大変だったから誰か褒めて欲しいナリ。(承認欲求)
概要
- Object Detection(物体認識)モデルの中でも有名な YOLO を、TensorFlow, PyTorch とかの色んな Deep Learning Framework で動くように変換してみたよ
- 変換しても精度はそんなに変わんなかったよ(安心)
- 速度的には ONNX サイコーなんで、PyTorch でコーディングし学習して、そして ONNX に変換してデプロイするのが個人的にはオススメ
- 性能と速度のパランスから言うと、モデル的には yolov5m あたりが丁度良いんじゃないかな
モチベーション
Object Detection は色々楽しい。写真に写っているものを認識させるのも楽しいし、カメラのストリーミング画像を認識させるのも楽しい。でも最近のモデルは(当たり前だけど) GPU パワーが無いと動かせないほど重かったりする。
俺、金無いから GPU なんて持ってない。
そこで、CPU で動かすことを前提に、どのフレームワークで動かすのが良いのか(速いのか)調べてみた。
そして変換するといつも思うけど、「変換して精度が落ちたらどうしよう」というのが心配。実際にほんのちょっとだけ結果が違ったりもする。果たして変換したら本当に精度が落ちるのかも調べた。
世に数多ある Object Detection モデル全部をやるのは到底無理なんで、一番有名な YOLO に対象を絞り、自分で変換して実際に動かしてみたというお話。
とても簡単な YOLO の説明
YOLO (You Only Look Once) は、有名な Object Detection モデルの実装のひとつ(論文)。
一番単純な Object Detection モデルの実装は以下の方法
- 画像の一部分を切り取って(検出窓)、そこに何が写っているのかを Classification モデルで予測する
- 色んなサイズの検出窓を画像上でスライドさせていき、予測確率が高い窓の部分にその物体が写っているものとする
ただしこれだと、簡単に想像できるように、色々なサイズの窓で画像を何回も走査しなきゃいけない。とても時間がかかる。
この方法の発展形には R-CNN 系のアルゴリズムがある。メチャクチャ簡単に言うと、これらは「色んなサイズの検索窓を画像上で走査させる」代わりに CNN やら何やらを使って高速化する手法。torchvision に Faster R-CNN が組み込まれているんで、簡単に使えるでしょう。(やってないけど)
でも Realtime Object Detection で人気があるのは YOLO や SDD (Single Shot Detector)(だと思う)。
SSD を大いに意訳すると、「検出窓って隣接するピクセルじゃん?だったらそれって隣接する特徴を畳み込む CNN と同じじゃね?んなら、全部ひとつなぎの CNN にしちゃっていんじゃね?」って感じ。誰もそんなこと言ってないけど。
それに対して YOLO は、全体を grid に切って、各 grid でオブジェクトの確率を予測、同じオブジェクトに対して高い確率を示す隣接する grid をまとめて・・・
って要するにみんな CNN なんだよ!
名前だって "Single Shot Detection" やら "You Only Look Once" やら結局同じこと言ってるし、anchor 使うし、階層的に bounding box 出すし、NMS しなきゃいけないし、ぶっちゃけ使っている身としては「どれも大して変わらん」。速くて精度が良けりゃ正義。(身も蓋もない)
しいて YOLO の特徴を言えば、最初に作った人が Darknet っていう C で書かれたフレームワークで作っていて、「Darknet 使ってなきゃ YOLO じゃない」派がいるらしい。実際に YOLO V3 と YOLO V4 は Darknet だけど、YOLO V5 は普通に PyTorch なので、「YOLO V5 は YOLO と認めない!」という論争があるような無いような。俺には関係ないけど。
実装してみた
変換したモデル
- YOLO V3
- yolov3-tiny, yolov3, yolov3-spp
- YOLO V4
- yolov4-tiny, yolov4
- (未実装) yolov4-csp (Scaled YOLOv4)
- (未実装) yolov4x-mish (YOLOv4-large P5)
- YOLO V5
- yolov5s, yolov5m, yolov5l, yolov5x
Realtime Object Detection の現時点(2021/04/08)の SOTA が yolov4-csp なんで、是非動かしてみたいところではあるが、かなりハマっている。本当はこの記事は 4/1 に書こうと思ってたけど、それが1週間伸びたのはこのせい。
対応したフレームワーク
-
torch: PyTorch (state dict を保存したものを読み込んで利用) -
torch_onnx: ONNX (torchから変換) -
onnx_vino: OpenVINO (torch_onnxから変換) -
onnx_tf: TensorFlow (torch_onnxから変換、SavedModel 形式) -
tf: TensorFlow (FrozenGraph形式で保存したものを読み込んで利用) -
tflite: TensorFlow Lite (量子化のレベルとしてfp32,fp16,int8全部生成) -
tf_onnx: ONNX (tfから変換)
ただし、YOLO V3/V4 は tf, tflite, tf_onnx しかやってない。疲れてギブアップ。
バージョンとかの細かい情報は github の README に書いた。
速度の比較
細かい条件は github の README に書いた。100枚の画像で推論した平均時間(msec)。
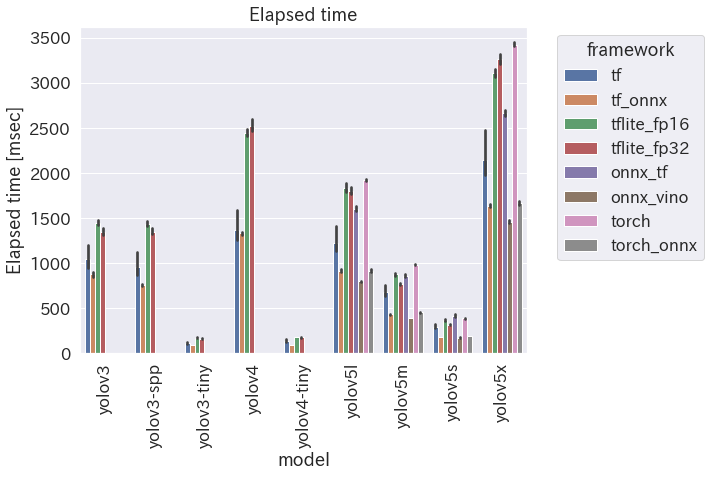
- ONNX 速い! しかも簡単!
- OpenVINO は ONNX よりちょっと速いけど、Intel 製の CPU に限られるし、setup がめんどくさい
- TensorFlow がびっくりするほど速い!
- でもこれは FrozenGraph 形式で読み込んだ場合
- FrozenGraph は TF2.x では obsoleted
- SavedModel 形式はサイズ制限(2GB)があり、一部のモデルでそれを超えたため、仕方なく FrozenGraph で出力した
- 変換のための余計なものが悪さしたのか、俺の実装がヘボなのか・・・
- TensorFlow Lite はそれほど速くない・・・
- int8 量子化の場合を載せてないけど、呆れるほど遅かったから(後述)
個人的に、PyTorch の方が設定が簡単で、モデルの書き方も(TensorFlow 2.x で言うところの Keras の subclassing 形式で)分かりやすく、Lightning とかあるから training のコードも描きやすく、GPU と CPU の変換も簡単、ONNX への変換も公式にサポートされてるので、PyTorch でコード書いて ONNX に変換というのが王道だなぁと思う次第。
精度の比較
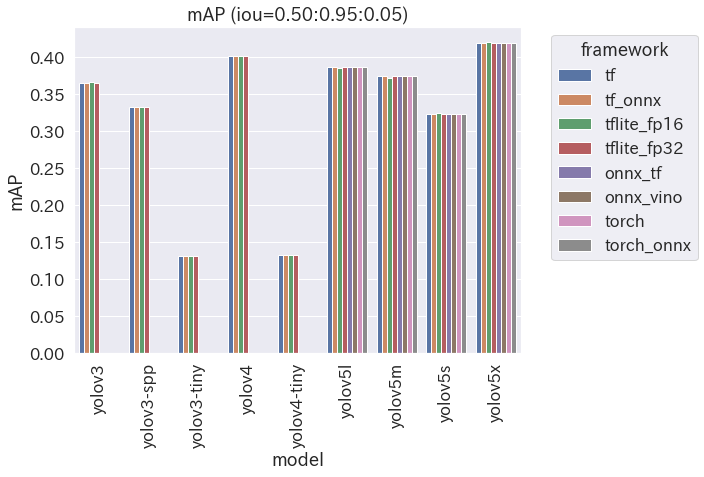
- 見事に横一直線
- ということは、変換しても精度は全く同じということ
- ほんのちょっとだけ値が違うことがあるんで心配したが、どうやら杞憂だった模様
- この杞憂のためだけに mAPを計算するツール を作ったかと思うと、ちょっと泣けてくる・・・
- mAP の勉強になったし、COCO のツールはなぜか Mac で動かんし、という所で無理矢理納得してみる
- 自分で作ったツールで計測した値だし、そもそも画像100枚での結果なんで、値自体はほんの参考に留めておいてください
速度 vs 精度
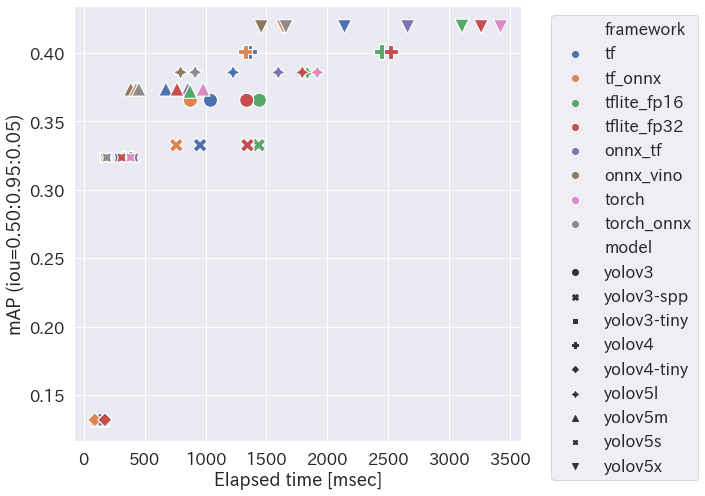
- 速度は左にあるほど速い、精度は上にあるほど良い
- ということで、ちょっと CPU で Object Detection して遊びたいぜ!という場合には yolov5m が丁度良いんじゃないかと思う次第
余談1:もっと Object Detection で遊びたい
上記の実装は、あるディレクトリ下にある画像を一気に変換するものだけど、動画を Object Detection したい、カメラの Streaming 画像を Object Detection したいなんて場合は、下のツールを使えばいいんじゃないかな(宣伝)
わざわざ対応させちゃたよ。TFLite だから、今考えればそれほど速くないんだけどね(白目)
余談2:TensorFlow Lite int8 について
基本的に様々なフレームワークに変換しても、バイナリのサイズはどれも同じ。ただし、TensorFlow Lite だけは量子化しているので、fp32 は同じ、fp16 で半分、int8 だと 1/4 になる。
int8 量子化して、さらに EdgeTPU 向けにコンパイルして TPU を使えば、サイズが小さくて凄い速くて最高!ということになるのだが、そうは簡単に問屋が卸さない。
すげー遅い。計測したくないぐらい遅い。
原因はコンパイルした時のログから明らか。下は yolov3-tiny をコンパイルした場合。
> ./compile_edgetpu.sh yolo/yolov3-tiny_int8.tflite
Edge TPU Compiler version 15.0.340273435
Model compiled successfully in 577 ms.
Input model: /home/yolo/yolov3-tiny_int8.tflite
Input size: 8.58MiB
Output model: /home/yolo/yolov3-tiny_int8_edgetpu.tflite
Output size: 8.70MiB
(省略)
Number of operations that will run on Edge TPU: 2
Number of operations that will run on CPU: 34
Operator Count Status
MAX_POOL_2D 6 More than one subgraph is not supported
QUANTIZE 2 Operation is otherwise supported, but not mapped due to some unspecified limitation
QUANTIZE 1 Mapped to Edge TPU
QUANTIZE 1 More than one subgraph is not supported
CONV_2D 1 Mapped to Edge TPU
CONV_2D 12 More than one subgraph is not supported
RESIZE_NEAREST_NEIGHBOR 1 Operation version not supported
LEAKY_RELU 11 Operation not supported
CONCATENATION 1 More than one subgraph is not supported
ちっとも TPU に乗りやがらねぇ!
そうなってくると、量子化の分だけ逆に CPU のコストがかかるから遅くなって当然。
俺の実装が悪いからかもしれないけど、きっちり TPU に乗る MobileNet v2 SSD と比べると、
- YOLO は入力の画像を 255 で割って 0-1 に正規化してから渡す
- MobileNet v2 SSD は 0-255 のママ
このせいで量子化が上手くいかないんじゃないかな〜と邪推する次第。
だったら 255 で割らないで学習させれば良いんじゃないかと思うけど、そもそも GPU を持ってないからこんな事してる訳で。
なんで、YOLO は TPU に向かない、と思っております。