
はじめに
PyTorch Lightningは生PyTorchで書かなければならない学習ループやバリデーションループ等を各hookのメソッドとして整理したフレームワークです。他にもGPUの制御やコールバックといった処理もフレームワークに含み、可読性や学習の再現性を上げています。
hookには次のようなものが存在します。
class LitModel(pl.LightningModule):
def __init__(...):
def forward(...):
def training_step(...)
def training_step_end(...)
def training_epoch_end(...)
def validation_step(...)
def validation_step_end(...)
def validation_epoch_end(...)
def test_step(...)
def test_step_end(...)
def test_epoch_end(...)
def configure_optimizers(...)
def any_extra_hook(...)
学習のループを各hookに分解する様子は、こちらの画像が分かりやすいです。動画もあります。
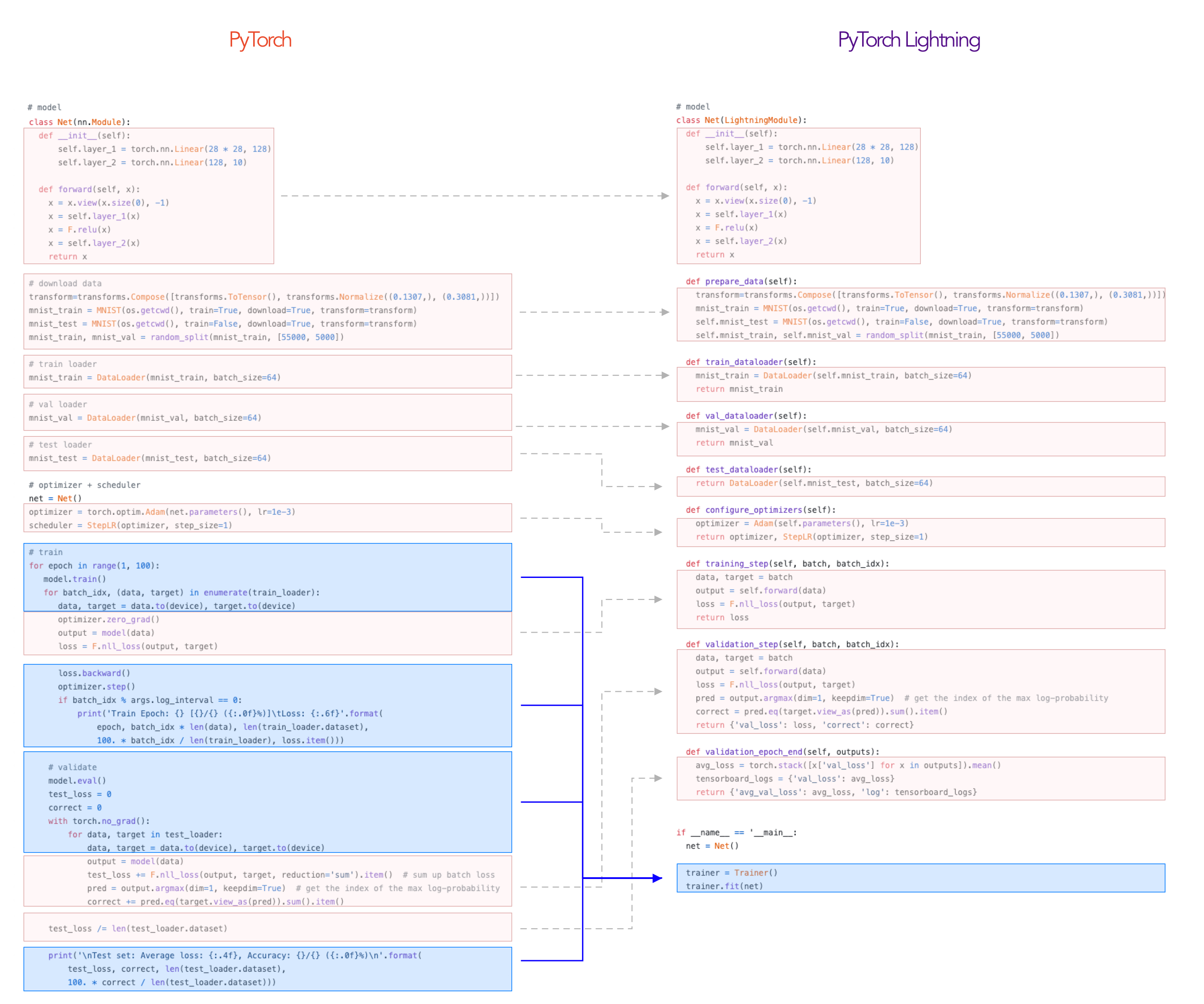
ということで、PyTorch LightningのAPIについて見てみましょう。
実践的な使い方は参考文献3の解説記事がとても分かりやすいです。
参考文献
概要
PyTorch Lightningは最小で二つのモジュールが分かれば良いです。LightningModuleとTrainerです。LightningModuleはtorch.nn.Moduleの拡張のようなクラスで、modelを作成するのに使用します。Trainerは学習のループを実行します。
さらに、データローダーを生成するのにLightningDataModuleを使用すると便利です。モデルの保存やEarly StoppingはCallbackを使用します。
pytorch_lightning.LightningModule
LightningModuleを継承したモデルクラスを作成します。torch.nn.Moduleの作成と似ていますが、ニューラルネットワークのmodelを定義するだけでなく、バッチに対するlossの計算、optimizerまで定義するクラスになっています。作成したモデルをTrainerクラスに渡してfitメソッドで学習を行います。
import os
import torch
from torch import nn
import torch.nn.functional as F
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader, random_split
from torchvision import transforms
import pytorch_lightning as pl
class LitAutoEncoder(pl.LightningModule):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 64),
nn.ReLU(),
nn.Linear(64, 3)
)
self.decoder = nn.Sequential(
nn.Linear(3, 64),
nn.ReLU(),
nn.Linear(64, 28*28)
)
def forward(self, x):
# in lightning, forward defines the prediction/inference actions
embedding = self.encoder(x)
return embedding
def training_step(self, batch, batch_idx):
# training_step defined the train loop.
# It is independent of forward
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = F.mse_loss(x_hat, x)
# Logging to TensorBoard by default
self.log('train_loss', loss)
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=1e-3)
return optimizer
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
train, val = random_split(dataset, [55000, 5000])
autoencoder = LitAutoEncoder()
trainer = pl.Trainer()
trainer.fit(autoencoder, DataLoader(train), DataLoader(val))
LightningModuleクラスを継承して、学習の動作をプログラムします。LightningModuleクラスは様々なメソッドを持っており、それらをオーバーライドして使用します。主に、次のコアなメソッドを使用します。
| メソッド | 必須 | 内容 |
|---|---|---|
| __init__(*args, **kwargs) | modelやcriterionなどをクラス変数として設定する。 | |
| forward(*args, **kwargs) | nn.Moduleのforwardと同じだが、主に予測で使用する。クラス内ではself(batch)として呼び出される。 |
|
| training_step(batch, batch_idx, optimizer_idx, hiddens) | ○ | DataLaoderをイテレーションして出力したbatchを引数として受け取り、criterionで計算したlossをreturnする。forwardとは独立したメソッド。 |
| validation_step(batch, batch_idx, dataloader_idx) | DataLaoderをイテレーションして出力したbatchを引数として受け取り、メトリックを計算する。 | |
| test_step(batch, batch_idx, dataloader_idx) | DataLaoderをイテレーションして出力したbatchを引数として受け取り、メトリックを計算する。テストデータに対する精度の評価に使用する。テストのラベルを与えられないコンペでは使用しない。 | |
| configure_optimizers() | ○ | optimizerをreturnする。schedulerを使用する場合はreturnをoptimizerのリストとschedulerのリストのタプルとする。 |
ほぼ確実に使うであろう、他のメソッドも紹介します。
| メソッド | 必須 | 内容 |
|---|---|---|
| training_epoch_end(outputs) | 1エポック終わった後の処理をする。各バッチのtraining_stepでreturnした値リストを引数に受け取る。バッチ全体のlossの平均をとったり、バッチ全体の出力を使用して評価指標を計算したりする。 | |
| validation_epoch_end(outputs) | 1エポック終わった後の処理をする。各バッチのvalidation_stepでreturnした値のリストを引数に受け取る。バッチ全体のlossの平均をとったり、バッチ全体の出力を使用して評価指標を計算したりする。 |
さらに細かいステップでのメソッドもあります。いくつかありますが、下記を紹介します。
| メソッド | 必須 | 内容 |
|---|---|---|
| backward(loss, optimizer, optimizer_idx, *args, **kwargs) | デフォルトはloss.backward()です。 |
|
| on_after_backward() |
loss.backward()の後、optmizer.step()の前のタイミング。デフォルトでは何もしない。 |
|
| optimizer_zero_grad | デフォルトはoptimizer.zero_grad()です。 |
LightningModuleクラスのメソッドとしては定義されていませんが、補助として下記のメソッドを用意して、__init__で呼び出すと便利です。クラスのメソッドとして実装しなくても大丈夫です。
| メソッド | 必須 | 内容 |
|---|---|---|
| create_model() | ニューラルネットワークのmodelをreturnします。 | |
| create_criterion() | Loss Functionsをreturnします。 |
LightningModuleクラスはデフォルトでLoggerを実装しており、各メソッドの中でlogメソッドでスカラー値のログを取る事ができます。辞書型のログはlog_dictを使用します。
def training_step(self, batch, batch_idx):
self.log('my_metric', x)
# or a dict
def training_step(self, batch, batch_idx):
values = {'loss': loss, 'acc': acc, ..., 'metric_n': metric_n}
self.log_dict(values)
ロガー独特のメソッドを持つ場合は、ロガーを直接呼び出します。
from pytorch_lightning.loggers import TensorBoardLogger, TestTubeLogger
logger1 = TensorBoardLogger('tb_logs', name='my_model')
logger2 = TestTubeLogger('tb_logs', name='my_model')
trainer = Trainer(logger=[logger1, logger2])
class MyModule(LightningModule):
def any_lightning_module_function_or_hook(self):
some_img = fake_image()
# Option 1
self.logger.experiment[0].add_image('generated_images', some_img, 0)
# Option 2
self.logger[0].experiment.add_image('generated_images', some_img, 0)
pytorch_lightning.Trainer
Trainerは、学習ループを処理します。データやモデルをGPUに配置したり、学習・バリデーション・テストの実行、コールバックの実行を管理します。
from argparse import ArgumentParser
def main(hparams):
model = LightningModule()
trainer = Trainer(gpus=hparams.gpus)
trainer.fit(model)
if __name__ == '__main__':
parser = ArgumentParser()
parser.add_argument('--gpus', default=None)
args = parser.parse_args()
main(args)
__init__の引数がとても多いので、主に使用するものを紹介します。
| 引数 | 必須 | 内容 |
|---|---|---|
| max_epochs | 最大エポック数。 | |
| min_epochs | 最小エポック数。この数までは強制的に学習させる。 | |
| max_time | 実行する最大時間。Timerコールバックでも同様の設定が可能。 |
|
| gpus | 使用するGPUの数。 | |
| callbacks | コールバックのリスト。 | |
| logger | Loggerのリスト。 | |
| limit_train_batches | 学習で使用するデータの割合を指定する。デバッグ等で使用する。 | |
| limit_val_batches | バリデーションで使用するデータの割合を指定する。デバッグ等で使用する。 | |
| deterministic | 非決定論的アルゴリズムを使用するかを決める。 | |
| default_root_dir | logやweightの保存先のデフォルトルート。各ロガーで指定したパスが優先される。 | |
| fast_dev_run | 1エポックのみの実行モードになり、学習・バリデーション・テストで実行するバッチ数を指定。デバッグで使用する。これが有効のときはロガー、コールバック、チューナーは実行されない。 | |
| flush_logs_every_n_steps | ログをディスクに書き込む頻度。 | |
| gradient_clip_val | 勾配のクリッピングの値を指定。 | |
| log_every_n_steps | ログをとる頻度。 | |
| precision | 学習の小数の精度を指定。CPUでは16-bitはサポートされていない。 |
主に使用するメソッドは下記のとおりです。
| メソッド | 内容 |
|---|---|
| fit(model, train_dataloaders=None, val_dataloaders=None, datamodule=None, train_dataloader=None) | 学習の実行。dataloaderを直接渡してもよいが、管理のためにLightningDataModuleを継承したdatamoduleを渡すほうが良い。 |
| validate(model=None, dataloaders=None, ckpt_path='best', verbose=True, datamodule=None, val_dataloaders=None) | 1エポックだけバリデーションを実行する。 |
| test(model=None, dataloaders=None, ckpt_path='best', verbose=True, datamodule=None, test_dataloaders=None) | 1エポックだけテストを実行する。 |
| predict(model=None, dataloaders=None, datamodule=None, return_predictions=None, ckpt_path='best') | modelのforwardをコールする。 |
また、知っていると便利なTrainerクラスが持っているプロパティです。
| プロパティ | 内容 |
|---|---|
| log_dir | 現在の実験のディレクトリ。 |
| current_epoch | 現在のエポック。 |
pytorch_lightning.LightningDataModule
各種dataloaderを定義するクラスです。オプションのモジュールですが、dataloaderの再現性のために作成すると良いでしょう。Trainerに渡して使用します。
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, data_dir: str = "path/to/dir", batch_size: int = 32):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
def setup(self, stage: Optional[str] = None):
self.mnist_test = MNIST(self.data_dir, train=False)
mnist_full = MNIST(self.data_dir, train=True)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=self.batch_size)
def val_dataloader(self):
return DataLoader(self.mnist_val, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=self.batch_size)
def teardown(self, stage: Optional[str] = None):
# Used to clean-up when the run is finished
...
mnist = MNISTDataModule(my_path)
model = LitClassifier()
trainer = Trainer()
trainer.fit(model, mnist)
LightningDataModuleクラスを継承して、データの準備をプログラムしていきます。主に、次のメソッドを実装します。
| メソッド | 必須 | 内容 |
|---|---|---|
| __init__(train_transforms, val_transforms, test_transforms, dims) | transformsやデータの次元をクラス変数に設定する。 | |
| prepare_data() | データのダウンロード等を行う。 | |
| setup() | train/val/test splitを行う。 | |
| train_dataloader() | train_dataloaderをreturnする。 | |
| val_dataloader() | val_dataloaderをreturnする。 | |
| test_dataloader() | test_dataloaderをreturnする。 | |
| teardown() | fitまたはtestの後に行う処理。主に複数GPU並列処理の後処理に使用される。 |
このクラスはデータに関する情報が含まれるクラスで、Configurationに強く依存するため、Configクラスのようなものを作り、クラス変数に持たせると良いかもしれません。
また、train/valのsplitは、foldを指定出来るようにしておくと、長時間の学習が必要なケースのときに便利です。参考文献3を参照してください。
pytorch_lightning.Callbacks
公式ドキュメントはこちら。
代表的なコールバックを紹介します。
モデルを保存するクラスpytorch_lightning.callbacks.ModelCheckpointです。
ModelCheckpoint(
dirpath=None,
filename=None,
monitor=None,
verbose=False,
save_last=None,
save_top_k=1,
save_weights_only=False,
mode='min',
auto_insert_metric_name=True,
every_n_train_steps=None,
train_time_interval=None,
every_n_epochs=None,
save_on_train_epoch_end=None,
period=None,
every_n_val_epochs=None)
)
モデルの汎化性能が上がらないときに学習学習を打ち切るpytorch_lightning.callbacks.EarlyStoppingです。
EarlyStopping(
monitor=None,
min_delta=0.0,
patience=3,
verbose=False,
mode='min',
strict=True,
check_finite=True,
stopping_threshold=None,
divergence_threshold=None,
check_on_train_epoch_end=True
)
コールバックを自作する場合はpytorch_lightning.callbacks.Callbackを継承し、学習ループ中のhookに該当する抽象メソッドをオーバーライドします。hookはたくさんあるので、こちらの動画でhookの位置を確認しつつ、ソースを見ながら確認したほうが良さそうです。
class Callback(abc.ABC):
r"""
Abstract base class used to build new callbacks.
Subclass this class and override any of the relevant hooks
"""
def on_configure_sharded_model(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called before configure sharded model"""
def on_before_accelerator_backend_setup(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called before accelerator is being setup"""
pass
def setup(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule', stage: Optional[str] = None) -> None:
"""Called when fit, validate, test, predict, or tune begins"""
pass
def teardown(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule', stage: Optional[str] = None) -> None:
"""Called when fit, validate, test, predict, or tune ends"""
pass
def on_init_start(self, trainer: 'pl.Trainer') -> None:
"""Called when the trainer initialization begins, model has not yet been set."""
pass
def on_init_end(self, trainer: 'pl.Trainer') -> None:
"""Called when the trainer initialization ends, model has not yet been set."""
pass
def on_fit_start(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when fit begins"""
pass
def on_fit_end(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when fit ends"""
pass
def on_sanity_check_start(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the validation sanity check starts."""
pass
def on_sanity_check_end(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the validation sanity check ends."""
pass
def on_train_batch_start(
self,
trainer: 'pl.Trainer',
pl_module: 'pl.LightningModule',
batch: Any,
batch_idx: int,
dataloader_idx: int,
) -> None:
"""Called when the train batch begins."""
pass
def on_train_batch_end(
self,
trainer: 'pl.Trainer',
pl_module: 'pl.LightningModule',
outputs: STEP_OUTPUT,
batch: Any,
batch_idx: int,
dataloader_idx: int,
) -> None:
"""Called when the train batch ends."""
pass
def on_train_epoch_start(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the train epoch begins."""
pass
def on_train_epoch_end(
self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule', unused: Optional = None
) -> None:
"""Called when the train epoch ends.
To access all batch outputs at the end of the epoch, either:
1. Implement `training_epoch_end` in the `LightningModule` and access outputs via the module OR
2. Cache data across train batch hooks inside the callback implementation to post-process in this hook.
"""
pass
def on_validation_epoch_start(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the val epoch begins."""
pass
def on_validation_epoch_end(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the val epoch ends."""
pass
def on_test_epoch_start(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the test epoch begins."""
pass
def on_test_epoch_end(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the test epoch ends."""
pass
def on_predict_epoch_start(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the predict epoch begins."""
pass
def on_predict_epoch_end(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule', outputs: List[Any]) -> None:
"""Called when the predict epoch ends."""
pass
def on_epoch_start(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when either of train/val/test epoch begins."""
pass
def on_epoch_end(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when either of train/val/test epoch ends."""
pass
def on_batch_start(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the training batch begins."""
pass
def on_validation_batch_start(
self,
trainer: 'pl.Trainer',
pl_module: 'pl.LightningModule',
batch: Any,
batch_idx: int,
dataloader_idx: int,
) -> None:
"""Called when the validation batch begins."""
pass
def on_validation_batch_end(
self,
trainer: 'pl.Trainer',
pl_module: 'pl.LightningModule',
outputs: Optional[STEP_OUTPUT],
batch: Any,
batch_idx: int,
dataloader_idx: int,
) -> None:
"""Called when the validation batch ends."""
pass
def on_test_batch_start(
self,
trainer: 'pl.Trainer',
pl_module: 'pl.LightningModule',
batch: Any,
batch_idx: int,
dataloader_idx: int,
) -> None:
"""Called when the test batch begins."""
pass
def on_test_batch_end(
self,
trainer: 'pl.Trainer',
pl_module: 'pl.LightningModule',
outputs: Optional[STEP_OUTPUT],
batch: Any,
batch_idx: int,
dataloader_idx: int,
) -> None:
"""Called when the test batch ends."""
pass
def on_predict_batch_start(
self,
trainer: 'pl.Trainer',
pl_module: 'pl.LightningModule',
batch: Any,
batch_idx: int,
dataloader_idx: int,
) -> None:
"""Called when the predict batch begins."""
pass
def on_predict_batch_end(
self,
trainer: 'pl.Trainer',
pl_module: 'pl.LightningModule',
outputs: Any,
batch: Any,
batch_idx: int,
dataloader_idx: int,
) -> None:
"""Called when the predict batch ends."""
pass
def on_batch_end(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the training batch ends."""
pass
def on_train_start(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the train begins."""
pass
def on_train_end(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the train ends."""
pass
def on_pretrain_routine_start(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the pretrain routine begins."""
pass
def on_pretrain_routine_end(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the pretrain routine ends."""
pass
def on_validation_start(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the validation loop begins."""
pass
def on_validation_end(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the validation loop ends."""
pass
def on_test_start(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the test begins."""
pass
def on_test_end(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the test ends."""
pass
def on_predict_start(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the predict begins."""
pass
def on_predict_end(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when predict ends."""
pass
def on_keyboard_interrupt(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called when the training is interrupted by ``KeyboardInterrupt``."""
pass
def on_save_checkpoint(
self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule', checkpoint: Dict[str, Any]
) -> dict:
"""
Called when saving a model checkpoint, use to persist state.
Args:
trainer: the current :class:`~pytorch_lightning.trainer.Trainer` instance.
pl_module: the current :class:`~pytorch_lightning.core.lightning.LightningModule` instance.
checkpoint: the checkpoint dictionary that will be saved.
Returns:
The callback state.
"""
pass
def on_load_checkpoint(
self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule', callback_state: Dict[str, Any]
) -> None:
"""Called when loading a model checkpoint, use to reload state.
Args:
trainer: the current :class:`~pytorch_lightning.trainer.Trainer` instance.
pl_module: the current :class:`~pytorch_lightning.core.lightning.LightningModule` instance.
callback_state: the callback state returned by ``on_save_checkpoint``.
Note:
The ``on_load_checkpoint`` won't be called with an undefined state.
If your ``on_load_checkpoint`` hook behavior doesn't rely on a state,
you will still need to override ``on_save_checkpoint`` to return a ``dummy state``.
"""
pass
def on_before_backward(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule', loss: torch.Tensor) -> None:
"""Called before ``loss.backward()``."""
pass
def on_after_backward(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule') -> None:
"""Called after ``loss.backward()`` and before optimizers are stepped."""
pass
def on_before_optimizer_step(
self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule', optimizer: Optimizer, opt_idx: int
) -> None:
"""Called before ``optimizer.step()``."""
pass
def on_before_zero_grad(self, trainer: 'pl.Trainer', pl_module: 'pl.LightningModule', optimizer: Optimizer) -> None:
"""Called after ``optimizer.step()`` and before ``optimizer.zero_grad()``."""
pass
コールバック作成/使用のベストプラクティスは下記です。
- コールバックは機能的に分離されていなければなりません。
- コールバックは、他のコールバックの動作に依存してはいけません。
- コールバックから手動でメソッドを呼び出さないでください。
- メソッドを直接呼び出すこと(例:on_validation_end)は強く推奨しません。
- 可能な限り、コールバックの実行順序に依存しないようにしてください。
Metrics
便利なメトリクスがTorchMetricsというパッケージにまとめられているようです。
おわりに
頑張って公式ドキュメントを読もう!