1. はじめに
本記事では、以下を満たす「実践的なMLパイプライン」を AWS 上で構築した事例を紹介します。
- SageMaker Pipelinesでワークフローを管理
- Hyperparameter Tunerで性能最適化
- mlflowでExperiment Tracking
- FSx for Lustreで高速なデータアクセス
2. 全体構成とユースケース
以下のような構成で、物体検出モデルの学習と最適化を行います。
図は生成AIに作ってもらいました、微妙にずれているのはご愛敬ということで・・
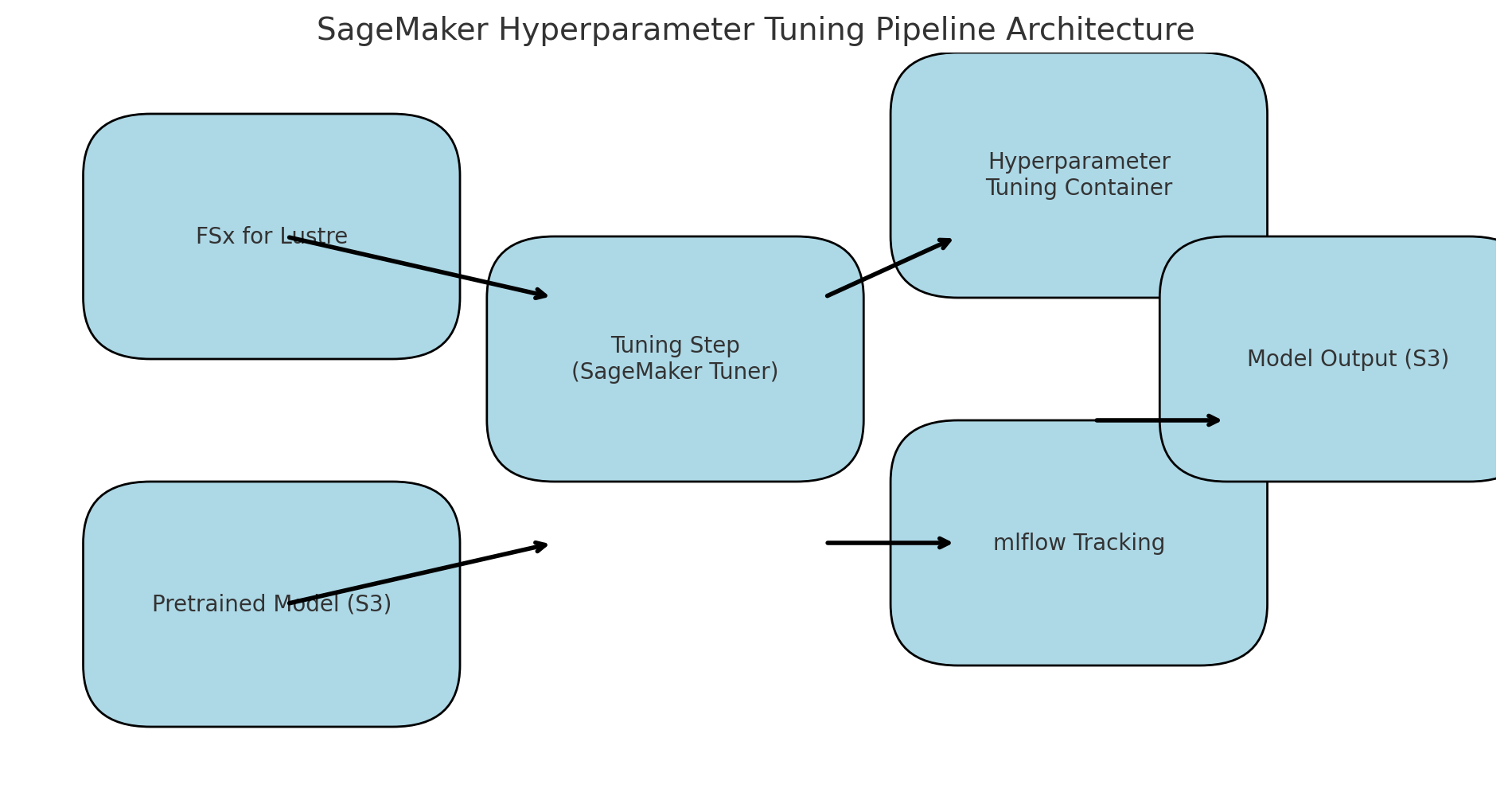
3. コードで見るチューニング構成
3.1 Estimator定義と環境変数の工夫
estimator = Estimator(
image_uri=environ["MODEL_TRAINING_ECR_IMAGE_URI"],
role=role,
instance_count=1,
instance_type="任意のインスタンス",
hyperparameters=hp_static_dict,
environment={
"MLFLOW_ARN": environ["MLFLOW_ARN"],
"MLFLOW_PARENT_RUN_ID": hpo_run.info.run_id,
"MODEL_ARCH": detection_model_exp,
...
},
...
)
environment で mlflow の設定を渡し、Container側からTrackingできるようにしています
FSx経由のデータ読み込みも file_system_id と directory_path で指定
3.2 mlflowとの親子Run管理
mlflow.set_experiment(experiment_name)
with mlflow.start_run() as hpo_run:
mlflow.set_tag("mlflow.runName", f"HPO-{current_time}")
mlflow.set_tag("mlflow.parentRunId", parent_run_id)
parent_run_id を受け継いで、チューニングステップが親実験に紐づくよう管理
3.3 HyperparameterTunerの設計
tuner = HyperparameterTuner(
estimator=estimator,
objective_metric_name="mAP",
hyperparameter_ranges=hp_ranges_dict,
...
)
評価指標 (mAP) を metric_definitions で正規表現マッチ。並列数やearly_stoppingも設定可。
3.4 FSx for Lustre を使った高速データアクセス構成
Amazon FSx for Lustre を使うことで、学習ジョブの入力データを高速に処理できます。
S3からの読み込みに比べ、ファイルI/Oが圧倒的に高速かつ並列化しやすく、画像処理系のパイプラインや大規模データにおいて効果を発揮します。
FSxは「Lustreファイルシステム」としてマウントされ、バッチ・チューニング処理から file:// として参照できる。前段でS3からFSxにリンクを張っておく(自動インポート or DataRepositoryTask)
from sagemaker.inputs import FileSystemInput
fsx_dataset = FileSystemInput(
file_system_id="任意のid",
file_system_type="FSxLustre",
directory_path="任意のパス",
file_system_access_mode="ro", # read-only
content_type="application/x-image" # optional
)
この fsx_dataset は、例えば TuningStep の入力として次のように使います:
step_tuning = TuningStep(
name="HPTuningStep",
tuner=tuner,
inputs={
"dataset": fsx_dataset,
"model": pretrained_model_s3_uri,
},
...
)
4. 再現性の工夫ポイント
mlflowでRun管理
チューニング結果を全てログ化。評価スコアと紐づけ
FSxで高速I/O
巨大データのS3→FSxキャッシュを活用
パラメータ外出し
config.yaml + environmentでチーム再利用しやすく
S3構成の分離
make_s3_output_path_from_stepnameで出力整理可能に
5. まとめと次にやりたいこと
この構成により、高性能モデルの自動探索とそのログ管理を1つのパイプラインに集約できた
CI/CDやModel Registryとの連携、Model Monitorを使った再学習の自動化にも拡張可能