はじめに
この記事は、NTTテクノクロス Advent Calendar 2025 シリーズ1の10日目の記事になります。
こんにちは、NTTテクノクロスの照喜名です。入社3年目でEMR、Glue、Lambda、Cloudwatch等を利用したAWSの開発をやっていました。最近はオンプレのシステムを触っています。
Glue Python shellとは
Glue3.0をベースにした、分散処理ではないPythonプログラムを動かすためのAWSサービスです。Glue3.0ベースのためPythonバージョンが3.9までしか選択できず、Python3.9は残念ながら2025年10月にEOLとなってしまいました。
EOLということは、セキュリティ上使い続けるのはあまりよくありません。そこで、別サービスへの移行が必要となります。
Python shellから別のサービスへの移行について
Python shellから別サービスへの移行の選択肢は主に2(+1)つです。
1つ目が、AWS Lambdaに移行する方法です。
Lambdaの実行時間上限15分とメモリ上限10GBに引っかからない場合は利用可能です。AWS SDK for PandasというLambdaレイヤーも使用可能のため、比較的楽に移行を行うことができます。
2つ目が、ECSに移行する方法です。
ECSにはFargateとEC2という二つの起動タイプがありますが、Fargateの方が管理上は楽と言われています。サーバレスサービスであるGlueからの移行のため、Fargateの方が優先度の高い選択肢となるでしょう。
一応3つ目として、Glueの最新バージョンに移行する方法があります。
こちらの場合移行作業は大変楽なのですが、Glueが分散処理を前提としたサービスで2Worker以上でしか起動できないという特徴があり、分散処理を動かさないPython shellからの移行となると1Worker分の遊休リソースが発生してしまいます。
今回目をつけたのは、2つ目のECS Fargateへ移行する方法です。
Lambdaのような制限が特になく移行可能なため、どんなワークロードにも対応できると考えています。また、チーム内でも少し話題にあがっていたので、先んじてお試しでECSへのデプロイをやってみようと考えました。
移行するプログラム
以下の簡単なPandasを利用したプログラムを移行しようと思います。ランダムなデータを作成し、そのデータを集計するプログラムです。
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
import json
def main():
# 時系列データのサンプル作成
dates = pd.date_range(start='2024-01-01', end='2024-01-31', freq='D')
np.random.seed(42)
sales_data = {
'date': dates,
'product_a_sales': np.random.randint(100, 500, len(dates)),
'product_b_sales': np.random.randint(50, 300, len(dates)),
'product_c_sales': np.random.randint(200, 600, len(dates)),
'temperature': np.random.normal(5, 10, len(dates)), # 気温(摂氏)
'is_weekend': [d.weekday() >= 5 for d in dates]
}
df = pd.DataFrame(sales_data)
print("売上データ:")
print(df.head(10))
# データ分析
# 1. 総売上の計算
df['total_sales'] = df['product_a_sales'] + df['product_b_sales'] + df['product_c_sales']
# 2. 移動平均の計算
df['sales_ma_7'] = df['total_sales'].rolling(window=7).mean()
# 3. 平日・休日別の分析
weekend_analysis = df.groupby('is_weekend').agg({
'total_sales': ['mean', 'std'],
'product_a_sales': 'mean',
'product_b_sales': 'mean',
'product_c_sales': 'mean'
}).round(2)
print("\n平日・休日別分析:")
print("False=平日, True=休日")
print(weekend_analysis)
# 4. 気温と売上の相関
correlation = df[['temperature', 'total_sales']].corr()
print("\n気温と売上の相関:")
print(correlation)
# 5. 日別売上ランキング
top_sales_days = df.nlargest(5, 'total_sales')[['date', 'total_sales', 'is_weekend']]
print("\n売上トップ5日:")
print(top_sales_days)
# 6. 週別集計
df['week'] = df['date'].dt.isocalendar().week
weekly_summary = df.groupby('week').agg({
'total_sales': 'sum',
'temperature': 'mean'
}).round(2)
print("\n週別集計:")
print(weekly_summary)
# 結果のサマリーをJSON形式で出力
summary = {
'total_days': len(df),
'average_daily_sales': float(df['total_sales'].mean()),
'max_daily_sales': float(df['total_sales'].max()),
'min_daily_sales': float(df['total_sales'].min()),
'weekend_avg_sales': float(df[df['is_weekend']]['total_sales'].mean()),
'weekday_avg_sales': float(df[~df['is_weekend']]['total_sales'].mean())
}
print("\nサマリー(JSON形式):")
print(json.dumps(summary, indent=2))
if __name__ == "__main__":
main()
移行手順
1. Dockerfileの作成
Python 3.13をベースにしたDockerfileを作成します。お試しなので最低限の構成です。
FROM python:3.13
RUN pip install --upgrade pip \
&& pip install pandas numpy boto3
WORKDIR /app
COPY main.py .
CMD ["python", "main.py"]
2. ECRの作成~イメージのプッシュ
今回はEC2上で実行します。AWS CLIが使える別の環境で実施してもOK
- ECRを作成

- EC2を作成し、S3とECRへのアクセス権限を付与してEC2に接続(今回はSSMセッションマネージャーにより接続)
- システムアップデート&Dockerインストール
$ sudo yum update -y
$ sudo yum install -y docker
- Dockerサービス開始
$ sudo systemctl start docker
$ sudo systemctl enable docker
- ssm-userをdockerグループに追加し、一度ログアウトして再ログイン
$ sudo usermod -a -G docker ssm-user
- Docker動作確認
$ docker --version
$ docker run hello-world
- 作成した
Dockerfileとmain.pyをS3に配置し、aws s3 cpでS3上に配置
cd
mkdir docker
aws s3 cp s3:xxxxx/Dockerfile docker
aws s3 cp s3:xxxxx/main.py docker
- ECRに記載のあるプッシュコマンドを順番に実行

- プッシュ完了
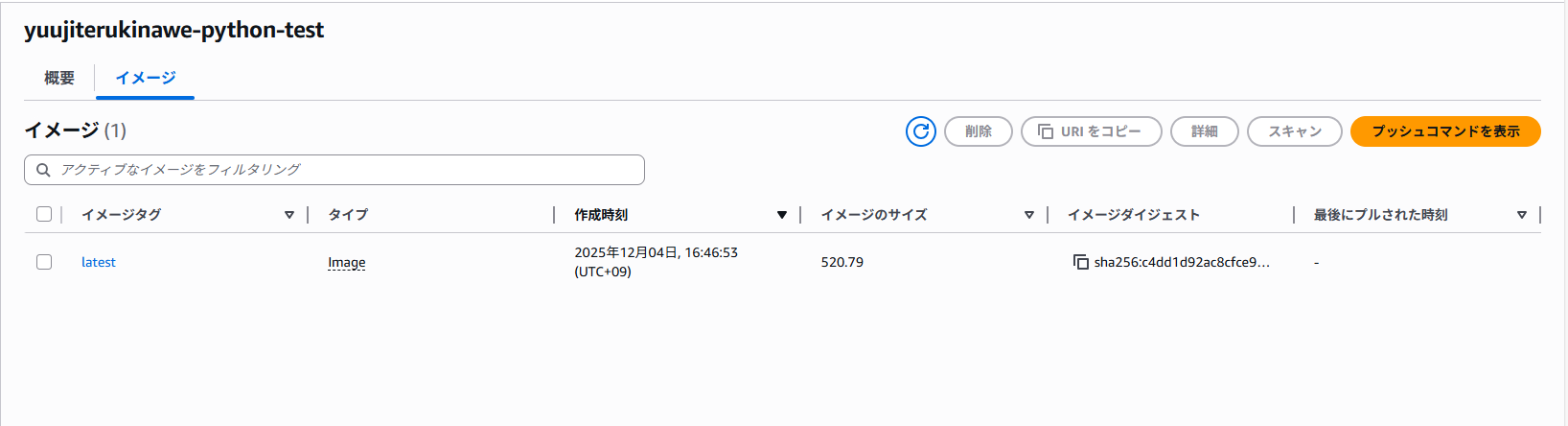
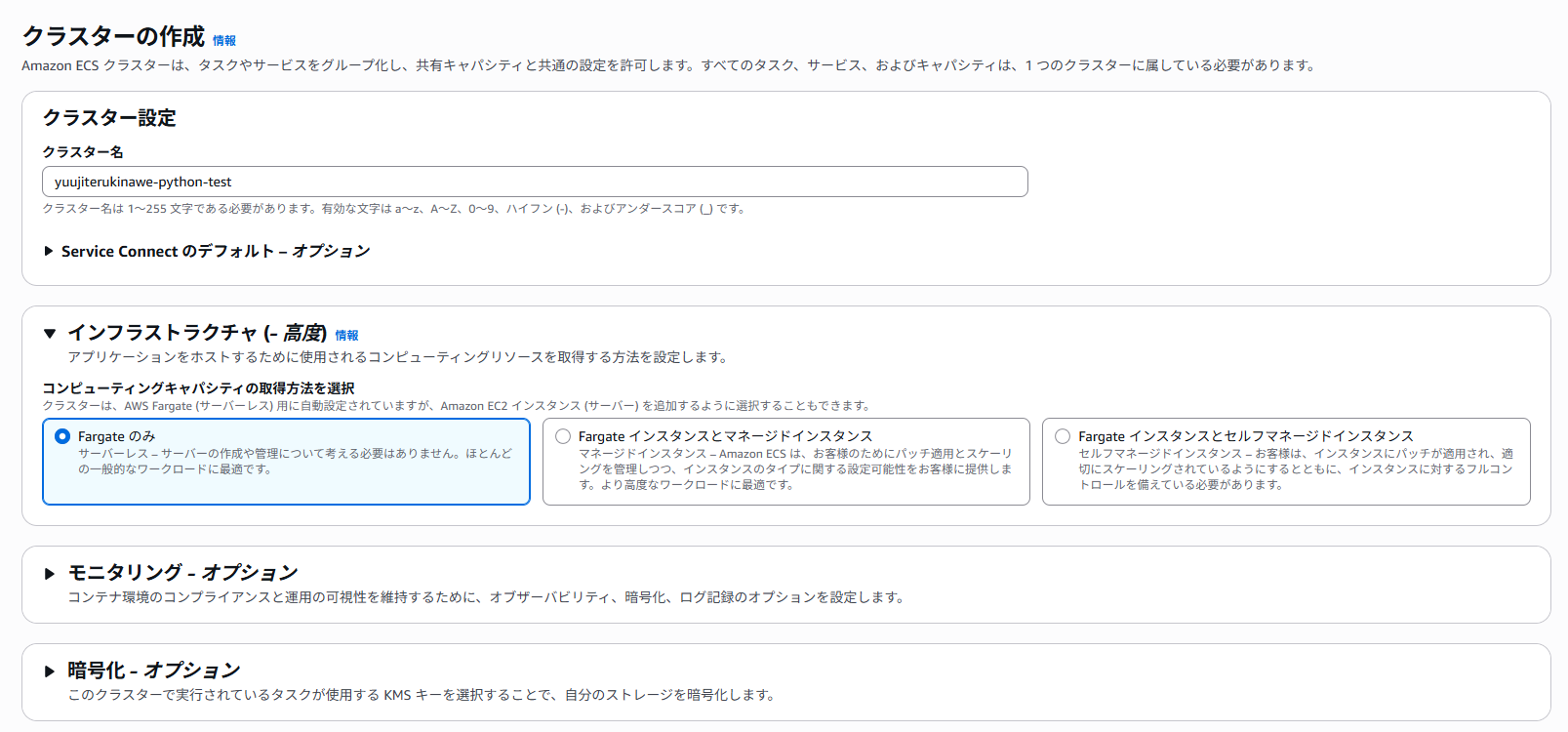
3. ECSクラスターの作成
ECSクラスターを作成します。
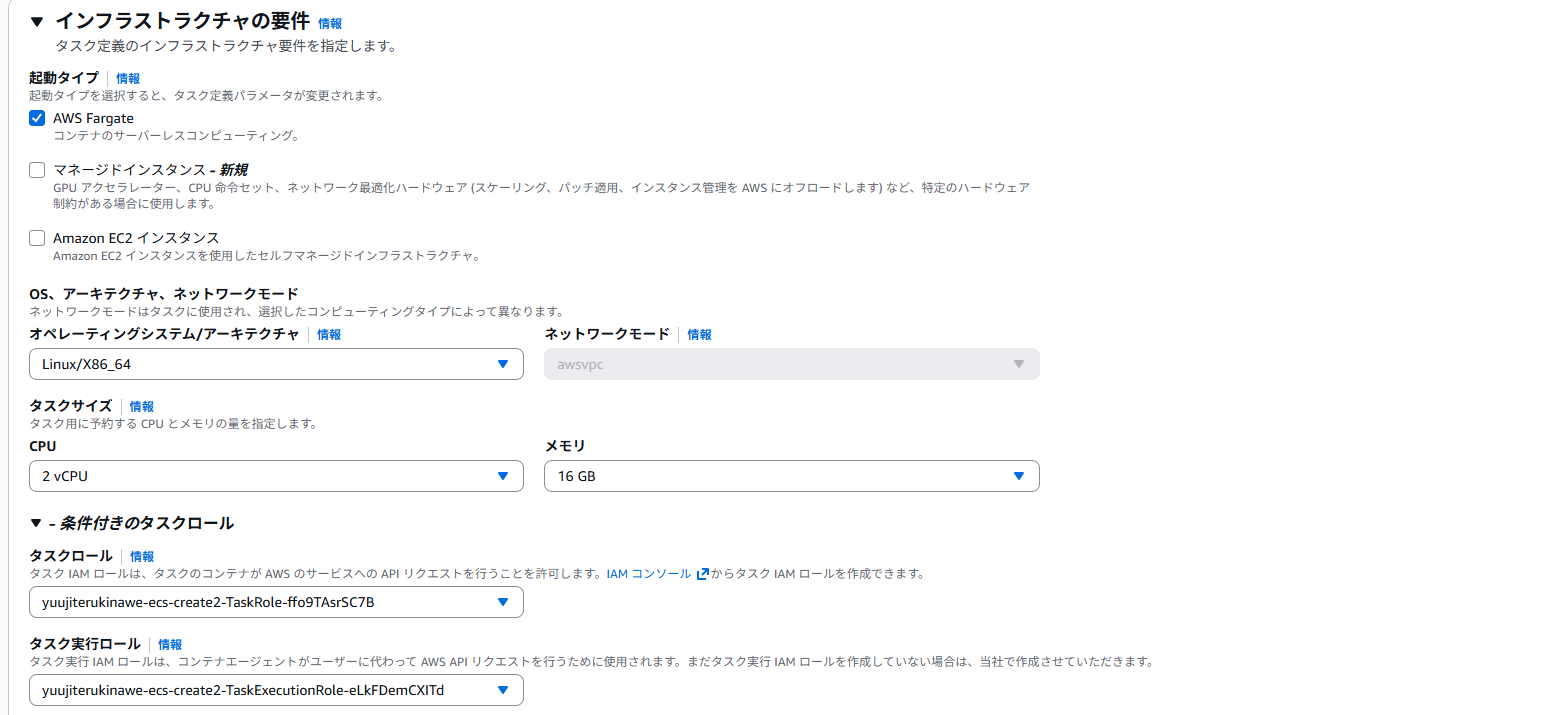
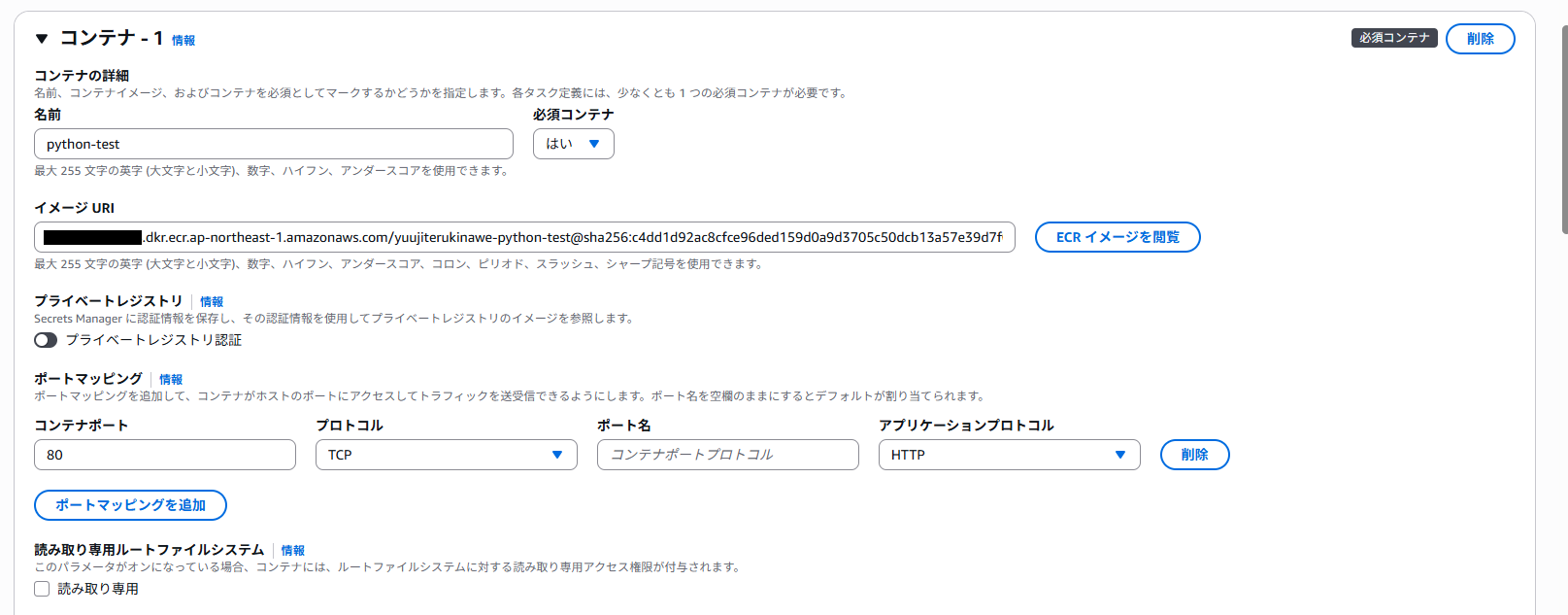
4. ECSタスクの実行
ECSタスクを作成します。メモリはせっかくなので16GBまで上げました(このプログラムでは不要ですが...)
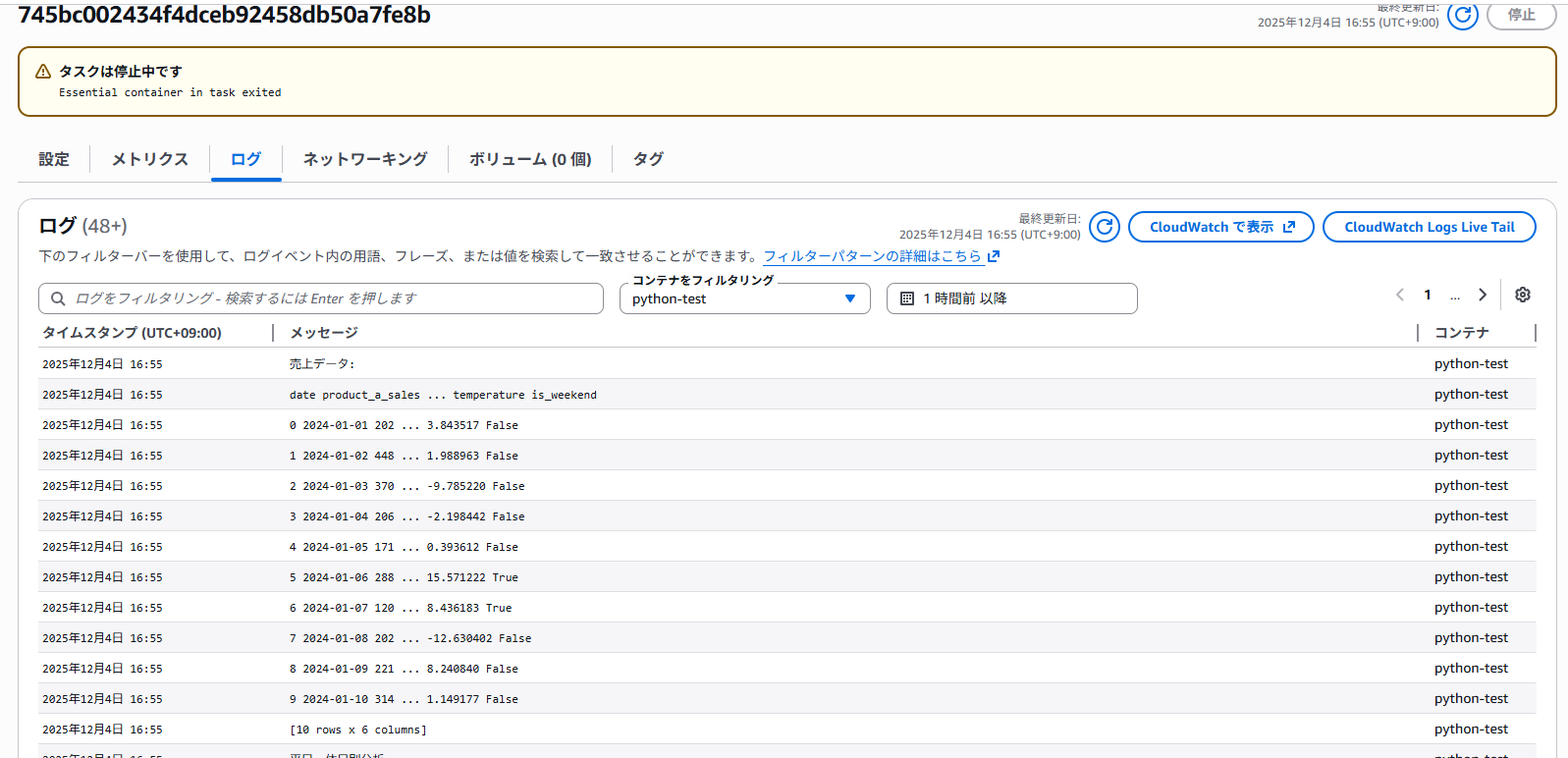
タスクの完了を確認します。ログが出ていることが確認でき、正常に処理が行われていることが確認できました。
5. 定期実行の確認
cronで定期実行を指定できます。(UTC時間なので注意!)
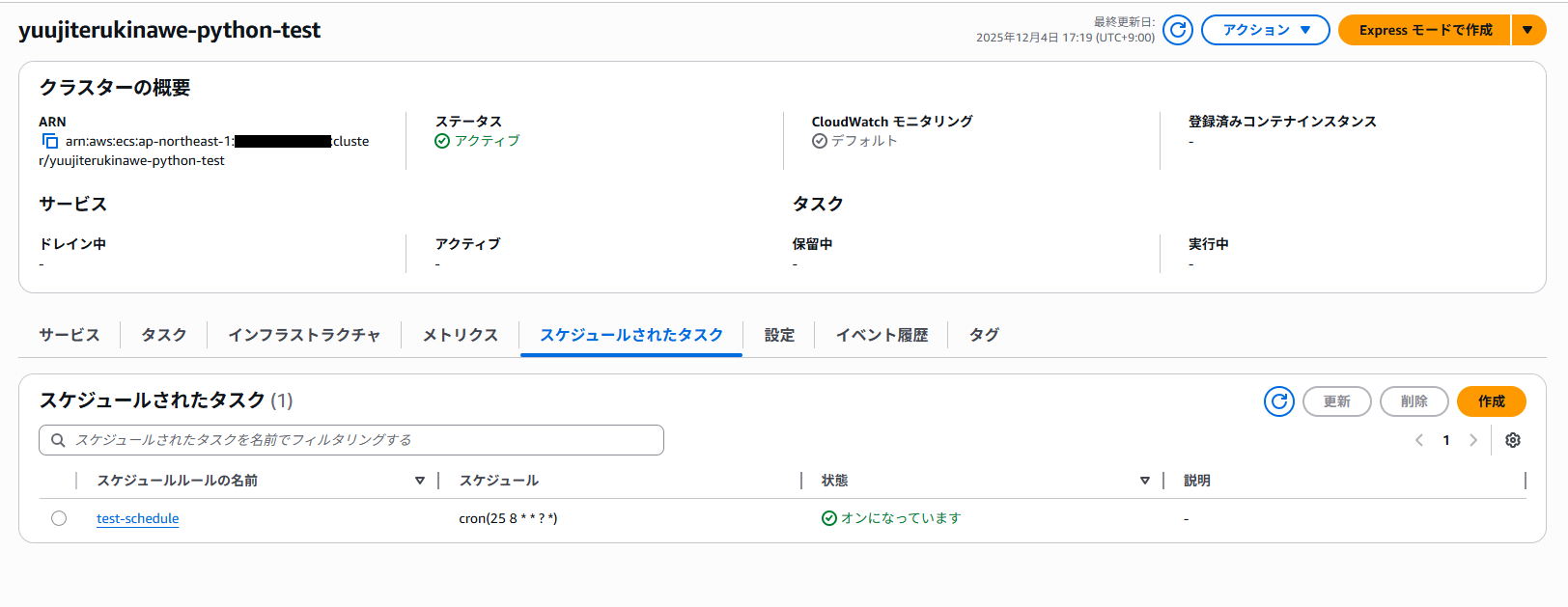
指定した時間に実行が行われました。
おわりに
最後まで読んでいただきありがとうございます。Python shellからECSへの移行はコンテナの構築がある関係上心理的ハードルは高いですが、EOLやコストの問題から移行が必要となる場面もあるかと思うので一度お試ししてみてください。
明日は、NTTテクノクロスアドベントカレンダー11日目の記事となります。明日の記事もお楽しみに。