概要
最近、時系列データの予測ツールとしてProphetなるものの存在を知った。
公式のチュートリアルをやりながら使い方や利点などを紹介していきたい。
Prophetとは?
Metaが公開している時系列データの統計予測モデルである。
言語はRとPythonに対応していて、統計や機械学習などの難しい知識がなくてもサクッと使うことができてとても便利。
使いどころとしては例えば過去の売り上げデータを元に将来の売上データを予測したりできる。
他にも株やFXなどの金融関連の予測だったりさまざまな用途で使えそうだ。
Prophetは複数の項を足し合わせた統計モデルであり、曜日や季節などの周期性も考慮した上で時系列データの予測が可能がある。
パラメータの難しいチューニングがいらないのもいいところ。
機械学習の回帰モデルと何が違う?
機械学習においても過去のデータを元に将来を予測することはよくある。
それはディープラーニングだったり決定木ベースの手法であったりする。
機械学習の場合は将来の「ある時点」における予測値を出したり分類問題に落とし込んだりすることが多いが、周期的な構造を持つ時系列データを再現するのは得意ではない。
なので「時系列データを直接予測したい」場合、Prophetが強い味方となる。
どんな統計モデル?
例えば過去のデータを直線でfittingするのも一種の予測モデルと言えるが、当然精度は微妙だろう。
n次関数とかにすれば精度は上がるかもしれないが、過去のデータに過剰に適合してしまうこともあり、汎用的なモデルを作るのは難しいだろう。
金融の分野では昔から様々な予測モデルが研究されているが、統計の知識がないとなかなか理解するのが難しかったりする。
(ARとはMAとかARMAとかいろいろある)
一方で時系列データというのはある程度パターンが決まっていることが多い。例えば
- 全体的なトレンドとして上昇しているか、下降しているか
- 季節や曜日などの周期性があるか
- イベントなど外れ値となるような日があるか
などだ。これらを足し合わせた上でよくあるガウス分布のノイズを乗せてあげれば汎用的なモデルを作れそうである。
Prophetの場合、時間tにおける予測値y(t)は以下のように表される。
y(t)=g(t)+s(t)+h(t)+ε_t
ここで
- $g(t)$: トレンドを表す
- $s(t)$: 季節(周期的な)変化を表す
- $h(t)$: 休日などの特定のイベントを表す
- $ε_{t}$: ガウス分布に従うノイズ
となっている。
g,s,hはどれも時間tの関数となっているが、ノイズは時間によらず一定なのでε(t)という書き方はしないんだと思う。
チュートリアルをやってみよう
公式の"Quick Start"をやってみる。
https://facebook.github.io/prophet/docs/quick_start.html#python-api
今回はPythonでやる。
まずは必要なライブラリをimportした後にサンプルデータをPandasのdataframeに落とし込む。
import pandas as pd
from prophet import Prophet
df = pd.read_csv('https://raw.githubusercontent.com/facebook/prophet/main/examples/example_wp_log_peyton_manning.csv')
df.head()
ds y
0 2007-12-10 9.590761
1 2007-12-11 8.519590
2 2007-12-12 8.183677
3 2007-12-13 8.072467
4 2007-12-14 7.893572
ちなみにこのデータはPeyton Manningという有名なアメフト選手のWikipediaのpv数みたいだ。
https://en.wikipedia.org/wiki/Peyton_Manning
dataframeの中身のyは予測したい値の実際の値で、dsは日付を表している。
データは2007年12月10日から2016年1月20日まである。
では早速学習していこう。
使い方は簡単でインスタンスを作ってfitするだけ。
sklearnと似ているので、そっちの学習に慣れている人であればすんなり受け入れられると思う。
m = Prophet()
m.fit(df)
未来を予測するために日付を指定したdfを用意しておく。
make_feature_dataframeの引数で何日分の未来の日付を作るか指定できる。
future = m.make_future_dataframe(periods=365)
future.tail()
中身はdsだけ。
1年分未来の日付まであるので2017年1月19日まである。
df
3265 2017-01-15
3266 2017-01-16
3267 2017-01-17
3268 2017-01-18
3269 2017-01-19
このfeatureを引数として以下のように予測することができる。
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
ds yhat yhat_lower yhat_upper
3265 2017-01-15 8.205418 7.537699 8.900801
3266 2017-01-16 8.530436 7.782230 9.203809
3267 2017-01-17 8.317838 7.543540 9.068007
3268 2017-01-18 8.150450 7.395619 8.947244
3269 2017-01-19 8.162372 7.433345 8.875072
featureのdataframeにds以外の新しいカラムが追加されていることがわかる。
yhatが予測したyであり、lower/upperはそれぞれ誤差も含めた下限/上限となる。
本当はforecastは他にも絡むが含まれているが、大事そうカラムだけにフィルターしてある。
可視化用の専用の関数も用意されている
Prophet.plotでplotしてみよう。
fig1 = m.plot(forecast)
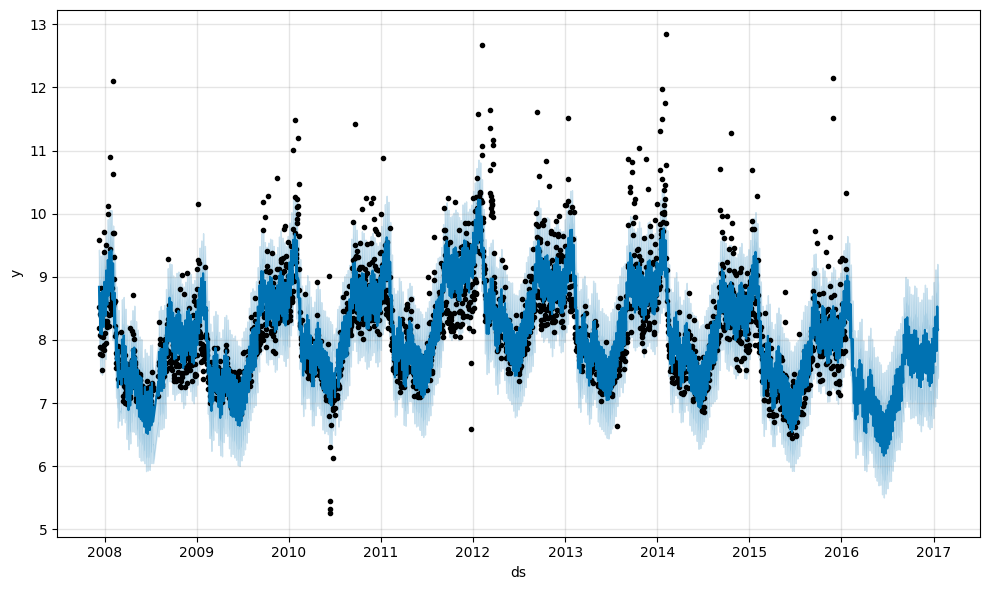
黒い点が実測値で青が予測である。
予測している最後の1年間は当然実測値はない。
それまでの傾向をうまく引き継いで予測できているように見える。
Prophet.plot_componemtsでcomponentごとに分解したplotもできる。
fig2 = m.plot_components(forecast)
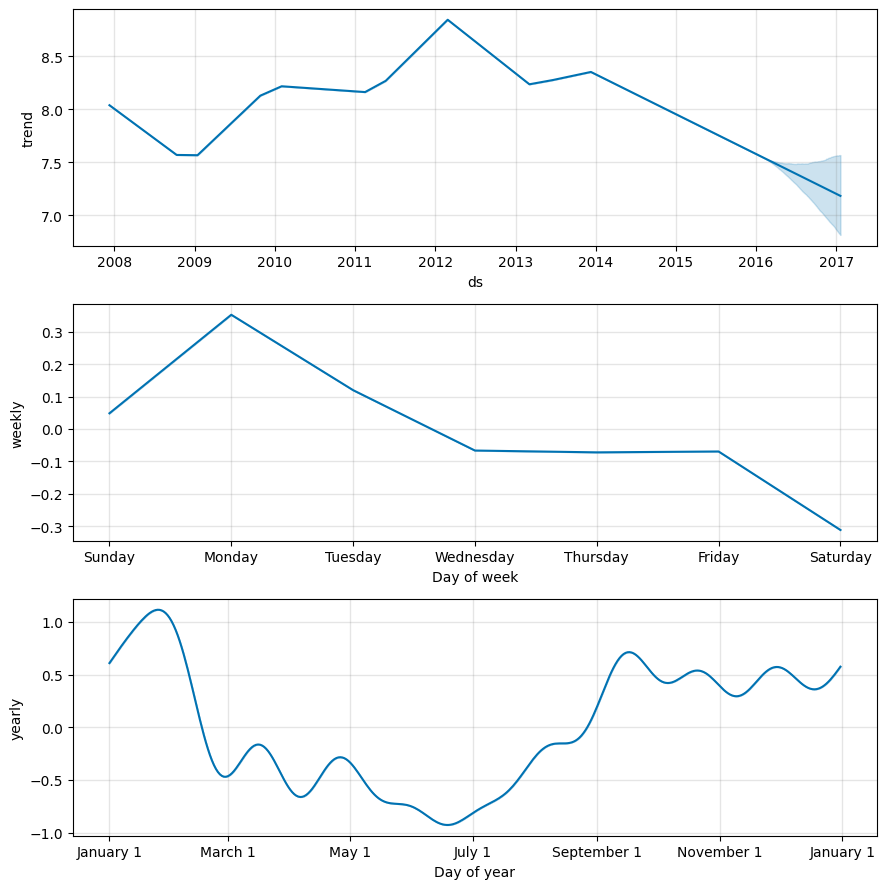
trendに加えてweekly, yearlyの周期的な条件を個別に見ることができる。
例えば週で見ると「土曜日が少なく月曜日が多い」という周期性が見られる。
また季節を見ると1月が多いようだ。
なぜだろうと思ってアメリカンフットボール(NFL)試合日程について調べてみた。
通常のシーズンが9-12月にかけて行われ、一番盛り上がるプレーオフ、スーパボウルが1-2月にかけて行われるようだ。
したがってアメフト選手である彼のWikipediaもそれに合わせて閲覧が増えるのだろう。

画像はここから:https://second-effort.com/game/bowl-schedule/
またアメリカにおいて金曜日は高校、土曜日はカレッジの試合があるためプロの試合を行わないらしい。
そう考えると土曜日が一番閲覧が少ないのにも納得がいく。
こうやってデータを深掘りしてみるのも面白い。
他にできること
今回はサンプルコードを使った一番シンプルなケースしかやらなかったが、他にも
- パラメータのチューニングによる精度の上昇
- 時系列を考慮したcross validation
- 予測に使うfeatureの追加
など様々なことができるので、試してみてほしい。
cvについては以下の記事がわかりやすかった。
パラメータのチューニングはデフォルト設定でもそこそこの精度は出るが、やはりチューニングをしたほうが精度は上がるだろう。
かたっぱしから試すgrid searchのほかにOptunaなどのベイズ的な手法を使っている人もいたので参考になりそう。
感想
時系列データの予測については昔から取り組まれているテーマだが、難しい知識がなくてもサクッと試せるという意味でProphetは便利なツールだなと思った。
曜日や季節などをcomponentごとに取り出して分析できるのも面白いと思った。