こんにちは、データアナリストの島田です。普段はタクシー配車アプリのユーザ分析をしています。今回は、オープンデータであるChicago Taxi Dataを例に、BigQueryとPythonでの空間情報分析の始め方を説明します。
Chicago Taxi Data
Chicagoのタクシー事情1
- イリノイ州の最大都市であるシカゴ市では、市により認可を受けた民間企業がタクシーを運営しています
- 車両台数は市が上限を定めており、およそ7000台が稼働しています
- 車両ごとのライセンスは厳格に管理されており、ボンネットに取り付ける許認可証(Taxi Medallion)は市から購入、または所有者から購入・リースする必要があります
- ドライバーが乗車拒否することは許されません
- 初乗り料金は3.25ドル、距離料金は1/9マイルごとに0.2ドルで、時間料金は36秒ごとに0.2ドルです
- 12歳未満または65歳以上を除き、最初の乗客一人に1ドル、追加の乗客一人につき0.5ドルの乗客料金がかかります
- 空港からの乗車には4ドルの空港出発税が追加料金としてかかります
- クレジットカードを利用する場合には0.5ドルの追加料金がかかります
- チップはオプションですが、タクシー料金の10%を支払うことが推奨されています
誰がデータを公開しているか?
シカゴ市がタクシーの決済事業者(payment processing vendors)から収集したデータを、プライバシーに配慮した上でオープンデータとして公開しています。
このChicago Taxi Dataは、BigQuery上で一般公開データセットとして公開されています。一時データの更新が中断されていましたが、現在では月に1回のペースでデータが更新されています2。
BigQueryは、クエリ実行時のデータスキャン量に応じて課金されますが、一定量までは無料です。
スキーマ定義
- 1レコードに1トリップ(1回の乗車から降車まで)でデータが記録されています
- データ型はBigQueryでの定義です
| カラム名 | データ型 | 説明 | Example |
|---|---|---|---|
| unique_key | STRING | トリップ(1回の乗車から降車まで)ごとのID | 8bd3b952677b35a7e0b74af976a0061053ffd163 |
| taxi_id | STRING | タクシーのID | ff2afe67ddd19f814a835c7ef66b4051b10e92ba019536dc6ef97485936b3f5f4edaea66e6fb0f878e6ab53363eaad3df60ca61034aecccb695b66c30bcf1faa |
| trip_start_timestamp | TIMESTAMP | トリップの開始時刻を15分間隔に丸めたもの | 2018-06-15 12:30:00 UTC |
| trip_end_timestamp | TIMESTAMP | トリップの終了時刻を15分間隔に丸めたもの | 2018-06-15 13:00:00 UTC |
| trip_seconds | INTEGER | トリップにかかった秒数 | 1588 |
| trip_miles | FLOAT | トリップの距離(マイル) | 6.04 |
| pickup_census_tract | INTEGER | トリップ開始地点の国勢統計区。プライバシーの理由からいくつかのレコードでは欠損する。またシカゴの外ではしばしば欠損する。 | 17031010100 |
| dropoff_census_tract | INTEGER | トリップ終了地点の国勢統計区。プライバシーの理由からいくつかのレコードでは欠損する。またシカゴの外ではしばしば欠損する。 | 17031020301 |
| pickup_community_area | INTEGER | トリップ開始地点のコミュニティーエリア番号 | 14 |
| dropoff_community_area | INTEGER | トリップ終了地点のコミュニティーエリア番号 | 6 |
| fare | FLOAT | 運賃 | 3.25 |
| tips | FLOAT | チップ(現金の場合は原則記録されない) | 3.65 |
| tolls | FLOAT | 有料道路の通行料金 | 0 |
| extras | FLOAT | 追加料金(空港乗り入れ料金など) | 8.25 |
| trip_total | FLOAT | 合計金額 | 15.15 |
| payment_type | STRING | 支払い方法 | Cash |
| company | STRING | タクシー会社 | Taxi Affiliation Services |
| pickup_latitude | FLOAT | トリップ開始地点近傍の国勢統計区またはコミュニティーエリアの緯度 | 41.938391 |
| pickup_longitude | FLOAT | トリップ開始地点近傍の国勢統計区またはコミュニティーエリアの経度 | -87.638575 |
| pickup_location | STRING | トリップ開始地点近傍の国勢統計区またはコミュニティーエリアの緯度経度(WKTフォーマット) | POINT (-87.6385749205 41.938391257700005) |
| dropoff_latitude | FLOAT | トリップ終了地点近傍の国勢統計区またはコミュニティーエリアの緯度 | 41.938391 |
| dropoff_longitude | FLOAT | トリップ終了地点近傍の国勢統計区またはコミュニティーエリアの経度 | -87.638575 |
| dropoff_location | STRING | トリップ終了地点近傍の国勢統計区またはコミュニティーエリアの緯度経度(WKTフォーマット) | POINT (-87.6385749205 41.938391257700005) |
BigQueryの使い方
BigQueryのセットアップ
- 公式のガイドに従ってBigQueryのセットアップが完了していることを想定しています
- 本記事中では、BigQueryのウェブUI上でのSQL実行とPythonクライアントライブラリによるSQL実行を使い分けます
- PythonクライアントライブラリからBigQueryでSQL実行する場合にはサービスアカウントキーによる認証が望ましいですが、本記事中ではOAuth2で認証します3。
データセットの確認
- セットアップが完了したらBigQueryのコンソールに行き、
chicagoでデータセットを検索してみてください
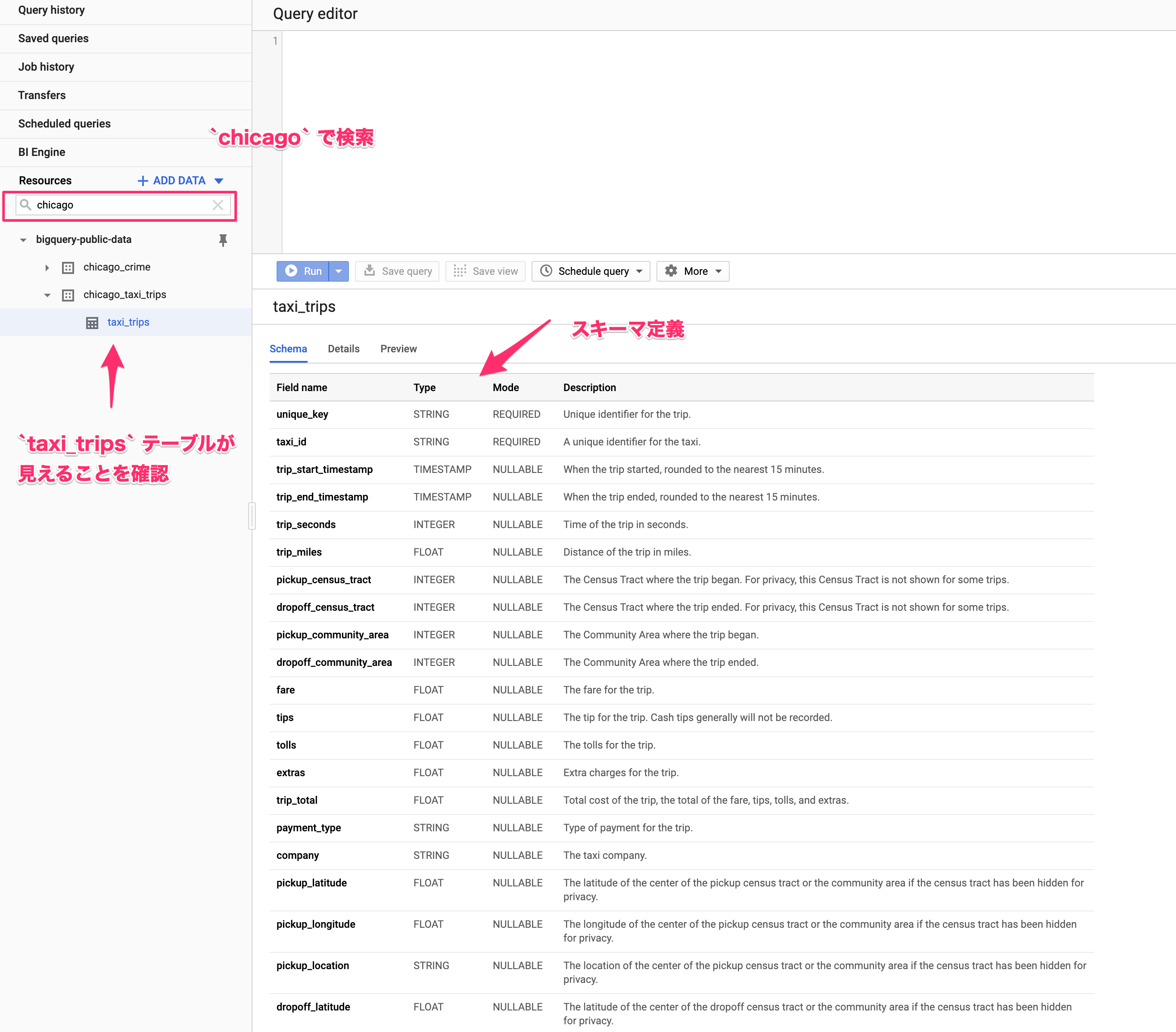
-
Detailsタブを開くとテーブルの情報が確認できます - テーブルサイズとレコード数を見ると、とてもローカルファイルで操作したくないサイズですが、BigQueryでは難なく扱えるサイズです
- 最終更新日を確認すれば、このテーブルに今もデータ更新がされているか確認ができます

BigQueryにおける空間情報の取り扱い
- それまでベータ版だったBigQueryの
GEOGRAPHY型は2019年5月に正式リリースされました - これにより、緯度経度、WKTやGeoJSONで定義されたline、polygon、multipolygonなどを
GEOGRAPHY型に変換して地理関数を適用した空間情報操作が可能になりました - 詳細な地理関数の使い方は「BigQuery GISを用いた位置情報データ分析の入門」などをご参照ください
緯度経度からPointデータの作成
-
Pointとは緯度経度を保持するGEOGRAPHY型です - 試しにPickupした緯度経度をPointに変換してみましょう
- 2通り存在しますが、同じ値が入っているはずですので、変換後も同一のGEOGRAPHY型の値になるはずです
- ただし、STRING型はスキャン量が多くなるため、FLOAT型の緯度経度を入力とする
ST_GEOGPOINTを以降は使用します
-
LIMIT句は実行結果を打ち切って返してくれますが、BigQueryではスキャン量は減少しませんので課金額は変わりません
SELECT
/* FLOAT64型の緯度経度からPointのGEOGRAPHY型を作成する */
ST_GEOGPOINT(pickup_longitude, pickup_latitude) AS pickup_point_1
/* WKTフォーマットに従うSTRING型からPointのGEOGRAPHY型を作成する */
,ST_GEOGFROMTEXT(pickup_location) AS pickup_point_2
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
LIMIT 1000
BigQueryからPythonにデータを持ってきて分析する
直線距離とトリップ距離の関係
- 地理関数の例として2点間の距離を出す
ST_DISTANCEを使ってみましょう - 2019年10月1日〜2019年10月31日のデータを対象とします
- また、トリップの開始地点と終了地点、トリップ距離があるレコードに限定します
- 開始終了地点間の直線距離とトリップ距離の差がどの程度なのか確認してみましょう
WITH distance AS (
SELECT
trip_miles * 1609.34 AS trip_meter
,ST_DISTANCE(ST_GEOGPOINT(pickup_longitude, pickup_latitude), ST_GEOGPOINT(dropoff_longitude, dropoff_latitude))
AS direct_distance_meter
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
DATE(trip_end_timestamp, 'America/Chicago') BETWEEN DATE('2019-10-01') AND DATE('2019-10-31')
/* 各カラムに値が入っているレコードのみを対象とする */
AND trip_miles > 0
/* 20km以上は異常値と見做す */
AND trip_miles * 1609.34 < 20000
AND pickup_latitude IS NOT NULL
AND pickup_longitude IS NOT NULL
AND dropoff_latitude IS NOT NULL
AND dropoff_longitude IS NOT NULL
)
/* 日付と非欠損を条件にしても大量のレコード存在するため、集計してから可視化する */
/* 500m単位で区分値化する */
SELECT
FLOOR(trip_meter / 500) * 500 AS trip_meter_bin
,FLOOR(direct_distance_meter / 500) * 500 AS direct_distance_meter_bin
,COUNT(*) AS cnt
FROM distance
GROUP BY
trip_meter_bin
,direct_distance_meter_bin
Pythonの環境設定
- 今回は以下のような環境をdockerfileで用意しました4
- Jupyterlabでkepler.gl、plotlyなどの可視化ツールを使用する場合は対応するextensionが必要です
FROM python:3.7.5-slim-stretch
ENV NODE_VERSION=12.13.1
# Python packages excluding jupyter
ENV PYTHON_PACKAGES="\
bokeh \
Cython \
google-cloud-bigquery \
google-cloud-bigquery-storage \
japanize-matplotlib \
keplergl \
matplotlib \
numpy \
pandas \
pandas-gbq \
plotly \
pyarrow \
pydata_google_auth \
seaborn \
scikit-learn \
scipy \
"
RUN echo "|--> Install tools" \
&& apt-get update \
&& apt-get install -y --no-install-recommends \
build-essential \
curl \
apt-utils \
&& echo "|--> Install Node.js" \
&& curl -L git.io/nodebrew | perl - setup \
&& export PATH=$HOME/.nodebrew/current/bin:$PATH \
&& nodebrew install-binary v$NODE_VERSION \
&& nodebrew use v$NODE_VERSION \
&& echo "|--> Install python packages" \
&& pip --no-cache-dir install --upgrade pip setuptools wheel \
&& pip --no-cache-dir install $PYTHON_PACKAGES \
&& echo "|--> Install jupyter" \
&& pip --no-cache-dir install \
jupyter \
jupyterlab \
ipywidgets \
&& jupyter serverextension enable --py jupyterlab \
&& jupyter nbextension enable --py widgetsnbextension \
&& export NODE_OPTIONS=--max-old-space-size=4096 \
&& jupyter labextension install @jupyter-widgets/jupyterlab-manager --no-build \
&& jupyter labextension install keplergl-jupyter --no-build \
&& jupyter labextension install plotlywidget --no-build \
&& jupyter labextension install jupyterlab-plotly --no-build \
&& jupyter lab build \
&& unset NODE_OPTIONS \
&& echo "|--> Cleanup temporary files" \
&& npm cache clean --force \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# Expose jupyter port
EXPOSE 8888
- buildする際はdockerfileがあるディレクトリに移動して
docker build -t your-image-name:tag .など適当な名前を付けてbuildしてください - コンテナを起動する場合は以下の様なコマンドを実行して、URLにブラウザからアクセスしてください
- コンテナと疎通するportなどは適宜調整してください
# Jupyter Notebookを起動する場合
# 起動後に表示されたURLにアクセスする
docker run --rm --name your-coutainer-name -it -p 8888:8888 -v $PWD/notebooks:/notebooks -w /notebooks -e NB_UID=$(id -u) -e NB_GID=$(id -g) -e GRANT_SUDO=yes your-image-name:tag jupyter notebook --port 8888 --ip=0.0.0.0 --allow-root
# Jupyter Labを起動する場合
# tokenを空にするのはセキュリティ上好ましくないので、個人利用する場合のみに限定すること
# 起動後にhttp://localhost:8888へアクセスする
docker run --rm --name your-container-name -p 8888:8888 -v $PWD/notebooks:/notebooks your-image-name:tag jupyter-lab --no-browser --port=8888 --ip=0.0.0.0 --allow-root --notebook-dir=/notebooks --NotebookApp.token=''
PythonでのBigQueryからのデータ抽出
- 結果をPythonに連携して可視化してみましょう
- PythonコードはすべてJupyter notebook、またはJupyter Lab上で実行することを想定しています
- まず、OAuth2でBigQueryのクレデンシャルを取得します
- 実行するとURLが表示されるので、そのURLからBigQueryが実行可能なGoogleアカウントでのBigQueryアクセス許可をしてAuthentication Codeを貼り付けます
import pydata_google_auth
credentials = pydata_google_auth.get_user_credentials(
# BigQueryをscopeとする
# https://developers.google.com/identity/protocols/googlescopes
scopes = ['https://www.googleapis.com/auth/bigquery'],
)
- SQLはnotebookと同じ場所に
distance_diff.sqlというファイル名で置いてあることとします
with open("/notebooks/distance_diff.sql", 'r') as f:
# sql = """SELECT * FROM table""" のように定義することも可
sql = f.read()
print(sql)
- BigQueryでSQLを実行して、実行結果をPandas Dataframeとして格納します
- 実行結果はparqeutなどのカラムナー形式のファイルで保存することで、同じデータをBigQueryから抽出する際の料金と実行時間を節約できます
from google.cloud import bigquery
from google.cloud import bigquery_storage_v1beta1
# データセットのあるGCPプロジェクト名
project = "your-project-name"
# BigQueryのクライアント
client = bigquery.Client(project=project, credentials=credentials)
# BigQuery Storageのクライアント
# 別途料金はかかるが、データ抽出が高速化する
# https://cloud.google.com/bigquery/docs/reference/storage/
bqstorage_client = bigquery_storage_v1beta1.BigQueryStorageClient(credentials=credentials)
df = client.query(sql, project=project).to_dataframe(bqstorage_client=bqstorage_client)
# parquet形式でデータを保存する
# 読み込むときはpandas.read_parqeut
df.to_parquet('data.pq')
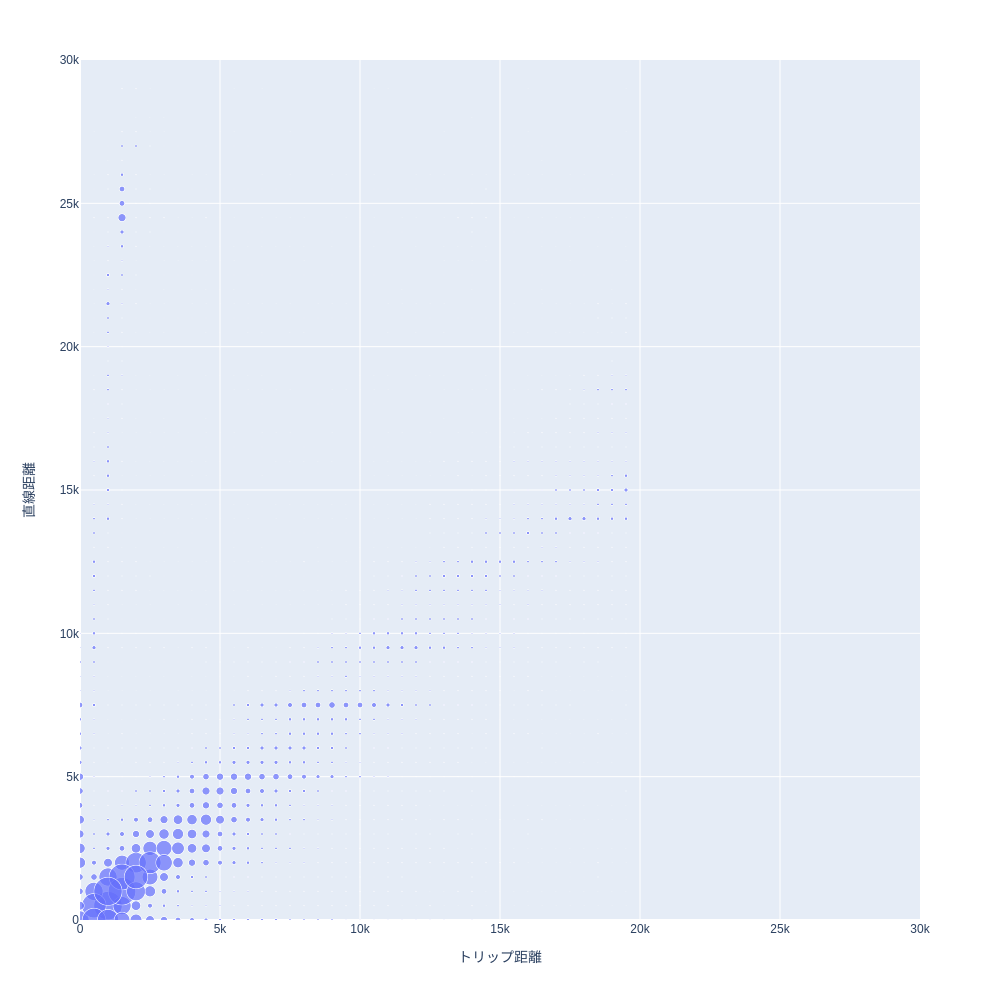
- バブルチャートで可視化してみます
import plotly.express as px
fig = px.scatter(
df,
x="trip_meter_bin",
y="direct_distance_meter_bin",
size="cnt",
width=1000,
height=1000,
range_x=[0, 30000],
range_y=[0, 30000],
)
fig.update_xaxes(title_text="トリップ距離")
fig.update_yaxes(title_text="直線距離")
fig.show()
- おおむね5km以内でに集中していてトリップ距離と直線距離は比例しているようです
- 一方で、トリップ距離、または直線距離のどちらかがゼロに近い値になっているものも一定数存在します
- タクシーメーターから排出されるデータなので、データクオリティはこの程度です
- まず、ここまででBigQueryのデータを操作してPythonで可視化する流れは実行できると思います
- これ以外にも、タクシー会社別の売上や、季節によるトリップ数の違い、曜日時間帯別の稼働タクシー数などいろいろ可視化することができます
- 「どのような可視化をするのか?」とか「BigQuery SQLにもっと慣れたい」という方はKaggleのKernelで手習い的に公開されていますのでそちらを参考にいろいろ試してみてください。
Kepler.glによる地図上での可視化
どこからどこへのトリップ?
- つぎに、タクシーのトリップがどこで始まってどこで終わるのが多いのか確認してみようと思います
- 今回のデータの場合、トリップ開始・終了地点の国勢統計区のIDが含まれているので、そのIDで集計してみましょう
SELECT
CONCAT(CAST(pickup_census_tract AS STRING), '-', CAST(dropoff_census_tract AS STRING)) AS census_tract_trip
,COUNT(*) AS cnt
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
DATE(trip_end_timestamp, 'America/Chicago') BETWEEN DATE('2018-11-01') AND DATE('2019-10-31')
/* 各カラムに値が入っているレコードのみを対象とする */
AND pickup_census_tract IS NOT NULL
AND dropoff_census_tract IS NOT NULL
GROUP BY census_tract_trip
ORDER BY cnt DESC
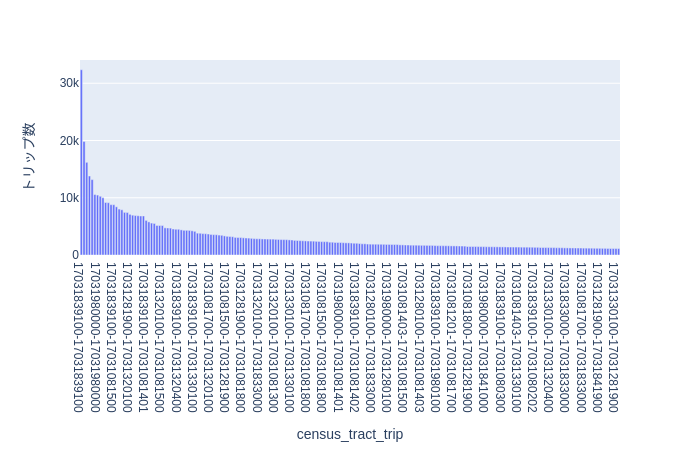
- トリップ数上位200を可視化
import plotly.express as px
fig = px.bar(df[:200], x="census_tract_trip", y="cnt")
fig.update_yaxes(title_text="トリップ数")
fig.show()
- 棒グラフにしてみるとトリップ数が偏る場所がありそうです
- ただ、census tractだとこれが一体どこなのか判然としません
地図で見てみる
- 地図上での可視化ツールとしてUber製のKepler.glをJupyter上から実行する方法を見てみましょう
- 出発地点と到着地点の緯度経度で、トリップ数をカウントしたデータをBigQueryからpandas.dataframeとして取得します
SELECT
pickup_latitude
,pickup_longitude
,dropoff_latitude
,dropoff_longitude
,COUNT(*) AS cnt
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
DATE(trip_end_timestamp, 'America/Chicago') BETWEEN DATE('2019-10-01') AND DATE('2019-10-31')
/* 各カラムに値が入っているレコードのみを対象とする */
AND pickup_latitude IS NOT NULL
AND pickup_longitude IS NOT NULL
AND dropoff_latitude IS NOT NULL
AND dropoff_longitude IS NOT NULL
GROUP BY
pickup_latitude
,pickup_longitude
,dropoff_latitude
,dropoff_longitude
-
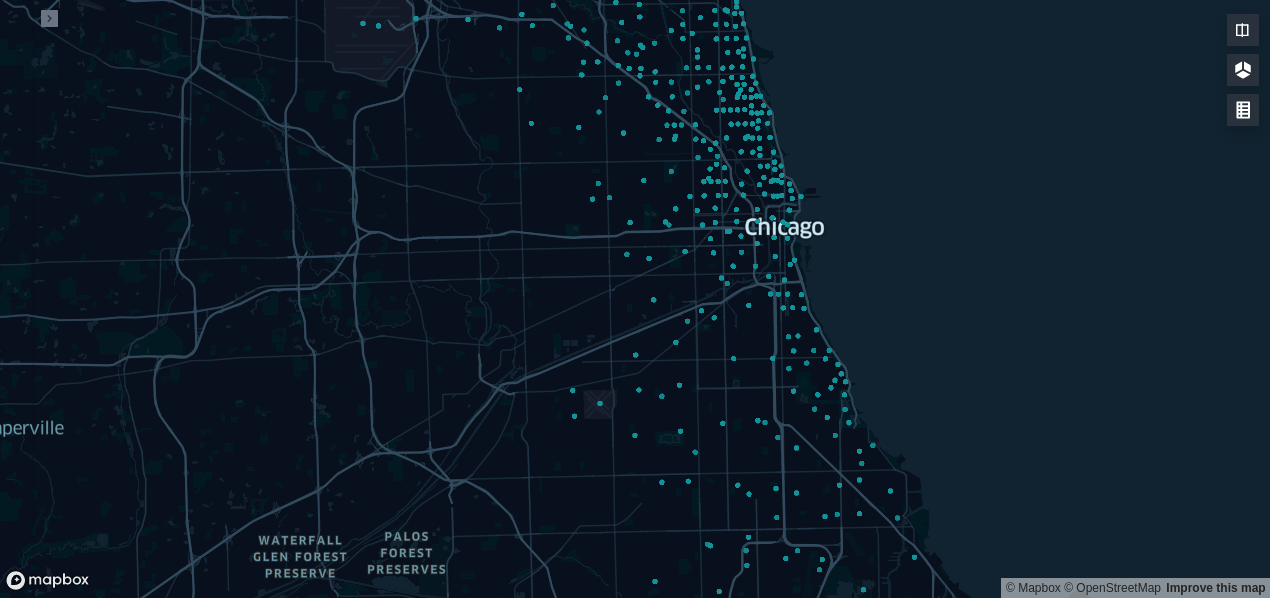
dfという変数にpandas.dataframe形式のデータを格納して、次のコードを実行します
from keplergl import KeplerGl
map1 = KeplerGl(height=600)
map1.add_data(data=df)
map1
- たったこれだけのコードですが地図上にデータ可視化ができてしまいます!
- デフォルトでは見たい表記になっていないと思いますので、カスタマイズします
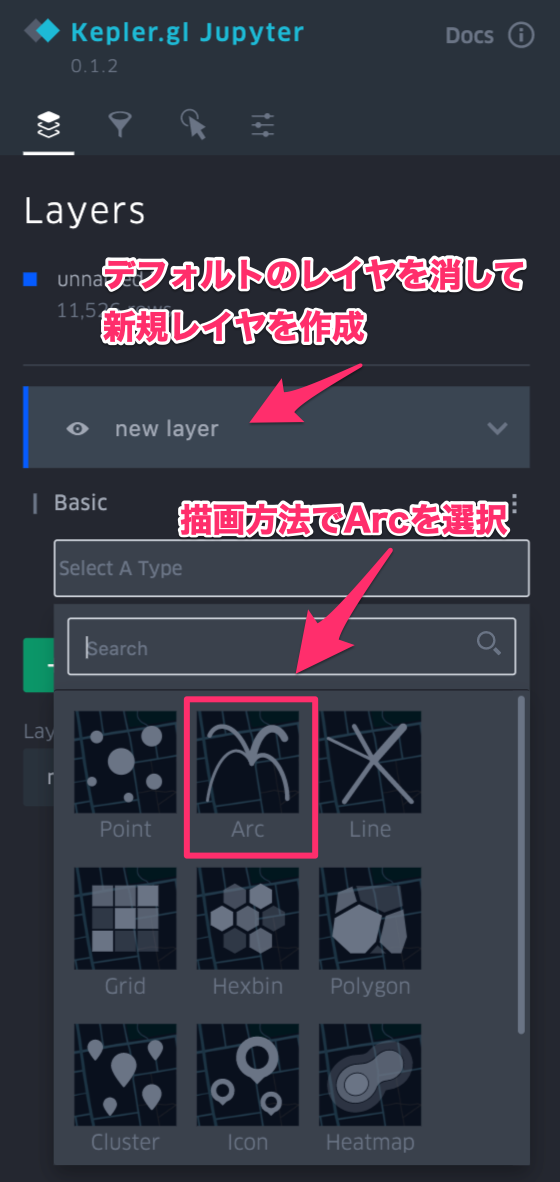
- さまざまな可視化方法がありますが、ここでは出発地点と到着地点を弧で結ぶArcにしてみます
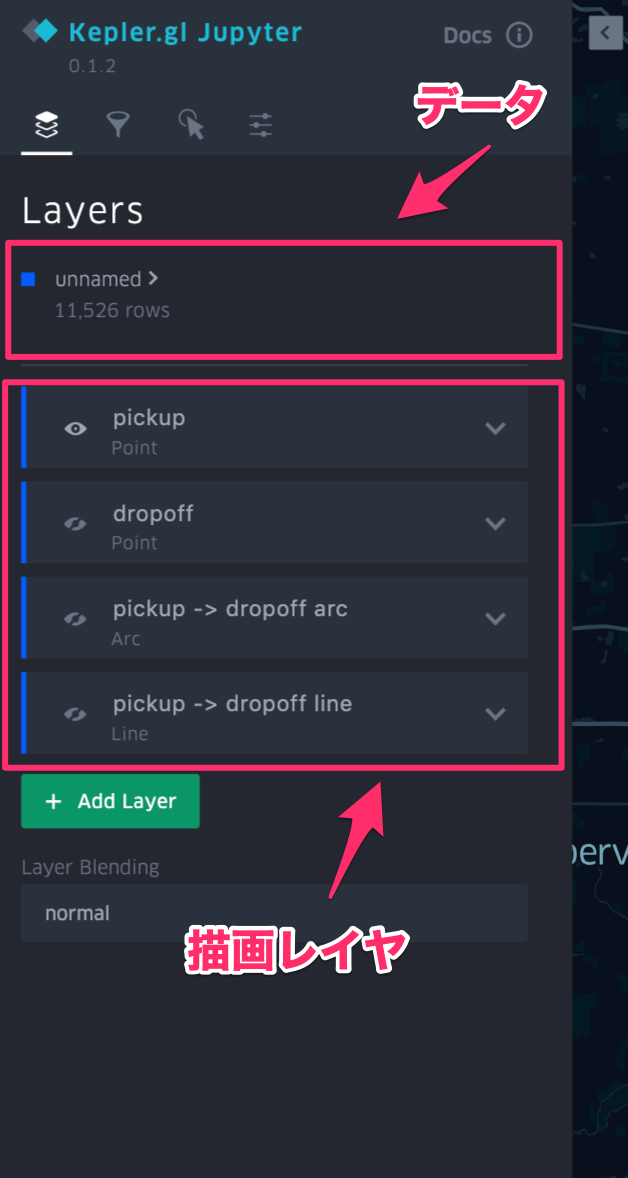
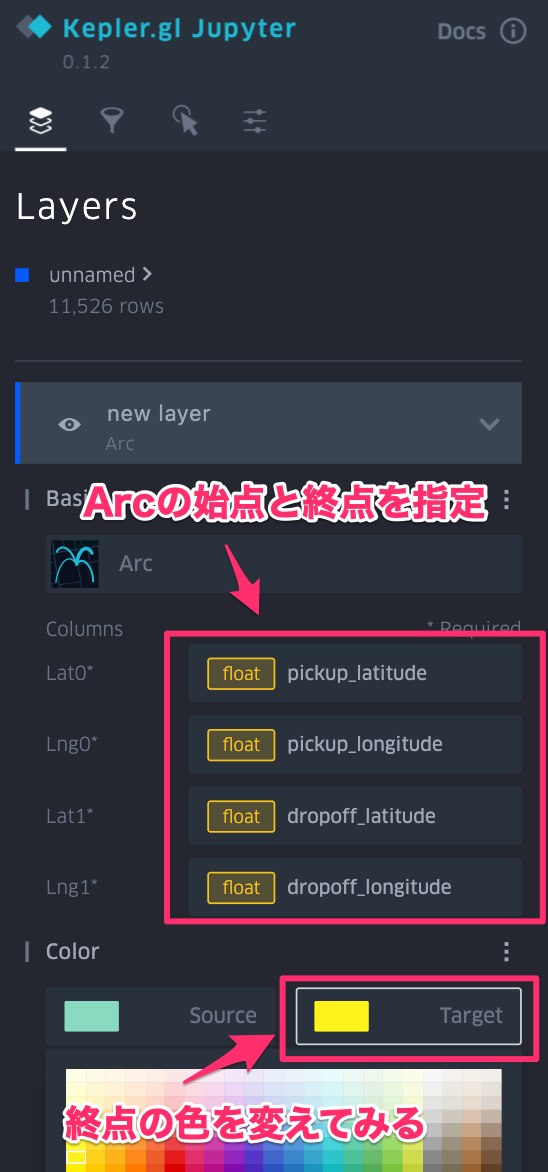
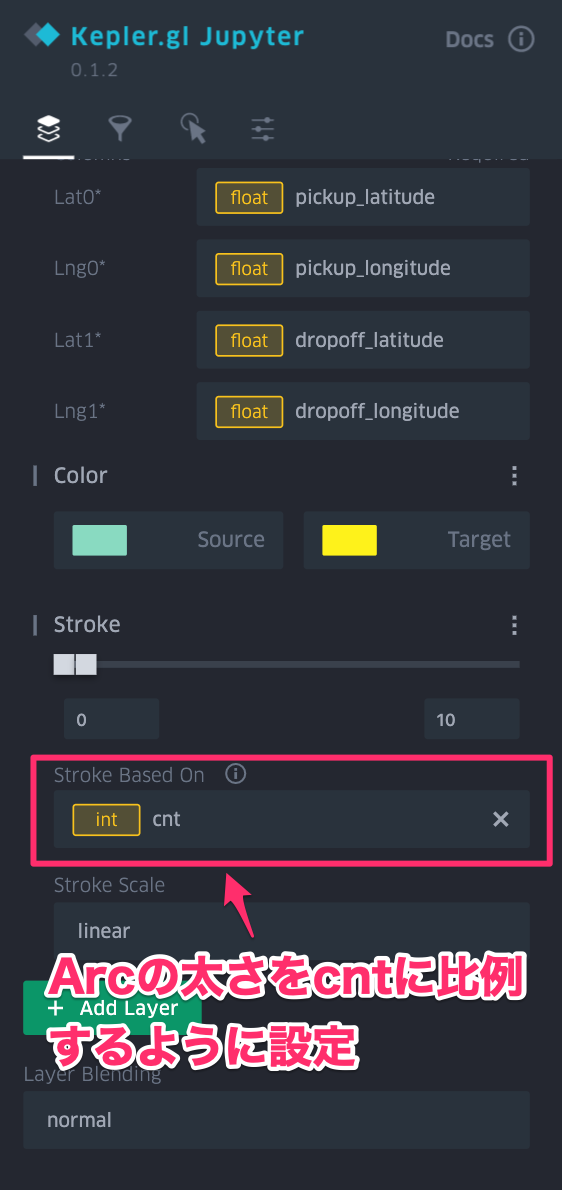
- 可視化の設定は左上の">"を押すと出てくる設定ペインのレイヤで変更できます
| 設定ペイン | Arcの描画方法を指定 | Arcの始点と終点を指定 | Arcの太さを変更 |
|---|---|---|---|
 |
 |
 |
 |
- 右上の3D Mapを有効にするとこのような可視化ができます
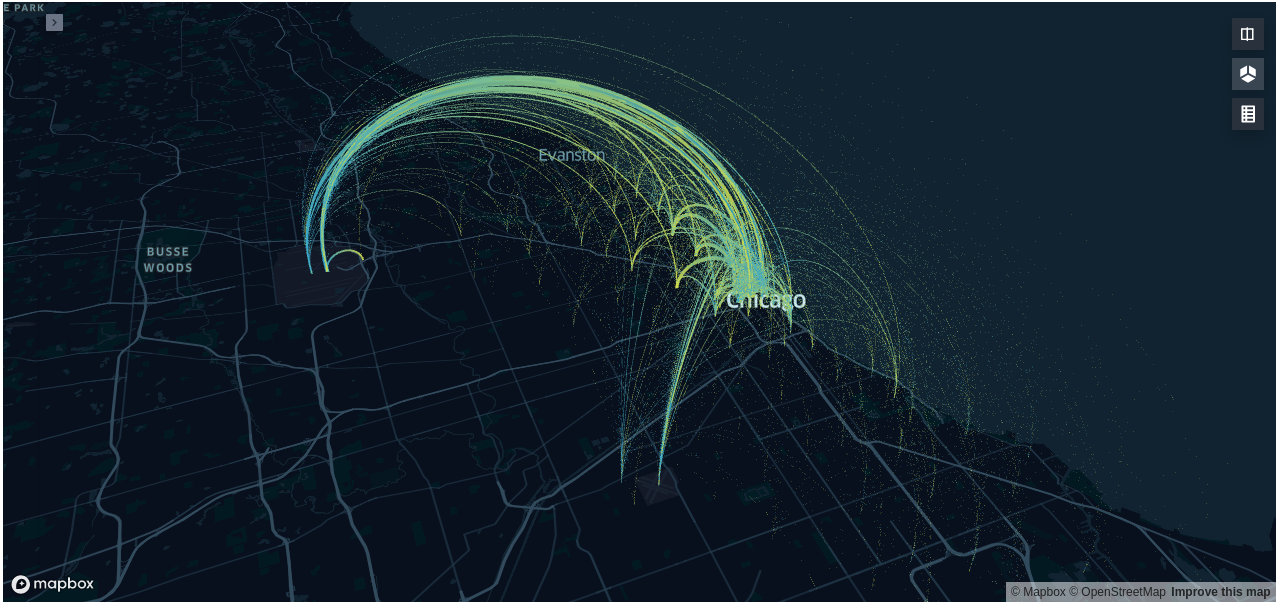
- 設定した可視化情報はJSON形式のconfigとして存在するので保存しておきます
# せっかく設定した可視化方法を上書きしないように注意!
with open("map1_config.py", "w") as f:
f.write("config = {}".format(map1.config))
- configを読み込む場合は次のようにします
%run map1_config.py
map1.config = config
- 時間カラムを持たせてフィルターに指定するとアニメーションさせることもできます
SELECT
DATETIME(trip_start_timestamp, 'America/Chicago') AS trip_start_time_cst
,pickup_latitude
,pickup_longitude
,dropoff_latitude
,dropoff_longitude
,COUNT(*) AS cnt
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
DATE(trip_start_timestamp, 'America/Chicago') BETWEEN DATE('2019-10-30') AND DATE('2019-10-31')
/* 各カラムに値が入っているレコードのみを対象とする */
AND pickup_latitude IS NOT NULL
AND pickup_longitude IS NOT NULL
AND dropoff_latitude IS NOT NULL
AND dropoff_longitude IS NOT NULL
GROUP BY
trip_start_time_cst
,pickup_latitude
,pickup_longitude
,dropoff_latitude
,dropoff_longitude
- こうすると空港からのタクシー利用が多く、深夜帯はタクシー利用が急激に減少し、街中での利用に偏るなどということがわかると思います
- 大量のデータをフロントサイドで頑張って描画するというアプローチですので、どのくらいのデータ量まで可視化できるのかはPCの性能などに依存します

空間の分割
- さて、前述の地図上での可視化方法は定性的な理解には役立ちますが、定量的に把握したり統計モデルにするにはもう一つ工夫が必要です
- Chicago Taxi Dataの場合にはすでにCensus Tract単位に緯度経度がまとめられていましたが、本来の緯度経度はトリップごとに異なっていて完全に同一の緯度経度のトリップは存在しないと考えて良いでしょう
- 空間上に散らばったデータポイントをまとめる手法として、HDBSCANのような密度ベースのクラスタリングを適用することも考えられます
- 今回は空間を事前に分割して、分割した空間の中でデータを集約することを考えます
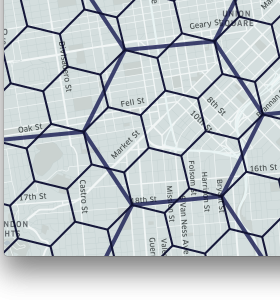
H3とは?

- Uberが提案した地球をヘキサゴンタイルで空間分割(Bin化)する手法で、オープンソースプロジェクトとして運用されています
- 以下の3つの理由によりUberはヘキサゴンを採用しました5
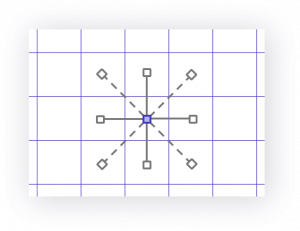
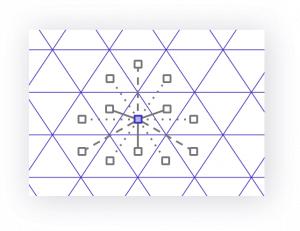
-
近接するグリッドの中心までの距離が均等
ヘキサゴン スクウェア トライアングル 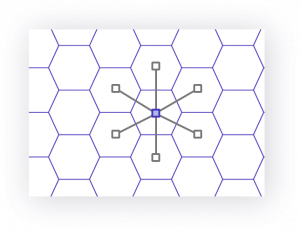
-
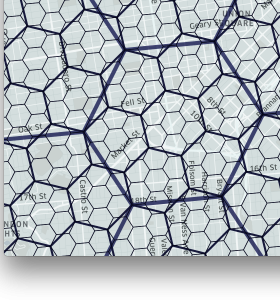
グリッドに階層構造を定義できる(正方形分割と違い、厳密な階層にはならない)
divide sub-divide subusub-divide 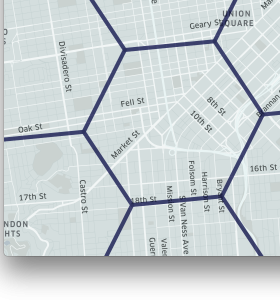
-
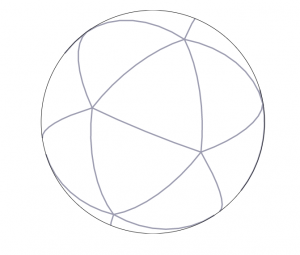
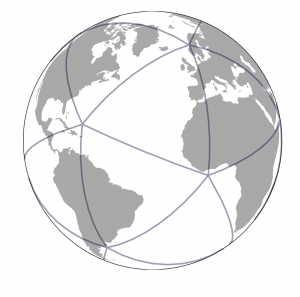
正二十面体(Icosahedron)による地表面分割により、グリッドのゆがみが少なく、また(自動車のことを考える場合に)無視できる海面しか含まれない分割領域ができるためデータ保持上も有利
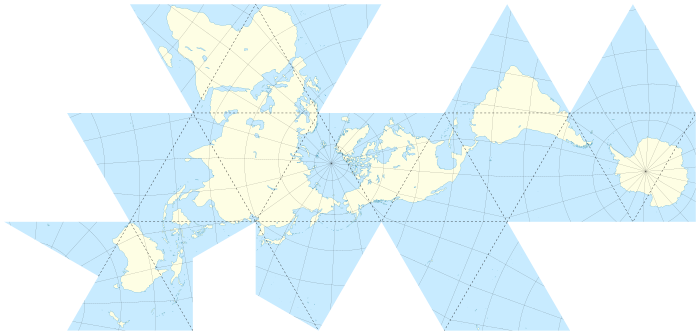
正二十面体 正二十面体の球体プロジェクション 正二十面体の地球プロジェクション 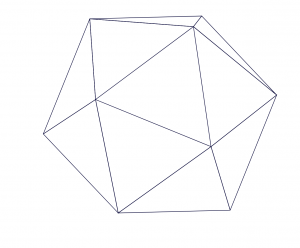
- いわゆるダイマクション地図と呼ばれる投影方法となります
H3をBigQueryで利用する
UDFとは?
- BigQueryでは通常の関数の他にユーザ定義関数(User-Defined Functions、以下UDF)が利用可能です
- UDFはSQL UDFとJavaScript UDFの2種類の書き方ができます
- JavaScript UDFの場合は外部ライブラリをインポートして定義することができます
- 今回は、H3のJavaScriptライブラリを利用してJavaScript UDFを定義し、BigQueryからH3の関数を使用できるようにします
H3のJavaScriptライブラリ
-
H3のJavaScriptライブラリのpre-bundled scriptをUNPKG経由で入手します
- H3はここ https://unpkg.com/h3-js から入手できます
- 例えば
h3-js.umd.3.6.3.jsのような適当なファイル名を付けて、Google Cloud Storage(以下GCS)に保存します - JavaScript UDFでライブラリ指定をすることで使用できます
- ベータ版ですが永続UDFにすることで、実行速度の高速化が望めますが今回は割愛します
H3のJavaScript UDF
- H3は各ヘキサゴンに
87283472bffffffというようなSTRING型のH3 Indexを付与します - まずは、緯度経度からH3 Indexを取得する関数をJavaScript UDFにしてみましょう
- ヘキサゴンのサイズを指定するにはResolutionを指定します
-
resolution=7だとヘキサゴンの一辺 ≒ 中心から頂点までの距離は平均で1.220629759kmです - 球面上のプロジェクションしているため、厳密な正六角形にはなっていません
-
/* Temporary FunctionとしてJavaScript UDFを定義する */
CREATE TEMPORARY FUNCTION geoToH3(lat FLOAT64, lng FLOAT64, res INT64)
RETURNS STRING
LANGUAGE js AS """
return h3.geoToH3(lat, lng, res);
"""
/* OPTIONSでGCSに保存したJavaScript Libraryを指定する */
OPTIONS (
library="gs://your-bucket-name/javascript_lib_for_bq/h3-js.umd.3.6.3.js"
);
/* 試しに緯度経度とresolutionを指定してH3 Indexを取得してみる */
SELECT geoToH3(37.3615593, -122.0553238, 7)
- JavaScript UDFを定義するにあたり、JavaScriptは BigQueryの
GEOGRAPHY型を取り扱うことができないので、GeoJSONフォーマットのSTRING型でやりとりするように設計する必要があります - GeoJSONフォーマットの
STRING型で返ってくるので、ST_GEOGFROMGEOJSON関数を使うことでGEOGRAPHY型に変換できます - 例えば、H3 Indexからそれを形成するPOLYGONを返す関数は以下の様に定義できます
/* H3 Indexから構成するヘキサゴンポリゴンを返す */
CREATE TEMPORARY FUNCTION h3ToGeoBoundary(h3Index STRING)
RETURNS STRING
LANGUAGE js AS """
/* GeoJSONのフォーマットを指定するパラメータ */
var formatAsGeoJson = true;
var coords = h3.h3ToGeoBoundary(h3Index, formatAsGeoJson);
/* GeoJSONフォーマットのSTRING型を生成する */
return JSON.stringify({"type": "Polygon", "coordinates": [coords]});
"""
OPTIONS (
library="gs://your-bucket-name/javascript_lib_for_bq/h3-js.umd.3.6.3.js"
);
/* 先ほどのH3 Indexを構成するヘキサゴンポリゴンをGEOGRAPHY型 */
SELECT ST_GEOGFROMGEOJSON(h3ToGeoBoundary("87283472bffffff"));
H3をKepler.gl上で可視化
- 気づいた方もいると思いますが、Kepler.glもH3もUber製ですので、連携は非常にスムーズです
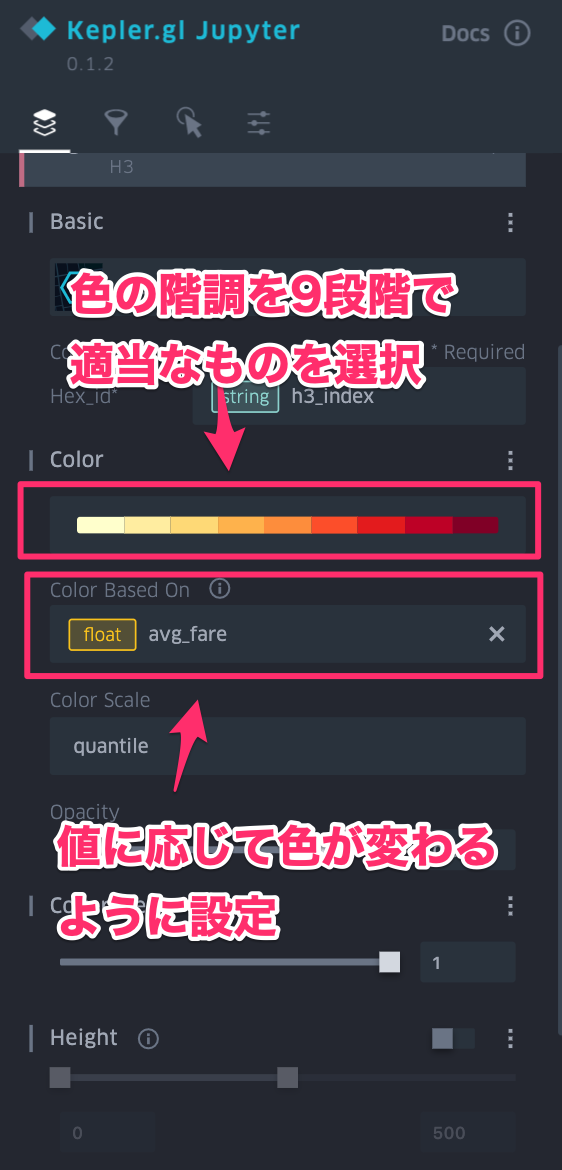
- 試しにH3のヘキサゴンで平均のfareを出して見たいと思います
- Kepler.glはSTRING型のH3 indexをそのまま解釈できます
/* Temporary FunctionとしてJavaScript UDFを定義する */
CREATE TEMPORARY FUNCTION geoToH3(lat FLOAT64, lng FLOAT64, res INT64)
RETURNS STRING
LANGUAGE js AS """
return h3.geoToH3(lat, lng, res);
"""
/* OPTIONSでGCSに保存したJavaScript Libraryを指定する */
OPTIONS (
library="gs://your-bucket-name/javascript_lib_for_bq/h3-js.umd.3.6.3.js"
);
SELECT
TIMESTAMP_TRUNC(trip_start_timestamp, HOUR, 'America/Chicago') AS trip_start_hour_cst
,geoToH3(pickup_latitude, pickup_longitude, 7) AS h3_index
,AVG(fare) AS avg_fare
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE
DATE(trip_start_timestamp, 'America/Chicago') BETWEEN DATE('2019-10-30') AND DATE('2019-10-31')
/* 各カラムに値が入っているレコードのみを対象とする */
AND pickup_latitude IS NOT NULL
AND pickup_longitude IS NOT NULL
AND fare IS NOT NULL
GROUP BY
trip_start_hour_cst
,h3_index
- 先ほどと同じように
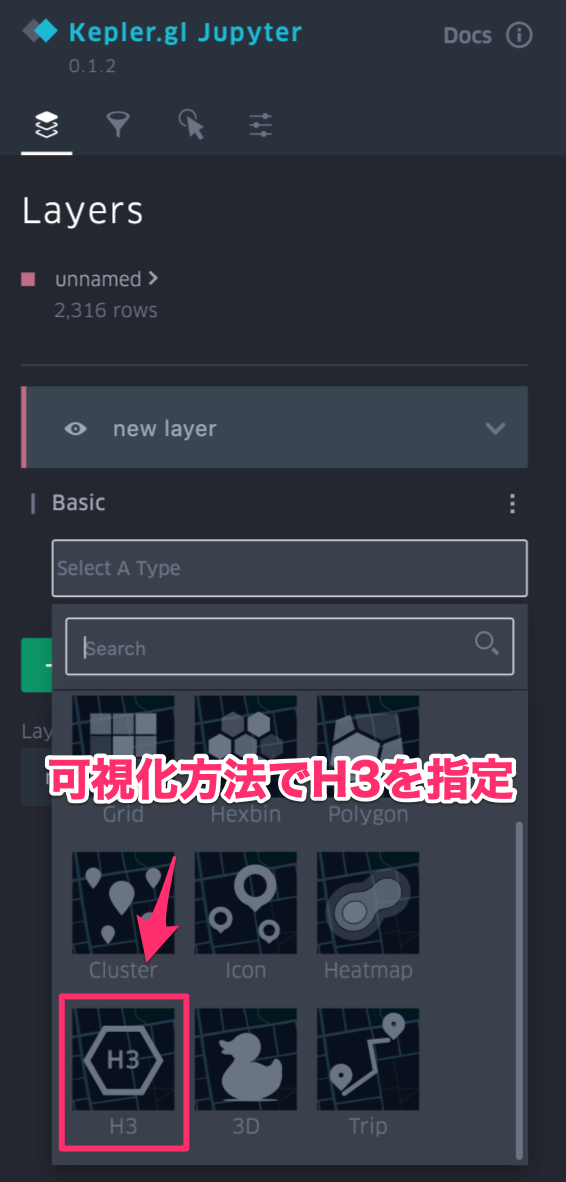
dfという変数にデータが格納されているとします - Kepler.gl上のレイヤ設定を変更します
| H3のレイヤを作成 | 値に応じて色が変わる設定 | 時系列のカラムをフィルタに設定 |
|---|---|---|
 |
 |
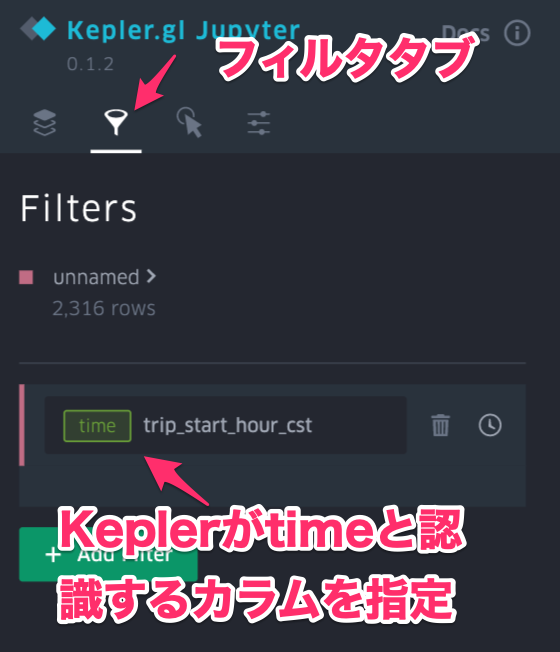 |
- 上記の様な設定をすると、H3ごとの平均fareを時間を追って可視化することができます

さいごに
- BigQuery GISという強力な空間情報処理DWH、Kepler.glという可視化ツール、H3という空間分割ツールのご紹介ができたかと思います
- 空間情報の取り扱いの下地ができたので、ここからさらに、機械学習モデル、統計モデルでの予測や現象理解に進みたいところでしたが今回はここまでとさせてください
- 以前はArcGISなどの高額なGISツールを使用しなければ高度な分析はできませんでしたが、このようなツールの登場によりハードルが下がっています
- この状況は、SPSS、SASでしかできなかった分析がRやPythonでできるようになったデータサイエンスの民主化と状況が似ていると思います
- 空間分割をしなければいけない理由として未加工の緯度経度でデータポイントを取り扱うには計算機リソースが足りないということもあります
- ディープラーニングがGPUを利用した計算機リソースの向上により大きく発展したのと同様に、空間情報分析もコンピュータ側のブレイクスルーにより大きく発展する可能性を感じています
- 個人的には、複雑ネットワークについても同様の可能性を感じています
- これからも新しい分析手法で新しい発見をしていきたいと思います
それでは、Merry Christmas and Happy Analytics Life!
-
実際に行ったことは無いのでWikipediaから引用 https://en.wikipedia.org/wiki/Taxicabs_of_the_United_States#Chicago ↩
-
2017年9月にデータ収集の欠損トラブルが発覚し、2019年まで更新が途絶えていました。現在では過去分のデータの復元も行われています。 http://dev.cityofchicago.org/open%20data/data%20portal/2019/04/12/tnp-taxi-privacy.html ↩
-
セキュリティ要件が定められている場合は、そちらに従ってください ↩
-
不要なライブラリをいくつか残してしまいましたが気にしないでください。imageサイズとanacondaに抵抗がなければscipy-notebookをベースにしても良いです。 ↩
-
空間分割方法(Bin化)に正解は無く、例えば地域メッシュや国勢調査の小地域、S2 Geometry、ジオハッシュなど様々なものが存在しますので、データの特性や分析の目的に合わせて選択する必要があります。 ↩