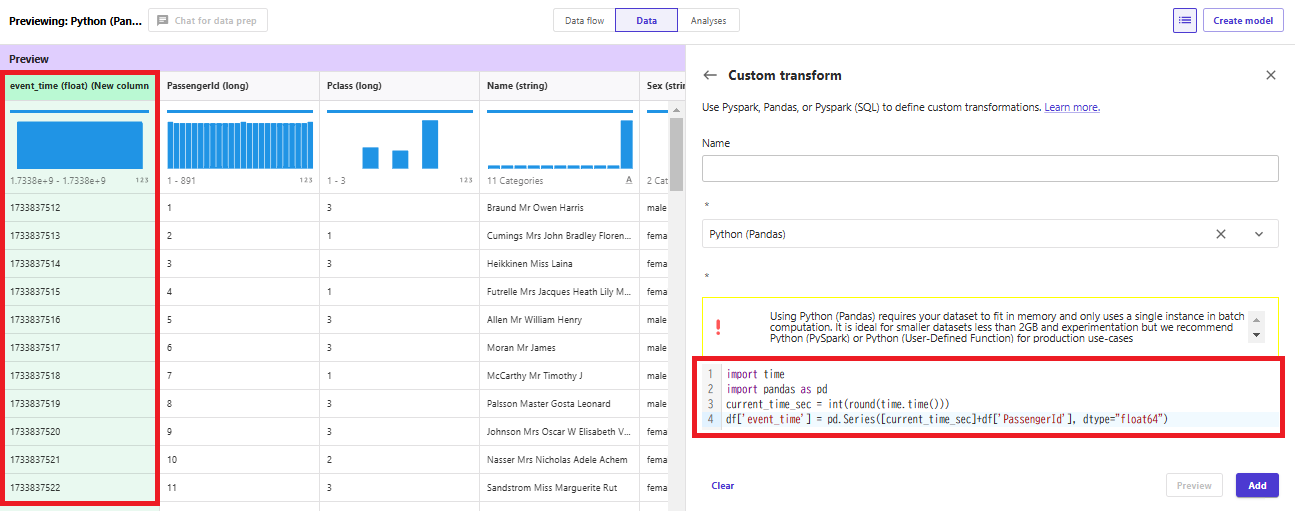
import time
import pandas as pd
current_time_sec = int(round(time.time()))
df['event_time'] = pd.Series([current_time_sec]+df['PassengerId'], dtype="float64")
「+」を選択して「Export」-「Export via Jupyter notebook」-「SageMaker Feature Store」を選択します。ローカルPCへダウンロードしたり任意のS3バケットを選択してNotebookを出力します。
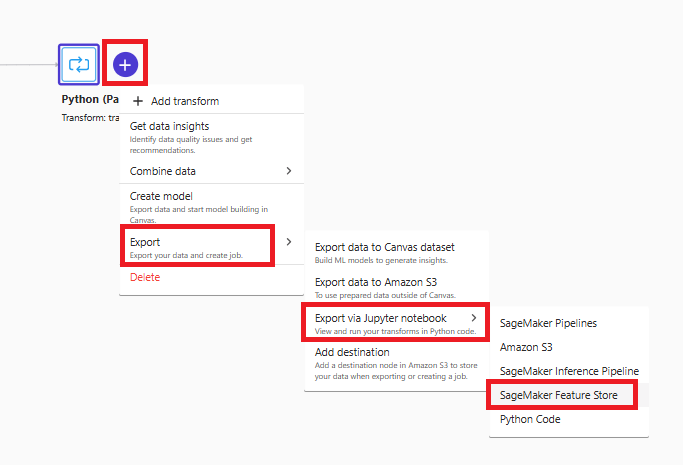
JupyterLabインスタンスを起動してコンソールを開きます。
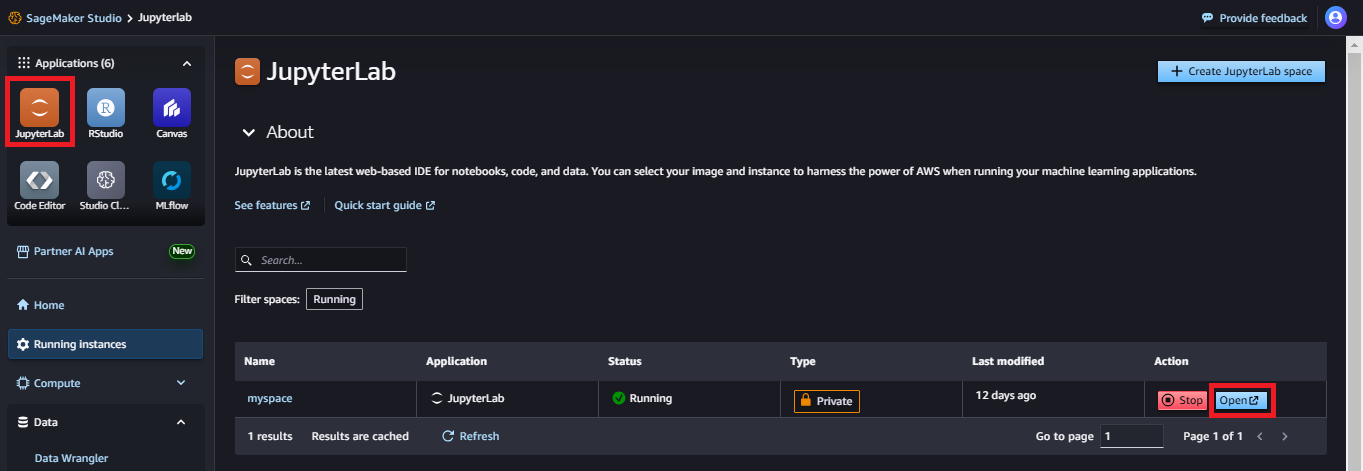
ダウンロードした.ipynbファイルを開き、record_identifier_feature_nameを"PassengerId"に、event_time_feature_nameを"event_time"に、flow_nameを任意の名前に変更します。


準備ができたら画面上部の実行ボタン(または[Shift]+[Enter])を押下して以下の項目が完了するまでセルを実行します。
- Create Feature Group
A. Define Feature Group
B. Configure Feature Group
C. Initialize & Create Feature Group
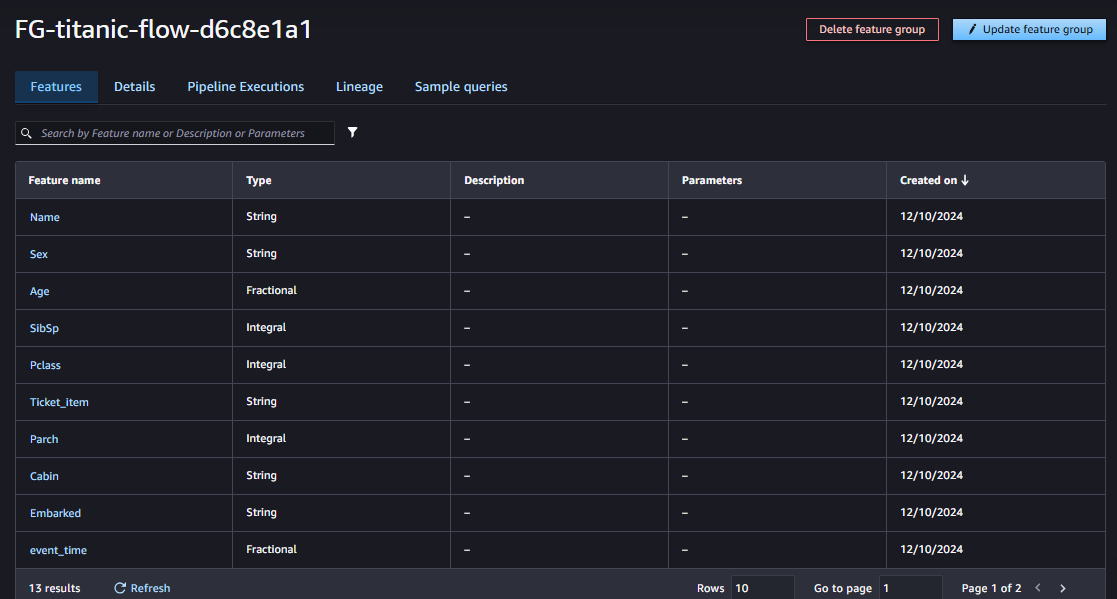
SageMaker Feature StoreのFeature Groupが作成されました。
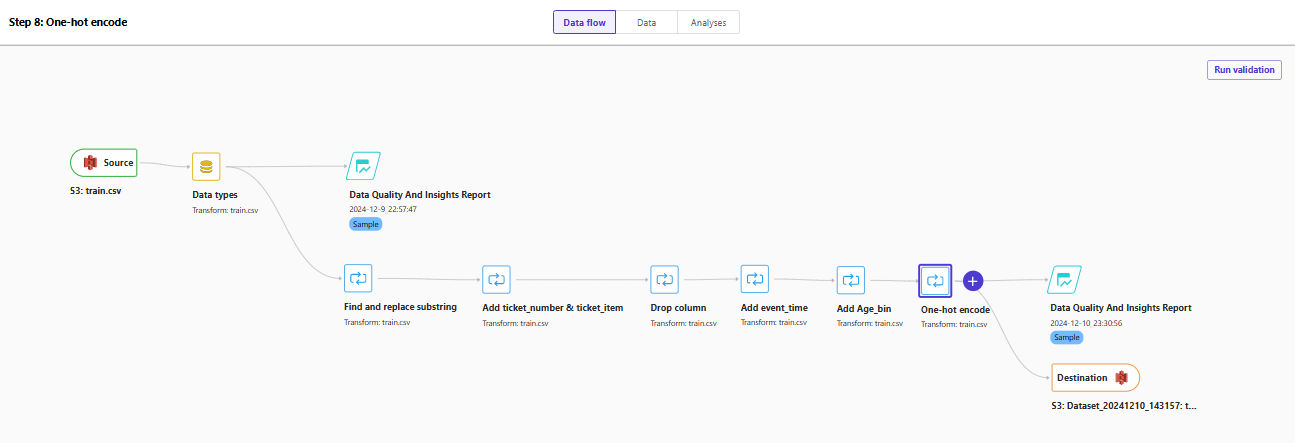
最終的にできたデータフローがこちらです。
SageMakerインスタンスの停止
SageMaker Data Wranglerはインスタンスを起動している時間単位で課金されます。
SageMaker Studioの「Running Instances」で起動しているインスタンスを表示できますので使っていないインスタンスは停止しておきましょう。同じく、JupyterLabインスタンスも停止しましょう。

おまけ1:SageMaker CanvasでAmazon Q Developerを使用する
AWS re:Invent 2024において、SageMaker CanvasでAmazon Q Developerを使用できるようになったとのアナウンスがありました。本題から逸れますが、気になったので試してみました。
ユーザープロファイルのアプリケーション設定において、Canvasの設定でAmazon Q Developerを有効化しておきます。
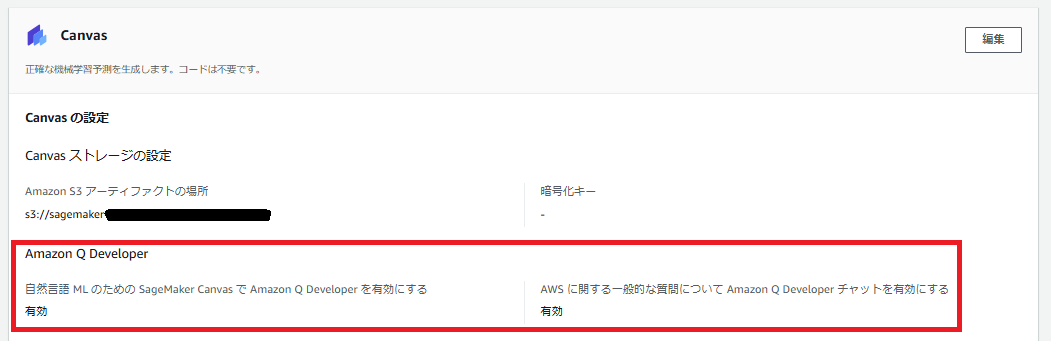
SageMaker Canvasの左ペインで「Amazon Q」が使えるようになっています。「Start a new conversation」で新しいチャットを始めます。
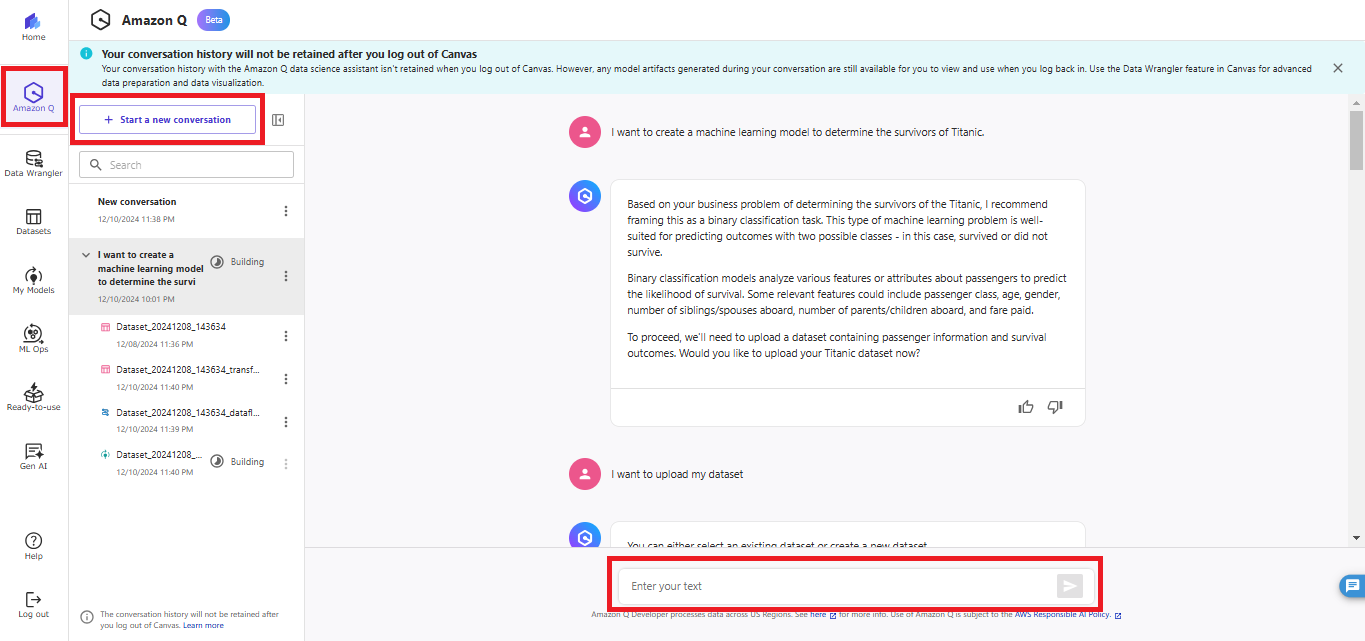
やりたいことを簡潔に伝え、データをアップロードするとデータセットの概要を教えてくれました。
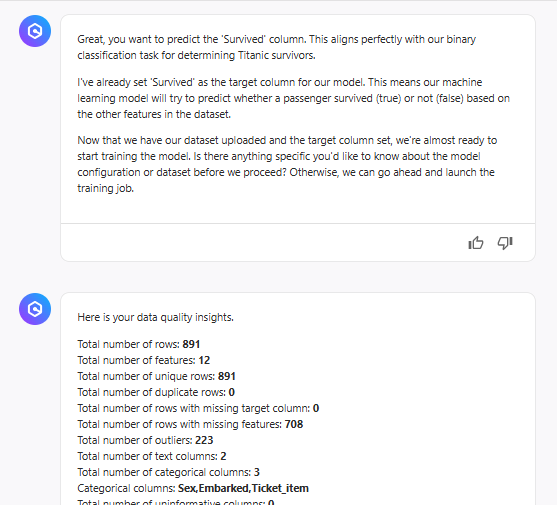
どんなアルゴリズムでモデルを訓練するか提案してくれて、
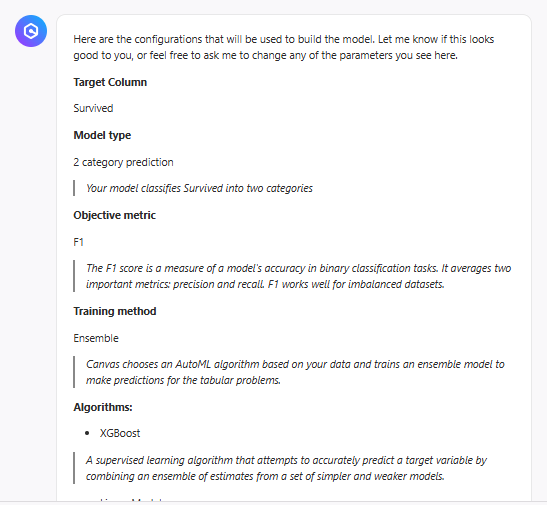
あっという間にモデルが作られました。
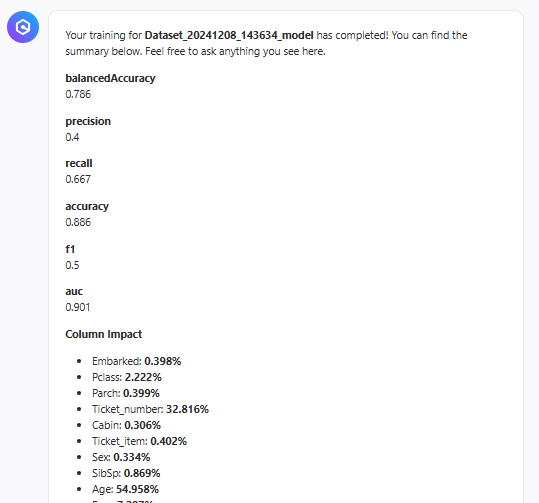
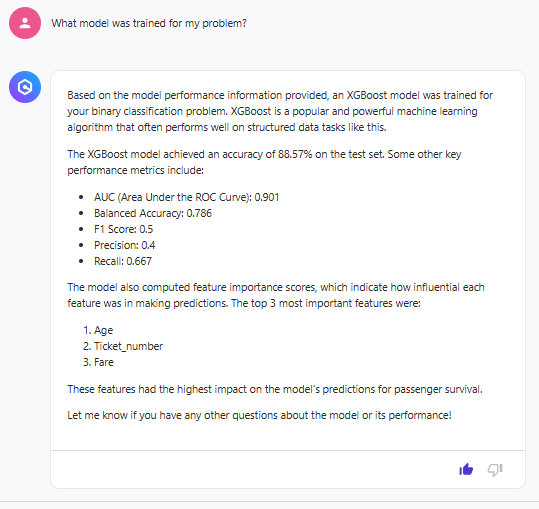
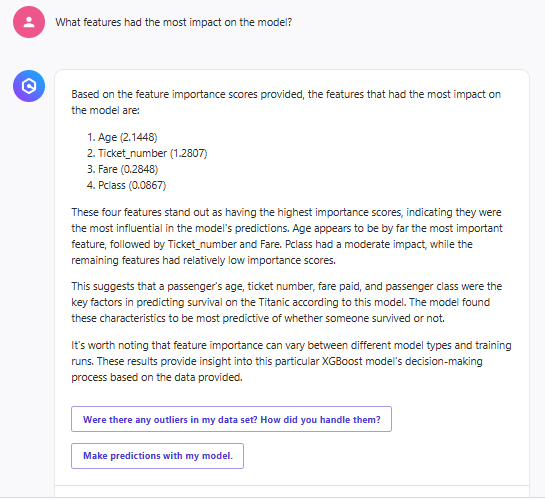
推論時に影響力のある特徴を教えてくれます。
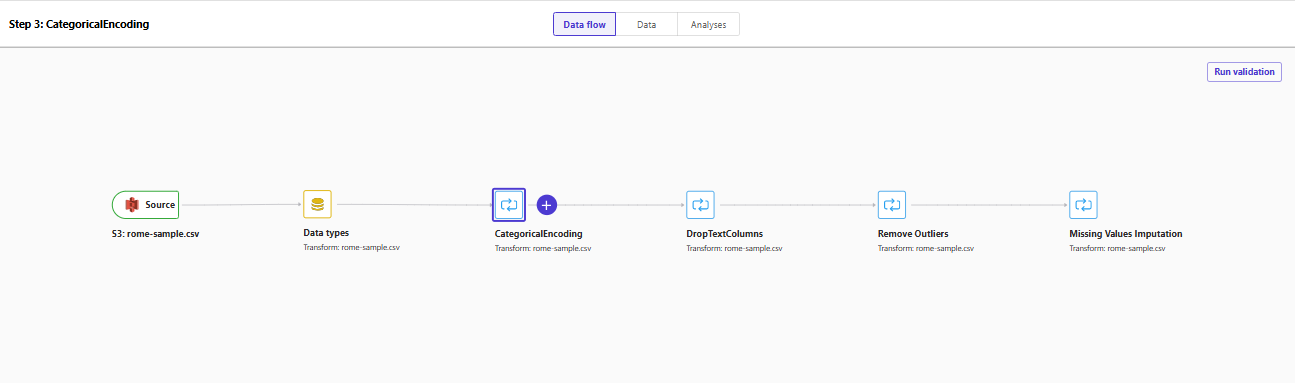
特徴量エンジニアリングとしてどのような処理が行われているかをData Wranglerのデータフローから確認することができます。(Flow nameに「Built by Amazon Q」というタグがついています。)
何から手を付けたらよいか分からない方は、最初にAmazon Qの手助けを借りて、後から自分のやりたいことを追加してもよさそうです。
おまけ2:Custom transformのコードを生成する
SageMaker CanvasでAmazon BedrockモデルやSageMaker Jumpstartモデルを使用できます。
SageMaker Data Wranglerが提供するノーコードの組み込み変換でできないことはCustom transformで実装しますが、ここで使用するPythonコードを生成AIに作ってもらいましょう。
ここではAmazon Bedrockの「Anthropic Claude Instant」を使用しますのであらかじめBedrockの画面からモデルへのアクセスを有効にしておきます。
SageMaker Canvasの左ペインで「Gen AI」を選択し、「Get started」を押下します。
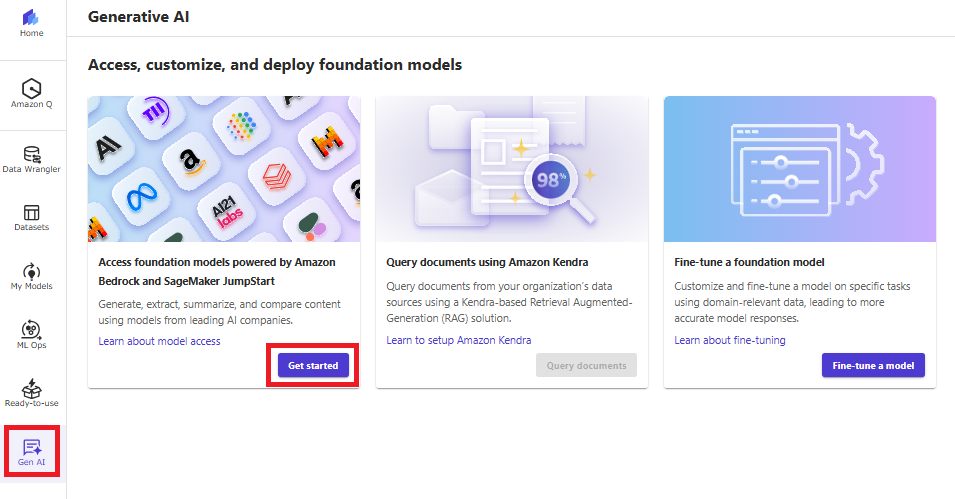
「Claude Instant」を選択して「Select」を押下します。
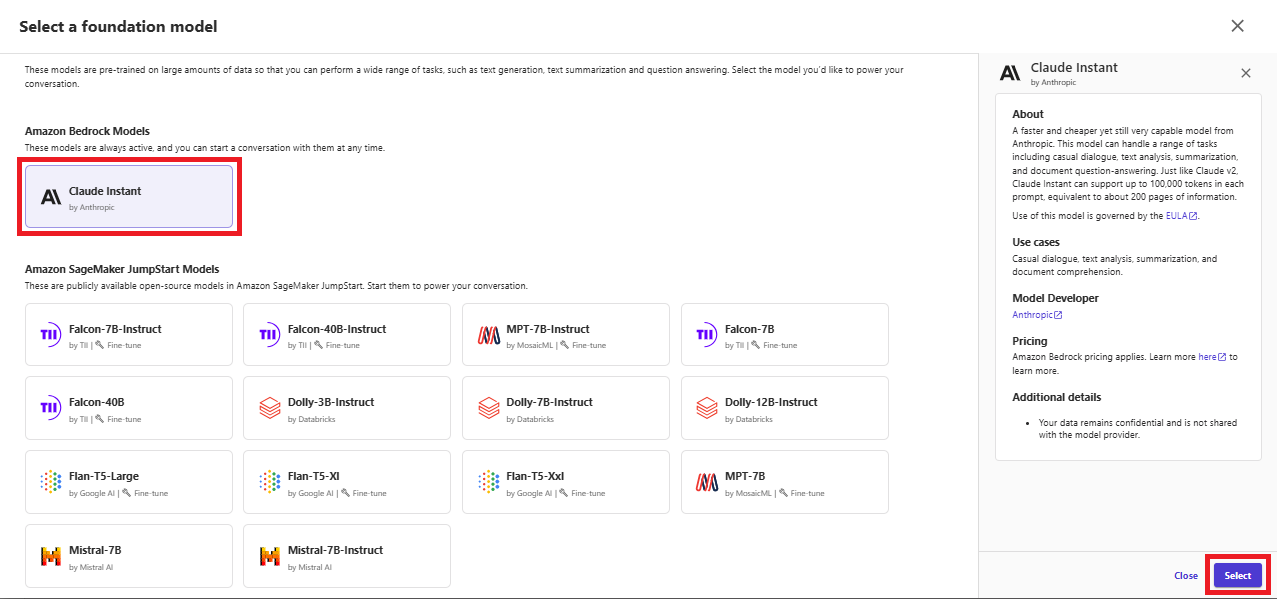
年齢のビニング処理について、Pandasを使用したPythonコード例を生成してもらいました。
SageMaker Data Wranglerの料金
一番安価なml.m5.4xlargeインスタンス(16vCPU、64GiB)を東京リージョンで使用した場合、1時間あたり$1.19とのことで、使わないときにインスタンスを起動したままにしておくと高額になりそうです。使わないときはきちんと停止しましょう。
ストレージ使用料はインスタンスを停止してもかかります。
おわりに
SageMaker Data Wranglerを使用することでデータ分析や前処理、特徴量エンジニアリングをノーコード・ローコードで実施でき、コードの書き方が分からないユーザでも分析業務に入りやすくなりました。
単純な処理はノーコード・ローコードで、より複雑な処理はカスタムコードを書いて処理するといったハイブリッドもよさそうです。
最後までご覧いただきありがとうございました。
本記事が皆さまのお役に立てましたら幸いです。