研究室のB4向けにTransformer勉強会を開催したので記事にします.
実装はこちら.スターをくれると励みになります
私は生成モデルの研究をしているWebエンジニアなのでTransformerの知識は薄いです.本記事の内容には誤りが含まれる可能性があります
環境構築
Dockerfileと起動スクリプトdocker.shを置いてあります.W&BのAPIキーを使用するのでREADMEを参考に取得してください.
取得したら.env.exampleというファイルをコピーして.envにリネームし,WAND_API_KEY=取得したAPIキーとしてください.APIキーは絶対に公開してはいけません
次のコマンドでコンテナを起動します.起動の際に$HOME/dataと$HOME/datasetをマウントしていますが,不必要なら消してください
bash cmd/docker.sh build # イメージのビルド
bash cmd/docker.sh shell # コンテナの起動
依存パッケージ一覧.Docker環境がない場合は手動で入れましょう
torch==2.0.0
pytorch-lightning==2.2.3
wandb==0.16.6
click==8.1.7
jupyter==1.0.0
ipykernel==6.29.4
Transformerモデルの構築 (コード)
Transformerのモデルは @gensal さんの記事からお借りしました.Attention is All You Needの図の通りの実装なので理解しやすいかと思います
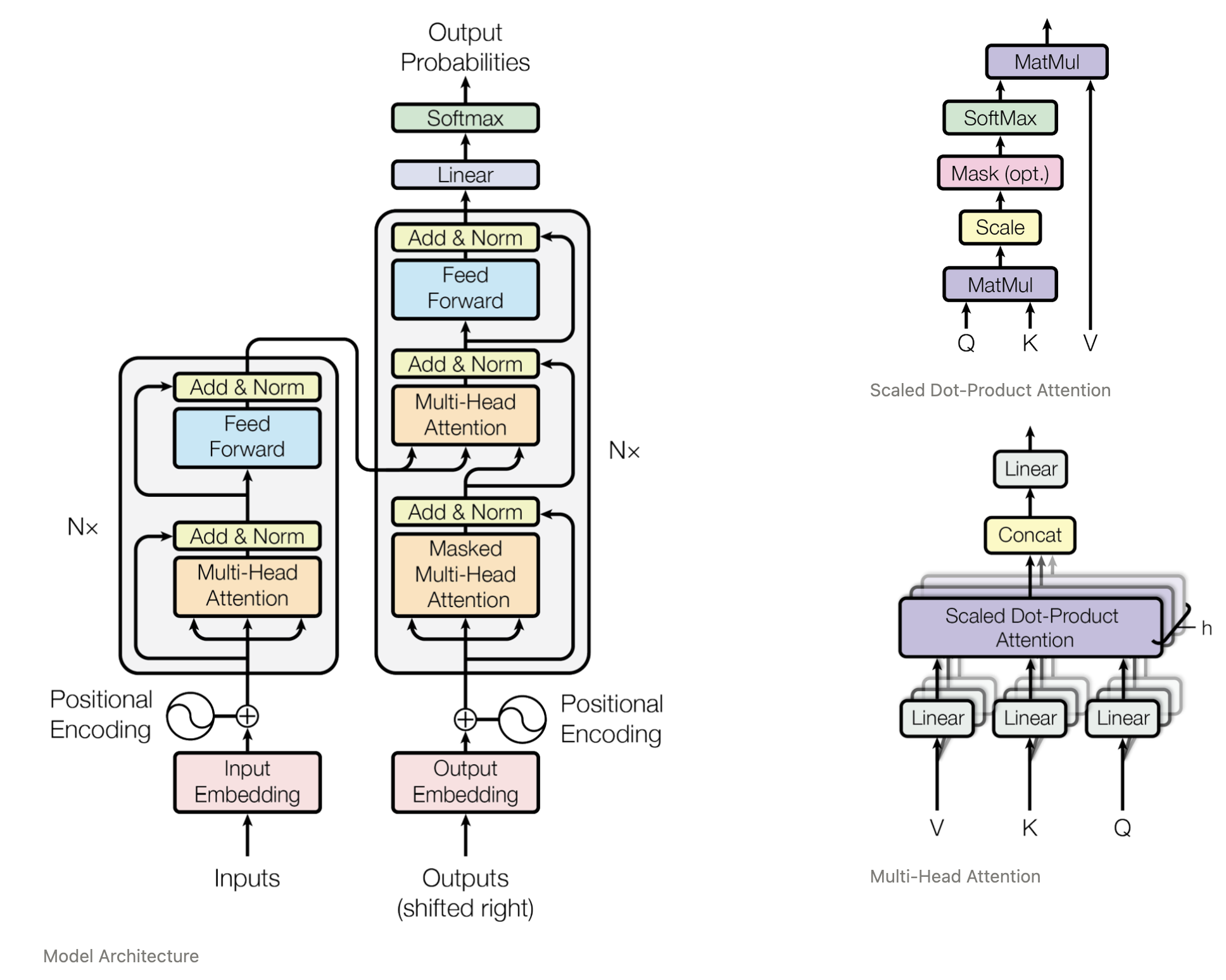
図を見ながら実装をながめたい方はこちら
PyTorch Lightningでの学習
PyTorch Lightningはモデルの学習フローを整理するためのラッパーライブラリです
「何epochだけfor文を回して」,「dataloaderからバッチを取り出して」,「損失を逆伝播して」 みたいな処理をつらつら書くのではなく,あるクラスにそれぞれの処理をメソッドとして登録することで実装します
使い方は @ground0state さんの記事が参考になります
今回の勉強会で扱うタスク
0 ~ 9からランダムに選んだ数字のペアからその間の連番を予測するタスクを選びました.非常に簡単なタスクなので学習する価値はあまり無いです
データセットの実装 (コード)
トークンには0~9の数字,開始タグ (11),末尾タグ (12),余白タグ (13) を使っています
1つのバッチには3つのテンソルが含まれます.
- x: ランダムな数字のペア
- dec_input: デコーダへの入力 (targetを一つシフトしたもの)
- target: 予測列
xはself.seq_len,dec_inputとtargetはself.seq_len-1の長さになるように,開始・末尾・余白タグを加えています
class SNDataset(data.Dataset):
############### 一部省略しています ####################
def __init__(self, num_categories, seq_len, size):
super().__init__()
self.num_categories = num_categories # トークンの種類 (今回は0 ~ 9なので10)
self.seq_len = seq_len # トークン長
self.size = size # データセットのデータ数
# 良くない実装だが今回はこれで割り当てる
self.prefix = num_categories + 1 # 開始トークン
self.suffix = num_categories + 2 # 末尾トークン
self.padding = num_categories + 3 # 余白トークン
# ランダムな整数のペアを作成
self.data = torch.randint(self.num_categories, size=(self.size, 2))
def __getitem__(self, idx):
x = self.data[idx]
# x[0] から x[1] までの連続した整数を生成
if x[0] < x[1]:
y = torch.arange(x[0].item(), x[1].item() + 1)
elif x[0] == x[1]:
y = torch.tensor([x[0].item()])
else:
y = torch.flip(torch.arange(x[1].item(), x[0].item() + 1), dims=(0,))
# suffixとprefixを追加
prefix = torch.tensor([self.prefix])
suffix = torch.tensor([self.suffix])
x = torch.cat([prefix, x, suffix], dim=0)
y = torch.cat([prefix, y, suffix], dim=0)
# padding
x = F.pad(x, (0, self.seq_len - x.size(0)), value=self.padding)
y = F.pad(y, (0, self.seq_len - y.size(0)), value=self.padding)
dec_input = y[:-1] # decoderへの入力 (1つシフトする)
target = y[1:] # 正解ラベル
return x, dec_input, target
Lightning Moduleの実装 (コード)
PyTorch Lightningで学習するためのクラス (Lightning Module) を実装します.
pytorch_lightning.LightningModuleを継承し,実装したい処理に対応するメソッドをオーバーライドすることで実装できます.後述するTrainer.fit関数にLightning Moduleを渡すと,内部でtraining_stepに書いたコードなどが呼ばれる仕組みです
import pytorch_lightning as pl
class TransformerLightning(pl.LightningModule):
############### 一部省略しています ####################
def __init__(self, model, lr, dec_vocab_size, mask_size):
super().__init__()
self.model = model # Transformerモデル
self.lr = lr # 学習率 (面倒なのでスケジューラを実装してないので固定)
self.dec_vocab_size = dec_vocab_size # decoderのボキャブラリの総数
self.mask_size = mask_size # decoderのマスクサイズ
def configure_optimizers(self):
"""Optimizerを設定する"""
optimizer = torch.optim.Adam(self.parameters(), lr=self.lr)
return optimizer
def _calculate_loss(self, batch):
"""lossの計算はtrain/test/valで共通するので分離する"""
x, dec_input, target = batch
# マスクを作成
mask = nn.Transformer.generate_square_subsequent_mask(self.mask_size).to(self.device)
# モデルへ入力
dec_output = self.model(x, dec_input, mask)
# 損失を計算
target = F.one_hot(target, self.dec_vocab_size).to(torch.float32)
loss = F.cross_entropy(target=target, input=dec_output)
return loss
def training_step(self, batch, batch_idx):
"""trainステップ Trainer.fit(*)で呼ばれる lossを返すとbackwardされるように内部で実装されている"""
loss = self._calculate_loss(batch)
self.log("train/loss", loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)
return loss
def validation_step(self, batch, batch_idx):
"""validationステップ Trainer.fit(*)で呼ばれる"""
loss = self._calculate_loss(batch)
self.log("val/loss", loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)
def test_step(self, batch, batch_idx):
"""testステップ Trainer.test(*)で呼ばれる"""
loss = self._calculate_loss(batch)
self.log("test/loss", loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)
Lightning Moduleの学習 (コード)
Lightning ModuleはTrainer.fit関数に渡すだけで学習を回せます.Trainerはloggerや実験の設定などを渡して初期化します
def main(accelerator, devices, lr, max_epochs, num_datas, num_heads, dim, batch_size, debug):
############### 一部省略しています ####################
# 実験の設定
exp_name = f"sn-data-{num_datas}-head{num_heads}-dim{dim}-lr{lr}" # 実験名
device = "cuda" if devices is not None else "cpu"
config = click.get_current_context().params # コマンドライン引数を辞書として保持しておく
# データセットの設定
num_categories = 10 # vocab (今回は0 ~ 9)
seq_len = 16 # 系列長は16で揃える
vocab_size = num_categories + 4 # 0 ~ 9 + 開始/終了/余白タグ と 偶数にするために+1
assert seq_len > vocab_size, "今回はseq_lenがvocab_sizeより大きいことを想定"
# dataloaderを作成
dataset = partial(SNDataset, num_categories, seq_len)
train_loader = DataLoader(dataset(num_datas), batch_size=batch_size, shuffle=True, drop_last=True, pin_memory=True, num_workers=4)
val_loader = DataLoader(dataset(5000), batch_size=batch_size, num_workers=4)
test_loader = DataLoader(dataset(10000), batch_size=batch_size, num_workers=4)
# modelを作成
model = Transformer(device=device,
enc_vocab_size=vocab_size,
dec_vocab_size=vocab_size,
dim=dim,
num_heads=num_heads).to(device)
model_lightning = TransformerLightning(model=model,
lr=lr,
dec_vocab_size=vocab_size,
mask_size=vocab_size + 1)
# loggerを作成
wandb_logger = WandbLogger(project="transformer-study", # w&bのprojectに対応
name=exp_name, # w&bのrunsに対応
save_dir="logs/", # このディレクトリはgit管理から外しましょう
tags=["debug" if debug else "run"],
save_code=True)
wandb_logger.log_hyperparams(config) # ここでコマンドライン引数を渡すとログを見る際に便利
# モデルを保存する関数. コールバック関数としてTrainerに渡す
checkpoint_callback = ModelCheckpoint(dirpath=f"ckpts/{exp_name}",
monitor="val/loss_epoch", # validation lossを監視して
mode="min", # lossが小さいモデルを
save_top_k=10, # 10個保持しておく
filename="{epoch}") # モデル名は{epoch}とする
# Trainerを作成
trainer = Trainer(logger=wandb_logger,
devices=devices,
accelerator=accelerator,
deterministic=False, # 再現性のために本来はtrueにするべき
max_epochs=max_epochs,
callbacks=[checkpoint_callback])
# Train
trainer.fit(model_lightning, train_dataloaders=train_loader, val_dataloaders=val_loader)
# Test
trainer.test(model_lightning, test_loader)
if __name__ == "__main__":
main()
W & Bを使った学習のロギング
W & B (Weight & Biases) は学習ログの可視化サービスです.APIキーを設定するだけでpythonから呼び出せます.(今回は冒頭で環境変数として設定しました)
今回はPyTorch Lightningに実装されているWandbLoggerクラスを使用していますが,公式のwandbパッケージを使用しても非常に簡単にログを出力できます
wandb_logger = WandbLogger(project="transformer-study", # w&bのprojectに対応
name=exp_name, # w&bのrunsに対応
save_dir="logs/", # このディレクトリはgit管理から外しましょう
tags=["debug" if debug else "run"],
save_code=True)
wandb_logger.log_hyperparams(config) # ここでコマンドライン引数を渡すとログを見る際に便利
trainer = Trainer(logger=wandb_logger,
devices=devices,
accelerator=accelerator,
deterministic=False, # 再現性のために本来はtrueにするべき
max_epochs=max_epochs,
callbacks=[checkpoint_callback])
W & Bはブラウザから学習ログを確認できるため,GPUサーバーで回した学習結果も確認しやすいです.また,Slackインテグレーションを利用すれば学習が終了した際に通知を送ることもできます
ログの確認方法は後述します
Clickを使ったコマンドライン解析 (コード)
clickはコマンドラインパーサです.コマンドライン引数を受け取ってpythonのプログラム内で扱う役割があります
研究に使うプロジェクトではコマンドラインからpythonプログラムを実行するようにしましょう.くれぐれもノートブック一つをgithubで公開することが無いように
Pythonのコマンドラインパーサとして有名なのはargparseだと思いますが,今回はclickを使用します
argparseでは,args.arg1のように引数を参照しますが,シンタックスチェックが効かないので一文字でも引数名を間違えて参照すると発見が難しいバグになります
clickでは,コマンドライン引数を関数の引数として展開してくれるので扱いやすいです
import click
@click.command()
@click.option("--accelerator", default="gpu", help="accelerator for training [gpu|cpu|tpu|ipu|None] (default: gpu)")
@click.option("--devices", default="1", help="number of devices (default: 1)")
@click.option("--lr", default=0.0001, help="learning rate")
@click.option("--max_epochs", default=100, help="epoch")
@click.option("--num_datas", default=50000, help="data数")
@click.option("--batch_size", default=128, help="batch size")
@click.option("--num_heads", default=1, help="Headの数")
@click.option("--dim", default=32, help="embedding dimension")
@click.option("--debug", is_flag=True, help="デバックモードで実行")
def main(accelerator, devices, lr, max_epochs, num_datas, num_heads, dim, batch_size, debug):
実行時は次のようにコマンドライン引数を渡します.なお,デフォルト値を指定した引数は省略できます
python3 train.py \
--accelerator gpu \
--devices 1 \
--batch_size 256 \
--num_datas 50000 \
--max_epochs 10 \
--lr 0.0001 \
--num_heads 8 \
--dim 512
引数が多い場合やblackを使用している場合には,clickは大変読みにくいのでargparseを使うようにしましょう
学習と可視化
学習スクリプトtrain.shを実行します.上のコマンドと同じものです
bash cmd/train.sh
W & Bにアクセスして学習のログを見てみましょう.Projects > transformer-study (今回指定したプロジェクト名) > Workspaceからログが確認できます
全然学習が進んでいませんが,lossが小さいモデルを使えば若干の精度が出ます.今回はモデルの改善までは扱いません

特定のRunを選択すれば,コマンドライン引数やCLI出力なども確認できます.また,ここで定義したコマンドライン引数を使って過去のRunをフィルタリングすることも出来ます

学習が終了した際にslackに通知を送ることも出来ます

推論 (コード)
最後に学習済みのモデルで推論を回してみます.今回は貪欲法によるサンプリングを実装しました
- デコーダの入力dec_inputを余白タグで埋める
- dec_input[0]を開始タグに置き換えて,1番目のトークンを予測する
- dec_input[1]を予測したトークンに置き換えて,2番目のトークンを予測する
- シーケンス長になるまで (あるいは末尾トークンが出力されるまで) 繰り返す
x, _, target = next(iter(test_loader))
# decoderへの入力を作成
dec_input = torch.full_like(target, num_categories + 3) # 余白タグで埋める
dec_input[:, 0] = num_categories + 1 # 先頭を開始タグにする
# マスクを作成
mask = nn.Transformer.generate_square_subsequent_mask(vocab_size + 1).to(device)
# 貪欲法でサンプリング
x, dec_input, target = x.to(device), dec_input.to(device), target.to(device)
for i in range(seq_len - 2):
dec_output = model_lightning.model(x, dec_input, mask) # 推論
dec_output = F.softmax(dec_output, dim=-1) # i+1番目の数字を予測
dec_input[:, i + 1] = dec_output.argmax(dim=-1)[:, i] # dec_inputのi+1番目を予測した数字で埋める
# dec_inputにpaddingをつけたものがpredictionとなる
# (targetのseq_lenが十分長いので末尾は必ずpaddingになる)
prediction = torch.cat([dec_input[:, 1:], torch.tensor([[num_categories + 3]]).to(device)], dim=1)
# 結果
print(f"x : {x.tolist()}")
print(f"dec_input : {dec_input.tolist()}")
print(f"target : {target.tolist()}")
print(f"prediction : {prediction.tolist()}")
print(f"accuracy : {torch.sum(prediction == target) / (seq_len - 1):.4}")
print(f"chance rate : {1 / seq_len:.4}")
実行結果はこんな感じです.少しだけ学習できています
x : [[11, 8, 4, 12, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13]]
dec_input : [[11, 8, 7, 6, 5, 4, 3, 2, 12, 13, 13, 13, 13, 13, 13]]
target : [[8, 7, 6, 5, 4, 12, 13, 13, 13, 13, 13, 13, 13, 13, 13]]
prediction : [[8, 7, 6, 5, 4, 3, 2, 12, 13, 13, 13, 13, 13, 13, 13]]
accuracy : 0.8
chance rate : 0.0625
以上です.何かあればTwitterまで
参考
モデル構築の引用元
https://qiita.com/gensal/items/e1c4a34dbfd0d7449099
DatasetとLightning Moduleの実装の参考
https://github.com/i14kwmr/practice-transformer/tree/main